通过 Elasticsearch、Kibana 和 Beats 监测 Kafka
我们最早于 2016 年发布了通过 Filebeat 监测 Kafka 的文章。6.5 推出以后,Beats 团队可以支持 Kafka 模块。这一模块能够自动完成监测 Kafka 集群时涉及的很多工作。
在本篇文章中,我们关注的是使用 Filebeat 和 Metricbeat 中的 Kafka 模块来收集日志和指标数据。我们会将数据采集到在 Elasticsearch Service 上托管的一个集群内,还会探索由 Beats 模块提供的 Kibana 仪表板。
我们在本篇博文中使用的是 Elastic Stack 7.1。我们还在 GitHub 上提供了一个示例环境。
为何使用模块?
Logstash Grok 筛选工具十分复杂,但凡用过的人都会因能通过一个 Filebeat 模块来无比轻松地设置日志收集方式而备感欣喜。在监测配置中使用模块还有一些其他好处:
- 简化日志和指标收集方式的配置过程
- 通过 Elastic Common Schema 对文档进行标准化
- 易于理解的索引模板,提供最佳字段数据类型
- 恰当的索引规模。Beats 通过 Rollover API 来确保 Beats 索引内分片的大小恰当。
请参阅文档了解 Filebeat 和 Metricbeat 支持的完整模块列表。
环境介绍
我们的示例配置是包括三个节点的 Kafka 集群(kafka0、kafka1 和 kafka2)。每个节点都运行 Kafka 2.1.1,同时还会使用 Filebeat和 Metricbeat 来监测节点状况。Beats 通过 Cloud ID 来配置,从而将数据发送到 Elasticsearch Service 集群。Filebeat 和 Metricbeat 中自带的 Kafka 模块可在 Kibana 中设置仪表板以实现可视化。备注,如果您希望在自己的集群中尝试完成此过程,可以在 14 天内免费试用 Elasticsearch Service,试用期间能体验所有炫酷功能。
设置 Beats
接下来,您将要配置并启动 Beats。
安装并启用 Beats 服务
我们将会按照《入门指南》中的说明来安装 Filebeat 和 Metricbeat。由于运行的是 Ubuntu,我们将会通过 APT 存储库来安装 Beats。
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list sudo apt-get update sudo apt-get install filebeat metricbeat systemctl enable filebeat.service systemctl enable metricbeat.service
配置 Elasticsearch Service 部署的 Cloud ID
从 Elastic Cloud 控制台中复制 Cloud ID,然后用其来配置 Filebeat 和 Metricbeat 的输出。
CLOUD_ID=Kafka_Monitoring:ZXVyb3BlLXdlc...
CLOUD_AUTH=elastic:password
filebeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/filebeat/filebeat.yml
metricbeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/metricbeat/metricbeat.yml
在 Filebeat 和 Metricbeat 中启用 Kafka 和 System(系统)模块
接下来,我们需要为 Filebeat 和 Metricbeat 启用 Kafka 和 System(系统)模块。
filebeat modules enable kafka system metricbeat modules enable kafka system
启用后,我们便可以运行 Beats 设置。这会配置模块所用的索引模板和 Kibana 仪表板。
filebeat setup -e --modules kafka,system metricbeat setup -e --modules kafka,system
启动 Beats!
