How we're making date_histogram aggregations faster than ever in Elasticsearch 7.11
Elasticsearch's date_histogram aggregation is the cornerstone of Kibana's Discover. And the Logs Monitoring UI. I use it all the time to investigate trends in build failures, but when it is slow I get cranky. Four seconds to graph all of the failures of some test over the past six months! I don't have time for that! Who is going to give me my four seconds back?! So I spent the past six months speeding it up. On and off.
Round with our bare hands
Back at the dawn of time (2018) there was a bug, "time_zone option makes date histograms much slower". Time zones that had a daylight savings time transition were four times slower. @jpountz fixed it by interpreting time ignoring daylight savings time on shards that don't contain any daylight savings transitions. It was good because time zones without a transition are easy! You just subtract their offset from UTC, round, add the offset back in, and do your aggregation. Well, you don't do it. The CPU does it. But still. It happens. You get the idea.
So date_histogram was fast. But every six months it slowed down! It's pretty common to have about a day's worth of data in an index. If you have to run a date_histogram on one of the indices with the daylight savings time transition it'd be slow. By the time I got wind of it the date rounding itself was about 1400% slower than on shards with a daylight savings time transition.
It turns out that we were using the java.util.time APIs which are lovely and accurate and cover everything but they allocate objects. And you really want to avoid making new objects for every single value in an aggregation. So we took the gloves off and implemented our own daylight savings time conversion code customized specifically for rounding times the way that date_histogram does it. Now instead of allocating we get to build an array with all of the daylight savings time transitions visible to the shard and just binary search it. That's fast! Even when the shard has thousands of transitions. Logarithmic time is a wonderful thing.
Stop rounding
But if you are going to precompute all of the daylight savings time transitions in all the data on the shard, then why couldn't you precompute all of the "rounding points"? All of the keys for each bucket that a date_histogram could produce. When we were doing our "gloves off" rounding API we did all of the work to flow the minimum and maximum dates in the index into all of the right spots, so you could just start at the minimum and then get the next rounding value until you are past the maximum, stuff it into an array and binary search *that*. Then you wouldn't need to call the date rounding code at all. It turns out that this is always faster. Well, almost always. If you have a hand full of documents over a huge time range then it isn't. But it's pretty fast then too. Again, logarithmic time is a wonderful thing.
