10 分钟内查询一个 PB 级的云存储
Elastic 的新冻结数据层将计算与存储分离,并利用低成本的对象存储系统(如 Google Cloud Storage、Azure Blob 存储或 Amazon S3)直接促进搜索。它提供了无限的存储扩展,同时保留了高效查询数据的能力,无需首先对数据进行解冻,使大规模管理数据变得更容易、更经济。
在这篇博文中,我们将比较新冻结层与现有 Elasticsearch 数据层的搜索性能,并展示如何使用冻结层以较低的性能存储和搜索更大量的数据。冻结层的主要亮点有:
- 如果数据没有缓存,在 4 TB 数据集中返回简单词条查询的结果需要几秒钟。如果有缓存,则搜索性能会以毫秒为单位,类似于暖层或冷层。
- 如果数据没有缓存,在 4TB 数据集上计算一个复杂的 Kibana 仪表板所需时间不到 5 分钟。如果有缓存,这一计算将在几秒钟内完成,类似于暖层或冷层。
- 轻松将数据量扩展到 1PB 数据集。在无缓存的情况下,对简单词条查询的结果将在 10 分钟内返回。
目前,冻结层在 Elasticsearch 7.12 和 Elastic Cloud 上以技术预览方式提供,很快就可以普遍应用。
数据层简介
数据层提供了优化的存储和处理能力,可实现基于不同需求(例如基于年龄、数据源或其他标准)的数据访问。热层主要处理集群中新数据的所有索引,并保存查询最频繁的最近每日索引。由于索引通常是一项 I/O 密集型活动,运行这些节点的硬件需要更强大,因此需要使用 SSD 存储。暖层可以处理大量查询频率较低的索引,因此可以使用延迟较长、成本较低的存储设备,例如非常大的旋转磁盘,降低较长时期内保留数据的总体成本,同时确保数据仍可用于查询。
最近引入的冷层和冻结层利用低成本的对象存储以具有成本效益的方式管理大量数据,同时保留了对数据的搜索能力。

冷层无需副本,而是通过从快照中恢复数据的方式促成恢复事件。在热层和温层中,有一半的磁盘空间通常用于存储副本分片。这些冗余副本可确保查询快速完成,性能一致,并能在机器故障时起复原作用(机器故障时,副本将成为新的主分片)。但是,一旦数据在其生命周期中变为只读,恢复就可以被卸载到快照。这意味着在冷层中,无需副本分片;当某个节点或磁盘故障时,系统会自动从快照中恢复数据,从而在集群中重新创建完整副本,以便本地磁盘重新提供搜索服务。快照存储库非常适合这种情况,因为在 Blob 存储中存储数据比在本地 SSD 或旋转磁盘上存储数据要经济得多,而且在大多数情况下,为了备份目的,数据会在 Blob 中存储。因此,冷层只需要温层一半的本地存储空间,就具有类似的查询性能,只是可用性稍逊,但能比温层节省 50% 的成本。
