使用 File Data Visualizer 将 CSV 和日志数据导入 Elasticsearch
我们在 Elastic Stack 6.5 中推出了一项新功能:File Data Visualizer。通过这项新功能,用户能够上传包含以分隔符隔开的文本(例如 CSV)、NDJSON 文本或者半结构化文本(例如日志文件)的文件,然后新的 Elastic Machine Learning find_file_structure 端点将会分析文件并返回包含数据相关结果的报告。这些结果包括建议使用的采集管道和映射,通过这些管道和映射便可从 UI 中将文件导入 Elasticsearch。
这一功能的目的是帮助那些希望使用 Kibana 或者 Machine Learning 探索自己数据的用户,让他们无需学习数据采集流程的复杂知识,便能轻松将少量数据导入 Elasticsearch。
这里有一个近期发生的很好的例子,那就是并没有开发背景的一位 Elastic 营销团队的成员撰写的这篇博文。通过使用 File Data Visualizer,他能够轻松将地震数据导入 Elasticsearch,进而帮助他使用 Kibana 中的 geo_point 可视化来探索和分析地震地点。
示例:将 CSV 文件导入 Elasticsearch
要想演示这一功能,最好的方法就是通过一个示例逐步呈现。在下面的示例中,我们将会使用来自 CSV 文件中的数据,这个 CSV 文件中包括某一航班预订网站的虚构数据。我们在下面仅列出了这个文件的前五行,让您大概知道数据的样子:
time,airline,responsetime 2014-06-23 00:00:00Z,AAL,132.2046 2014-06-23 00:00:00Z,JZA,990.4628 2014-06-23 00:00:00Z,JBU,877.5927 2014-06-23 00:00:00Z,KLM,1355.4812
在 File Data Visualizer 中配置“CSV 导入”
File Data Visualizer 位于 Kibana 中的下列位置:Machine Learning > Data Visualizer。用户会看到下面的界面,在此界面上,用户便可以选择或者拖放文件。对于 6.5 版本,我们将文件大小的上限设置为 100MB。
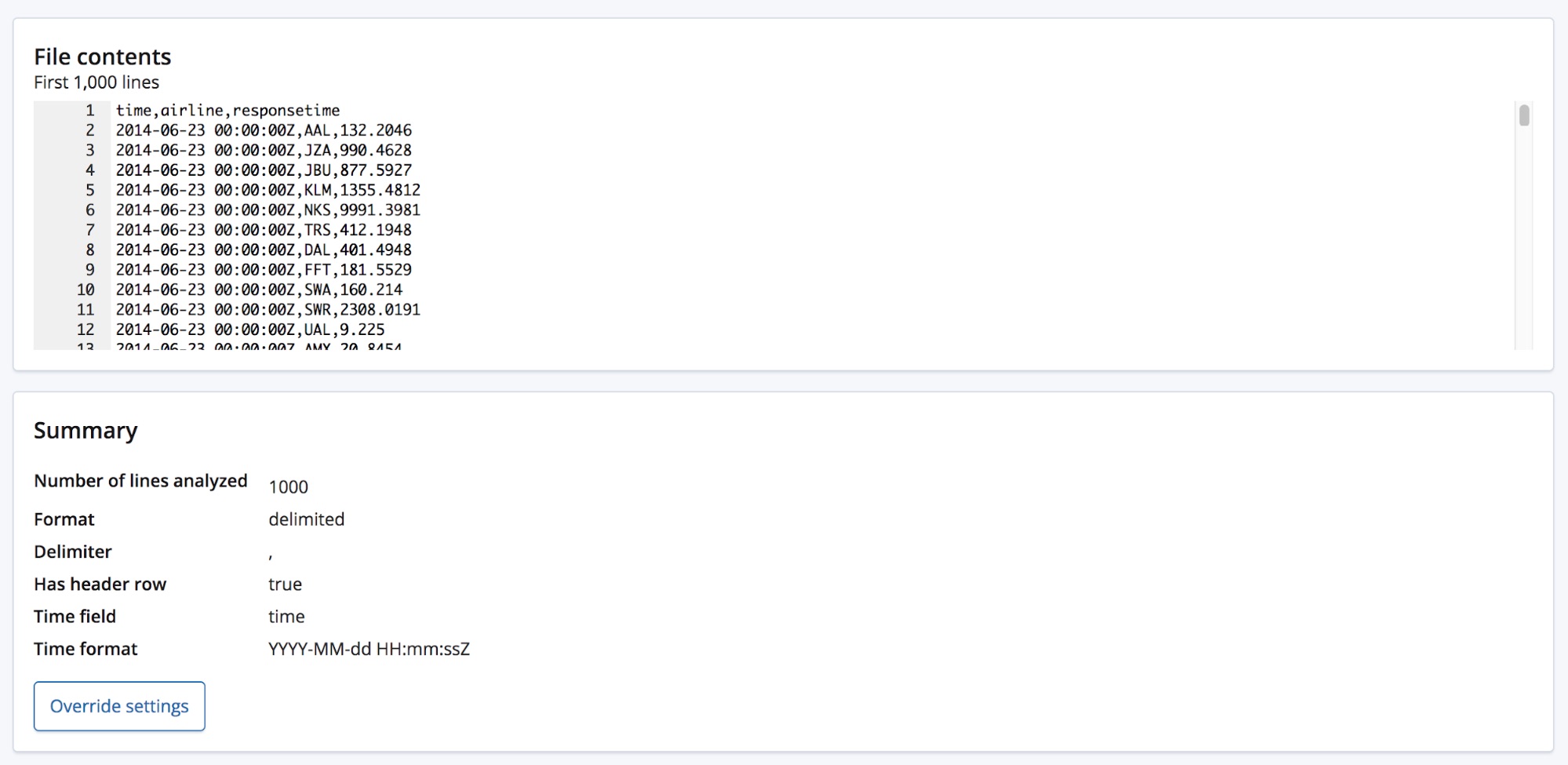
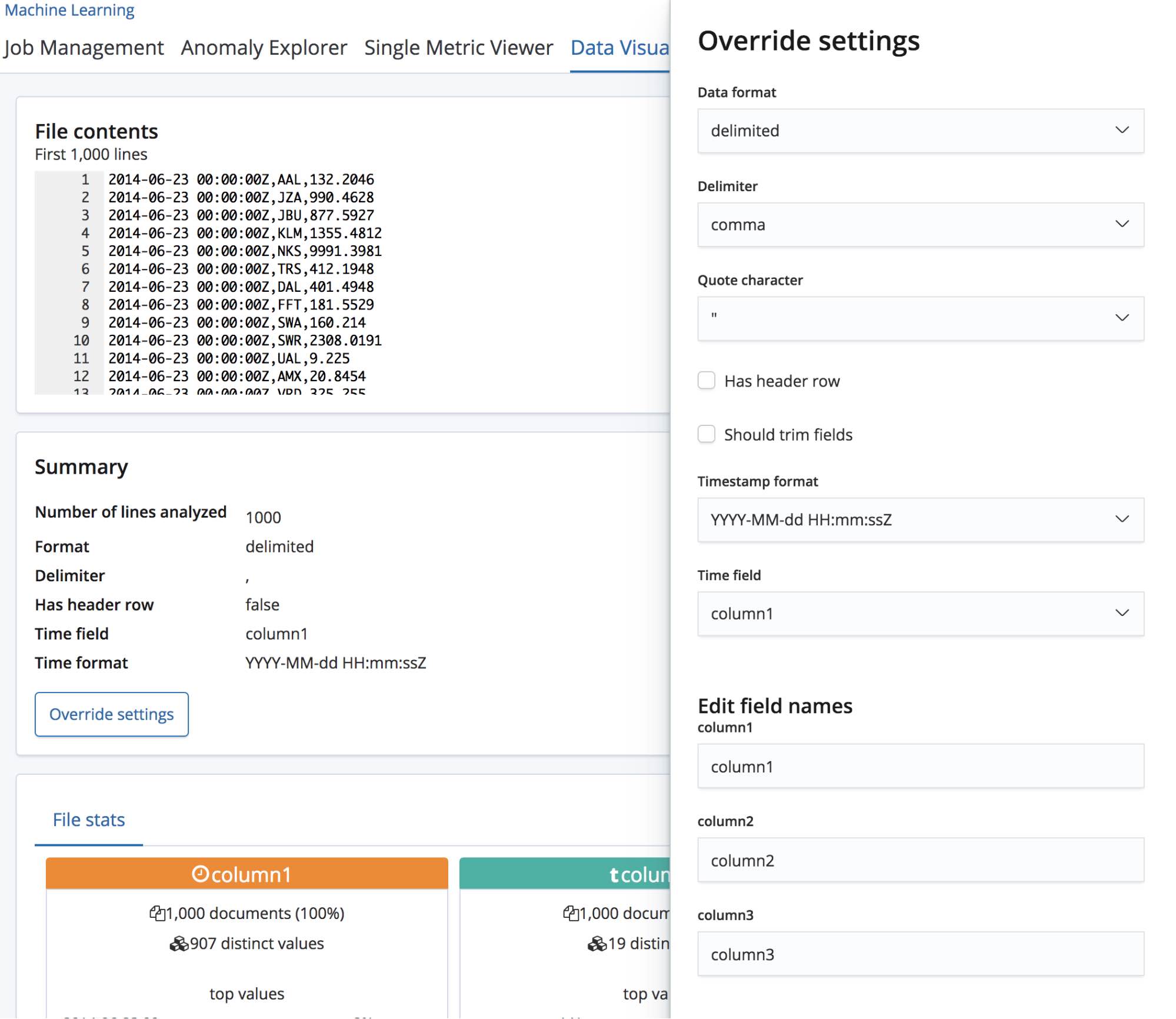
