使用 Elastic Stack 和 Google Operations 监测 Google Cloud
Google Operations 套件(此前为 Stackdriver)是一个中央存储库,从 Google Cloud 资源接收日志、指标和应用程序跟踪数据。这些资源可以包括计算引擎、应用引擎、Dataflow、Dataproc 及其 SaaS 产品与服务,例如 BigQuery 等。 通过向 Elastic 传输该数据,就可以获得跨整个基础架构(从云端到本地部署)的统一资源性能视图。
本博文中,我们将建立一个从 Google Operations 到 Elastic Stack 的数据流式传输管道,便于您分析 Google Cloud 日志以及其他可观测性数据。本演示中,我们将使用 Filebeat Google Cloud 模块将 Google Cloud 数据传输到免费试用版 Elastic Cloud 中进行分析。大家要跟上哦!
高级别数据流
本演示中,我们将从 Google Cloud 资源向 Google Cloud Operations 传输审计、防火墙和 VPC 流日志。接着我们将创建接收器、Pub/Sub 主题,由 Filebeat 订阅,并将数据传输到 Elastic Cloud,再使用 Elasticsearch 和 Kibana 做进一步的分析。此示意图提供了数据流概览,说明了数据进入我们集群的路径:
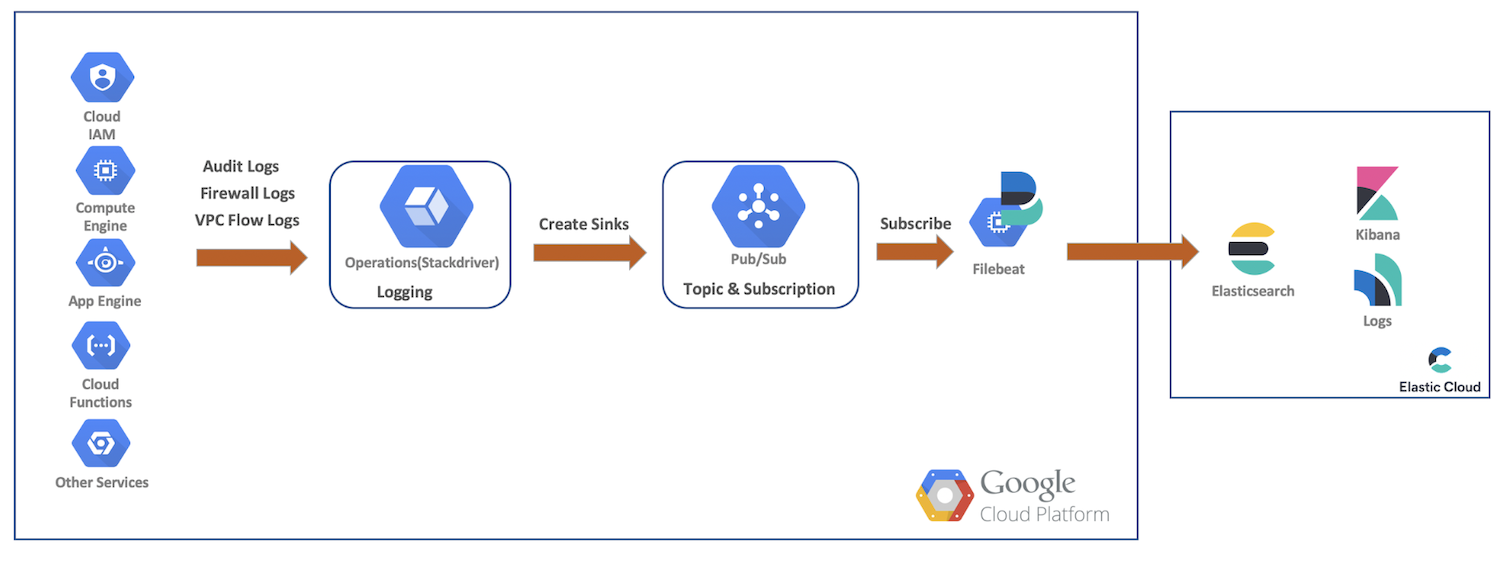
Google Cloud 日志设置和配置
Google Cloud 为启用服务日志提供一个富 UI,而这些日志都会在独立的控制台中进行配置。在下面的步骤中,我们将启用多个日志,创建接收器和主题,然后设置服务账号和凭据。
