Elasticsearch 7.13 版新增功能:更快的聚合
在上一节中,我提到了一些关于 date_histogram 的速度改进。所以我也迫不及待地想看看是否可以将同样的原则应用于其他聚合。在过去的几个月里,我大部分时间都在忙于开发运行时字段,但最终我抽时间研究了一下 terms 聚合。
是时候谈谈 terms 了!
在 date_histogram 聚合方面,我们通过在内部将其重写为 filters 聚合,获得了巨大的性能提升。将 terms 重写为 filters 产生了更为复杂的结果。我经常会看到惊人的速度提升 (454ms -> 131ms)。请查看链接的 PR,详细了解一下“经常”具体是指多频繁。但是,现在我们已经将聚合重写为 filters,我们可以更进一步了!
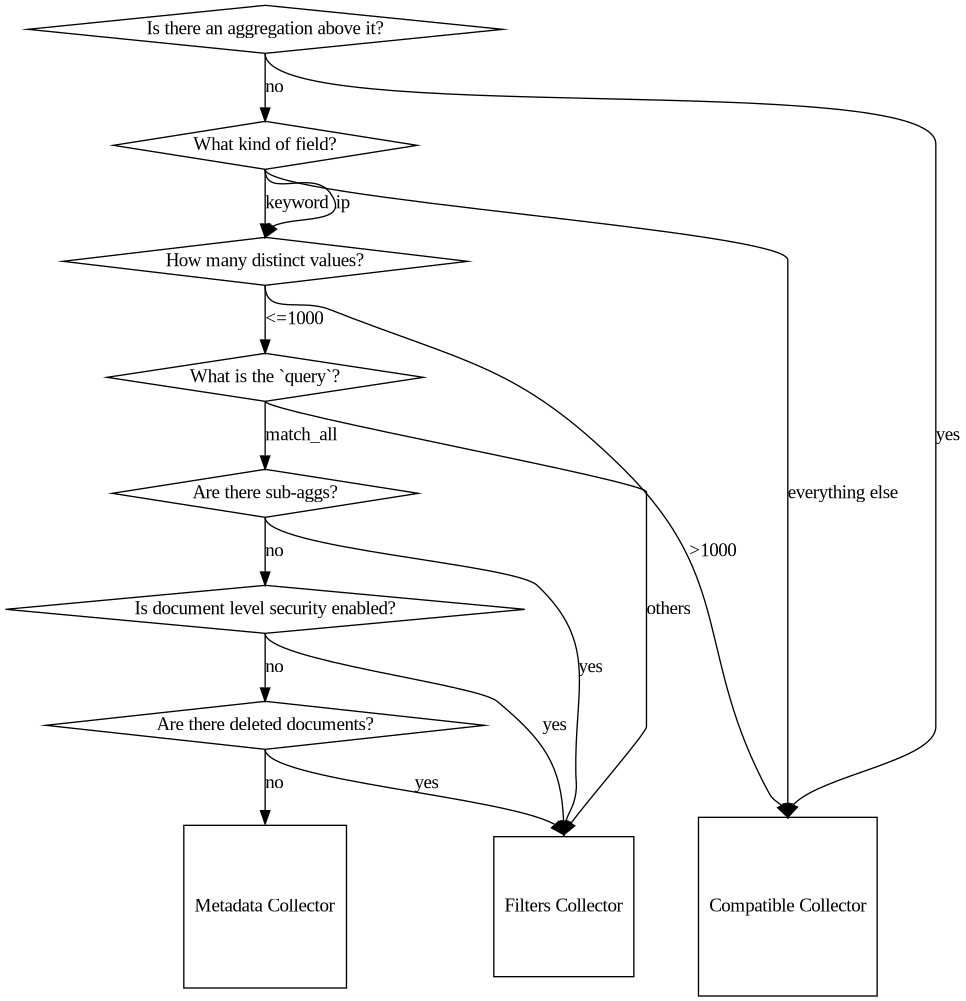
我们实现了另一项令我非常兴奋的优化。这是一条非常好的捷径,它让人觉得对原始代码不公平。这项优化包含了出色的代码!而且运行起来很好用!但是,新代码根本不收集命中信息。它只是从索引元数据中读取计数。这是一种不需要执行搜索的搜索。知道了吧,我们必须存储包含每个术语的文档计数,以便能够将其发送到相似度来计算分数。而且,如果大约有七个先决条件成立(见下图),那么计数正好是原始代码给出的答案。所以我们只是读取计数,而不是执行搜索。130 毫秒的请求时间缩短到了 37 毫秒。这对于能够使用这种优化的请求是相当常见的。特别是对于那些已经存在一段时间的分片尤为明显。这一点非常重要,因为这些分片通常最终会出现在旋转型磁盘上,甚至是可搜索d快照,这两者的 IO 速度都比高级 SSD 上的“热”分片要慢。
3.5 倍的速度提升并不是它的全部。我所做的其他大多数改进都是为了加快*收集*速度。因此,聚合的运行时间仍然与分片上的文档数量有关。根据您的查询,您会看到一些 O(docs_in_index)、一些 O(log docs_in_index) 和一些 O(matching_docs)。但是这个优化是 O(1)。换句话说,无论您在索引中放入多少文档,它都会在相同的时间内返回。可以说八九不离十。我们必须对每个段的统计数据求和,如果索引中有更多的文档,那么就会有更多的段。段数与文档数大致成对数增长。但是,与读取元数据相关的常量因素非常低,我希望您不会注意到。因此,实际上,运行时与文档数量无关。
我们将 3,300 万个气候测量值 (5.9GB) 的索引时间从 130 毫秒缩短到了 37 毫秒。如果实际情况一切顺利,您将在更大的数据集上看到更大的提升。您可能会问,为什么要收集气候数据?因为我喜欢啊,而且谁让我是运行性能测试的人呢。
