网络安全中的 Machine Learning:检测网络数据中的 DGA 活动
在本系列博客的第 1 部分,我们探讨了如何使用 Elastic Stack Machine Learning 来训练一个监督式分类模型,用以检测恶意域名。在第 2 部分中,我们将了解如何使用我们训练的这个模型在采集时使用分类扩充网络数据。这对于想要在 Packetbeat 数据中检测潜在 DGA 活动的用户非常有用。
借助 Elastic Stack 进行 DGA 检测
感染计算机的恶意程序通常需要一种回传途径来联系攻击者控制的服务器,也就是所谓的命令及控制(C&C 或 C2)服务器。为了阻挠防御措施拦截任何硬编码的 IP 地址或 URL,攻击者会使用域名生成算法 (DGA)。当恶意软件需要联系 C&C 服务器时,它会使用 DGA 生成数百上千的候选域名,并尝试解析每个域名的 IP 地址。然后,攻击者只需注册 DGA 生成的一个或几个域名,就能与受感染的计算机进行通信。DGA 以不同的方式进行播种和随机分配,使防御者更加难以阻止和发现它们。
因为 DGA 活动通常涉及到 DNS 查询,所以它通常会表现在从受感染的计算机发出的 DNS 请求中。Packetbeat 可以收集 DNS 流量并将其发送到 Elasticsearch 进行分析。在本博文中,我们将了解如何扩充 Packetbeat 数据中的 DNS 查询信息,用分数来指示域名的恶意程度。

推理处理器和采集管道
为了基于一个经过训练、可区分良性域名和恶意域名的模型生成的预测来扩充 Packetbeat 数据,我们将需要使用合适的推理处理器来配置采集管道。推理处理器为用户提供了一种方法,可以使用在 Elastic Stack 中经过训练的模型(或在我们支持的外部库中经过训练的模型),对要被采集到 Elasticsearch 中的新文档进行预测。为了了解所有这些活动组件是如何组合在一起的,以及需要进行哪些配置,让我们简单回顾一下本系列博客的第 1 部分。
在第 1 部分中,我们讨论了如何训练分类模型来预测给定域名是否为恶意的过程。该过程中的一个步骤就是对训练数据(一组已知的恶意域名和良性域名)执行特征工程,我们的模型将基于这些数据来学习如何对以前未见过的新域名进行评分。必须对原始域名加以处理,以提取对模型有用的特征:一元语法、二元语法和三元语法。然后,同样的特征工程步骤也必须应用到我们希望对恶意性进行评分的 Packetbeat 数据中的域名。