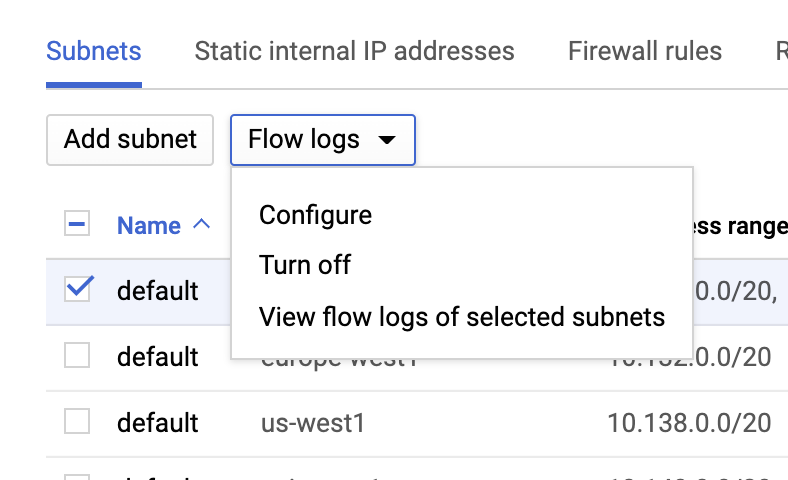
VPC 流日志
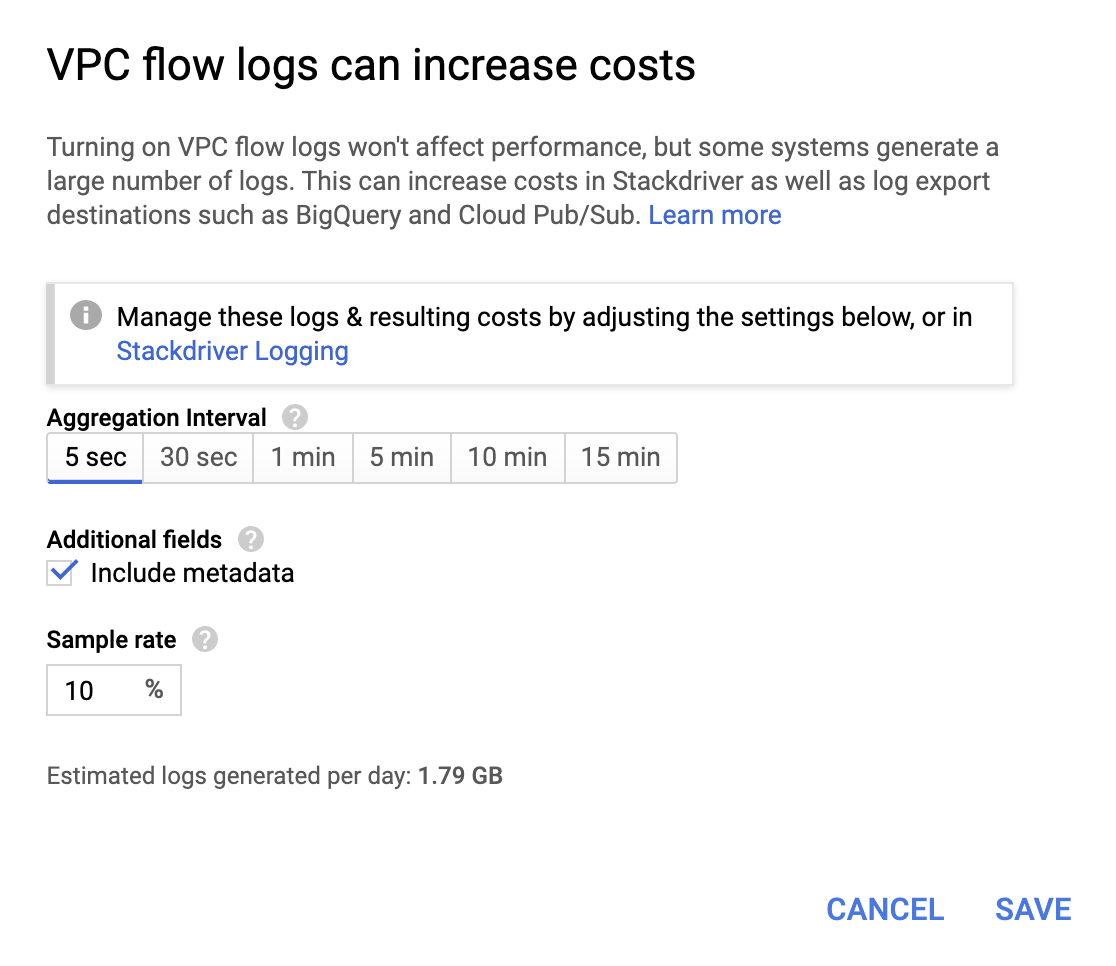
进入 VPC 网络页面,选择一个 VPC,然后从流日志下拉列表中单击配置,即可启用 VPC 流日志。
虽然价格不是特别昂贵,但运维本身也会增加成本,所以请根据自己的要求选择聚合时间间隔和采样速率。
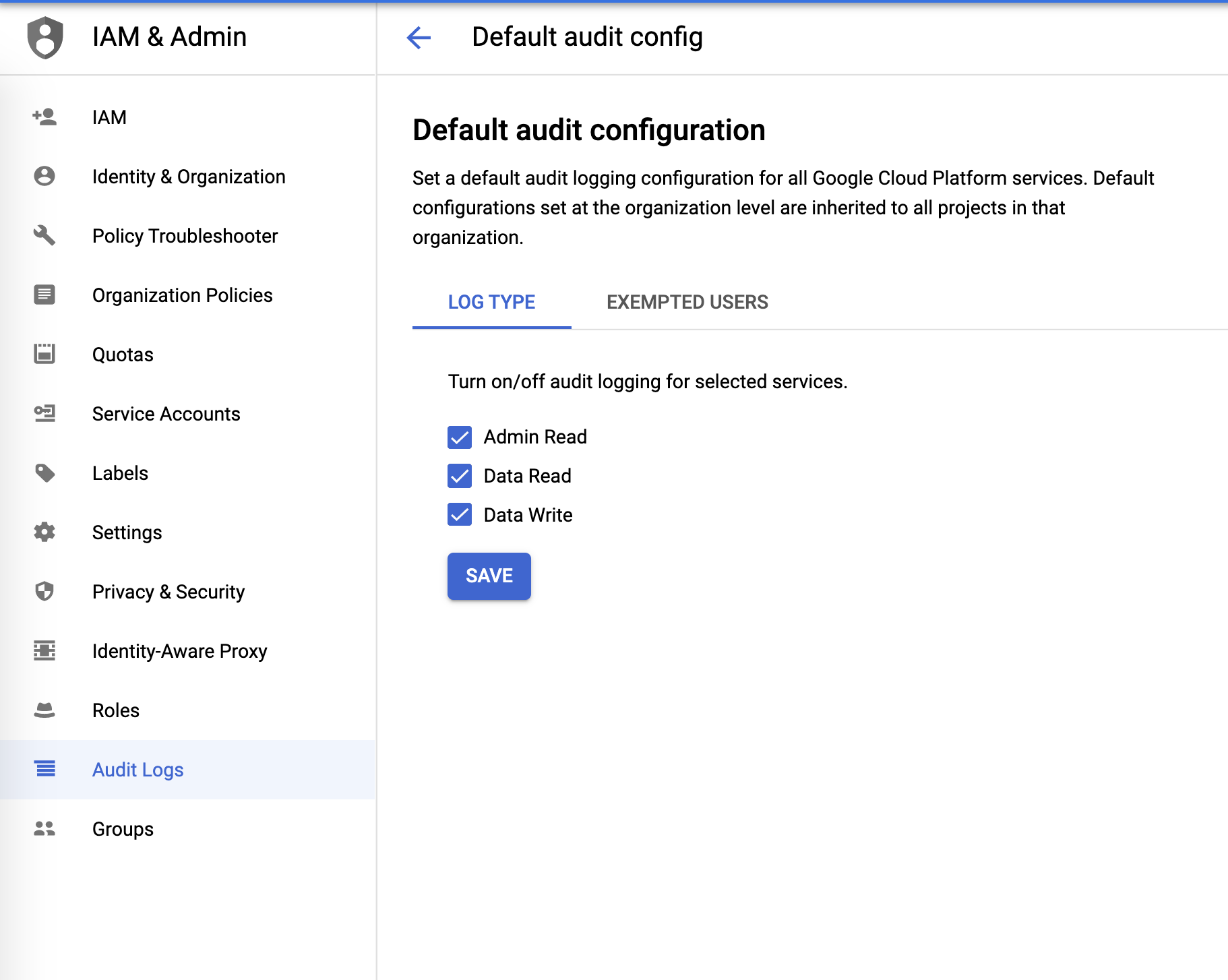
审计日志
审计日志可以在 IAM 和管理菜单中进行配置:
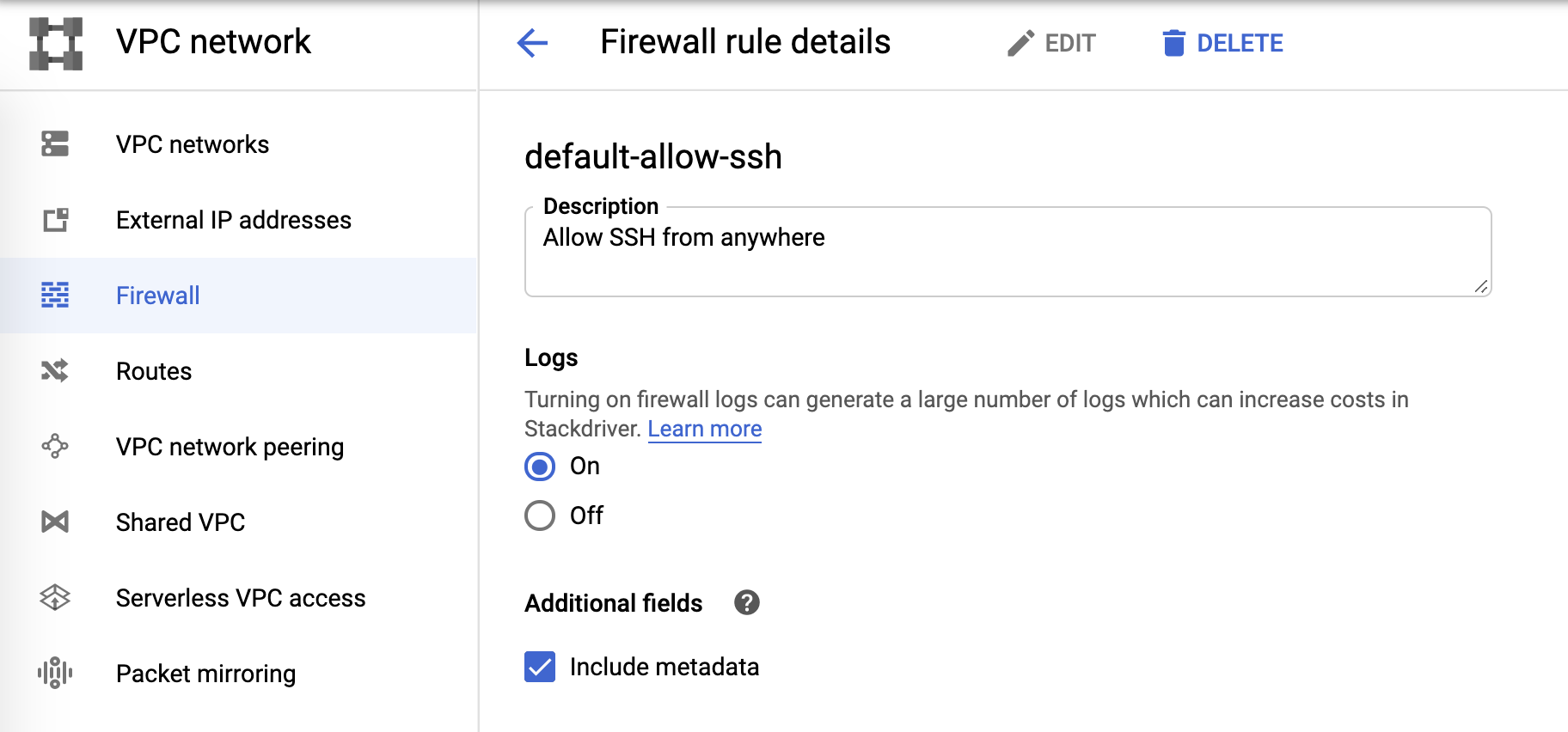
防火墙日志
最后,防火墙日志可在防火墙规则中进行控制:
日志接收器和 Pub/Sub
配置完成各日志区域后,便可在日志查看器中为每个日志创建接收器:

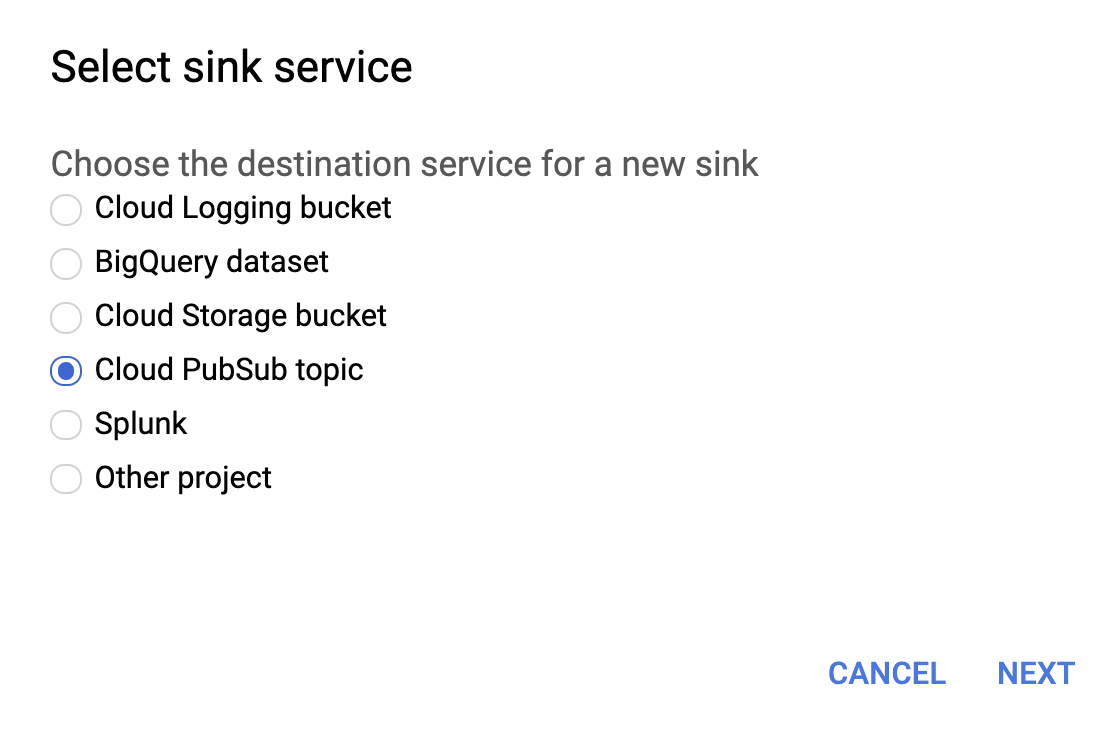
如下所示,为接收器服务选择 Cloud PubSub 主题。
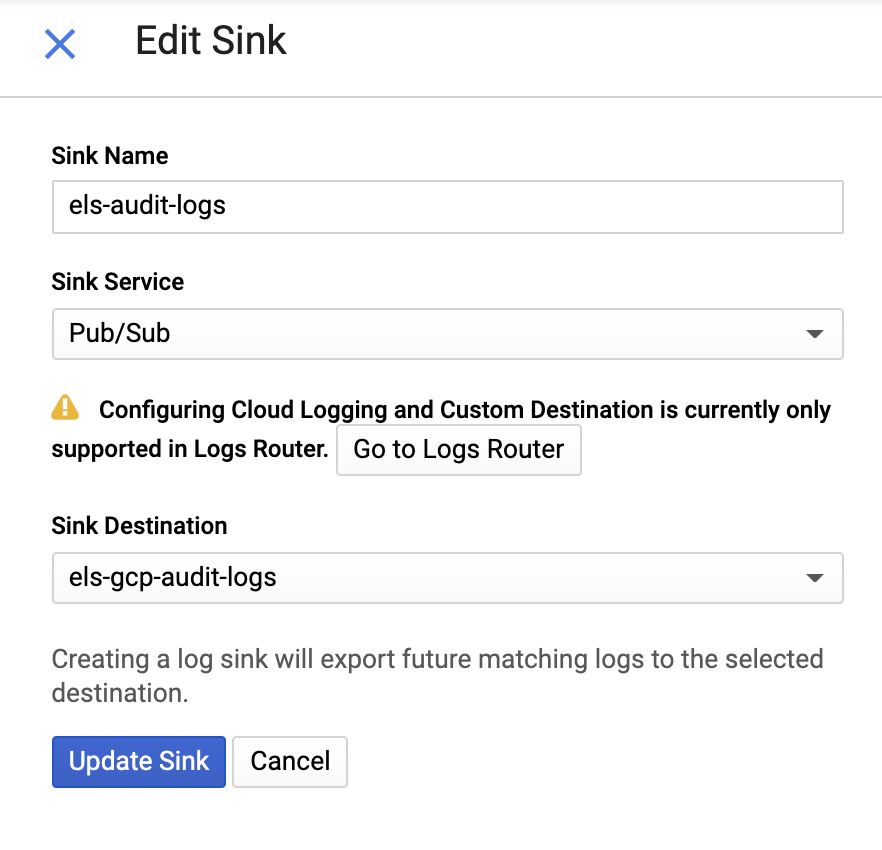
然后提供接收器名称和 Pub/Sub 主题,可以将其发送至已有主题,也可以创建新主题:
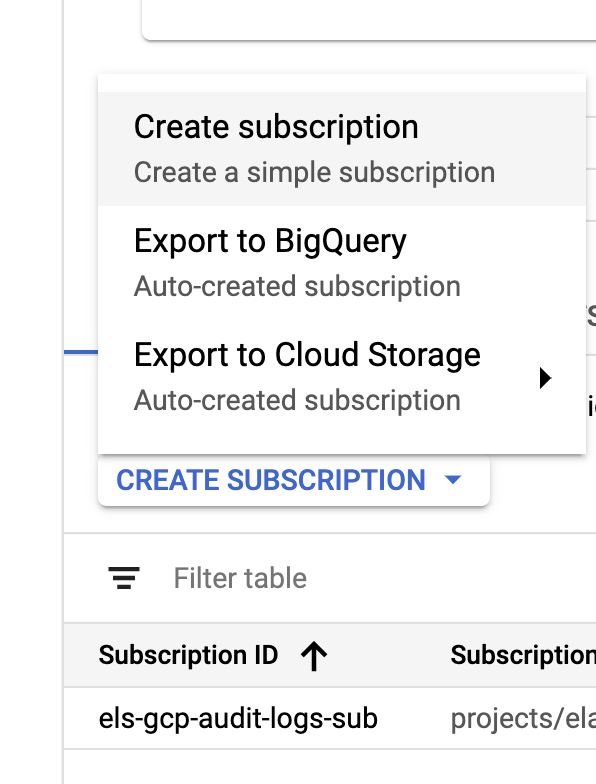
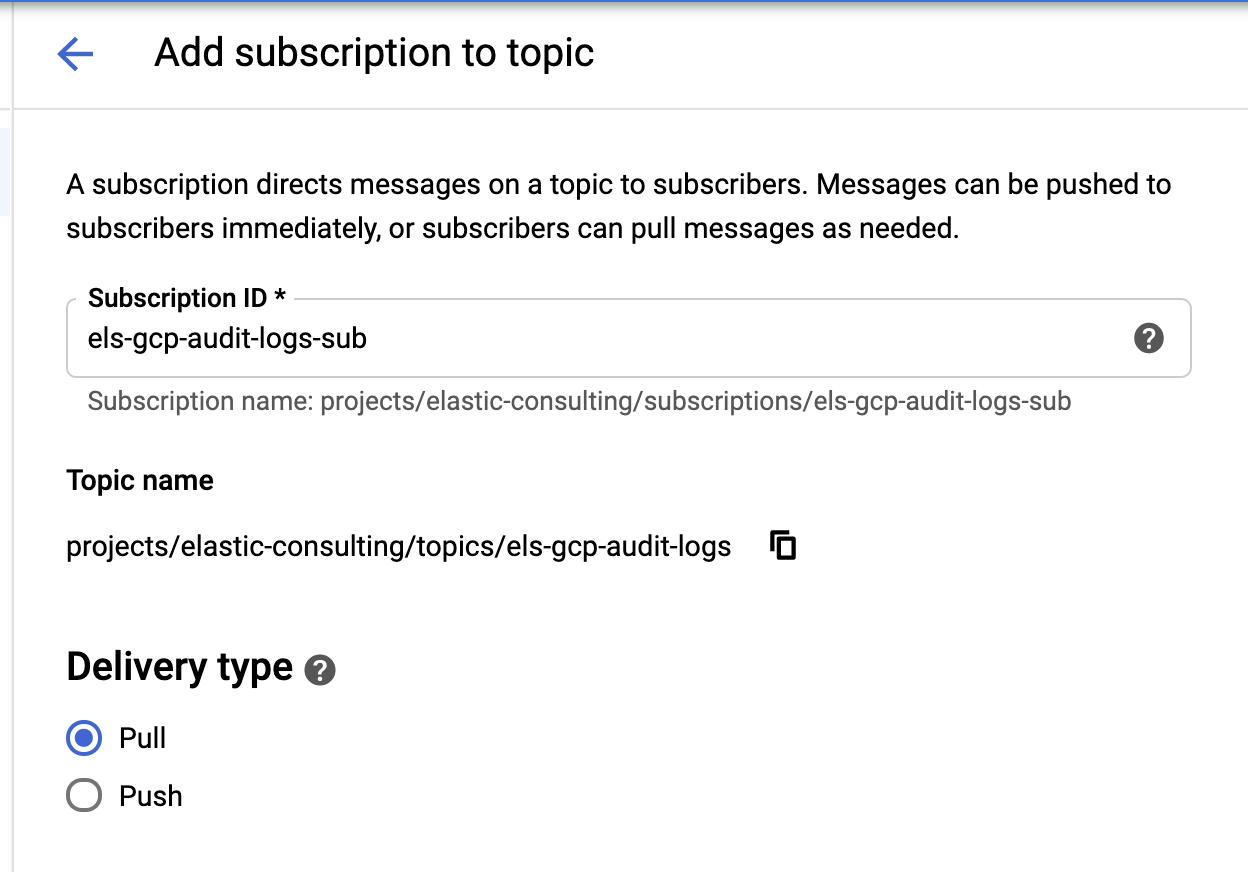
接收器和主题创建完成后,下面开始创建 Pub/Sub 主题订阅:
| 
|
根据您的要求配置订阅。
服务账号和凭据
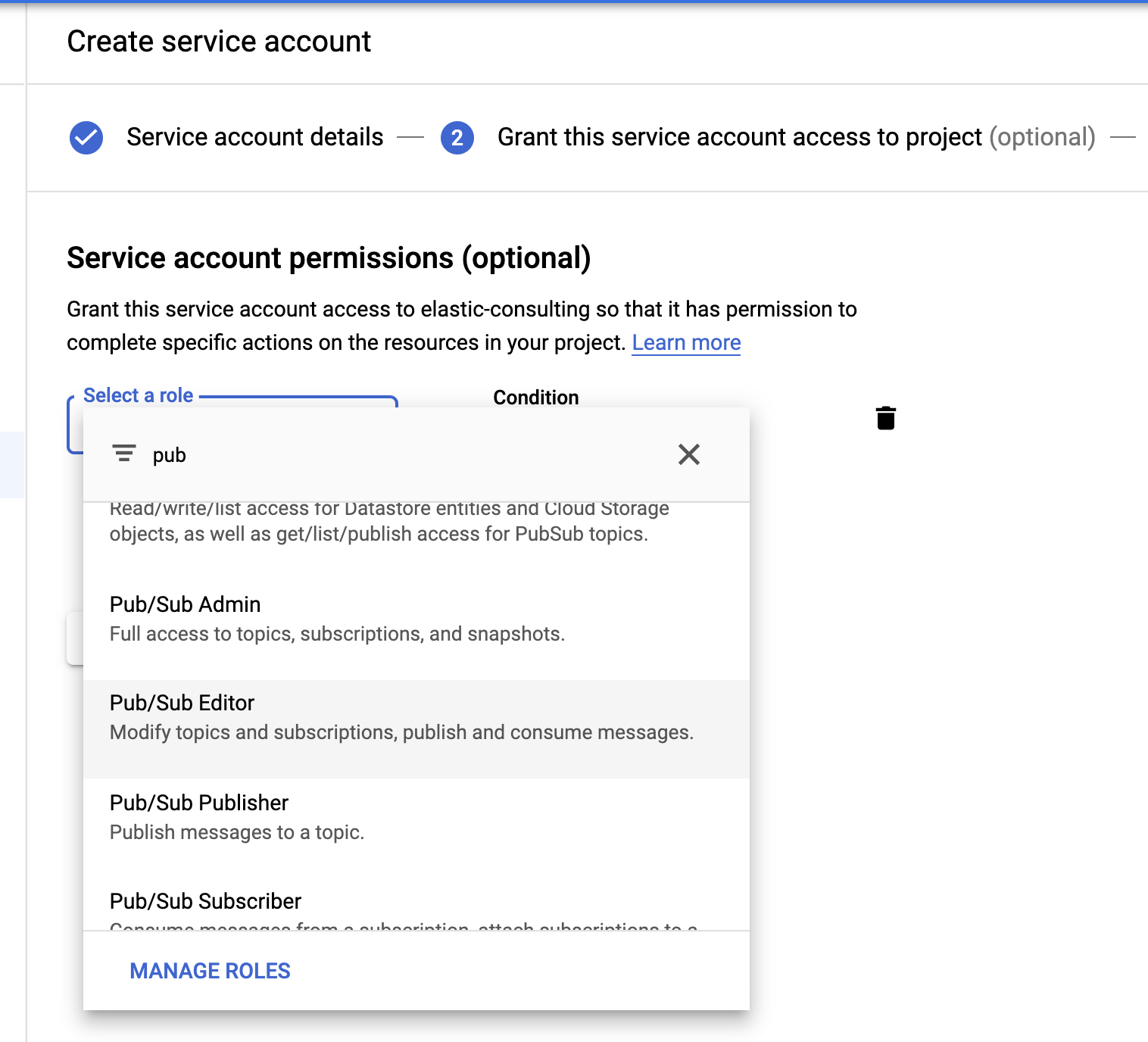
最后但也很重要,我们要创建一个服务账号和凭据文件。
选择 Pub/Sub 编辑器角色;条件可选并可用于筛选主题。
