Elasticsearch 优化排序查询,更快获得结果


 Share on Twitter
Share on Twitter在 Twitter 上分享

 Share on LinkedIn
Share on LinkedIn在 LinkedIn 上分享

 Share on Facebook
Share on Facebook在 Facebook 上分享

 Share by Email
Share by Email通过邮件分享

 Print this page
Print this page打印
请求按某个字段对结果进行排序是 Elasticsearch 极为常用的操作。我们投入了大量时间和精力来优化排序查询,以便为用户提供更快的排序查询体验。本篇博文将介绍我们对数值和日期字段进行的一些排序优化。
排序查询的工作原理
当您想要找到匹配筛选条件的文档,并请求按某个字段对结果进行排序时,Elasticsearch 会检查该字段的文档值,找出所有匹配筛选条件的文档,并根据排在最前面的值选出前 K 个文档。最复杂的情况莫过于筛选条件极其宽泛(例如 match_all query),此时,我们必须检查并比较某个索引中所有文档的文档值。对于大的索引来说,这一过程可能需要相当长的时间。
优化特定字段排序查询的方法之一是使用索引排序,并对该字段中的整个索引进行排序。如果索引按字段进行了排序,那么其文档值也会被排序。因此,要获得按某个字段排序的前 K 个文档,我们只需获取前 K 个文档,甚至不必检查其余的文档,如此一来,排序查询自然就非常快了。
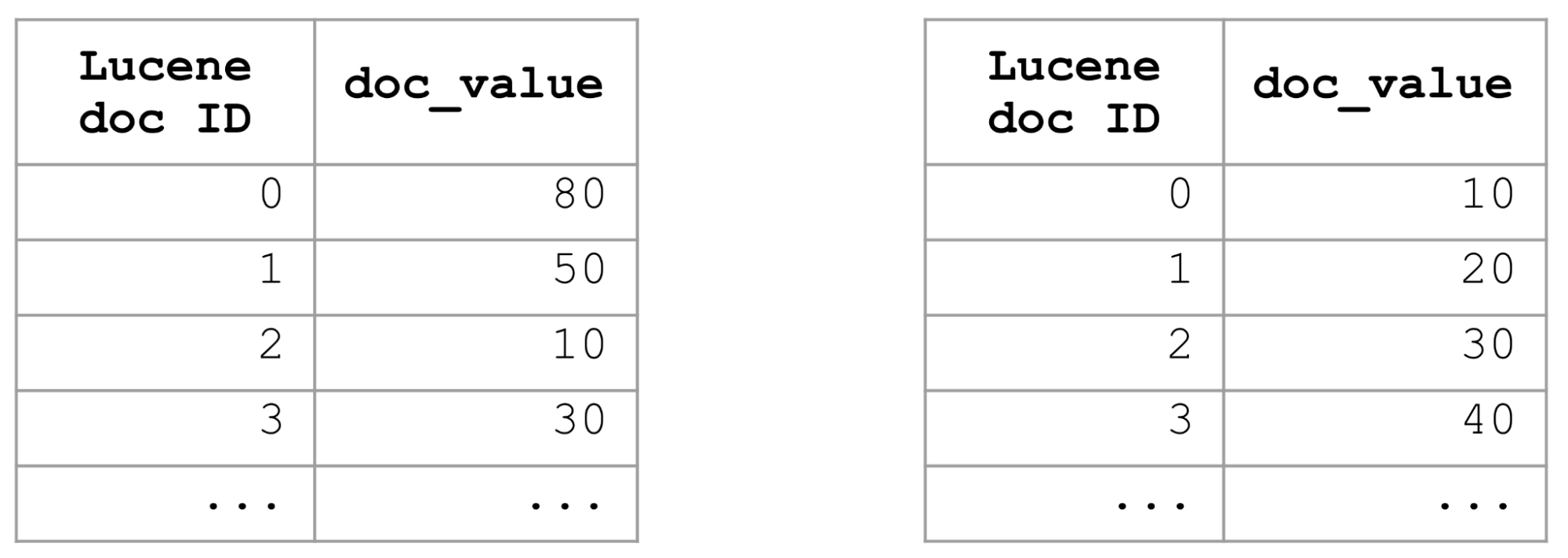
索引排序是一个不错的解决方案,但是您只能以单一方式进行索引排序。索引排序并不适用于具有下列特征的排序查询:采用不同的排序标准,例如降序与升序;采用不同的字段;或所用组合不同于索引排序定义中指定的组合。因此需要其他更灵活的方法来提高排序查询的速度。
使用 distance_feature 查询优化数值排序查询
以前,我们通过为每个文档块存储最大影响因素(词频与文档长度的组合)的方式,显著提高了基于词且按 _score 排序的查询的速度。在查询期间,我们可以通过查看文档块的最大影响因素来快速判断其是否具有竞争力。如果某个块不具有竞争力,我们可以跳过整个文档块,这将极大地加快查询速度。
我们当时觉得有可能利用类似的方法来提高对数值或日期字段的排序查询速度。结果证明,用 distance_feature 查询代替排序是可行的。distance_feature 查询是一种值得关注的查询方式,它会返回最接近给定原点的前 K 个文档。如果我们使用字段的最小值作为原点,我们将得到按升序排序的前 K 个文档。使用最大值作为原点则会按降序为我们提供前 K 个文档。