冻结层更进一步,只在集群本地缓存少量但经常访问的数据部分,并根据搜索要求基于搜索需求从对象存储中惰性地提取数据,从而将计算与存储分离。与到目前为止使用 Elasticsearch 所实现的功能相比,这提供了更高的计算存储比。当然,冻结层中的搜索可能比在热层、温层或冷层中慢得多,但对于不太频繁的搜索(如运行或安全调查、法律搜索或历史性能比较)来说,这是可以接受的折衷。Elasticsearch 具有默认为所有内容建立索引的优势,这一功能非常强大,因为它避免了在查询时对数据进行全面扫描,并且利用这些索引结构可以在非常庞大的数据集上快速返回结果。
冻结层的工作原理
冻结层中的节点不需为保存其所有索引的完整副本预留充足的磁盘空间。相反,我们引入了磁盘上的 LFU(最少使用)缓存,它只缓存从 Blob 存储下载的索引数据的一部分,以服务于给定的查询。磁盘缓存的工作原理类似于操作系统的页面缓存,可以加速对 Blob 存储数据中经常请求部分的访问。在 Lucene 级别的读取请求会被映射到此本地缓存上。如果缓存丢失,可从 Blob 存储的 Lucene 文件中下载更大的部分(16 MB 的数据块),供搜索用。到 Lucene 下一次访问文件的相同部分时,就可直接从本地缓存获取。
节点级共享缓存将基于“最少使用”策略对映射的文件部分进行逐出处理,因为我们认为 Lucene 文件的某些部分的使用频率比其他部分更高。如果需要使用一个 Lucene 文件的某些部分反复响应查询(比如 @timestamp 字段的范围查询),那么这些数据将保留在缓存中,而其他数据可能会被逐出。
虽然现在搜索需要下载正在访问的文件部分,但 Lucene 基于一组预先计算的索引结构执行搜索的方式减少了有待扫描的数据量,使这个过程变得更快。为了进一步减少这些分片的内存占用,我们只在有需要时,也就是说,在有活动搜索的时候才打开 Lucene 索引。这使我们能够在一个冻结层节点上拥有大量索引。
基准测试目标
对于每一层,我们在第一次访问时测量搜索性能(没有利用任何缓存,因为它们还没有预热),并使用相同的查询重复搜索(缓存预热)。对于冻结层,当磁盘上的 LFU 缓存不能容纳所有数据时,我们还会检查重复搜索性能。
对于这个基准测试,我们考虑了两种查询类型。第一个代表安全调查,即在一个大数据集中找到一小组匹配的文档(犹如大海捞针),第二个代表 Kibana 仪表板,即对大量数据进行多次频繁聚合计算。
由于这些基准测试的目标是准确地比较不同层的查询性能,所以我们选择在所有层上使用相同的机器类型;然而,在实际部署中,应该使用针对特定层的机器类型,以权衡每一层的最佳成本和性能。基准测试中的基线是热层,其中有常规的基于时间的 Elasticsearch 索引。温层访问数据的方式与热层相同,并且为实现此基准测试的目的,我们对所有层使用相同的机器类型,因此它等同于热层,没有单独列出。在冷层中,我们有从快照装载的相同索引的完整副本。在冻结层中,我们使用磁盘上的 LFU 缓存从快照装载索引。
