Elasticsearch 缓存深度剖析:一次提高一种缓存的查询速度
缓存是加快数据检索速度的王道。因此,如果您有兴趣了解 Elasticsearch 如何利用各种缓存来确保您尽可能快地检索数据,请仔细研读这篇博文,接下来的内容全是干货。本篇博文将阐释 Elasticsearch 的各种缓存功能,这些功能可帮助您在进行初始数据访问后更快地检索数据。Elasticsearch 是使用各种缓存的大户,但在本篇博文中,我们将只着重介绍以下三种:
您将了解每种缓存的用途、运作方式,以及哪种缓存最适合哪个用例。此外,我们还将探讨为何您有时可以控制缓存,有时则不得不信任另一个组件能够做好缓存作业。
我们还将了解页缓存如何处理数据过期的问题。您肯定不希望遇到返回过时数据的缓存。缓存必须与数据的生命周期绑定在一起,下面我们来看看它在每种缓存中的工作原理。
如果您想知道这篇博文是不是对您适用,请放心,不管您是自己运行 Elasticsearch 还是使用 Elastic Cloud 运行 — 您都可以直接使用这些缓存功能。好吧,下面就让我们一探究竟。
页缓存
第一个缓存属于操作系统级别。虽然这部分主要介绍 Linux 上的实施过程,但其他操作系统也有类似的功能。
页缓存的基本理念是从磁盘读取数据后将数据放入可用内存中,以便下次读取时从内存返回数据,而且获取数据不需要进行磁盘查找。所有这些对应用程序来说是完全透明的,应用程序发出相同的系统调用,但操作系统可以使用页缓存而不是从磁盘读取。
我们看一看下面这张图,其中应用程序正在执行系统调用以从磁盘读取数据,内核/操作系统将访问磁盘以进行第一次读取,并将数据放入内存的页缓存中。然后,内核可以将第二次读取重定向到操作系统内存中的页缓存,因此检索速度会快得多。
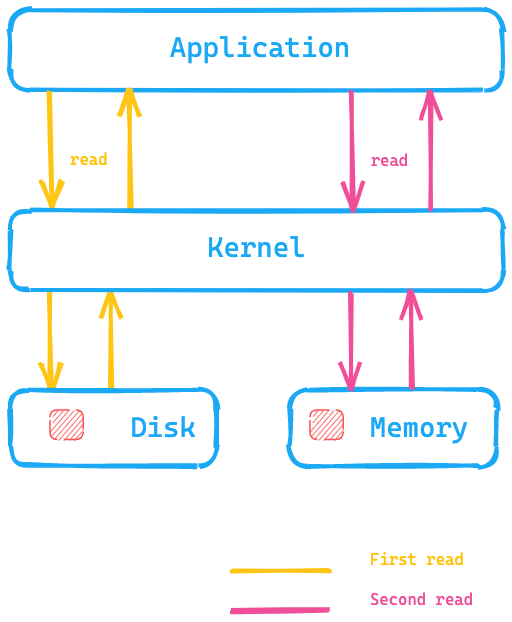
这对 Elasticsearch 来说意味着什么?与访问磁盘上的数据相比,通过页缓存可以更快地访问数据。这就是为什么建议的 Elasticsearch 内存通常不超过总可用内存的一半 — 这样另一半就可用于页缓存了。这也意味着不会浪费任何内存;相反,它会被重用于页缓存。
缓存中的数据是如何过期的?如果数据本身发生更改,页缓存会将数据标记为脏数据,并将这些数据从页缓存中释放。由于 Elasticsearch 和 Lucene 使用的段只写入一次,因此这种机制非常适合数据的存储方式。段在初始写入之后是只读的,因此数据的更改可能是合并或添加新数据。在这种情况下,需要进行新的磁盘访问。另一种可能是内存被填满了。在这种情况下,缓存的行为类似于内核文档所述的 LRU。
测试页缓存
如果您想查看页缓存的功能,我们可以使用 hyperfine 来执行此操作。hyperfine 是一个 CLI 基准测试工具。下面我们通过 dd 创建一个大小为 10MB 的文件
dd if=/dev/urandom of=test1 bs=1M count=10
如果您想使用 macOS 运行上述内容,可能需要改用 gdd 并
确保通过 brew 安装 coreutils。