别走开,精彩继续
在上一节中,我们谈到了将 date_histogram 重写为 filters。具体来说,它变成了一个包含 range 查询的 filters 聚合。这就是我们优化的内容 — range 查询。但是 Elasticsearch 很棘手。有时,当您要求它构建一个 range 查询时,它会构建一个 exists 查询。如果该字段的所有值都在 range 内,它就会这样做。我们可以对 exists 查询使用类似于 terms 查询的优化。这一点在 7.13 版中没有成行,但它将会在 7.14 发行版中。🚂
当 date_histogram 或 terms 具有子聚合(如 max 或 avg,甚至是其他的 terms 聚合)时,7.13 版会应用其中的一些优化。我们不能对元数据使用任何真正不公平的优化,因此您不会看到任何 8ms 聚合或类似内容。但是通过这一改变,我们在过去几个版本中所做的许多优化可以应用到更多的地方。我们的基准测试发现了这样一个改进。下图显示了从 320 毫秒下降到 270 毫秒左右的过程。
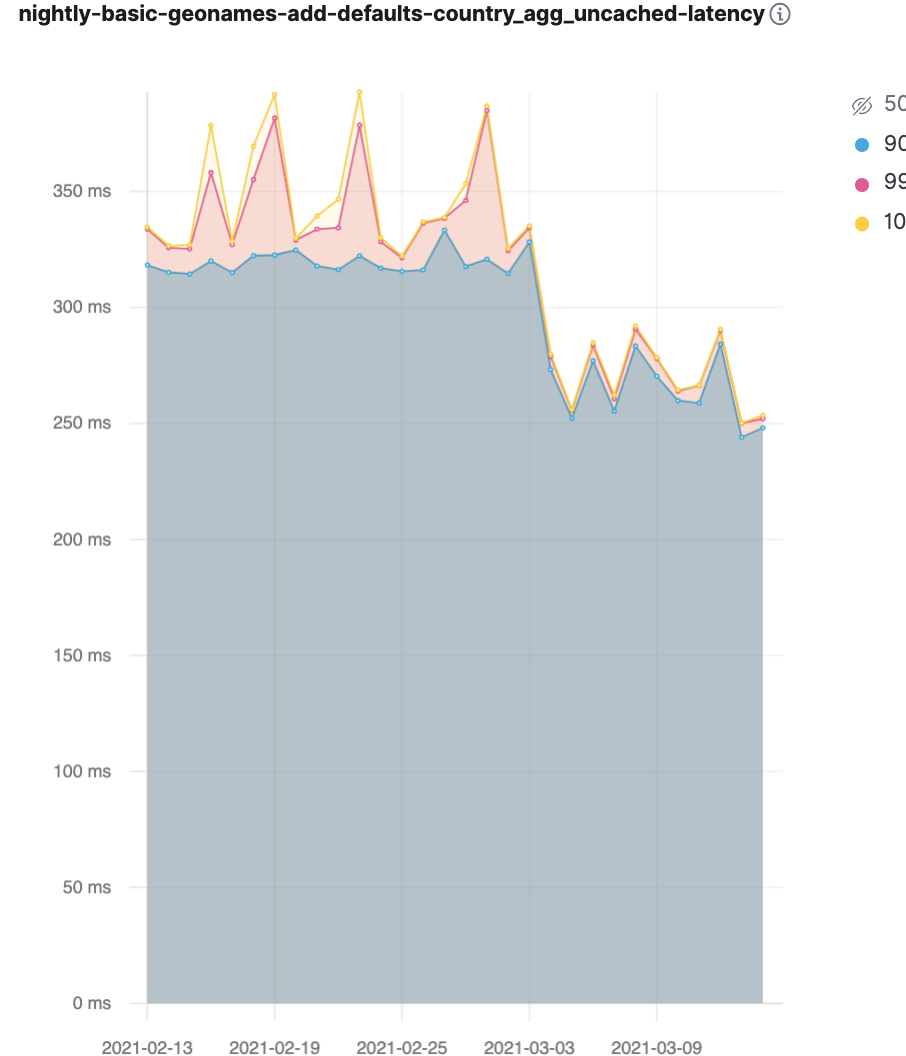
基准测试中 50 毫秒的下降相当于 15% 的聚合性能提升。这 15% 很可能表明,我们能够将这些经过优化的顶级收集机制用于子聚合。子聚合本身需要相同的时间,这在某种程度上“稀释”了我们通过加快顶级聚合速度而获得的性能增益。
试过 filters 吗?
到目前为止,我只谈到了 terms 和 date_histogram 的性能。特别介绍了我们如何加快这两个聚合的速度,方法就是:将它们作为 filters 运行,然后加快 filters 的聚合速度。filters 曾经是我们最慢的聚合之一。当然,如果不能走快速路径,它仍然是最慢的。我们只是在将 terms 或 date_histogram 作为 filters 运行时不采用这条路径。就这么简单!
但是,如果您出于某种原因*需要* filters 聚合怎么办?filters 的“快速路径”比慢速路径快大约 20 倍。现在,如果 filters 是最顶层的聚合,并且您不使用其他存储桶,那么就可以获得快速路径。在执行我上面提到的子聚合更改之前,您*还*必须确保 filters 聚合下没有聚合。
计划中的计划
现在,当 terms 或 date_histogram 不是搜索中最顶层的聚合时,这些高级的优化都不起作用。但从这个角度看,这是合乎逻辑的下一步。然后,我们就可以优化 date_histogram 内的 terms,或者 terms 内的 terms。拭目以待!