Start filtering
Slight tangent: @polyfractal had the idea that you could speed up the range aggregation by looking at the search index instead of the doc values. It showed a pretty compelling speed bump but we didn't want to merge the prototype because it would be expensive to maintain and folks don't use the range aggregation all that much.
But we realized that if you've precomputed all of the "rounding points" for a date_histogram you can turn it into a range aggregation. And if you use the search index for that range aggregation just as @polyfractal's prototype did you get an 8x speed boost. And it's worth maintaining the optimization for the range aggregation now that it's powering an optimization for the date_histogram aggregation.
This is the first time we've turned one aggregation into another one to execute it more efficiently. And we're actually doing it twice. We turn the date_histogram into a range aggregation and then we turn the range aggregation into a filters aggregation. The filters aggregation has never been super duper quick. So we wrote a "filter by filter" execution mode for it that produces the correct results in some cases and we just don't use it in the other cases. So the sequence of events goes like this:
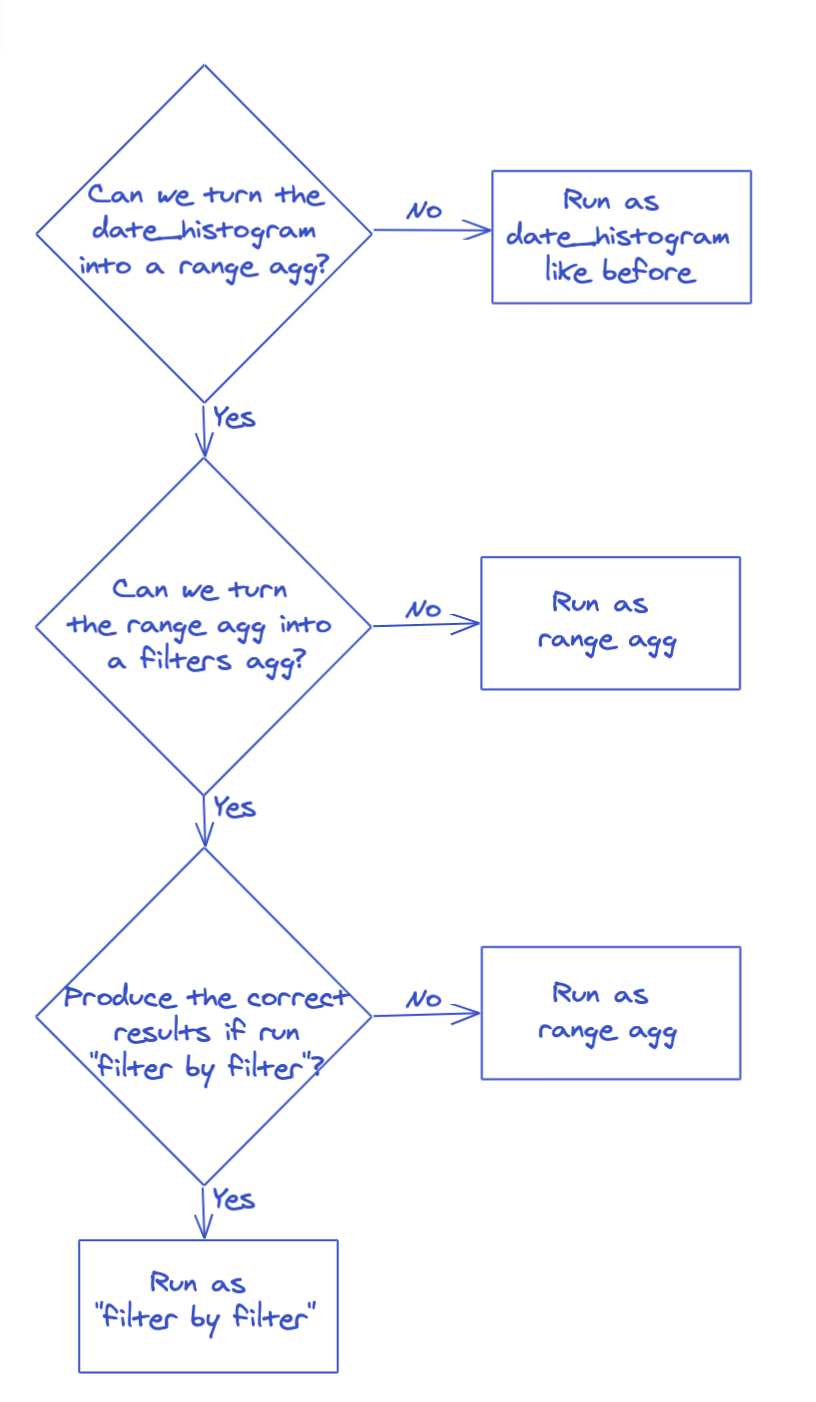
Why this works
The neat thing about this is that you can get on the "optimization train" at any stop along the way. range aggregations will check if they can run "filter by filter". So will filter aggregations.
It doesn't have the maintenance burden that the range specific optimization had because we only have to maintain the new "filter by filter" execution mechanism and the aggregation rewrites. And we can probably speed up more aggs with other rewrites. Could we rewrite terms aggregations into filters aggregations and get the same optimization? Probably! Can we optimize a terms aggregation inside of a date_histogram aggregation by thinking of it as a filters aggregation instead of another filters aggregation? Maybe. Could we do the geo-distance aggregation as ring shaped filters? Probably, but it might not actually be faster. Would it be worth doing even if it isn't inherently faster just to reduce the working set? It'll be fun to find out.
So this brave new world needs brave new benchmarks. We rely on JMH for microbenchmarks and Rally for our macrobenchmarks. We run Rally nightly and publish the results. But that is a story for another blog post.
Anway, it's fun to see your work make the graphs look better. It's been a fun trip overall. I've read more assembly in the past year than in the past 15 years combined. We always welcome contributions and if you want to get paid to contribute full time we're hiring. And you too can experience the exhilarating speed of "filter by filter" aggregations on Elastic Cloud the day Elasticsearch 7.11.0 is released.