对我们来说,distance_feature 查询最具吸引力的特点在于,它可以有效跳过无竞争力的文档块。为实现这一点,它需要依赖于 BKD 树的属性。BKD 树在 Elasticsearch 中用于索引数值和日期字段。类似于将文本字段的倒排索引划分为文档块的方法,BKD 索引也被划分为单元格,并且每个单元格的最小值和最大值是已知的。因此,只需检查单元格的最小值和最大值,distance_feature 查询就可以有效跳过文档无竞争力的单元格。要运行这种排序优化方法,数值或日期字段既要有索引又要有文档值。
用 distance_feature 查询代替对文档值进行排序,使我们可以实现大幅提速(在某些数据集上高达 35 倍增益)。我们已在 Elasticsearch 7.6 中引入了这种对日期和长字段的排序优化。
使用 search_after 优化排序查询
我们为所取得的这些提速成果感到欣慰,不过在使用 search_after 参数进行排序的问题上,我们还没有找到一个令人满意的解决方案。利用 search_after 进行排序十分普遍,因为用户通常不仅会关注搜索结果的首页,也会对后续页面感兴趣。可以确定的是,相较于当前使用的在 Elasticsearch 中重写排序查询的方法,更好的解决方案是让 Lucene 中的比较器和收集器进行这种排序优化,并跳过无竞争力的文档。Lucene 中的比较器和收集器已支持 search_after,得益于此,我们苦于寻找解决方案的难题也迎刃而解了。我们将 distance_feature 查询用于跳过无竞争力文档块的同一个 Elasticsearch 代码添加到 Lucene 的数值比较器中。
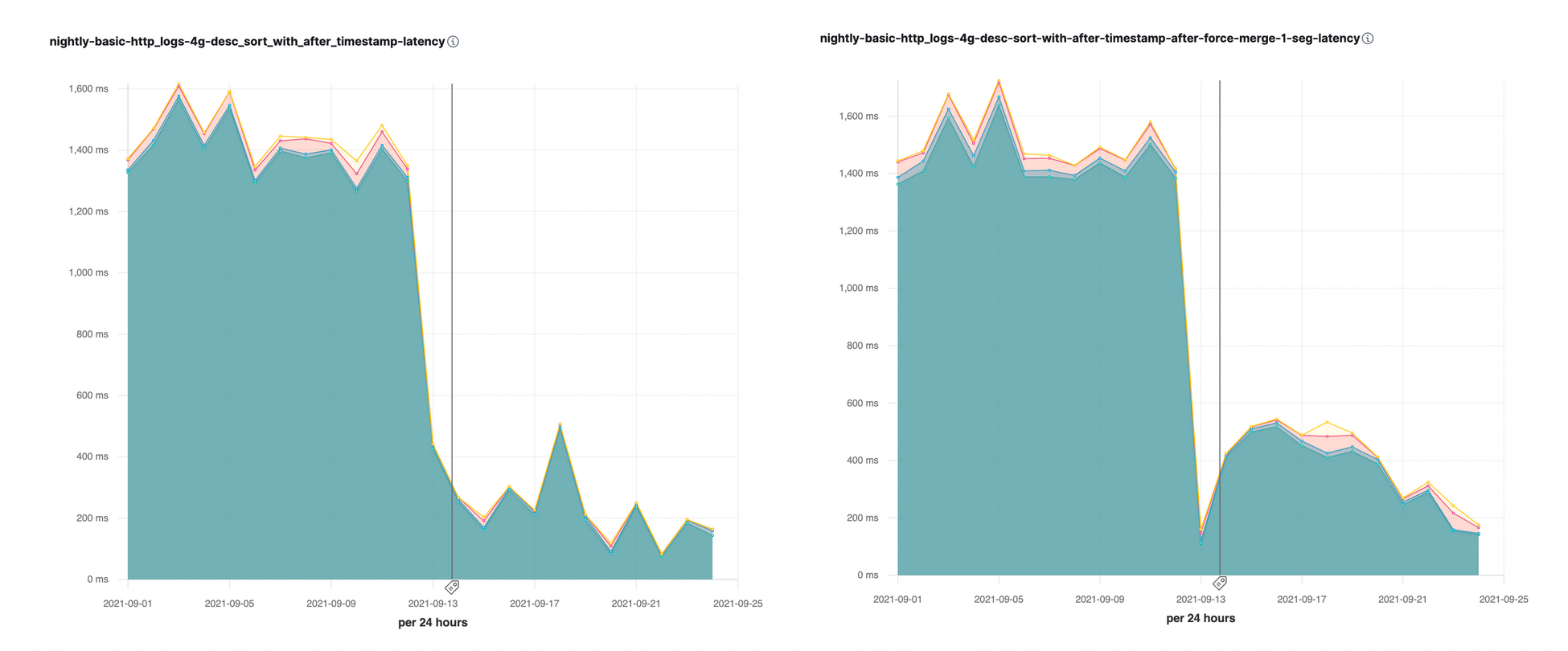
在 Elasticsearch 7.16 中,我们已利用 search_after 参数引入了这种排序优化。我们发现,在一些夜间性能基准测试中,查询速度大幅提升(高达 10 倍),效果立竿见影:
优化跨多个段的排序
一个分片由多个段组成。Elasticsearch 在搜索时会按顺序检查段,因此确定具有前 K 个值的文档,先从最有可能包含此类文档的段开始处理会事半功倍。一旦收集了具有前 K 个值的文档,我们就可以快速跳过仅含有排位靠后的值的其他段。
先从哪些段开始处理在很大程度上取决于用例。对于时间序列索引,最常见的请求是对时间戳字段的结果进行降序排序,因为人们最关心的是查看最新事件。为了优化时间序列索引的这种排序,我们首先对 @timestamp 字段进行降序排序,以便可以最先处理包含最新数据的段,理想情况下,我们可以按时间戳文档在第一个段中收集最新的数据并跳过所有其他段。这一方法强有力地提高了时间戳字段的降序排序查询速度。
当较小的段合并成更大的段时,我们不希望出现最新的段排在最后,而其中最新的文档也位列末尾的情况。为了更加均衡地合并段,我们引入了新旧段交叉的全新合并策略,即新旧段的文档在全新的合并段中以混合顺序排列。这也可以让我们高效查找最新的文档。