选择 CSV 文件之后,此页面会将文件中的前 1000 行发送给 find_file_structure 端点,然后此端点便会进行分析并返回结果。 通过查看 UI 中的 Summary(汇总)部分,我们可以看到该端点已正确检测到数据格式为包含分隔符,并且分隔符为英文逗号。
它还检测到有一个标题行,并且已将这些字段名称添加为每列数据的标签。第一列对应到一个已知的日期格式,并且已经高亮显示为 Time(时间)字段。
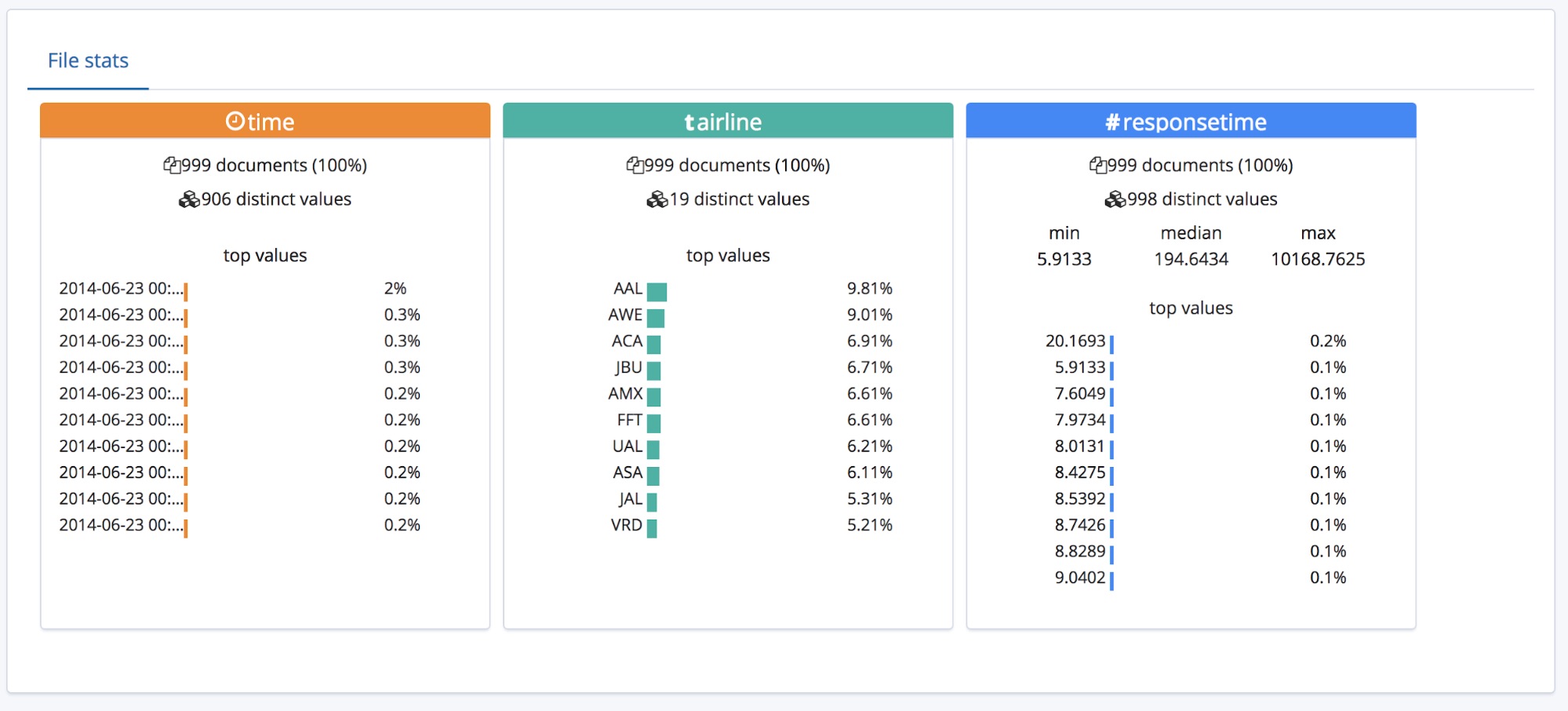
Summary(汇总)部分下方便是字段部分,对于曾使用过最初 Data Visualizer 功能的用户而言,他们应该已经熟悉这一部分。
我们可以看到,已经正确识别出了这三个字段的类型,并且还针对每个字段列出了一些高层次统计数据。 针对每个字段列出了出现次数最多的前 10 个值。对于已被正确识别为数字型字段的 responsetime,还列出了 min(最小值)、median(中位数)和 max(最大值)这三个值。
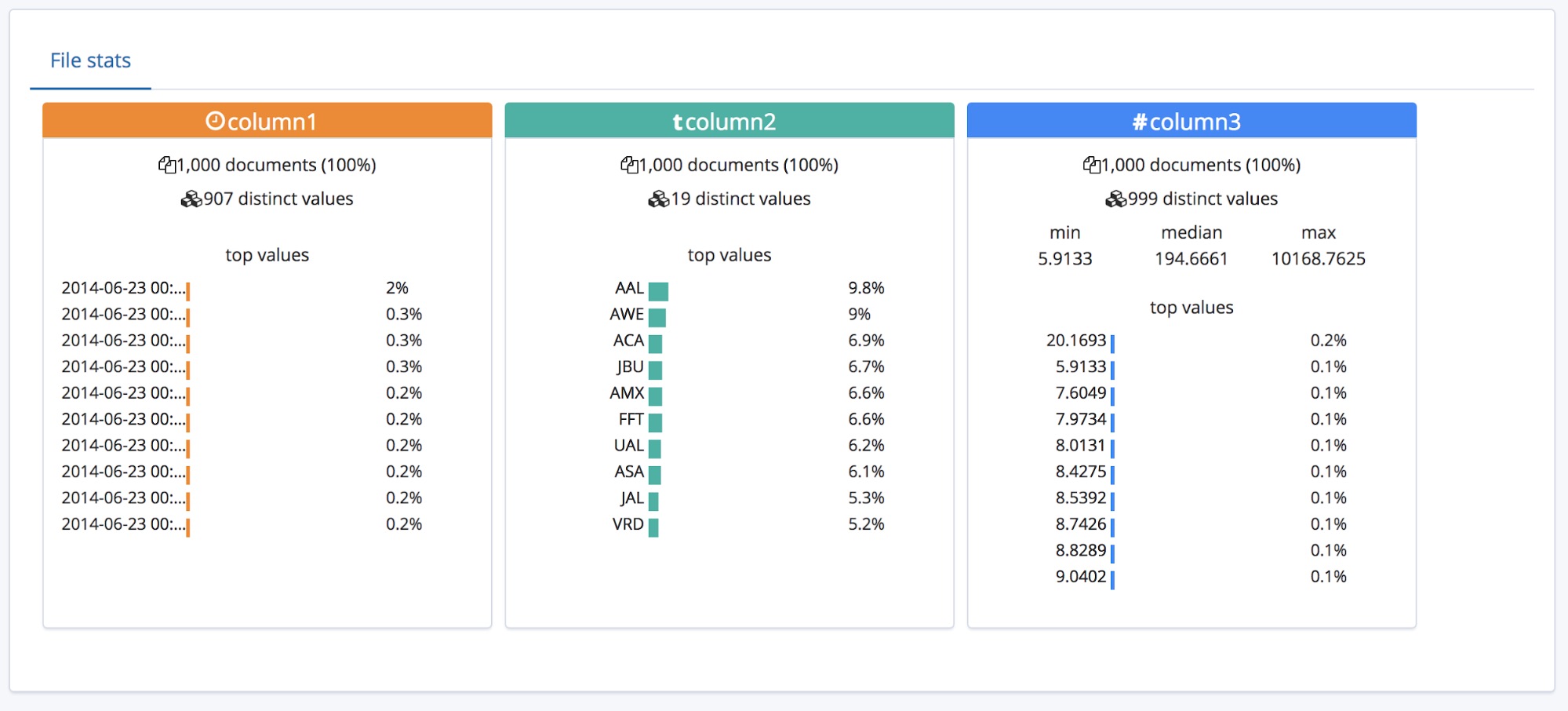
对于拥有标题行的的 CSV 文件,此功能的运行效果很好,但如果数据顶部没有标题行的话,又会如何呢?