服务账号创建完成后,我们将生成一个 JSON 密钥,上传至 Filebeat 主机,并存储在 Filebeat 配置目录 /etc/filebeat 中。Filebeat 将使用该密钥来验证服务账号。

现在我们已经完成了 Google Cloud 配置。
安装和配置 Filebeat
Filebeat 用于收集日志并传输到我们的 Elasticsearch 集群中。在本博文中,我们将使用 CentOS,但您也可以根据自己的操作系统安装 Filebeat,只需按照我们 Filebeat 文档中的简单步骤操作即可。
启用 Google Cloud 模块
Filebeat 安装完成后,我们需要启用 googlecloud 模块:
filebeat modules enable googlecloud
将此前创建的 JSON 凭据文件复制到 /etc/filebeat/,然后修改 /etc/filebeat/modules.d/googlecloud.yml 文件,使之匹配您的 Google Cloud 设置。
部分配置已完成;例如所有三个模块均已列出,所有需要的配置也已键入,您只需要根据自己的设置更新成相应的值即可。
# 模块:googlecloud
# 文档:https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-module-googlecloud.html
- module: googlecloud
vpcflow:
enabled: true
# Google Cloud 项目 ID。
var.project_id: els-dummy
# 包含 VPC 流日志的 Google Pub/Sub 主题。Stackdriver 必须
# 加以配置,将该主题用作 VPC 流日志的接收器。
var.topic: els-gcp-vpc-flow-logs