基准测试设置
基准测试使用 Elasticsearch 7.12.1 在 Google Cloud 上运行,并以一个基于事件的 Web 服务器日志数据集为基础,Elastic 使用该数据集对各种功能进行基准测试。磁盘上索引数据集的大小为 4 TB(10 个基于时间的索引,各有 5 个 80 GB 的分片,每个映射中有 35 个字段)。分片被强制合并为一个段,这优化了读取性能,也是索引生命周期管理在将数据移动到冻结层时使用的默认值。相同的(预先计算的)数据快照(可使用 Elasticsearch 的 repository-gcs 插件在 Google Cloud Storage 中访问)用于对每一层进行基准测试。恢复限制被禁用,以免人为限制性能。
在我们的基准测试中,第一个搜索只是一个简单的词条查询,用于查找数据集中的匹配项;在该数据集中,某个给定的 IP 地址访问了 Web 服务器:"nginx.access.remote_ip":"1.0.4.230"。
第二个搜索是 Kibana 仪表板,它包含五个视觉效果,用于分析带有 404 响应代码的请求,例如,查找不再指向任何地方的链接。
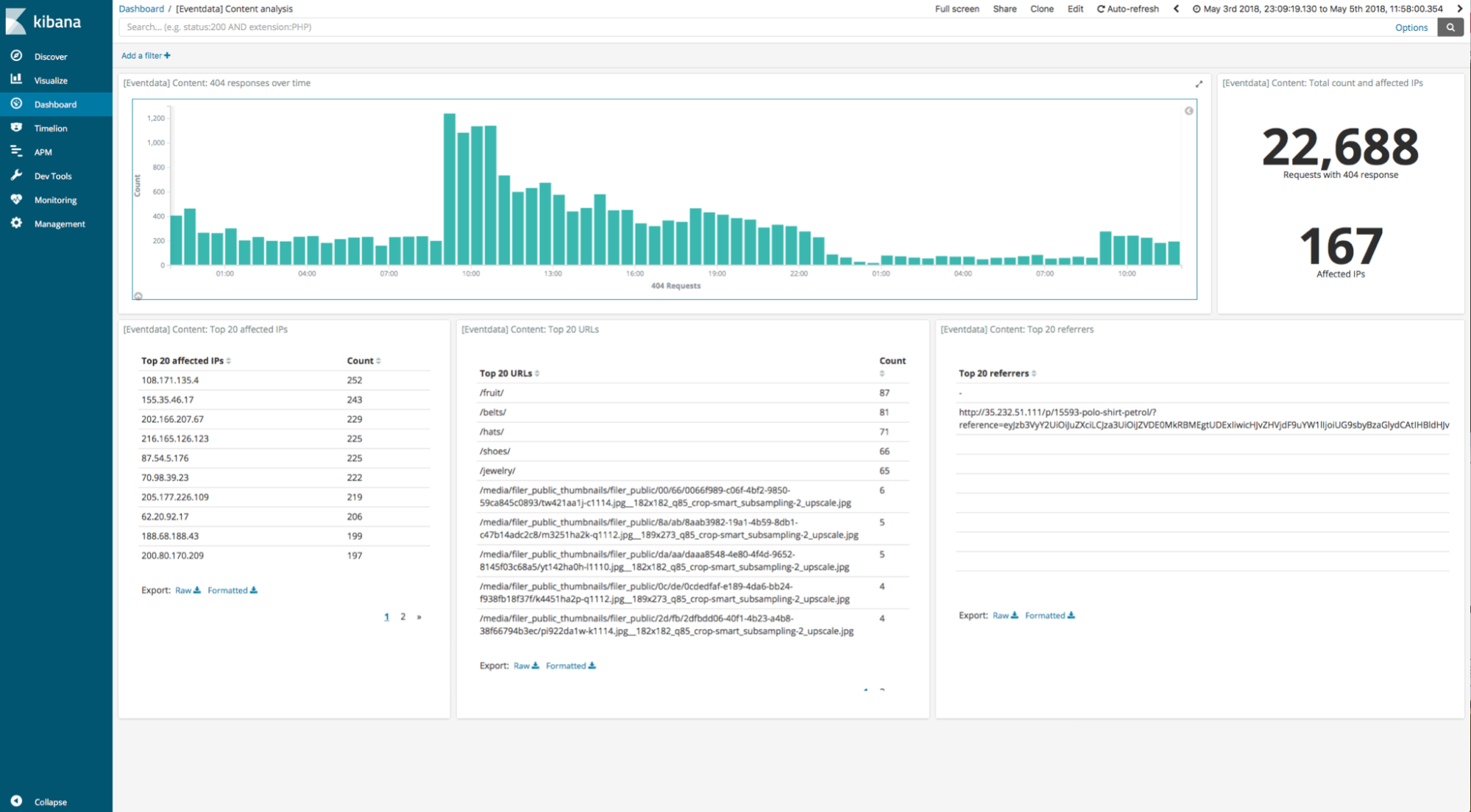
在每个基准测试场景中,我们运行一些预备步骤以减少运行间的差异,包括删除操作系统缓存和 slab 对象,以及修整 SSD 磁盘。在热/温层,Elasticsearch 默认使用 hybridfs 存储类型,这些内存映射了 Lucene 的一些文件类型。冷层和冻结层不使用内存映射。因为内存映射会通过预取页面对页面缓存有影响,我们在热/温层进行两项测试并提供结果:使用内存映射,以及使用 "niofs" index.store.type 来配置它(更接近于我们访问冷层和冻结层中本地文件的方式)。
为了简单起见,我们这里只对单节点集群进行基准测试,但每一层也支持多节点集群。单节点集群是一个 Google Cloud 上的 N2D (n2d-custom-8vCPUs-64GB) 实例,具有 8 个 vCPU,64 GB RAM(Elasticsearch 将其中的 29 GB 用于 JVM 堆),以及 RAID-0 中16 x 375 GB 的本地暂存 SSD 磁盘,以便它可以在热/温层和冷层中完全容纳 4 TB 数据集。它是一个适合冻结的候选实例,因为它有应用于磁盘上 LFU 缓存的快速本地磁盘,并且有到Google Cloud Storage 的快速网络连接。
我们还针对冻结层中的磁盘上 LFU 缓存采用两种不同的缓存大小进行实验,以显示其对重复搜索的重要性:200 GB (数据集的 5%)和 20 GB (数据集的 0.5%)。