因此,除了推理处理器之外,我们的采集管道还将包括 Painless 脚本处理器,以便在采集时从 Packetbeat DNS 数据中提取一元语法、二元语法和三元语法。图 2 所示为一个具有完整管道的图表。
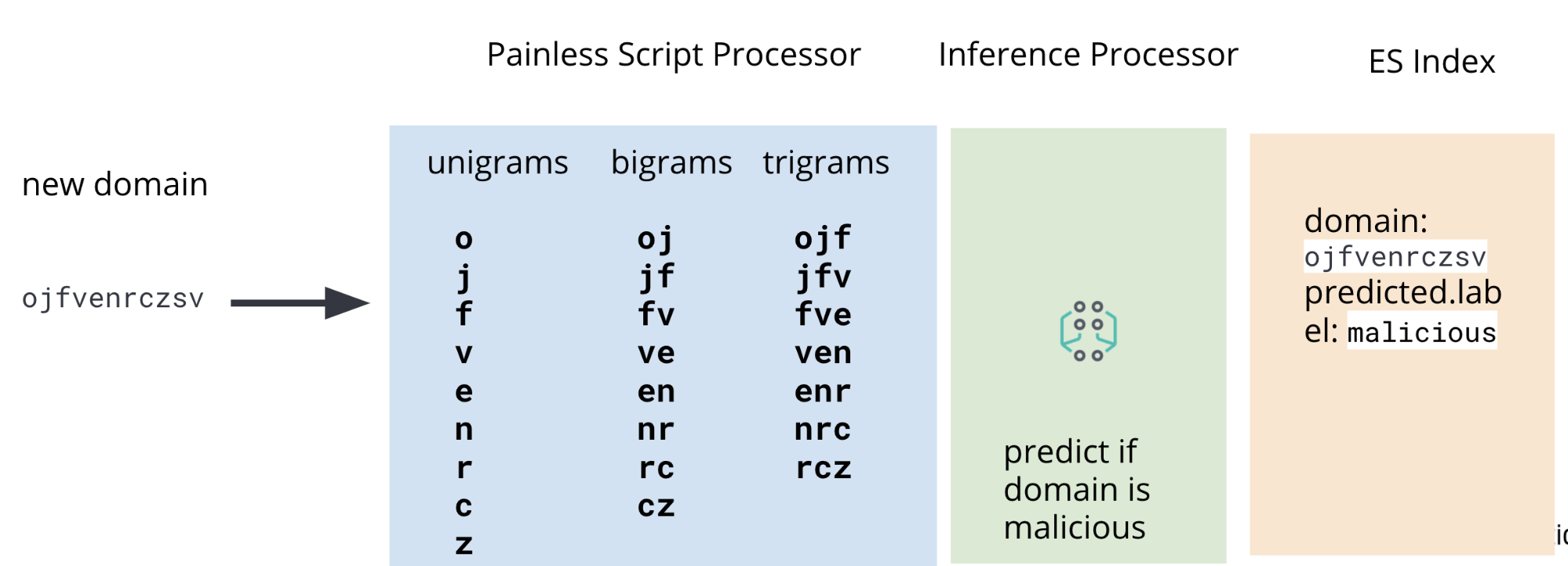
在 Packetbeat 数据中,我们希望执行操作的字段是 DNS 注册域名。尽管在某些边缘用例中,这个字段不会包含感兴趣的域名,但就本博客的目的而言,足以说明用例了。图 3 中的图像说明了示例 Packetbeat 文档中感兴趣的字段。

dns.question.registered_domain为了从 dns.question.registered_domain 中提取一元语法、二元语法和三元语法,我们将需要使用图 4 中所示的 Painless 脚本。
POST _scripts/ngram-extractor-packetbeat
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount, int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['dns']['question']['registered_domain'].length();i++){
ctx['field_'+Integer.toString(params.ngram_count)+'_gram_'+Integer.toString(i)] = nGramAtPosition(ctx['dns']['question']['registered_domain'], i, params.ngram_count)
}
"""
}
}
提取必要的特征后,仍通过采集管道传递的文档将通过推理处理器,在该处理器中,我们在前一部分训练的分类模型将使用提取的特征进行预测。最后,因为我们不想使模型所需的所有额外特征杂乱无章,所以,我们将添加一系列 Painless 脚本处理器来删除包含一元语法、二元语法和三元语法的字段。
因此,在采集管道的末尾,我们将采集的是一个 Packetbeat 文档,其中包含新的额外字段,这些字段包含 ML 预测的结果。图 5 所示为一个示例采集管道配置。有关完整的详细信息,请参阅示例存储库。
PUT _ingest/pipeline/dga_ngram_expansion_inference
{
"description":"Expands a domain into unigrams, bigrams and trigrams and make a prediction of maliciousness",
