在 Elasticsearch 中使用 Machine Learning 实现按需预测
编者按(2021 年 8 月 3 日):这篇文章使用了已弃用的功能。有关当前说明,请参阅使用反向地理编码映射定制区域文档。
按需预测是 6.1 中最新推出的 X-Pack Machine Learning 功能。之前,Elastic Machine Learning 的设计目标是使用历史数据来预测“现在”的正常数值范围,并将其与我们实际看到的数据进行对比,进而实时识别异常情况。目前在 6.1 中,Machine Learning 可以完成数据建模,并预估未来多个时段的情况。
我们之所以将其称为“按需预测”,是因为借助 Machine Learning 中内置的预测模型,用户可以使用既有的 Machine Learning 作业来预测此模型在预测日期范围内的增长情况。预测结果会写到 Elasticsearch 索引中,从而允许用户将实际结果与预测模型进行对比。
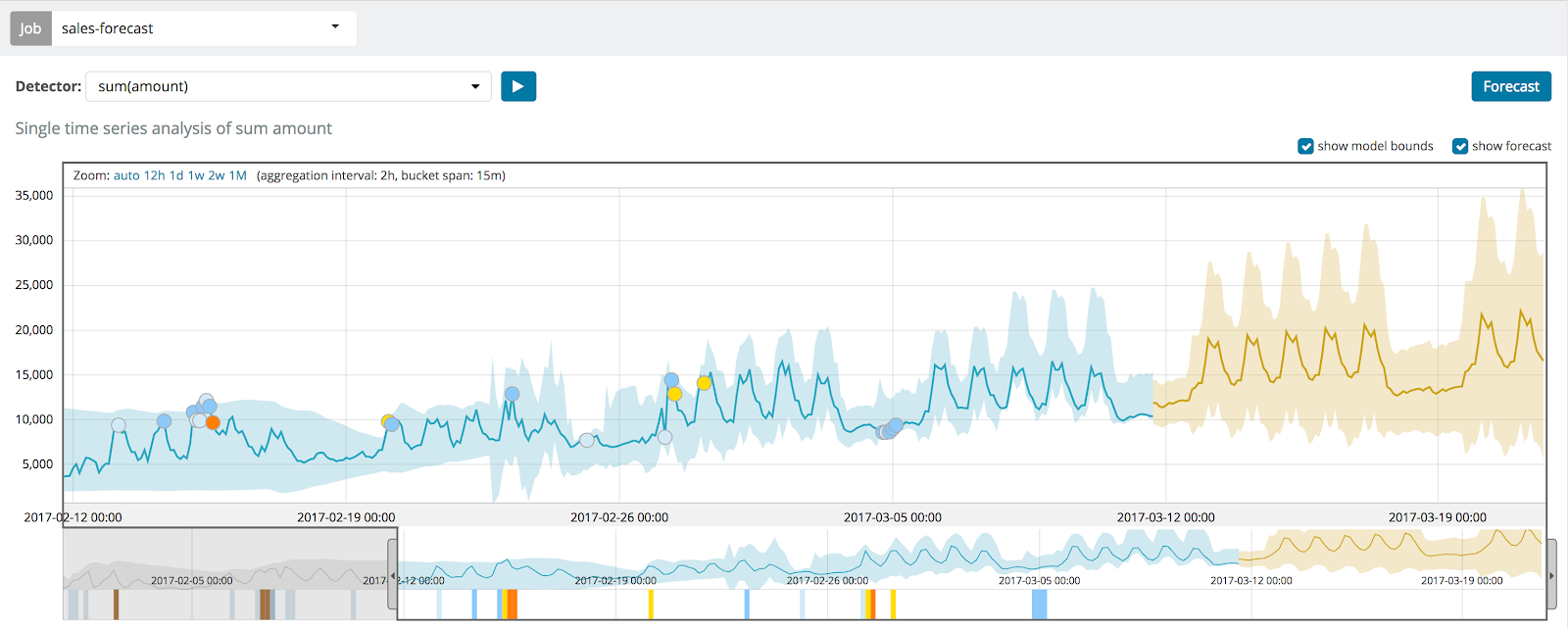
借助 Machine Learning 和预测功能进行容量规划
我们之前也提到,既往表现并不能代表未来结果。但是,要想预测结果来进行容量规划,最佳方式就是使用既往表现指标。
您如何确定某一资源何时会达到容量限值呢?举例说明,如果您正在监测服务器磁盘空间,则您可能需要预测磁盘空间何时会用完。您可以使用 Elastic 的 Machine Learning 预测模型来预测未来情况,并确定何时需要向系统中添加存储。
您还可以通过容量规划来预测未来特定时刻某个度量指标的值。举例说明此种情况,您想预测贵公司周一下午会接到多少通客户来电。通过分析历史数据并使用复杂的 Machine Learning 模型,您便能获得所需信息来做出人员调配和资源配置决策。
开始使用预测功能
您可以从既有 Machine Learning 作业的单一指标查看器 (Single Metric Viewer) 中运行预测功能。系统升级到 6.1 之后,屏幕右上角将会新增一个选项按钮来让您运行预测作业。