结果
查询性能受到各种缓存机制的影响,从操作系统级页面缓存到应用程序级内存缓存,例如分片请求缓存和 Elasticsearch 中的节点查询缓存。对于每个结果,我们都解释了这些缓存是如何发挥作用的。显示的结果为五次运行的中位数,以减少运行间的差异。
简单词条查询
让我们从简单的词条查询开始。这里主要的观察结果是,冻结层在几秒钟内返回 4 TB 数据集上的结果(5 个匹配文档),只下载数据集的很小一部分来寻找匹配的元素。这突显了 Lucene 中的索引结构功能强大,可实现快速查找。
重复运行查询后,所有层展示出相似的性能,因为现在可以在冻结层中提供来自于本地磁盘上 LFU 缓存的数据。Elasticsearch 的内存中结果缓存在这里不起作用,因为这种类型的查询不会被缓存。在页面缓存中提供数据会影响在热/温层和冷层中重复运行的性能。
4TB 数据集上进行简单的词条查询 | |||
操作 | 热/温层 niofs | 冷层 | 冻结层 |
简单词条查询:首次运行 | 92 毫秒 | 95 毫秒 | 6257 毫秒 |
简单词条查询:重复运行 | 29 毫秒 | 38 毫秒 | 76 毫秒 |
注意:在所有层中使用相同的机器类型,以便展示在冻结层反复使用缓存给查询性能带来的改善。这并非实际部署中跨不同层的查询性能。请参阅基准测试目标,了解更多详细信息。
当使用默认索引存储类型 hybridfs 而不是 niofs 时,热/温层的性能在首次运行时会略低(285 毫秒而不是 92 毫秒),详细信息将在下一节中介绍。
Kibana 仪表板
我们对 Kibana 仪表板重复同样的流程。这里主要观察结果是,冻结层在 5 分钟内基于相同的 4 TB 数据集返回仪表板,而在具有本地数据访问途径的其他层中计算仪表板需要 20 秒。尽管仪表板使用时间范围筛选聚合了超过 75% 的数据集,但由于索引结构,它仍然只需要下载存储库中的一小部分数据(在本例中约为 3%,下文将详细介绍)。
4 TB 数据集上的 Kibana 仪表板 | ||||
操作 | 热/温层 niofs | 冷层 | 冻结层 (5% 的缓存) | 冻结层(0.5% 的缓存) |
仪表板:首次运行 | 16.3 秒 | 16.6 秒 | 282.8 秒 | 321.5 秒 |
仪表板:精准重复运行,无 Elasticsearch 结果缓存 | 6.2 秒 | 7.1 秒 | 11.1 秒 | 224.1 秒 |
仪表板:精准重复运行,有 Elasticsearch 结果缓存 | 80 毫秒 | 75 毫秒 | - | - |
仪表板:相似重复运行,无 Elasticsearch 结果缓存 | 19.5 秒 | 20.3 秒 | 23.4 秒 | 238.4 秒 |
