Elasticsearch 服务的节省成本策略:数据存储效率
数千家客户都在使用 Elastic Cloud 上的官方 Elasticsearch Service (ESS),他们不仅在其中运行 Elasticsearch,还运行我们的专属产品,例如 Elastic Logs、Elastic APM、Elastic SIEM 等。在运行方面拥有七年多经验,ESS 是唯一提供完整 Elasticsearch 体验的托管型服务,包括开发公司提供的所有功能、所有解决方案,以及支持;同时 ESS 还能在运行和部署方面提供诸多优势来辅助这些产品。
在前一篇博文中,我们针对使用与您的服务、基础设施或日志设备不在同一地区的 SaaS 解决方案,解释了存在的隐藏网络成本,而这些成本会导致费用骤增。在本篇博文中,我们会重点讲解 Elastic Cloud 上的 Elasticsearch 服务如何让您灵活选择各种策略,助您在工作负载增加时控制成本。
存储和分析您的应用程序所生成的日志、指标、APM 跟踪信息和安全事件时,都需要用到基础设施。但凡工作负载有增长,尤其是可观测性和安全用例的工作负载出现增长时,所需基础设施就要增加,而这会致使成本上升。ESS 提供了多种方式来帮助您管理自身数据,以便您在延长有用数据的保留期的同时仍能控制成本,而且还能让您提供同样实用的 Elastic Stack 功能:整合不同来源的数据、可视化选项、告警、异常检测,等等。
我们将会针对时序型数据(例如可观测性和安全用例)查看有哪些节约成本的机会。为向您演示,我们将会使用 Elastic Stack 最常见的用例之一:基础设施监测。Elastic Stack 包括 Beats,这是一系列存在于您的客户端中的轻量型代理,能够将数据传输到您的集群。Metricbeat 在很多团队中使用都很广泛,可用来发送系统指标(例如 CPU 使用率、磁盘 IOPS,或者 Kubernetes 上所运行应用程序的容器遥测数据)。
随着使用的应用程序越来越多,您的监测需求也会增长,而这就要求您提供更多存储空间来储存所生成的指标。当今,团队在管理大规模时序数据时的策略之一便是定义保留期限。我们今天会研究 ESS 中提供的能提高存储效率的更多选项,而且这些选项都开箱即用。
场景
为连续起见,我们将会针对下面的集群深入探讨能节省成本的策略:监测 1000 台主机,每个代理会针对每个指标采集 100 字节的数据,每 10 秒钟会采集 100 个指标,数据保留期为 30 天。我们还会为集群中的数据存储一个副本以实现高可用性,从而防止在节点发生故障时数据丢失。我们用数学算式计算一下需要多少存储空间:
|
|
如采用此法存储这些指标,我们需要的存储空间为 5.2TB。为简单起见,我们这里将会忽略 Elasticsearch 集群运行所需的空间。
总结如下:
| 监测的主机数 | 1,000 |
| 每天采集的数据量 (GB) | 86.4GB |
| 保留期限 | 30 天 |
| 副本数目 | 1 |
| 所需存储(包括副本) | 5.184TB |
借助热温部署和索引生命周期管理,提高存储效率
在诸如日志和指标等可观测性用例中,数据的使用率会随着时间的流逝而递减。一般情况下,团队会利用近期的数据来快速调查系统事件、安全告警,或者网络流量为何骤增。随着数据的时间越来越久,虽然仍保存在集群中并和集群中其他部分一样占用相同的计算能力、内存和存储资源,但是它们的查询频率会越来越低。这就产生了两种截然不同的数据访问模式,然而集群仅仅针对快速采集和频繁查询进行了优化,并未针对不经常访问的数据的存储方式进行优化。
Elasticsearch 服务中的热温架构派上用场了。此部署选项会在同一个 Elasticsearch 集群中提供两个硬件配置文件。热节点处理所有新输入的数据,并且存储速度也较快,以便确保快速地采集和检索数据。温节点的存储密度则较大,如需在较长期限内保留数据,不失为一种具有成本效益的方法。