在这种情况下,find_file_structure 端点将会使用临时字段名。我们也可以演示一下这种情况,从示例文件中删除第一行,然后再次上传即可。现在,这些字段被赋予了通用名称:column1、column2 和 column3。
用户很可能会拥有一些相关领域的知识,并希望将这些字段重新命名为涵义更加明晰的名称;点击 Override settings(覆盖设置)按钮便可进行重命名。
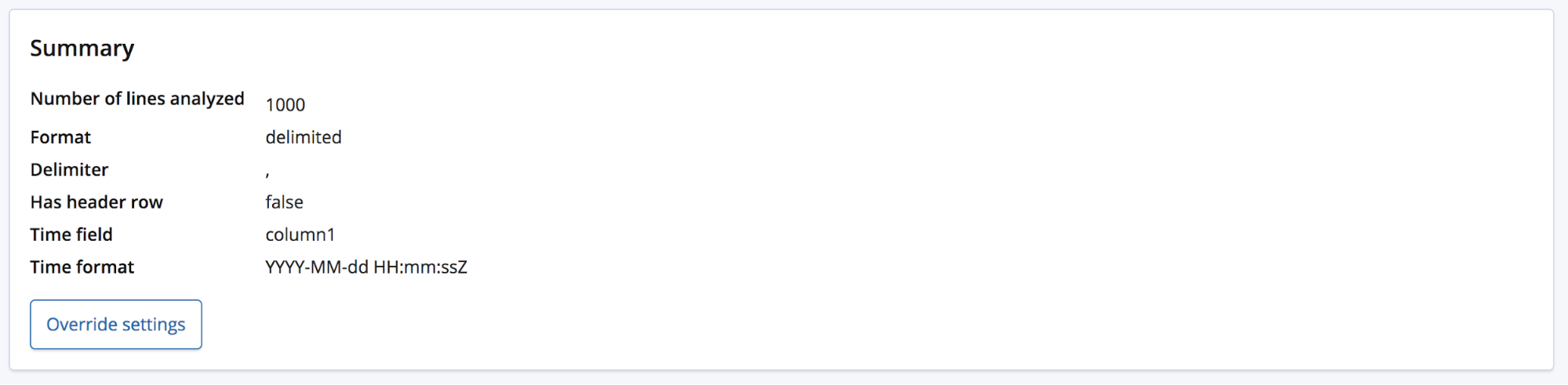
在重命名这些字段的同时,用户还能够编辑其他设置,例如 Data format(数据格式)、Delimiter(分隔符)和 Quote character(引用字符)。可以将这一部分看做为用户提供了一种方法,让他们能够更正 find_file_structure 端点就数据做出的合理猜测。您可能会有多个日期字段,而此端点仅选择了第一个。或者,即使文件包括标题行,您仍然希望完全更改字段名称。
对这些设置感到满意之后,我们便可以点击位于页面左下角的 Import(导入)按钮。
将 CSV 数据导入 Elasticsearch
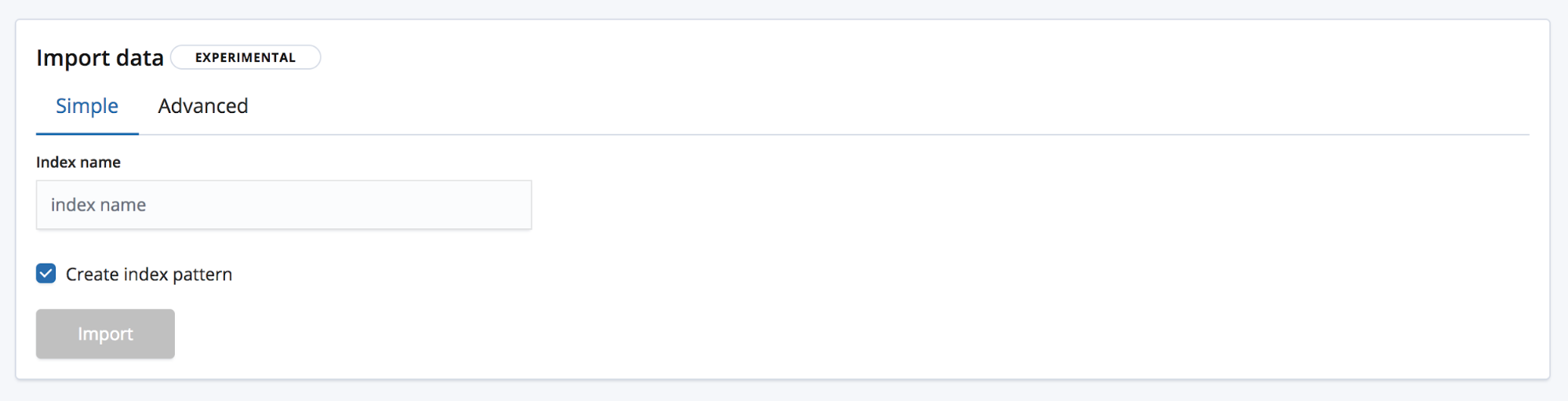