当 Elasticsearch 的结果缓存被禁用时,重复搜索的性能主要依赖于页面缓存,当查询所需的数据部分完全纳入磁盘上的 LFU 缓存时,重复搜索的性能就与冻结层的性能相当。值得注意的是,对于这个特定的工作负载,热/温层中的内存映射会导致页面缓存“抖动”,当使用默认存储类型时,这会对热/温层的性能产生不良影响(与使用 niofs 时的 6.2 秒相比,最多可慢三倍)。
对于冻结层,我们考虑了两种不同大小的 LFU 缓存的,以显示对重复搜索性能的影响。磁盘上的 LFU 缓存大小首先被定为 200 GB,这只是 4 TB 的一小部分(数据集大小的 5%),但仍然足以容纳为计算给定的仪表板而下载的所有数据(大约 3%,或 120 GB)。在第二次运行基准测试时,它的大小仅定为 20 GB(原始数据集大小的 0.5%),这不足以容纳给定仪表板需要的所有数据。
当启用 Elasticsearch 的内存中缓存时,重复搜索会更快,因为部分查询结果现在可以直接在Elasticsearch 节点上获得,而不需要重新计算。然而,目前冻结层并不使用这些内存中的 Elasticsearch 缓存。
对于仅计算的仪表板略有不同并通过不同的国家/地区代码进行筛选的情况,我们也进行了基准测试。在这种情况下,由于已经下载了与满足这个略有不同的查询相关的数据的许多部分,冻结层可以从中受益,并且返回结果的速度几乎与其他层一样快。
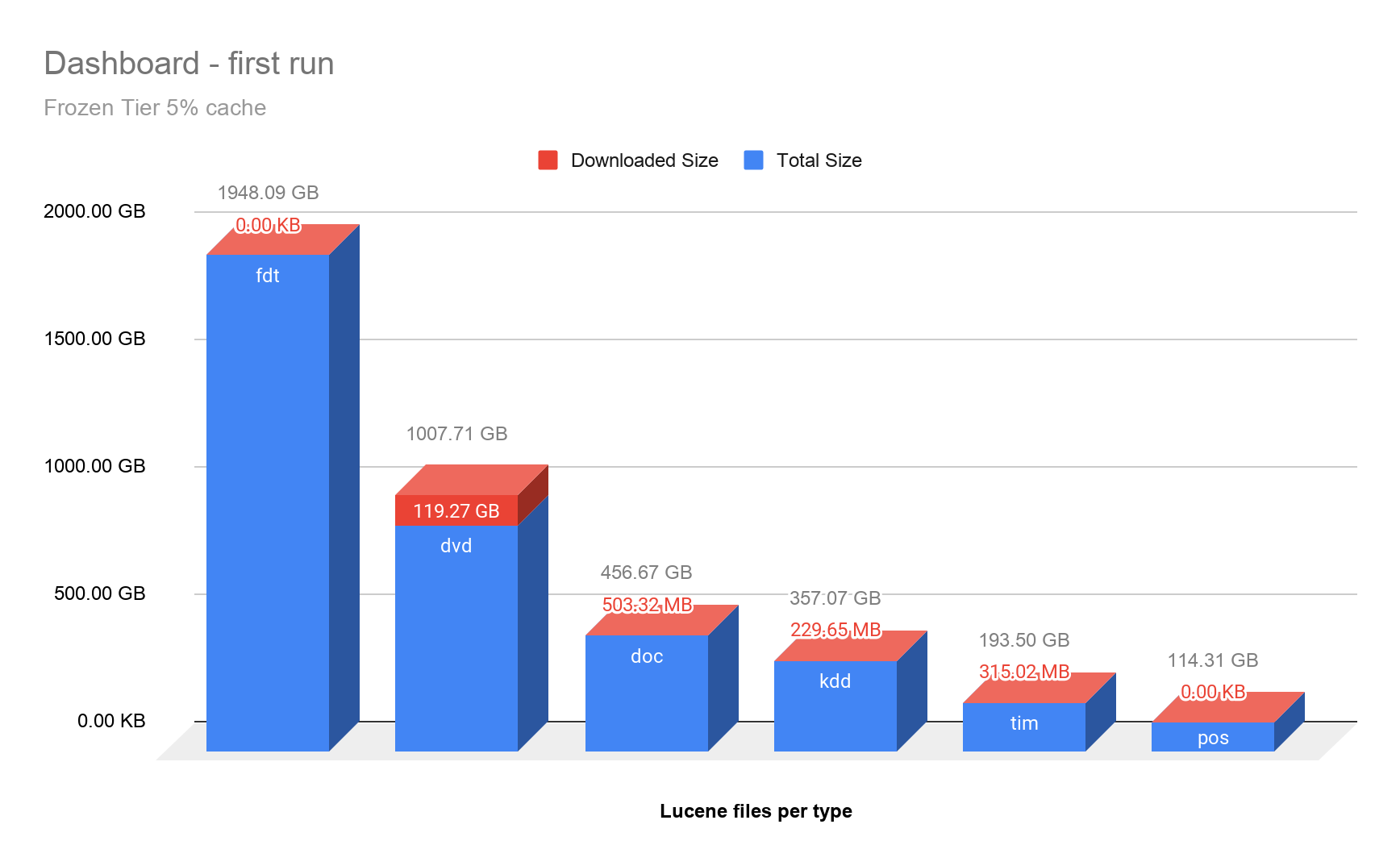
为了在首次运行仪表板时显示在冻结层中下载了些什么,我们对请求的六个最大的 Lucene 文件类型以及下载了多少量进行了可视化。虽然 fdt(字段数据)文件消耗了大部分空间(用于存储文档),但并未通过访问这些文件来计算聚合。正如预期的那样,大多数访问都是在 Lucene 的 dvd(每个文档的值)文件上完成的,它们是用于计算聚合的文档值。
快速访问大量对象存储
虽然在冻结层上的查询肯定会更慢,但它的主要优势体现在不经常访问上,使数据无需解冻即可用于搜索。相比之下,即使禁用了恢复限制,在本地提供完整的数据集也需要一个多小时,这比我们直接在冻结层上运行查询所花的时间要长得多。
使 4 TB 数据集可访问 | |||
操作 | 热/温层 | 冷层 | 冻结层 |
从快照恢复索引 | 72.4 分钟 | - | - |
从快照挂载索引 | - | 115 秒 | 47 秒 |
预热(使数据在冷层本地完全可用的时间) | - | 82.8 分钟 | - |
扩展到 PB 级