# for Linux hyperfine --warmup 5 'cat test1 > /dev/null' \ --prepare 'sudo sync; sudo echo 3 > /proc/sys/vm/drop_caches'
# for osx hyperfine --warmup 5 'cat test1 > /dev/null' --prepare 'sudo purge' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 38.1 ms ± 6.4 ms [User:1.4 ms, System:17.5 ms] Range (min … max): 30.4 ms … 50.5 ms 10 runs hyperfine --warmup 5 'cat test1 > /dev/null' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 3.8 ms ± 0.6 ms [User:0.7 ms, System:2.8 ms] Range (min … max): 2.9 ms … 7.0 ms 418 runs
总之,如果在我的本地 macOS 实例上运行相同的 cat 命令而不清除页缓存,速度大约是原来的 10 倍,因为可以跳过磁盘访问。您肯定希望对 Elasticsearch 数据采用这种访问模式
深入剖析
负责读取 Lucene 索引的类是 HybridDirectory 类。根据 Lucene 索引中文件的扩展名,可以决定是使用内存映射还是使用 Java NIO 进行常规文件访问。
此外还要注意的是,有些应用程序更了解自己的访问模式,并带有自己非常特定和经优化的缓存,而页缓存可能会与之相悖。如果需要,任何应用程序都可以在打开文件时使用 O_DIRECT 绕过页缓存。我们将在这篇博文的最后探讨这个问题。
如果您想检查缓存命中率,则可以使用 cachestat,它是 perf-tools 的一部分。
关于 Elasticsearch 的最后一点。您可以将 Elasticsearch 配置为通过索引设置将数据预加载到页缓存中。这是一项需要专家来完成的设置,请小心使用这项设置,以确保页缓存不会持续出现“抖动”现象。
总结
通过在操作系统的主内存中加载完整的索引数据结构,页缓存有助于更快地执行任意搜索。没有更多的粒度,它完全基于数据的访问模式。操作系统负责逐出。
接下来,我们看看下一级缓存。
分片级请求缓存
通过缓存仅由聚合组成的搜索响应,这种缓存有助于加快 Kibana 的运行速度。我们将聚合的响应与从多个索引中提取的数据叠加起来,以直观地查看使用这种缓存解决的问题。
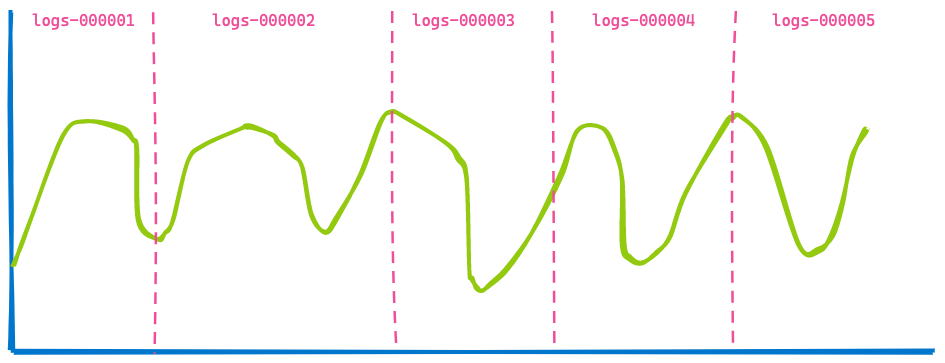
您办公室中的 Kibana 仪表板通常会显示来自多个索引的数据,您只需指定一个时间跨度(例如过去 7 天)即可查看。您无需关心查询了多少索引或分片。因此,如果您对基于时间的索引使用数据流,可能就会得到一个如下图所示的包含五个索引的可视化结果。
现在,我们跳转到 3 个小时后,显示相同的仪表板:
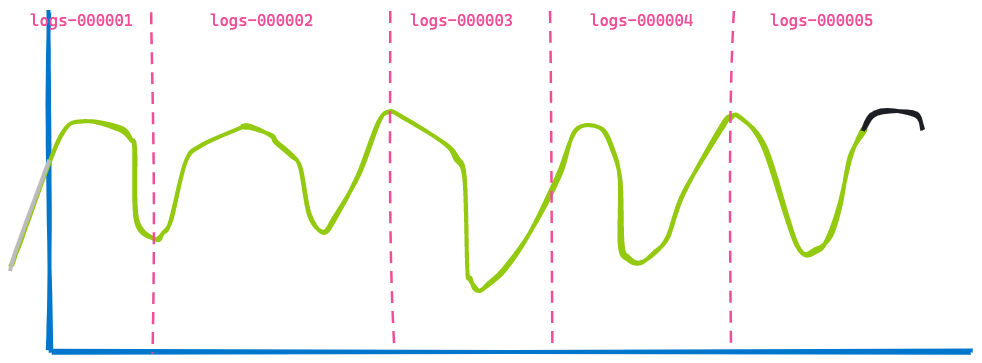
第二个可视化结果与第一个非常相似 — 一些数据由于已过时而不再显示(蓝线左侧),并且在黑线所示的末尾添加了更多数据。您能看出没有发生改变的部分吗?从索引 logs-000002、logs-000003 和 logs-000004 返回的数据没有变化。