然后我们会来到 Import(导入)页面,在此页面上,我们便可以将数据导入 Elasticsearch。请注意:此功能不可用于重复性的生产流程,仅可用于最初的数据探索过程。主要原因固然是缺少自动化选项,但还有另外一个原因,即此功能目前尚处在实验阶段。
有两种导入模式可供选择。Simple(简单),使用此种模式的话,用户只需要提供新的唯一性索引名称,并选择是否需要同时创建索引模式。
还有 Advanced(高级),使用这一模式,用户可在更细层面上管理创建索引时所用的设置。
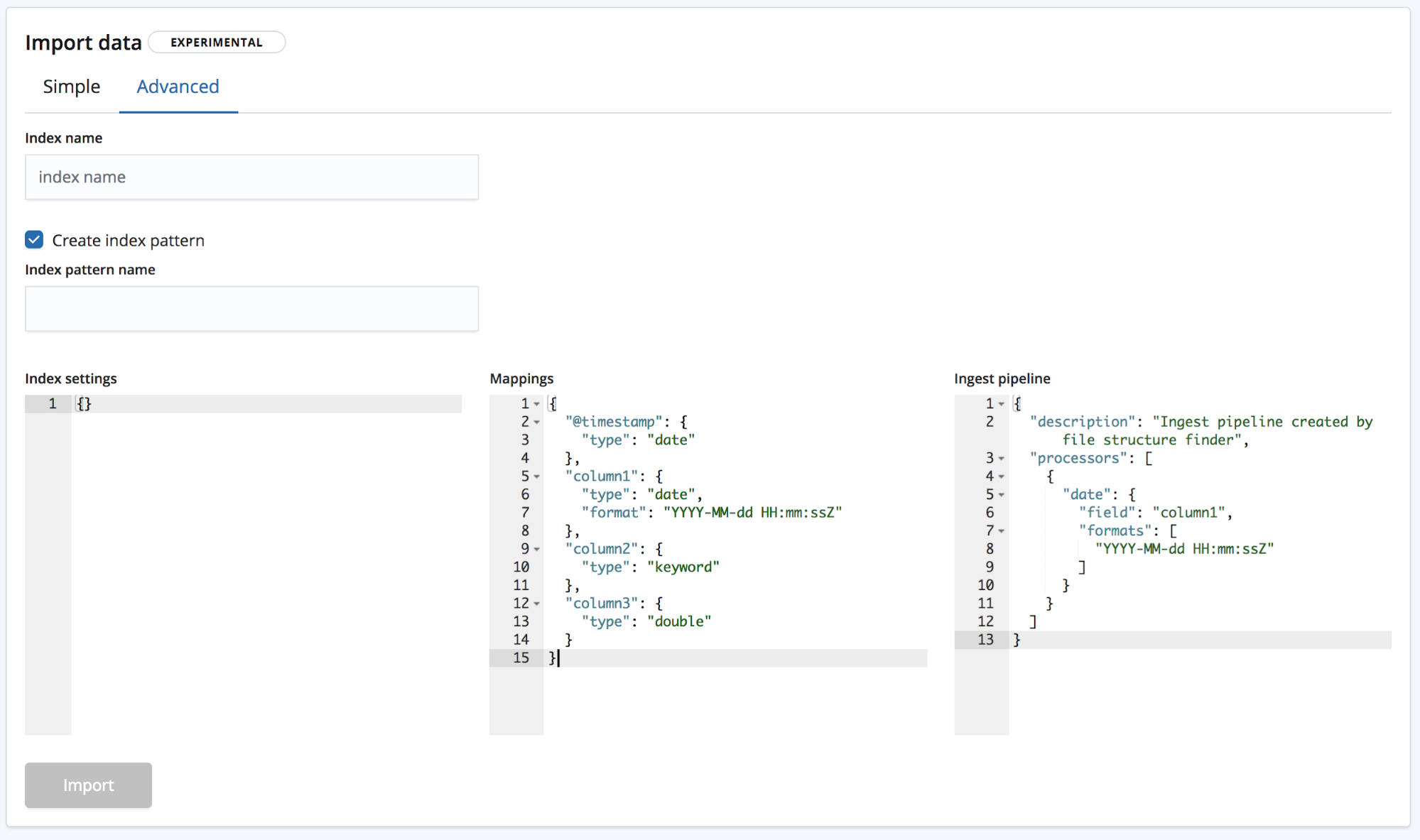
- Index settings(索引设置)- 默认情况下,无需针对索引创建和导入过程进行额外设置,但是这里仍然提供了对索引设置进行自定义的选项。
- Mappings(映射)-
find_file_structure会根据识别出的字段和类型提供一个映射对象。如需了解可用映射列表,请查看我们的 Elasticsearch 映射文档。 - Ingest pipeline(采集管道)-
find_file_structure会提供一个默认采集管道对象。采集数据时便会用到这个采集管道,而且此采集管道还可用于上传任何其他数据。
在 6.5 中,为了降低损坏索引的几率,我们仅允许创建新索引,而不允许向既有索引中添加数据。
单击导入按钮即会开始导入过程。这一过程包括多个步骤,已在下面编号列出:
- 处理文件 - 将数据转换为 NDJSON 文档,从而可以使用批量 API 进行采集
- 创建索引 - 使用设置和映射对象创建索引
- 创建采集管道 - 使用采集管道对象创建采集管道
- 上传数据 - 将数据加载到新的 Elasticsearch 索引中
- 创建索引模式 - 创建 Kibana 索引模式(如果用户选择的话)

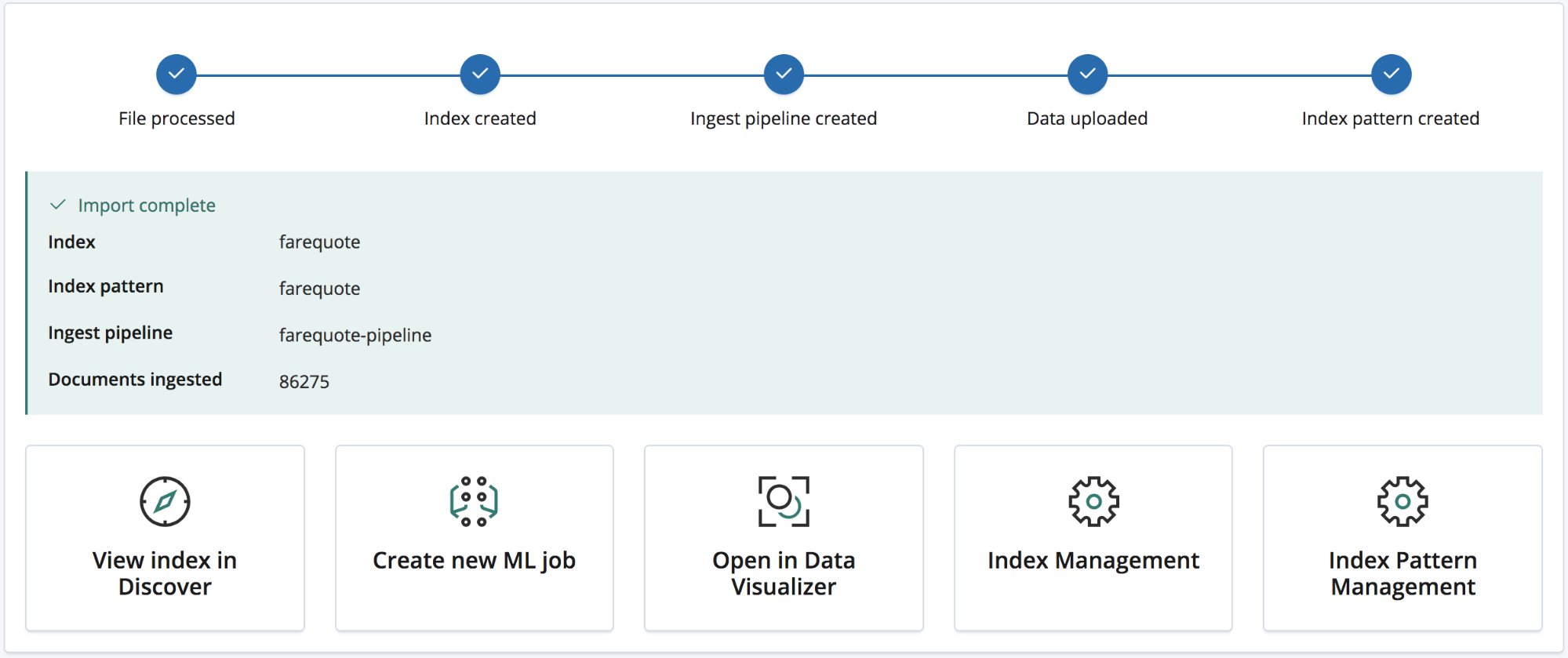
导入完成之后,用户便会看到一个汇总,其中列明了索引的名称、索引模式、所创将的采集管道、所采集的文档的数量,
以及用于探索新导入数据的大量 Kibana 链接。还会为白金级和试用期订阅用户提供一个链接,让他们能够基于数据快速创建一个 Machine Learning 作业。
示例:将日志文件和其他半结构化文本导入 Elasticsearch
现在我们已经讲完了 CSV 数据,NDJSON 数据就更简单了,导入时仅需要进行极少处理即可,但是半结构化文本又怎样呢?我们看一下 CSV 数据的分析过程与典型日志文件数据(亦称半结构化文本)的分析过程有哪些不同。
下面是路由器生成的某个日志文件的三行数据。