到目前为止,基准测试集中在层与层之间的性能比较上,不能展示冻结层的全部可能性。该层比其他层具有更高的计算存储比。我们采用了接近极致的做法,对相同的数据集进行了超过 250 次的挂载,每次都使用不同的名称,以便将其作为单独的索引处理。然后,我们的单节点集群有 12500 个 80 GB 的分片,这相当于挂载了 1 PB 的数据。在完整的 1 PB (相当于 100 万 GB) 数据集上运行简单的词条查询只花了不到 10 分钟的时间,表明这一实施过程可以很好地扩展到更大的数据集。
在 1 PB 数据集上的简单词条查询 | |||
操作 | 热/温层 | 冷层 | 冻结层 |
简单词条查询:首次运行 | 不可行(需要 1 PB 的本地存储!) | 554 秒 | |
简单词条查询:重复运行(具有 4 TB 磁盘上 LFU 缓存) | 127 秒 | ||
在实践中,这可能不是一个理想的设置,因为单个节点上分片过多,本地磁盘缓存与对象存储大小的比率极低。在这种规模下,数据集的存储成本远超冻结层节点的计算成本,因此添加更多节点将显著提高性能,而对成本的影响可以忽略不计。
调整磁盘上 LFU 缓存的大小
如前所述,为了在重复搜索中获得优良的性能,调整磁盘上的 LFU 缓存大小很重要。在这里,正确的值在很大程度上取决于所运行的查询类型,特别是产生查询结果所需访问的数据量。因此,挂载更大量的数据并不一定总是需要更大的磁盘缓存。例如,在基于时间的索引背景中应用时间范围筛选可以减少需要查询的分片数量。由于在数据访问模式中经常存在某种底层空间或时间局部性,冻结层将允许对非常大的数据集进行有效查询。根据我们目前的观察结果,我们建议调整磁盘上 LFU 缓存的大小,使其介于挂载的数据集大小的 1% 到 10% 之间。5% 的比率也许是一个很好的实验起点。
请注意,冻结层可以很好地支持垂直和水平扩展,因为计算具有非常相似的性质。使用性能更好的机器类型或向集群添加更多节点就是提高冻结层查询性能的一种简单方法。
结论
我们已经展示了冻结层可以以优异的性能响应两种不同类型的查询。使用 Elasticsearch 的默认索引策略,冻结层的搜索性能要比扫描整个数据集快几个数量级。在冻结层中的重复搜索将进一步受益于磁盘上的缓存,并提供与其他层相似的性能。
当以经济有效的存储搭配灵活的计算存储比为主要目标时,冻结层就会提供巨大的价值。冻结层中的数据只是作为任何常规索引而访问,因此可以轻而易举地切换现有设置,以利用这个令人兴奋的新功能。进行设置也并非难事,因为它再次利用了已经用于备份目的的快照存储库,并与索引生命周期管理完全集成,以便将数据从热层/温层/冷层转换到冻结层。Kibana 的异步搜索集成在此基础上提供了扩展功能,允许在后台计算运行缓慢的仪表板,并在可用时进行可视化。
冻结层既可用于自托管部署,也可用于 Elastic Cloud,所以请查看这份文档,进行尝试,并提供您的反馈意见吧。