在 Elasticsearch 服务中,针对热节点,我们通常会按照 1:30 的内存硬盘比来配置本地附加型 SSD,而对于温节点,则会按照 1:160 来配置高密度 HDD。这一强大架构与另一个重要功能相辅相成,即:索引生命周期管理 (ILM)。ILM 能够让您自动管理一段时间内的索引,它会根据特定条件(例如索引规模、文档数量或者索引)简化将数据从热节点转移到温节点的过程。
通过结合使用这两项功能,您能够在集群中设置两个不同的硬件配置文件,然后索引自动化工具便会在不同级别的节点之间传输数据。
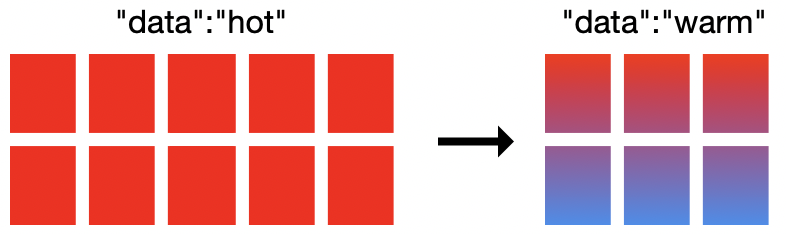
现在,我们要迁移到热温部署并配置 ILM 策略。在 ESS 中,您可以创建新的热温部署,还可以选择恢复来自其他集群的快照。如果已经拥有高 I/O 部署,您可以十分轻松地迁移到热温部署,只需向集群中添加温节点即可。通过使用 ILM 策略,我们会将数据在热节点中保存七天,然后将这些数据转移到温节点。
说一下底层的工作原理,当数据转移到温节点阶段后,您便不能再向索引中写入内容了。这又为我们节省成本提供了另一个机会,因为我们可以选择不在温节点中保存任何副本。如果温节点发生故障,我们可以基于最近截取的快照进行恢复,而无需使用副本。
此法有一个缺陷:从快照进行恢复时,速度通常较慢,所以在发生故障时,此法会导致您的故障解决时间变长。然而,很多时候这种情况是可以接受的,因为温节点中包含的通常是查询不太频繁的数据,所以在实际项目中影响比较有限。
最后,当数据存储时间到达 30 天后,我们会将数据删除,从而与我们原始的数据保留政策相一致。使用和上面类似的数学算式,下面是这种方法的汇总信息:
| 传统集群 | 热温 + ILM | |
| 监测的主机数 | 1,000 | 1,000 |
| 每天采集的数据量 (GB) | 86.4GB | 86.4GB |
| 保留期限 | 30 天 |
热:7 天
温:30 天 |
| 所需副本数量 | 1 |
热节点:1
温节点:0 |
| 存储要求 | 5.184TB |
热:1.2096TB(带副本)
温:1.9872TB(无副本) |
| 所需集群规模(约值) | 232GB RAM(6.8TB 的 SSD 存储) |
热:58GB RAM,带 SSD
温:15GB RAM,带 HDD |
| 每月集群成本 | $3,772.01 | $1,491.05 |
这一方法将每月成本削减了高达 60%,同时您仍能拥有可搜索的弹性数据。您可以对 ILM 策略进行微调以便找到理想的滚动期限,从而最大程度利用温节点上的存储优势。
通过数据汇总节省更多存储空间
如要节省存储空间,还可以考虑另外一个选项:数据汇总。汇总 (rollup) API 能够将数据“汇总”为 Elasticsearch 中的单份文档,让您以更节省空间的方式对数据进行汇总和存储。然后,您便可将原始数据归档或删除,从而节省存储空间。
创建“汇总”时,您需要选择在未来分析时会感兴趣的所有字段,然后基于汇总后的数据生成一个新索引。对主要处理数值型数据的用例进行监测时,这种方法尤为有用,因为此类数据可以很轻松地按照更粗的粒度(例如分钟、小时甚至天)进行汇总,同时仍能显示一段时间内的趋势。汇总后的索引在 Kibana 中的所有地方都能使用,您可以将它轻松地添加到既有仪表板中,从而避免造成任何分析工作的中断。这些都可以直接在 Kibana 中进行配置。
继续使用上面的场景,回想一下,我们需要 5.2 TB 的存储空间来存储 1,000 个主机 30 天的指标,其中包括一个副本集以确保高可用性。然后描述了一个使用热温部署模板的场景。现在我们要使用“数据汇总”API 来配置一个“汇总”作业,此作业会在数据到达七天后执行,这样我们稍微牺牲一些粒度,便可获得多得多的可用存储空间。