# 针对该主题的 Google Pub/Sub 订阅。Filebeat 将创建
# 该订阅(如果订阅不存在)。
var.subscription_name: els-gcp-vpc-flow-logs-sub
# 针对服务账号的凭据文件,以及
# 订阅读取授权。
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
firewall:
enabled: true
# Google Cloud 项目 ID。
var.project_id: els-dummy
# 包含防火墙日志的 Google Pub/Sub 主题。Stackdriver 必须
# 加以配置,将该主题用作防火墙日志的接收器。
var.topic: els-gcp-firewall-logs
# 针对该主题的 Google Pub/Sub 订阅。Filebeat 将创建
# 该订阅(如果订阅不存在)。
var.subscription_name: els-gcp-firewall-logs-sub
# 针对服务账号的凭据文件,以及
# 订阅读取授权。
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
audit:
enabled: true
# Google Cloud 项目 ID。
var.project_id: els-dummy
# 包含审计日志的 Google Pub/Sub 主题。Stackdriver 必须
# 加以配置,将该主题用作防火墙日志的接收器。
var.topic: els-gcp-audit-logs
# 针对该主题的 Google Pub/Sub 订阅。Filebeat 将创建
# 该订阅(如果订阅不存在)。
var.subscription_name: els-gcp-audit-logs-sub