好啦,现在一切配置完毕,我们来启动 Filebeat 和 Metricbeat。
systemctl start metricbeat.service systemctl start filebeat.service
探索监测数据
默认日志仪表板显示下列内容:
- Kafka 集群最近遇到的例外情况。例外情况会按照例外情况的类别和完整的例外情况详情来进行分组
- 按照级别显示日志概览,以及完整日志详情。
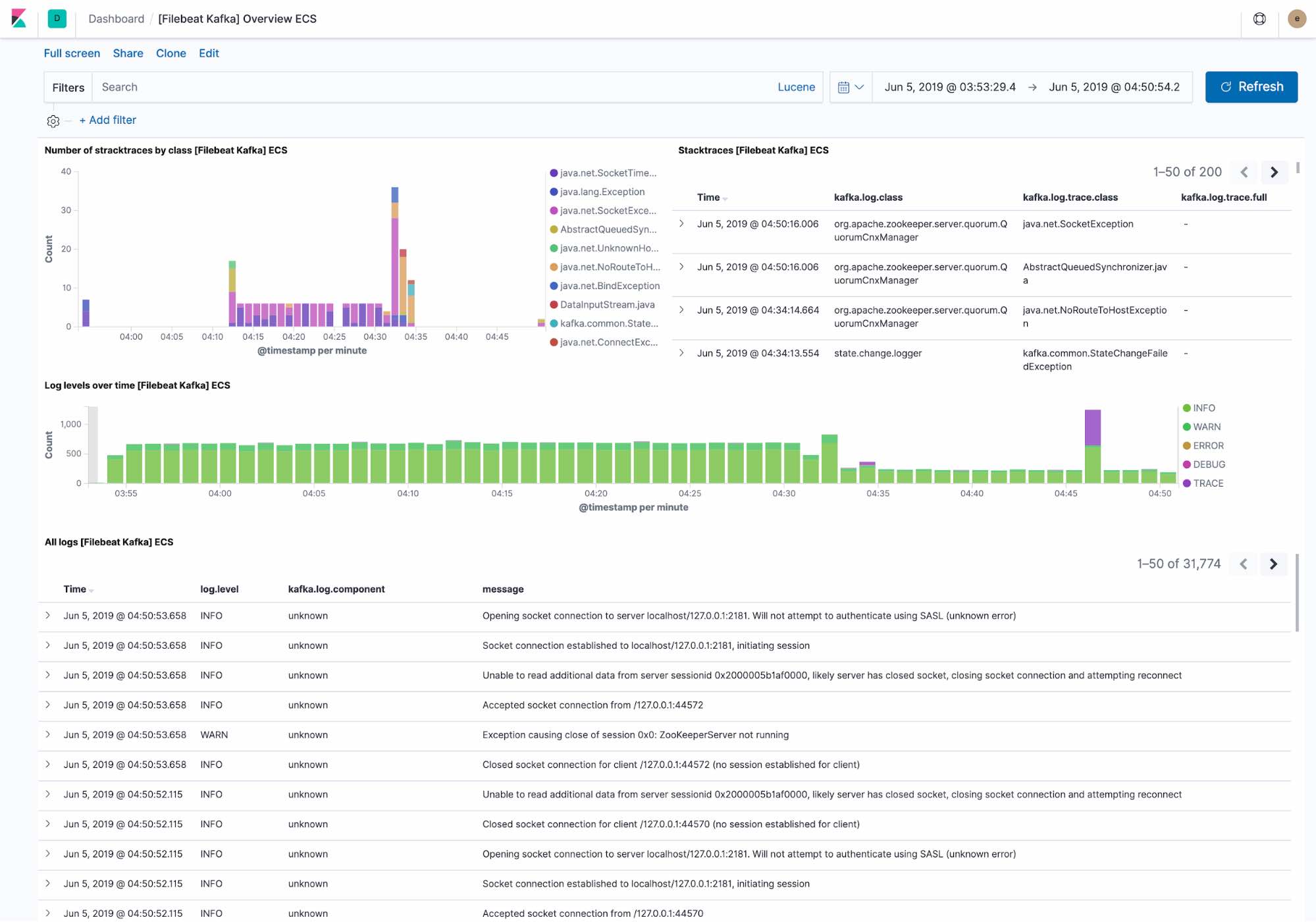
Filebeat 按照 Elastic Common Schema 来采集数据,允许我们一直将筛选条件细化到主机级别。
Metricbeat 提供的仪表板显示了 Kafka 集群内任何主题的当前状态。我们还提供下拉菜单来对仪表板进行筛选,从而仅保留一个主题。
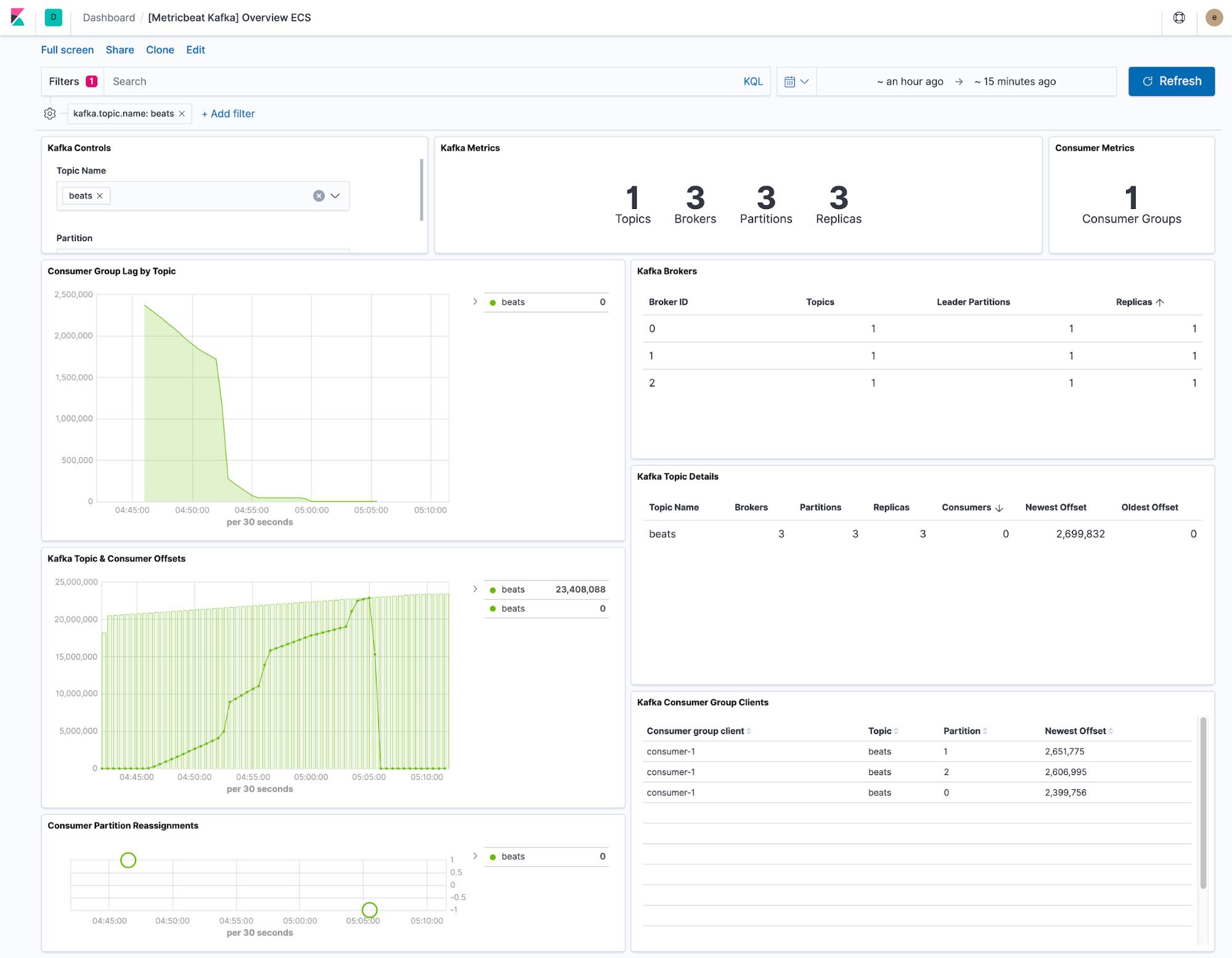
消费者延时和偏移量可视化会显示消费者在具体主题上是否落后。各分区偏移量还会显示单个分区是否落后。
Metricbeat 的默认配置会收集两个数据集,分别是 kafka.partition 和 kafka.consumergroup。通过这些数据集,您能获得 Kafka 集群及其消费者状态的相关洞见。
kafka.partition 数据集包括集群内分区状态的完整详情。这一数据能够用来:
- 构建仪表板,显示分区与集群节点之间的映射方式
- 对尚无同步副本分片的分区发送提醒
- 跟踪一段时间内的分区分配情况
- 对一段时间内的分区偏移量限值进行可视化。
完整的 kafka.partition 文档如下所示。

kafka.consumergroup 数据集会采集单个消费者的状态。这一数据可用来显示单个消费者正在从哪个分区读取内容,以及该消费者的当前偏移量。