即使这些数据已经在页缓存中,我们仍然需要在结果之上执行搜索和聚合。其实,没必要做这种事倍功半的工作。为了使这项工作顺利进行,Elasticsearch 还添加了一项优化:重写查询的能力。不必为日志索引 logs-000002、logs-000003 和 logs-000004 指定时间戳范围,我们可以在内部将其重写为 match_all query,因为该索引中的每个文档都与时间戳匹配(当然,其他筛选器仍然适用)。通过这种重写方法,现在两个请求在这三个索引上是完全相同的请求,因此可以被缓存。
这就是分片级请求缓存。这种缓存的理念是对请求的完整响应进行缓存,因此您根本不需要执行任何搜索,并且基本上可以立即返回响应 — 只要数据没有更改,以确保您不会返回任何过时数据!
深入剖析
负责缓存的组件是 IndicesRequestCache 类。执行查询阶段时,在 SearchService 中使用这一方法。如果查询符合缓存条件,还有一个附加检查 — 例如,从不缓存正在分析的查询以避免结果出现偏差。
此缓存会默认启用,最多可占用总堆的 1%,如果需要,甚至可以按每个请求进行配置。默认情况下,这种缓存是针对不返回任何点击量的搜索请求启用的 — 这就是 Kibana 可视化请求!但是,您也可以通过请求参数启用这个缓存,以在返回点击量时使用它。
您可以通过以下指令检索有关此缓存使用情况的统计信息:
GET /_nodes/stats/indices/request_cache?human
总结
分片级请求缓存会记住对搜索请求的完整响应,如果相同的查询再次出现而没有访问磁盘或页缓存,则会返回这些响应。顾名思义,这个数据结构与包含数据的分片是相关联的,并且永远不会返回过时的数据。
查询缓存
查询缓存是我们这篇博文要介绍的最后一种缓存。同样,这种缓存的工作方式也与其他缓存有着很大的不同。页缓存方式缓存的数据与实际从查询中读取的数据量无关。当使用类似查询时,分片级请求缓存会缓存数据。查询缓存更精细些,可以缓存在不同查询之间重复使用的数据。
我们来看看它的运作方式。假设我们在日志中搜索。三个不同的用户可能正在浏览本月的数据。但是,每个用户使用不同的搜索词:
- 用户 1 搜索“failure”
- 用户 2 搜索“Exception”
- 用户 3 搜索“pcre2_get_error_message”
每次搜索都会返回不同的结果,但它们都在同一时间范围内。这就是查询缓存的用武之地:它能够仅缓存查询的这一部分。基本理念是缓存信息而非搜索磁盘,并仅在那些已经缓存的文档中进行搜索您的查询可能如下所示:
GET logs-*/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "pcre2_get_error_message"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte":"2021-02-01",
"lt":"2021-03-01"
}
}
}
]
}
}
}
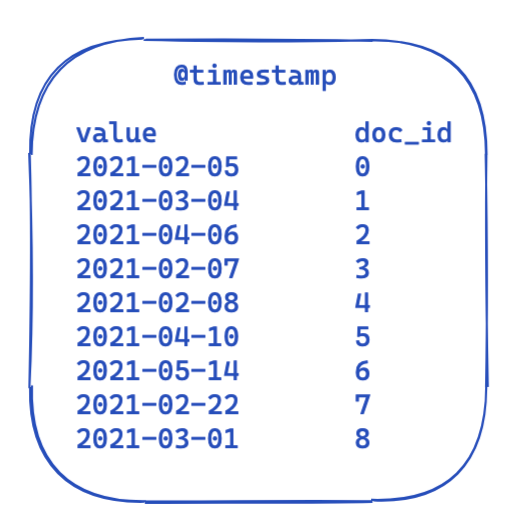
对于每个查询,filter 部分保持不变。下图是一个高度简化的视图,其中显示了倒排索引中数据情况。每个时间戳都映射到一个文档 ID。
那么,如何在查询中优化这个问题并加以重用呢?这时就轮到位集(也称为位数组)上场了。位集基本上是一个数组,其中每个位代表一个文档。我们可以为这个特定的 @timestamp 筛选器创建用于涵盖一个月的专用位集。0 表示文档在此范围之外,而 1 表示它在此范围内。生成的位集如下图所示:
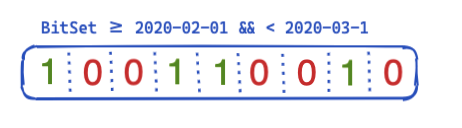
在每段基础上创建这个位集后(意味着在合并后或创建新段时需要重新创建这个位集),下一个查询甚至在运行筛选器之前都不需要进行任何磁盘访问来排除五个文档。位集有几个有趣的属性。首先它们可以组合。如果您有两个筛选器和两个位集,则可以轻松找出设置了这两个位的文档,还可以将 OR 查询合并在一起。位集另一个有趣的方面是压缩。默认情况下,每个筛选器的每个文档都需要一个位。但是,通过不使用固定的位集,而是使用另一种实现方式,例如 Roaring bitmaps,您可以减少内存需求。
那么,如何在 Elasticsearch 和 Lucene 中实现这一点呢?下面让我们一探究竟!
深入剖析
Elasticsearch 具有 IndicesQueryCache 类。这个类与 IndicesService 的生命周期绑定在一起,这意味着它不是按索引,而是按节点的特性 — 这样做是有道理的,因为缓存本身使用了 Java 堆。这个索引查询缓存占用以下两个配置选项
indices.queries.cache.count:缓存条目总数,默认为 10,000indices.queries.cache.size:用于此缓存的 Java 堆的百分比,默认为 10%
在 IndicesQueryCache 构造函数中,设置了一个新的 ElasticsearchLRUQueryCache。这个缓存从 Lucene LRUQueryCache 类扩展而来。该类具有以下构造函数:
public LRUQueryCache(int maxSize, long maxRamBytesUsed) {
this(maxSize, maxRamBytesUsed, new MinSegmentSizePredicate(10000, .03f), 250);
}
MinSegmentSizePredicate 确保只有包含至少 10,000 个文档的段才有资格进行缓存,并且该段的文档数占该分片总文档数的 3% 以上。
然而,从这里开始,事情就有点复杂了。即使数据在 JVM 堆中,还有另一种机制可以跟踪最常见的查询部分,并只将这些部分放入该缓存中。但是,这种跟踪是在分片级别进行的。有一个 UsageTrackingQueryCachingPolicy 类使用 FrequencyTrackingRingBuffer(使用固定大小的整数数组实现)。这个缓存策略在它的 shouldNeverCache 方法中还包含其他规则,用于防止缓存某些查询,如术语查询、匹配所有/无文档查询或空查询,因为这些查询足够快,而不需要缓存。还有一个条件是最小频率有资格进行缓存,这样单次调用就不会导致缓存被填满。您可以通过以下指令跟踪使用情况、缓存命中率和其他信息:
GET /_nodes/stats/indices/query_cache?human
总结
查询缓存已进入下一个粒度级别,可以跨查询重用!凭借其内置的启发式算法,它只缓存多次使用的筛选器,还根据筛选器决定是否值得缓存,或者现有的查询方法是否足够快,以避免浪费任何堆内存。这些位集的生命周期与段的生命周期绑定在一起,以防止返回过时的数据。一旦使用了新段,就需要创建新的位集。
缓存是加快检索速度的唯一方法吗?