"processors": [
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params": {
"ngram_count":3
}
}
},
{
"inference": {
"model_id": "dga-ngram-job-1587729368929",
"target_field": "predicted_label",
"field_mappings":{},
"inference_config": { "classification": {"num_top_classes":2} }
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params": {
"ngram_count":3
}
}
}
]
}
因为并不是每个 Packetbeat 文档都会记录 DNS 请求,所以仅当所采集文档中存在所需的 DNS 字段且不为空时,我们才需要使采集管道有条件地执行。为此,我们可以使用管道处理器(见图 6 中的配置)来检查是否存在所需的字段且填充有内容,然后将文档的处理重定向到我们在图 5 中定义的 dga_ngram_expansion_inference 管道。虽然以下配置适用于原型,但对于生产用例,您需要考虑采集管道中的错误处理。有关完整的配置和说明,请参阅示例存储库。
PUT _ingest/pipeline/dns_classification_pipeline
{
"description":"A pipeline of pipelines for performing DGA detection",
"version":1,
"processors": [
{
"pipeline": {
"if": "ctx.containsKey('dns') && ctx['dns'].containsKey('question') && ctx['dns']['question'].containsKey('registered_domain') && !ctx['dns']['question']['registered_domain'].empty",
"name": "dga_ngram_expansion_inference"
}
}
]
}
使用异常检测作为对推理结果的二阶分析