优化跨多个分片的排序
Elasticsearch 的强大之处在于它的分布式搜索,如果忽略了分布式的特点,任何优化都无法尽如人意。一些搜索可以跨越数百个分片(例如对时间序列索引的搜索),对此,从“正确”的分片集开始操作且跳过不包含具有竞争力命中结果的分片将大有助益。该方法已得到全面落实。从 Elasticsearch 7.6 开始,我们根据主排序字段的最大值/最小值对分片进行预排序,以便我们可以从这样一个分片集开始分布式搜索,即其中的分片最有可能包含排在最前面的值。从 Elasticsearch 7.7 开始,我们省去了使用来自其他分片的结果这一查询阶段,即一旦我们从第一个分片集收集了排在最前面的值,就完全可以跳过其他分片,因为相较于前面分片中计算得到的最后面的排序值,这些分片中所有候选的值还要更加靠后。在许多机器生成的时间序列索引中,文档遵循索引生命周期策略,从性能优化的硬件开始,到成本优化的硬件结束,然后才是删除文档。这种分片跳过机制通常意味着用户可以发送广泛的查询,并享受由其性能优化的硬件所定义的查询性能,因为速度较慢和更经济的硬件上的分片会被跳过(使可搜索快照的应用更加高效)。
对用户的影响
作为 Elasticsearch 的用户,您如何才能利用这些排序优化呢?只有在无需跟踪某个请求确切的总命中数且该请求不包含聚合时,这些排序优化才会发挥作用。如果您需要知道确切的总命中数,我们就不能执行任何跳过操作,因为我们需要计算所有匹配筛选条件的文档。track_total_hits 的默认值设置为 10,000,也就是说,排序优化只有在收集了 10,000 个文档时才能开始。如果将此值设置为一个较小的数或“false”,那么 Elasticsearch 就可以更早地开始排序优化,换言之,您的请求响应速度也会更快。
最近 Kibana 也开始在 track_total_hits 被禁用的情况下发送请求,因此 Kibana 中的排序查询也应该会更快。
立即试用
现有 Elastic Cloud 客户能够直接从 Elastic Cloud 控制台访问其中的许多功能。如果您刚刚使用 Elastic Cloud,请查看我们的快速入门指南(助您快速入门的培训短视频),或我们的免费基础知识培训课程。您随时可以开始使用 Elastic 企业搜索的 14 天免费试用版。或者,您也可以免费下载 Elastic Stack 的自管型版本。
分享
- Share on Twitter
在 Twitter 上分享
- Share on LinkedIn
在 LinkedIn 上分享
- Share on Facebook
在 Facebook 上分享
- Share by Email
通过邮件分享
- Print this page
打印