# 针对服务账号的凭据文件,以及
# 订阅读取授权。
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
最后是配置 Filebeat,使之指向您的 Kibana 和 Elasticsearch 终端。
可按照 Kibana 和 Elasticsearch 终端文档,在 filebeat.yml 文件中设置 setup.dashboards.enabled: true,以便加载适用于 Google Cloud 的预创建仪表板。
请注意,Filebeat 提供各种配有预创建仪表板的模块。本博文中我们只看一下 Google Cloud 模块的情况,但您完全可以探索其他可用 Filebeat 模块,了解可能适用于自己的资源。
启动 Filebeat
最后,我们可以启动 Filebeat,并添加 -e 旗标,使之轻松将日志输出至控制台:
sudo service filebeat start -e
Kibana 中的数据探索
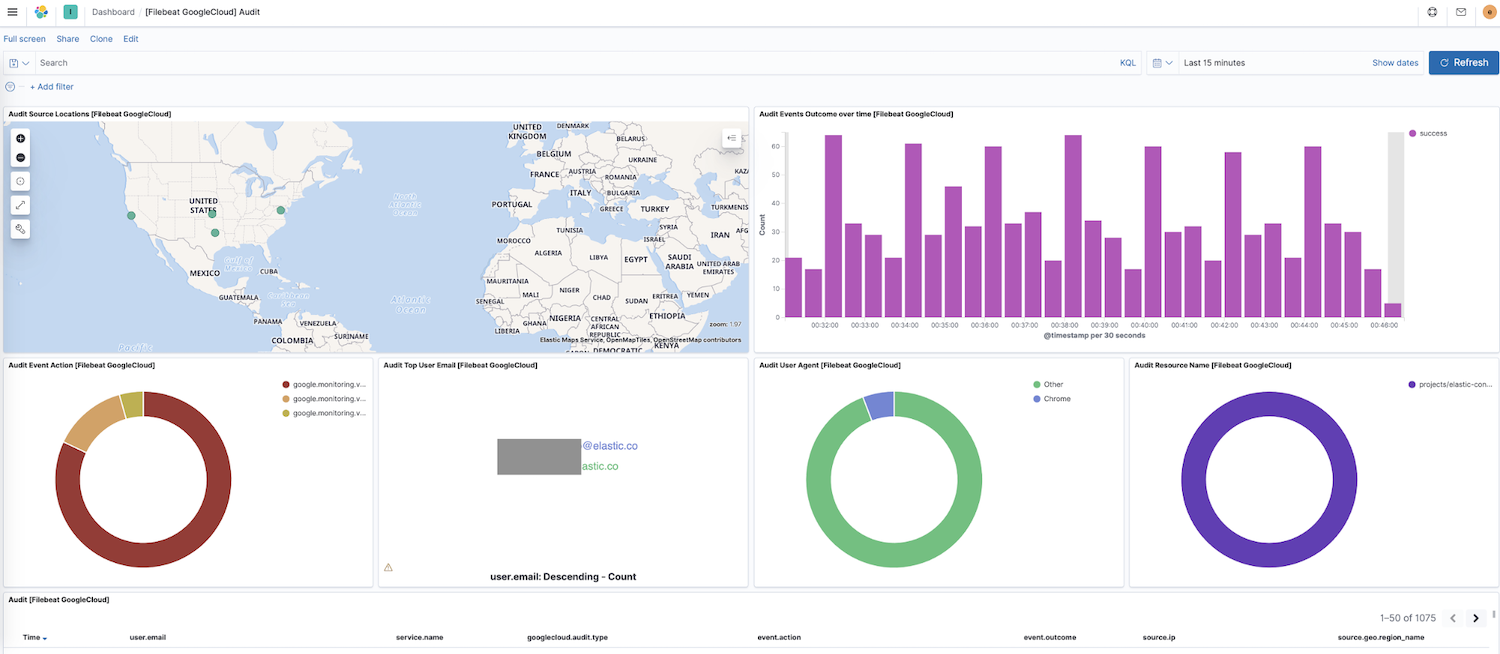
现在 Filebeat 正在向您的集群传输数据,我们在 Kibana 边栏导航中找到仪表板,如果有其他模块的仪表板,可以搜索 google 找到新启用模块的仪表板。本例中,我们将看到 Google Cloud“审计”仪表板。
此仪表板中您会看到源位置动态映射、随时间推移的事件结果、事件操作细目等可视化内容。通过这些预创建的交互型可视化内容,可非常直观地探索日志数据。如果是首次设置 Filebeat,或者运行较老版本的 Elastic Stack(Google Cloud 模块在 7.7 GA 版本中就已添加),则需要按照以下说明下载仪表板。