<190>38377:GOW45-AR002:Apr 18 08:44:02.434 GMT: %JHG_MS-6-ROUTE_EVENT_INFO:Route changed Prefix 10.156.26.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38378:GOW45-AR002:Apr 18 08:44:07.538 GMT: %JHG_MS-6-ROUTE_EVENT_INFO:Route changed Prefix 10.156.72.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38379:GOW45-AR002:Apr 18 08:44:08.818 GMT: %JHG_MS-6-ROUTE_EVENT_INFO:Route changed Prefix 10.156.55.0/24, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired
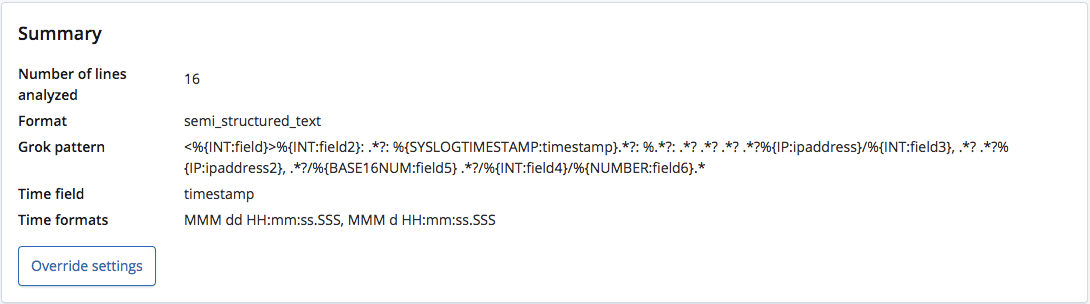
使用 find_file_structure 端点分析时,其正确识别出了格式为半结构化文本,并且创建了一个 grok 模式来从每行数据中提取字段和字段类型。在这些字段中,它还识别出了哪个为时间字段以及此字段的格式。