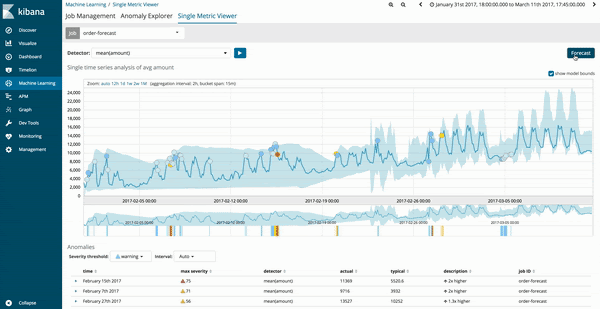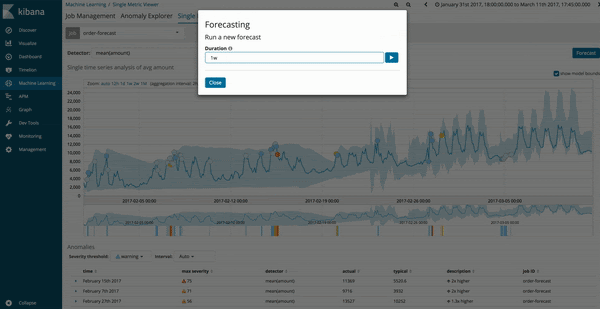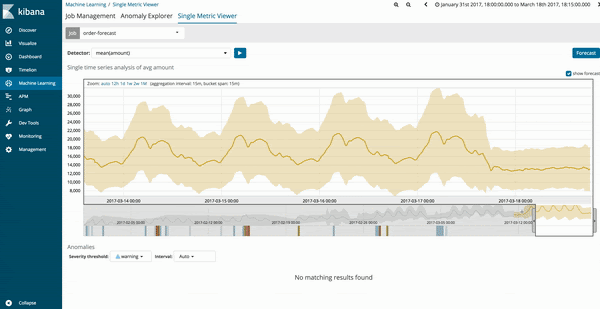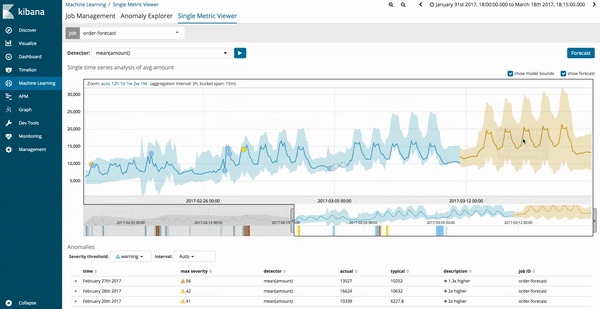
Machine Learning 作业的预测结果会以深黄色的趋势线表示,置信度模型会以颜色较浅的黄条表示。如果浅黄区带较窄,则表示预测模型的置信度较高。如果预测模型的置信度降低,浅黄区带将会变宽。
创建预测模型时的注意事项
为了更好地理解结果,创建预测模型时,有几个细节需要考虑。预测结果可能与您的预期不相符,而且并非每个数据集都能得出预测结果。
我们建议您首先收集足量的历史数据,然后再尝试运行 Machine Learning 预测作业。历史数据量通常以大约 3 周或者 3 个完整的定期数据周期为宜。如果您在学习阶段过早地运行预测,由于这时模型尚未建立,显示的结果很可能根本不能用。
如果预测置信度水平超出合理范围,预测模型将会提前停止。 预测作业将终止并显示一条消息(如下所示),告诉您置信度水平超出可接受范围。

如果模型绘图为“打开”状态,预测结果将会容易理解得多。这是一个可选项,对单指标作业而言,此项默认为打开。对多指标作业而言,可以通过下列方法打开模型绘图选项:在 Machine Learning 作业配置中对 “model-plot-config” 选项进行配置。
为了帮助在单一指标查看器之外跟踪任何具体预测结果,每个预测结果都有一个唯一 ID(称为 forecast_ID),这样的话,用户便可单独查询每个搜索结果。虽然可以针对同一指标进行多次预测,但对任何单一指标而言,UI 仅会显示最近运行的五个预测结果。尽管这样,所有预测结果仍可使用,也会占用相应的索引空间。如果您从 UI 运行的话,预测结果会在 14 天后自动删除,而如果您直接使用 API,则可以指定数据过期日期。有关详情,请查看预测文档。
Machine Learning 是 Elastic 白金级订阅服务中的功能,但是您可以下载免费试用版 X-Pack 并亲自尝试一下。