这需要看情况(您已经猜到这个答案一定会适时出现在这篇博文中,对吧?)。Linux 内核的一个最新发展前景相当可期待:io_uring。这是一种在 Linux 下使用自 Linux 5.1 以来发布的完成队列进行异步 I/O 的新方法。请注意,io_uring 仍处于大力开发阶段。但是,Java 中有一些首次使用 io_uring 的尝试,例如 netty。简单应用程序的性能测试结果十分惊人。我想我们还得等一段时间才能看到实际的性能数据,尽管我预计这些数据也会有重大变化。我们希望 JDK 将来也能提供对这一功能的支持。有一些计划支持 io_uring 作为 Project Loom 的一部分,这可能会将 io_uring 引入 JVM。更多的优化,比如能够通过 madvise() 提示 Linux 内核的访问模式,还尚未内置于 JVM 中。这个提示可防止预读问题,即内核尝试读取的数据会比预期下次读取的数据要多,这在需要随机访问时是无用的。
还不止这些!Lucene 开发人员一如既往地忙于从任何系统中获得最大的收益。目前已经有使用 Foreign Memory API 重写 Lucene MMapDirectory 的初稿,这可能会成为 Java 16 中的一个预览功能。然而,这样做并不是出于性能原因,而是为了克服当前 MMap 实现的某些限制。
Lucene 最近的另一个变化是通过在 FileChannel 类中使用直接 i/o (O_DIRECT) 来摆脱原生扩展。这意味着写入数据将不会让页缓存出现“抖动”现象 — 这将是 Lucene 9 的功能。
有时,您还可以加快运行速度,这样您就不必再考虑缓存了,从而降低了操作复杂性。最近,在多次加速 date_histogram 聚合方面取得了巨大的进步。不妨花点时间阅读那篇很长但颇具启发性的博文。
另一个非常好的例子是,在 Elasticsearch 7.0 中实现了 block-max WAND(没有缓存),这是一次极大的改进。您可以在 Adrien Grand 撰写的这篇博文中阅读所有相关内容。
缓存深度剖析总结
希望您喜欢穿梭于不同缓存的这段旅程,现在您已经掌握了哪个缓存将在什么时候发挥作用。还要记住,监测缓存是特别有用的,不仅可以判断缓存是否有意义,还有助于确定缓存是否由于数据的不断添加和过期而持续出现“抖动”现象。如下图所示,在您启用对 Elastic 集群的监测后,即可在节点的高级选项卡中以及每个索引的基础上(如果您要查看某个索引)看到查询缓存和请求缓存的内存占用情况:
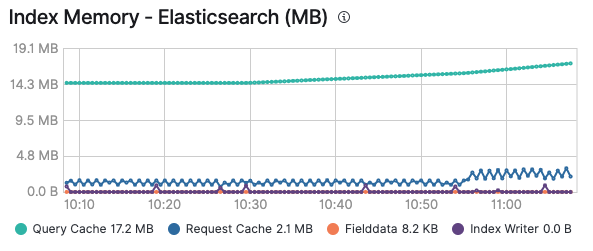
所有基于 Elastic Stack 构建的现有解决方案都将利用这些缓存来确保尽可能快地执行查询和交付数据。请记住,您只需单击一下即可在 Elastic Cloud 中启用日志记录和监测功能,并且无需额外费用就能够监测您的所有集群。欢迎亲自试用!