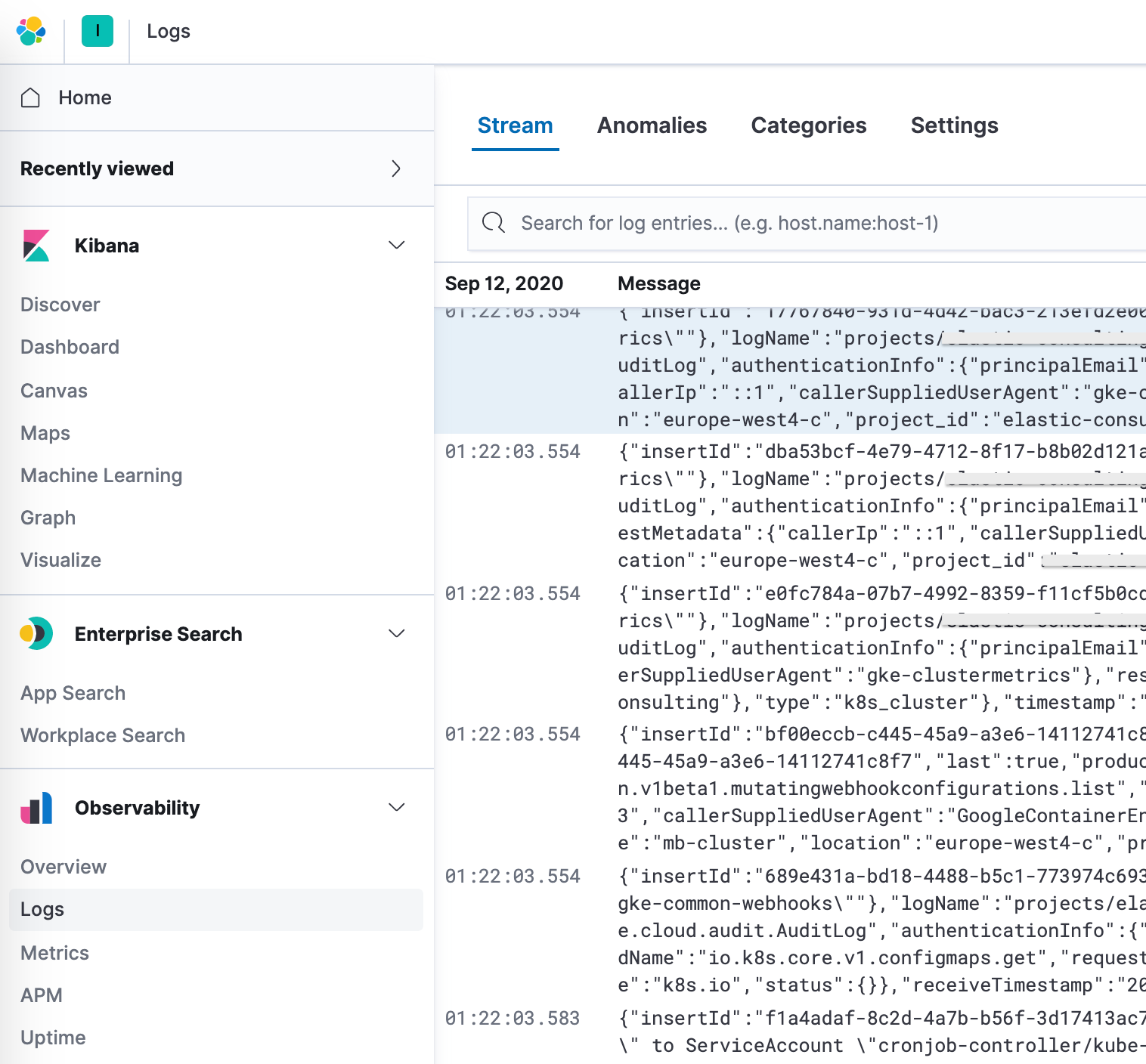
此外,Elastic 还通过日志监测应用程序提供可观测性解决方案。日志索引可进行配置;默认值为 filebeat-* 和 logs-*。
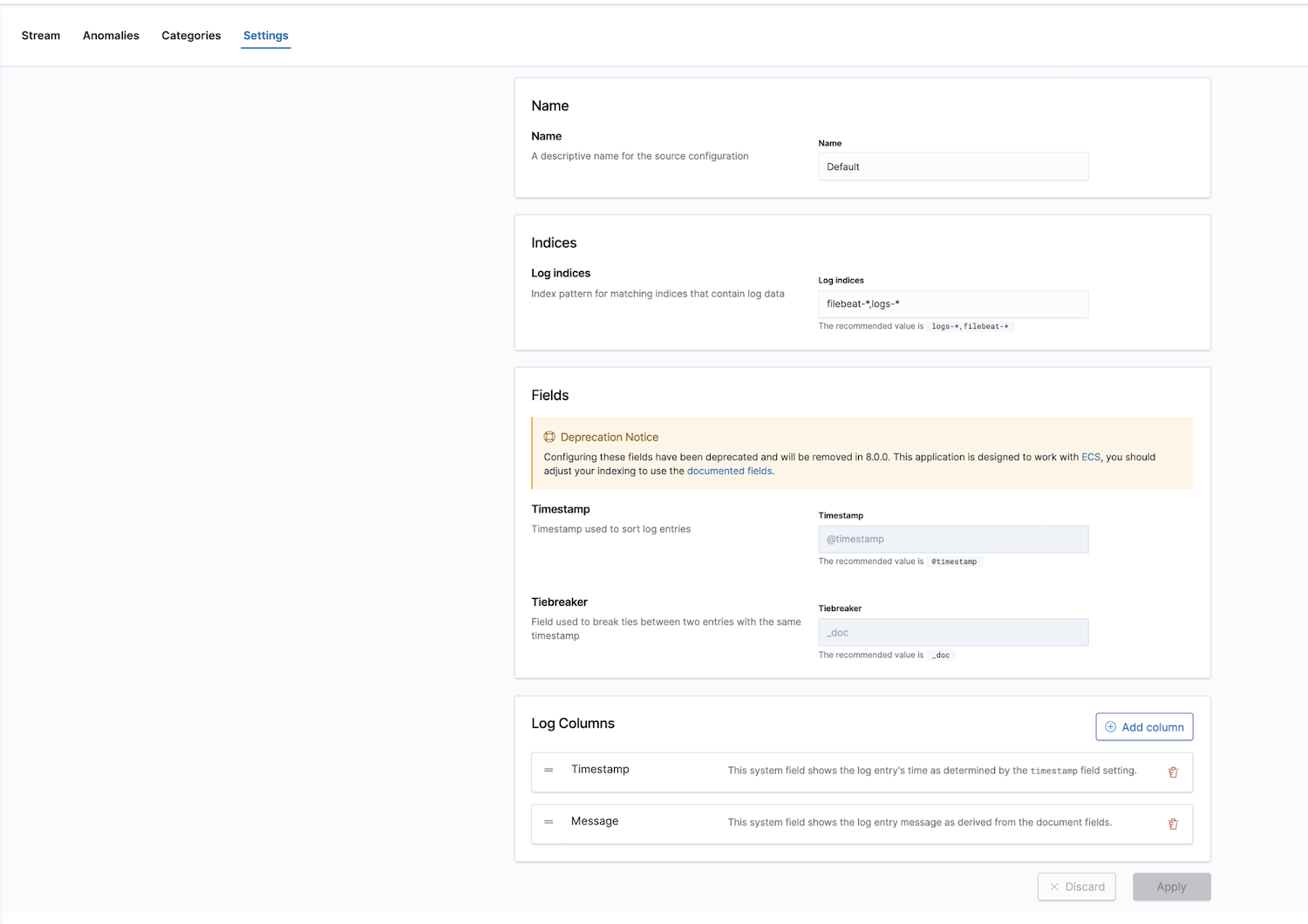
在设置中配置完成正确的索引模式后,便可以在 Logs 应用中探索日志,其允许查看日志详细信息,更重要的是,还可以为异常行为定义 Machine Learning 工作、分类数据并创建警报。
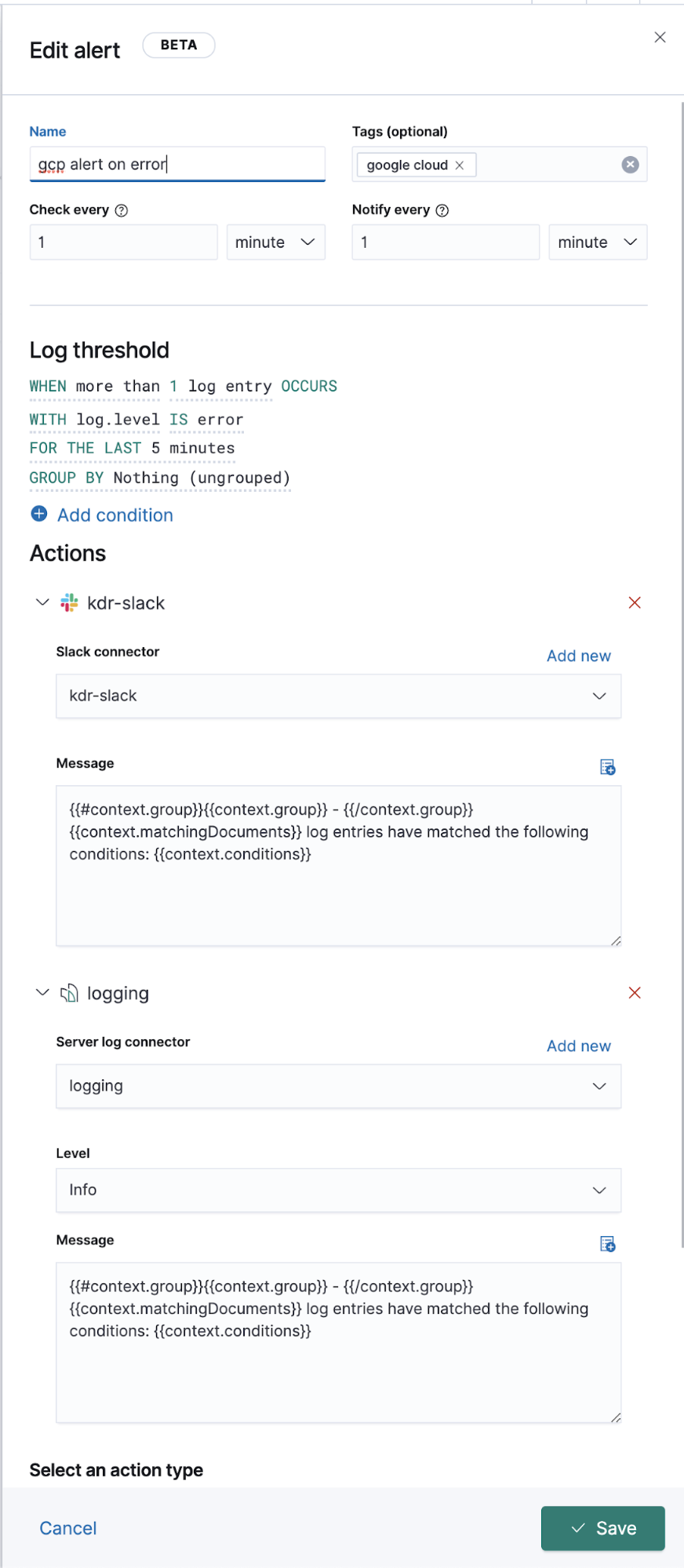
拓展 Google Operations (stackdriver) 日志
上面我们讨论了如何为那些具有 Filebeat 模块的日志传输运维日志,但其他没有专属 Filebeat 模块的日志呢?接下来我们讨论如何将这些日志也传输到 Elastic 中,以便与其他日志数据一同查看。
从 Google Cloud 设置和配置角度而言,包括流在内的所有内容都没有变动。我们创建接收器、主题、订阅、sa 以及 JSON 密钥。差别仅在于 Filebeat 配置上。
后台运行时,模块的运行要依靠输入和预配置、来源级别解析以及某些情况下的采集管道。Filebeat 模块会简化常见日志格式的收集、解析和可视化,但对于 Filebeat 输入,有时则需要额外解析。
googlecloud 模块使用底层的 google-pubsub 输入,并提供一些模块特定的采集管道。它支持直接使用 vpcflow、audit和防火墙日志。
配置
我们将使用 Filebeat 输入来订阅这些主题,而不是 Filebeat 模块。
向您的 filebeat.yml 文件中添加:
filebeat.inputs: - type: google-pubsub enabled: true pipeline: gcp-pubsub-parse-message-field tags: ["gcp-pubsub"] project_id: elastic-consulting topic: gcp-gke-container-logs subscription.name: gcp-gke-container-logs-sub credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
我们在该输入中指定拉取的主题以及要使用的订阅。同时也指定随后会定义的凭据文件和采集管道。
采集管道
采集管道就是一系列按照声明的相同顺序而执行的处理器。
Google Cloud Operations 是以 JSON 格式存储日志和消息体,也意味着只需要在管道中添加一个 JSON 处理器,就可以将消息字段中的数据提取到 Elasticsearch 的单独字段。
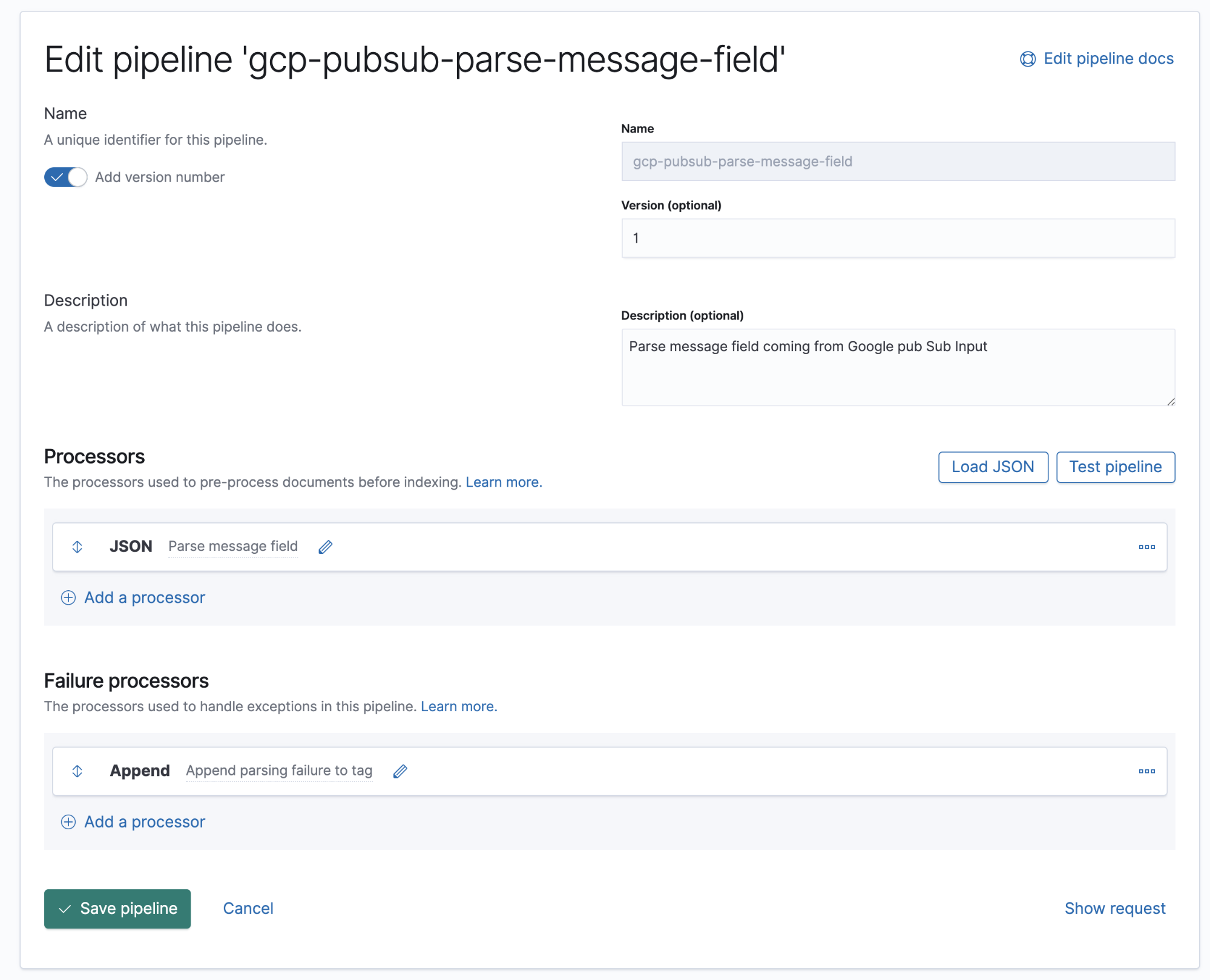
在该管道中,我们有一个 JSON 处理器,其从文件消息字段中收集数据,并提取到称为日志的目标字段中。
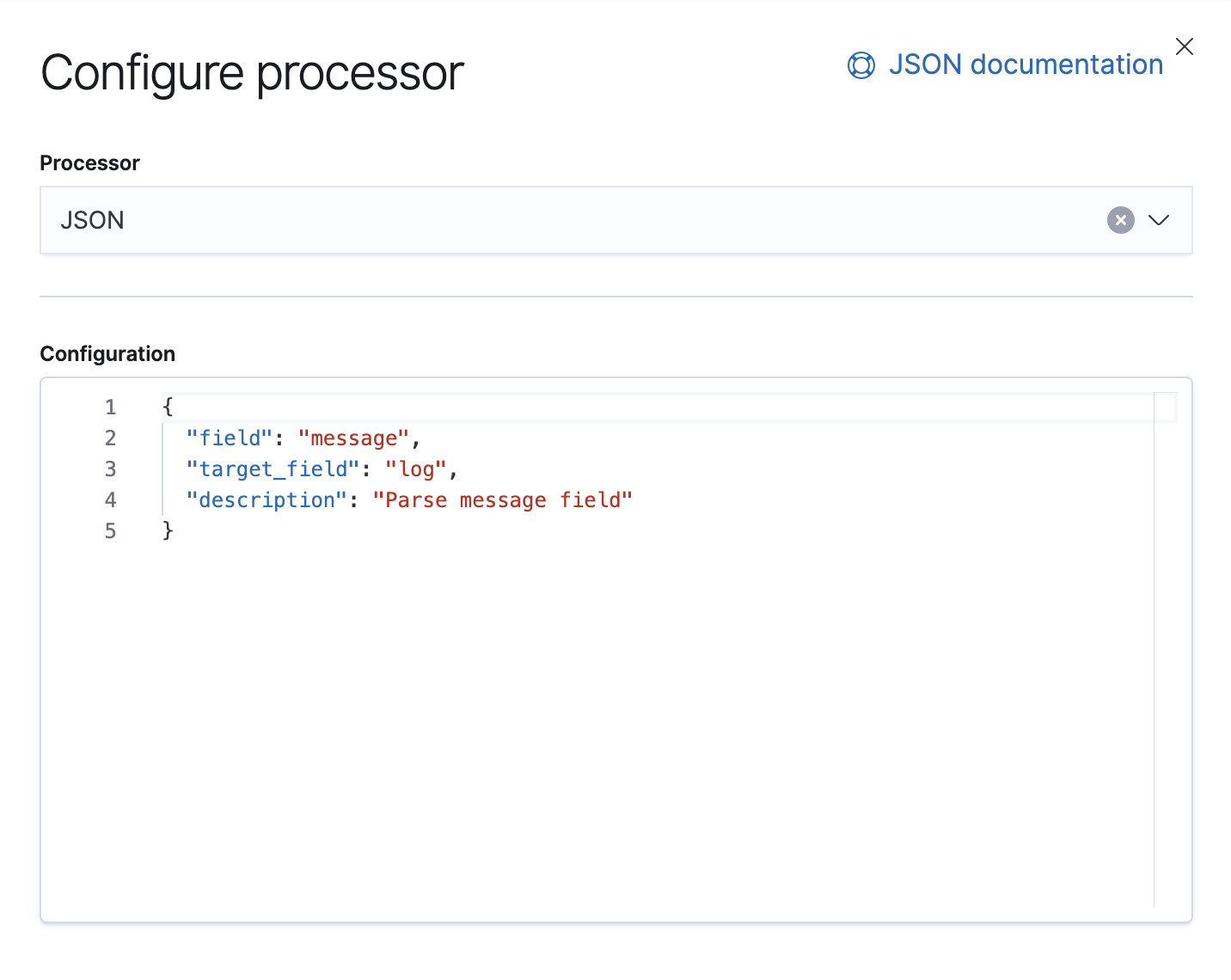
同时还有一个 Failure 处理器,用于处理该管道中的异常,我们在这里附加一个标签。
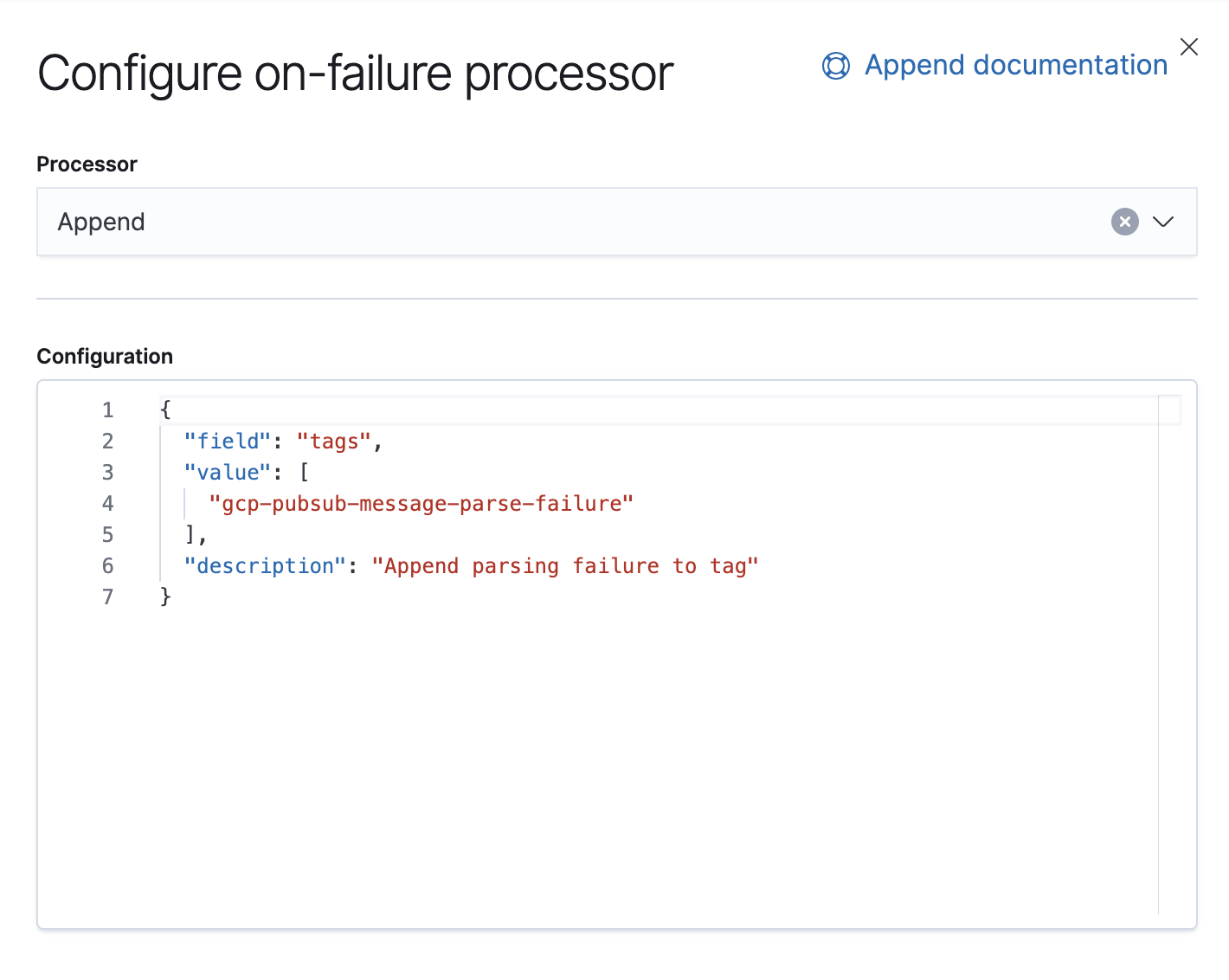
从 7.8 版本开始,就已经支持从 Kibana 的 UI 创建采集管道,路径为 Stack Management → Ingest Node Pipelines。如果使用的是较早期版本,可使用 API。以下是该管道适用的等效 API。