在本系列博客的第 1 部分中,我们训练的模型有 2% 的误报率。虽然这个数值听起来很低,但我们必须记住,DNS 流量通常是非常高的。因此,即使误报率为 2%,也可能会将大量的查询评为恶意。减少误报数量的一种方法是研究进一步的特征工程方案。另一种方法就是对分类的结果使用异常检测。下面让我们探讨一下如何在 Elastic Stack 中采用第二种方法。
首先要观察的是,如果我们获取扩充的 Packetbeat 文档,并根据时间绘制标记为恶意的 Packetbeat 文档的数量,我们得到的是一个时间序列(图 7)。
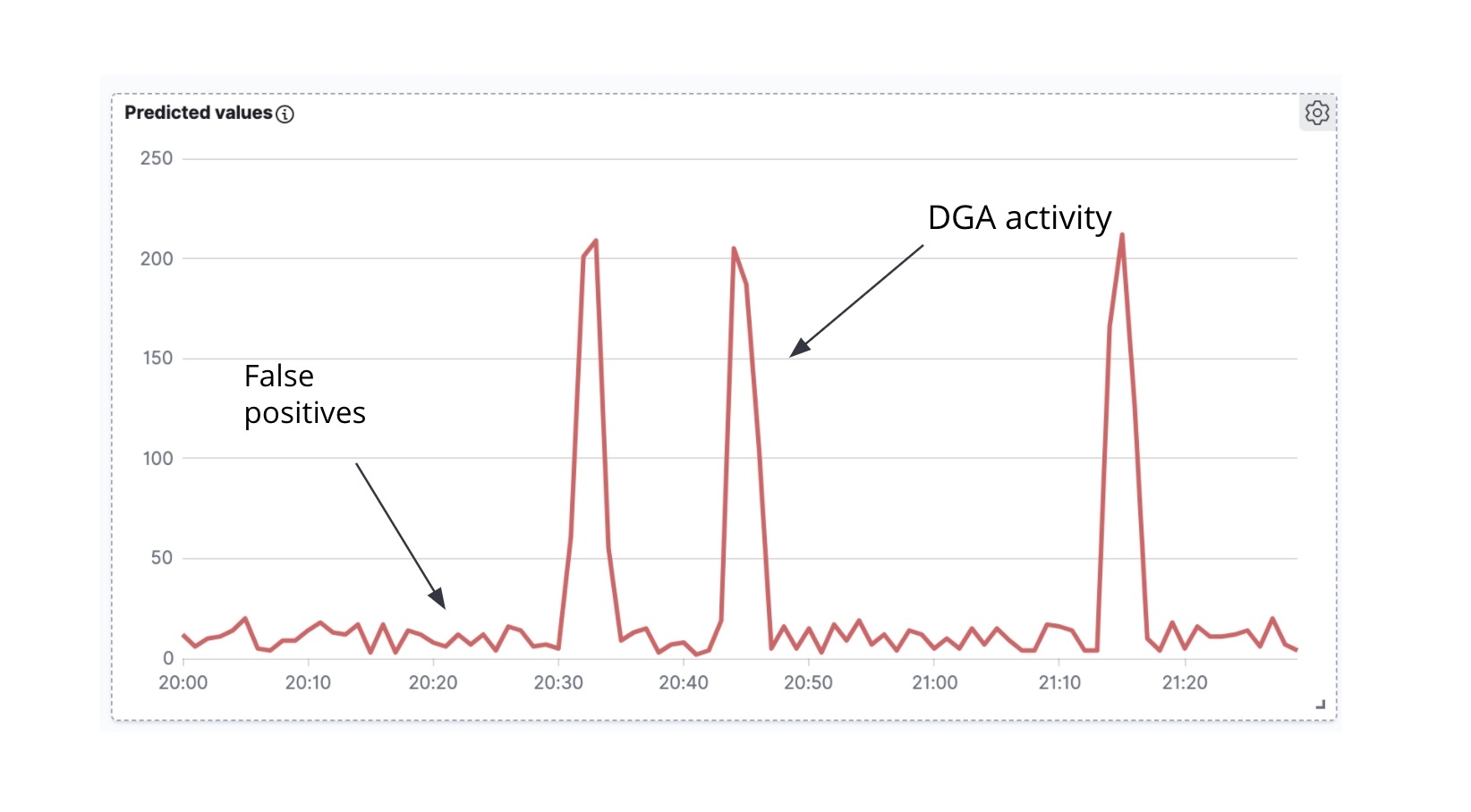
其次要注意的是,通常情况下(尽管也有例外),当 DGA 恶意软件主动尝试与 C&C 服务器进行通信时,往往会一次性生成一波 DNS 请求(也就是,恶意软件会遍历算法生成的许多域名,试图解析每个域名的 IP 地址)。在一段时间内预测的恶意域的时间序列分析中(图 6),我们可以看到,活动的峰值以及峰值之间的小噪声。这些峰值表明,我们的分类模型在很短时间跨度内将许多域名归类为恶意域名,因此,我们很可能在处理一个真正的 DGA。与之相反的,峰值之间的背景噪声很可能是误报的结果。正是这种直觉,我们将设法在此时间序列的 high_count 异常检测作业中进行编码。
如果将异常检测泳道与图 7 中的时间序列重叠,我们将看到,我们收到了与时间序列中的峰值(真正的 DGA 活动)相对应的异常警报,而在峰值之间的间隔(误报的背景噪声)内没有警报。
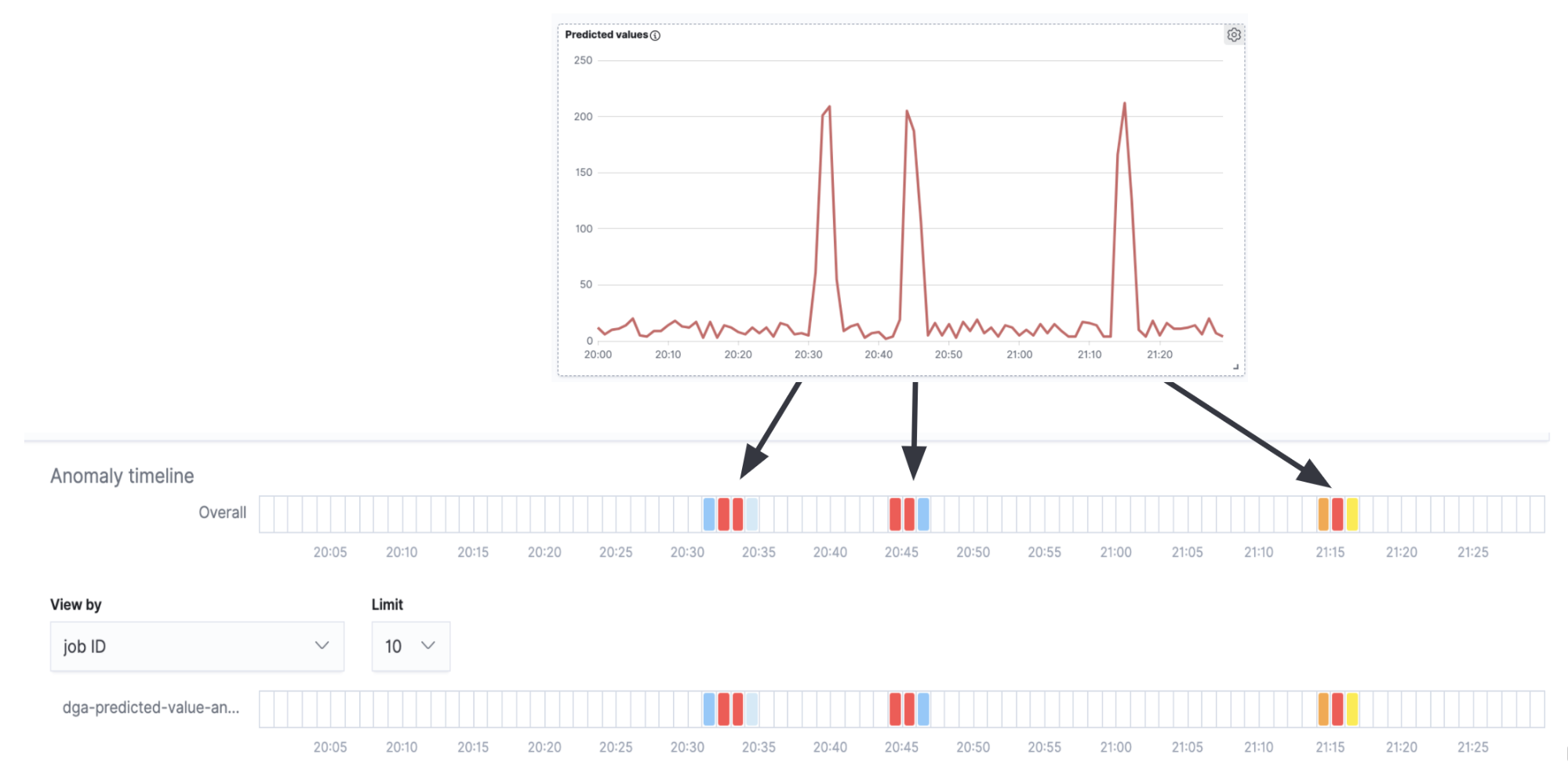
尽管这是一个非常简单的示例,并且对于生产用例可能还需要进行很多的微调和配置,但它还是能表明,异常检测作业可以有效地用作推理结果的二阶分析。
结论
在本博文中,我们使用了经过训练的分类模型来扩充采集时的网络数据(Packetbeat 文档)。在推理处理器和采集管道的共同促进下,扩充过程将在 DNS 请求期间对每个被查询的域名添加一个预测标签,用于指示域名被恶意攻击的可能性有多大。此外,为了减少误报警报,我们还研究了如何对推理结果使用异常检测作业。此外,我们还计划在 Elastic SIEM 中提供用于 DGA 检测的精选配置和模型。
如果您想使用自己的网络数据进行这方面的尝试,可以启动为期 14 天的 Elasticsearch Service 免费试用,以开始采集和分析。您还可以在本地下载 Elastic Stack 并启动试用许可证,免费试用 Machine Learning 30 天。或者,开始使用免费开放的 Elastic SIEM,立即开始保护您的数据。