我们对“数据汇总”作业进行如下设置:将每 10 秒一次的指标数据汇总为逐小时的汇总文档。这样的话,我们仍能按小时查询和可视化较早的指标,而且这些指标能够在 Kibana 可视化和 Lens 中使用,从而揭示趋势和数据中的其他关键时刻。接下来,我们要删除刚才汇总之前的原始文档,这能够在集群中省出大量存储空间。使用数学算式进行计算后,我们能够得出针对所汇总的数据我们需要多少存储空间。
|
|
这些汇总后文档的原始数据已超过七天,所以如使用“热温 + ILM”的方法,它们会存储在我们热温集群里的温节点中。现在,我们可以将 1.99 TB 的数据完全删除。右边一列显示的是新方法得出的结果:
| 传统集群 | 热温 + ILM | 热温 + ILM,搭配汇总数据 | |
| 监测的主机数 | 1,000 | 1,000 | 1,000 |
| 每天采集的数据量 (GB) | 86.4GB | 86.4GB | 86.4GB |
| 保留期限 | 30 天 |
热:7 天
温:30 天 |
热:7 天
温:30 天 |
| 粒度 | 10 秒 | 10 秒 |
前 7 天:10 秒
7 天后:1 小时 |
| 所需副本数量 | 1 |
热节点:1
温节点:0 |
热节点:1
温节点:0 |
| 存储要求 | 5.184TB |
热:1.2096TB(带副本)
温:1.9872TB(无副本) |
热:1.2096TB(带副本)
温:5.52GB(无副本,有汇总数据) |
| 所需集群规模(约值) | 232GB RAM(6.8TB 的 SSD 存储) |
热:58GB RAM,带 SSD
温:15GB RAM,带 HDD |
热:58GB RAM,带 SSD
温:2GB RAM,带 HDD |
| 每月集群成本 | $3,772.01 | $1,491.05 | $1,024.92 |
节约的成本可谓十分之大。如果在既有热温集群的基础上采用数据汇总,我们可将成本降低 31%。如果将最后一个场景与仅包含单一硬件级别的传统集群相比,结果更加引人注目,您能够将成本锐减 73%!
你的部署你做主
每种方法都有利有弊。您可以灵活地微调各个策略,让其能够最大程度上符合您的需求。
通过 ILM 策略,您能够基于索引规模、文档数量或文档新旧程度来定义滚动期间,然后便可将数据转移到热温集群中的温节点。温节点能够高效地存储大量数据,帮助您节省计算资源成本。由于温节点的查询时间比热节点要长,所以对于不常查询的数据,这是一种优选方法。
数据汇总功能能够将数据汇总到较粗粒度的文档中,所以当数据较久,您不再需要较细粒度的原始文档时,这种方法十分有用。然后,您便可以删除源文件,从而帮助节省存储成本。您可以定义将数据汇总到多粗的粒度,以及何时进行汇总。您需找到正确的平衡点,以便汇总后的数据仍能继续为您提供关键洞见,例如一段时间内的趋势,或者流量骤增导致的系统行为。
您现在已经熟悉了如何使用开箱即用型策略优化 Elasticsearch 集群中的指标类工作负载,那么您要如何利用节省下来的存储空间呢?Elastic Stack 适用于各种各样的丰富用例:日志、APM 跟踪信息、审计事件、终端数据,等等。
Elastic Cloud 上的 Elasticsearch Service 不但提供 Elastic Stack 的全部功能,而且您还能从中获取由开发公司提供的运行方面的专业知识。如尚未准备好扩展至新用例,您可以借助存储优化机会来继续使用您的集群。以相似的成本,您可以延长数据的保留期,存储更多内容;或者,您还可以轻点几下鼠标来在不牺牲数据可见性的前提下缩小集群规模,从而节约成本。
希望开始使用 Elastic Cloud 上的 Elasticsearch 服务?参加 14 天的免费试用活动,快速部署一个集群。