PUT _ingest/pipeline/gcp-pubsub-parse-message-field
{
"version":1,
"description":"Parse message field coming from Google pub Sub Input",
"processors": [
{
"json": {
"field": "message",
"target_field": "log",
"description":"Parse message field"
}
}
],
"on_failure": [
{
"append": {
"field": "tags",
"value": [
"gcp-pubsub-message-parse-failure"
],
"description":"Append parsing failure to tag"
}
}
]
}
我们将保存此管道,只要在 google-pubsub 输入中配置有相同的管道,便可在 Kibana 中开始查看解析的日志。
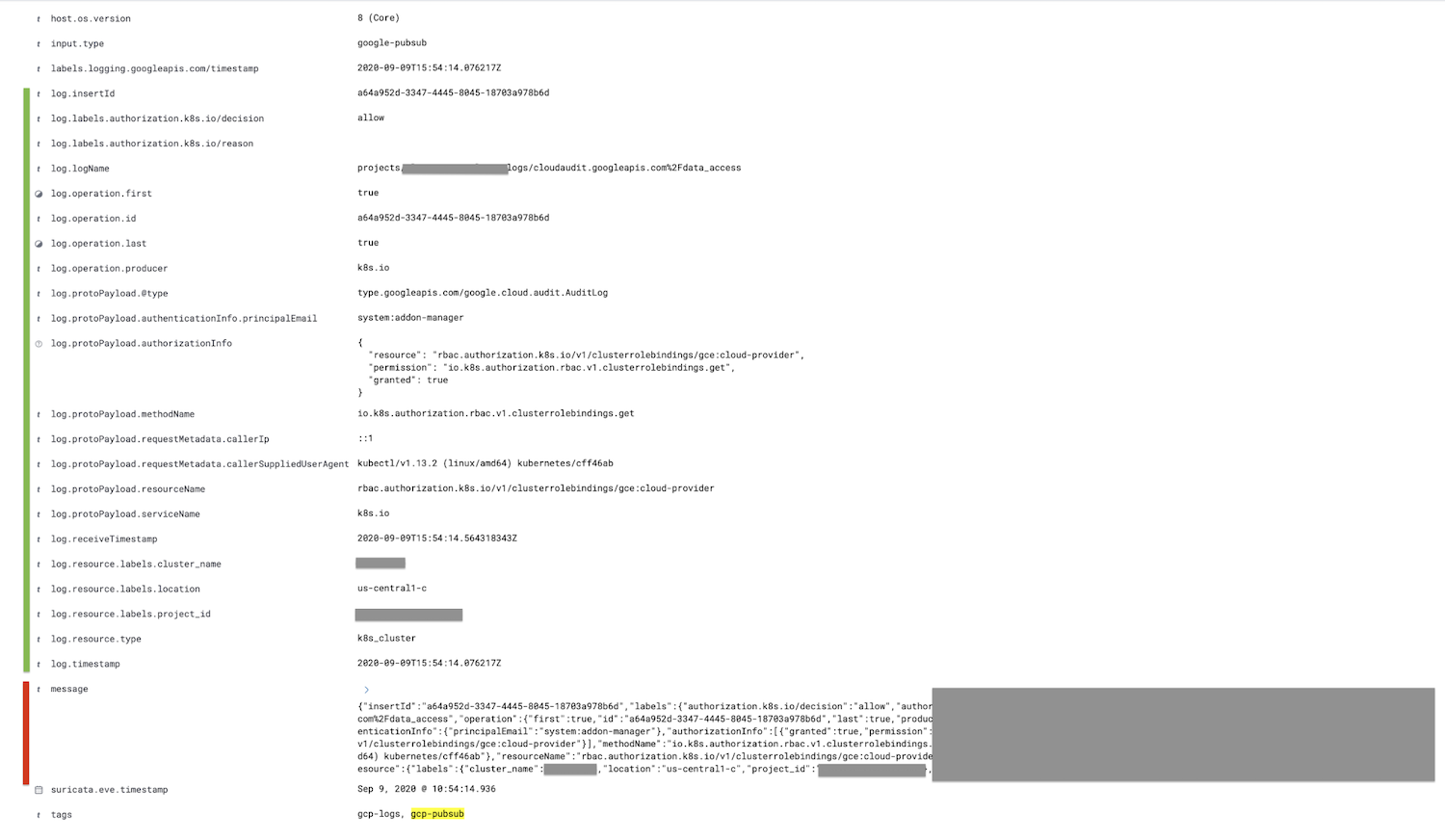
标记为红色的字段(消息字段)将解析到日志字段中,所有子字段将被进一步嵌套,标记为绿色。
也可以选择使用删除处理器,删除采集管道 JSON 中处理器之后的消息字段;如此可缩小文件大小。
总结
以上就是本博文的全部内容,感谢阅读。如有问题,请在我们的讨论论坛中进行交流;欢迎提问。或者可以在我们的点播网络研讨会中深入了解 Elastic 日志和可观测性相关内容。
如果想要尝试本演示操作,可在 Elastic Cloud 上注册免费试用版 Elasticsearch Service 或者下载最新版本自行管理。