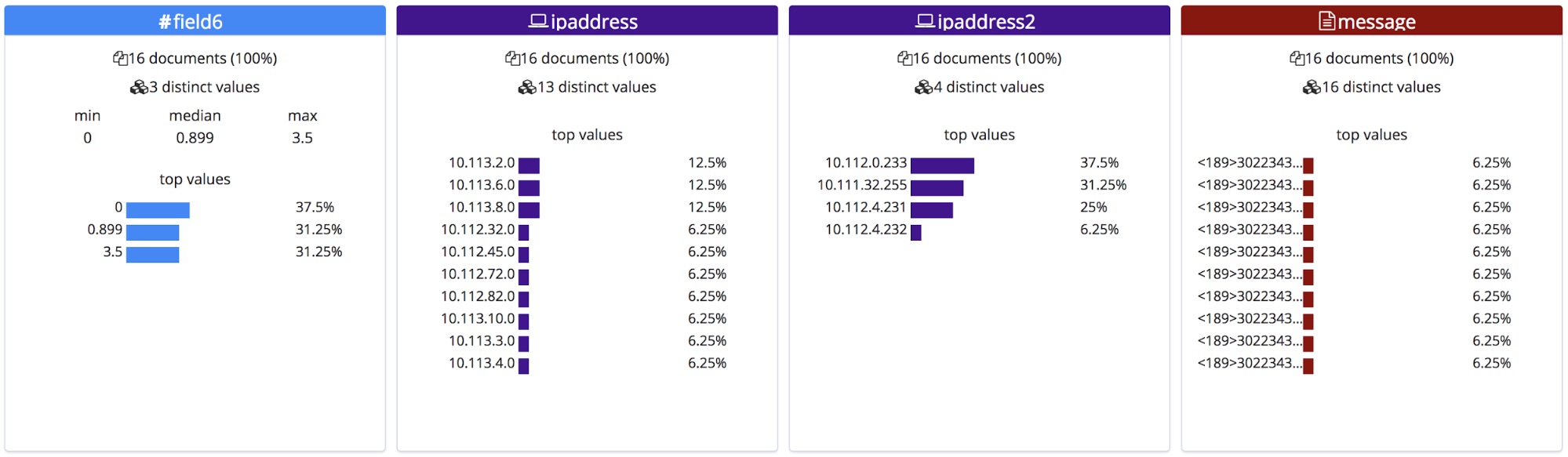
与带有标题行的 CSV 文件或者 NDJSON 文件不同,此端点无法获知这些字段的正确名称,所以其会根据字段类型给它们赋予通用名称。
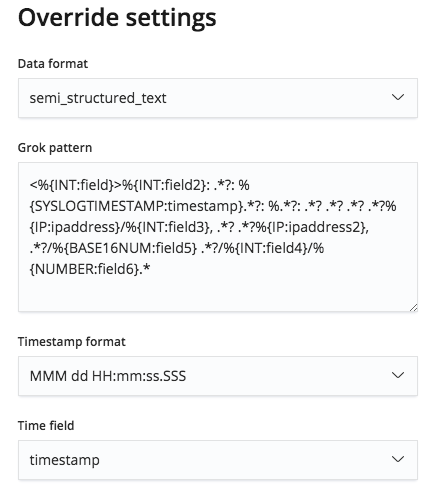
然而,通过 Override settings(覆盖设置)菜单可以对这一 grok 模型进行编辑,所以我们能够更正字段名称以及类型。
然后,这些更正后的字段名称便会显示在 File(文件)统计数据部分。请注意,它们是按照字母顺序排列的,所以我们稍微调整了一下顺序。
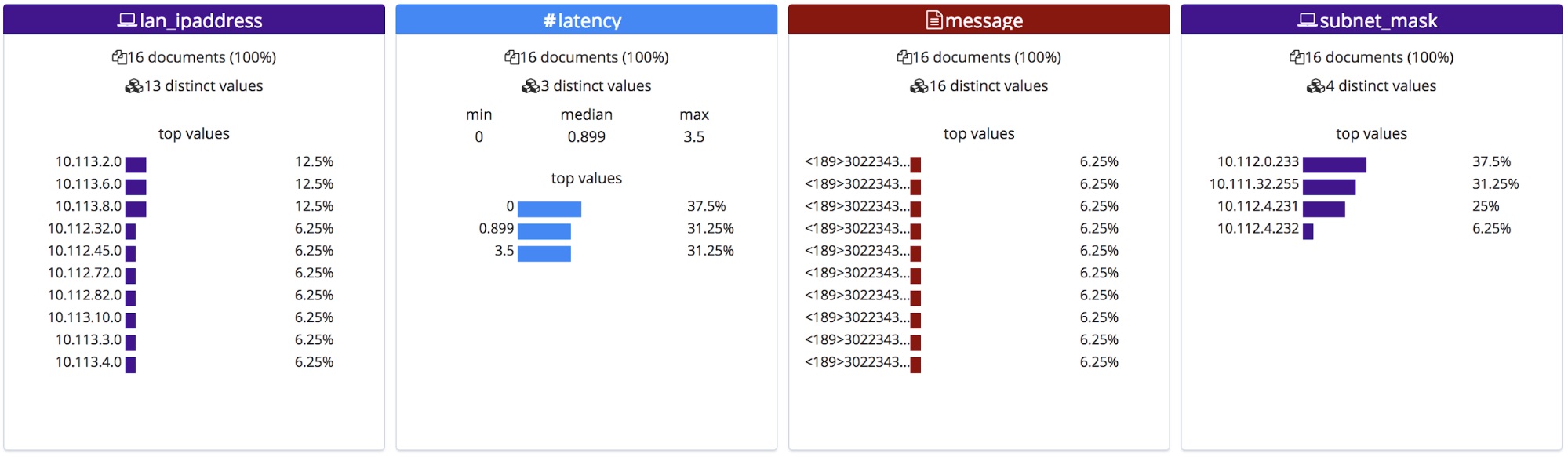
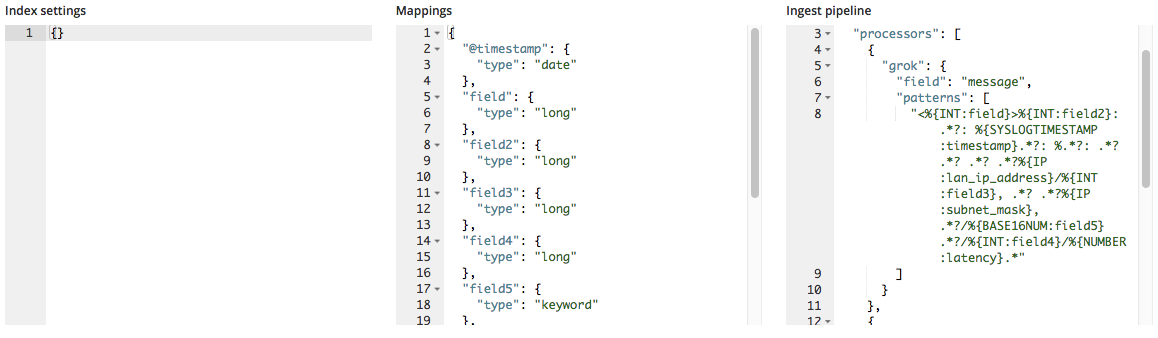
导入时,会将这些新的字段名称添加至映射对象中,并且会将 grok 模式添加到采集管道中的处理器列表中。
总结
希望这篇文章勾起了您尝试 6.5 中 File Data Visualizer 功能的浓厚兴趣。这在 6.5 中仍然是一项实验功能,所以可能并不能正确匹配每种文件格式,但是欢迎大家尝试并向我们反馈您的使用情况。您的反馈能够帮助我们尽快推出这一功能的正式版本。