针对日志和指标对 Elasticsearch 集群进行基准测试并确定集群规模
使用 Elasticsearch,您可以轻松上手,迅速投入工作。当我构建第一个 Elasticsearch 集群时,几分钟内它就可以进行索引和搜索了。当我惊喜地发现我能这么快速地部署集群时,我的脑子里就已经升腾起接下来的步骤了。但随后我想到需要放慢节奏(有时我们需要这样提醒自己!),先弄清楚几个问题,然后再去超越自我。比如像这样的问题:
- 我有多大把握可确保该集群在生产环境中正常运行?
- 我的集群的吞吐量是多少?
- 它的性能如何?
- 我的集群中是否有足够的可用资源?
- 大小合适吗?
如果这些问题听起来很耳熟,那太好了!在将新产品部署到自己的生态系统中时,每个人应该思考这些问题。在本博文中,我们将深入探讨类似上面的性能、Elasticsearch 基准测试和规模大小等问题。我们不仅会“具体问题具体分析”,还会为您提供一套方法和建议,帮助您确定 Elasticsearch 集群的规模并对环境进行基准测试。因为规模确定练习是特定于每个用例制定的,所以我们将在这篇博文中重点介绍日志和指标。
像服务提供商一样思考
不管我们定义什么系统的架构,都需要对用例以及我们提供的功能有一个清晰的认知,这就是“像服务提供商一样思考”如此重要的原因 — 我们的服务质量是主要的关注点。此外,架构还可能会受到我们已有约束的影响,比如现有的硬件、公司的全球战略和许多其他约束条件,这些都是我们在规模确定练习中需要考虑的因素。
请注意,对于 Elastic Cloud 上的 Elasticsearch Service,我们将负责下面要介绍的大量维护工作和数据分层。此外,我们还提供了一个预定义的可观测性模板和一个复选框,以便将日志和指标发送到专用的监测集群。在跟随本博文学习的过程中,您可以随时部署一个免费试用版集群。
计算资源基础概念
性能取决于您使用 Elasticsearch 执行什么任务,以及您在什么平台上运行它。下面让我们先回顾一下有关计算资源的一些基础知识。对于每个搜索或索引操作,都会涉及到以下资源:
存储:保存数据的地方
- 建议尽可能使用 SSD,特别是那些运行搜索和索引操作的节点。由于 SSD 存储的成本较高,建议使用热温架构来减少支出。
- 在裸机上操作时,本地磁盘才是王道!
- Elasticsearch 不需要冗余存储(无需 RAID 1/5/10),日志和指标用例通常至少有一个副本分片,这是确保容错性的最低要求,同时又能最大限度地减少写入次数。
内存:缓存数据的地方
- JVM 堆:存储关于集群、索引、分片、段和 Fielddata 的元数据。该项较为理想的设置是可用 RAM 的 50%。
- OS 缓存:Elasticsearch 将使用剩余的可用内存来缓存数据,避免在全文搜索、对文档值执行聚合和排序期间多次读取磁盘,从而实现性能的极大提升。
计算:处理数据的地方
Elasticsearch 节点具有线程池和线程队列,它们会使用可用的计算资源。在 Elasticsearch 中,CPU 核心的数量和性能决定着数据操作的平均速度和峰值吞吐量。
网络:传输数据的地方
网络性能 — 带宽和延迟 — 会对节点间的通信和集群间的功能(如跨集群搜索和跨集群复制)产生影响。
按数据量确定规模
对于指标和日志用例,我们通常要管理大量的数据,因此,根据数据量来初步确定 Elasticsearch 集群规模是比较有意义的。在开始这个练习时,我们需要提出一些问题,以便更好地了解需要在集群中管理的数据。
- 我们每天将索引多大量的原始数据 (GB)?
- 我们会将数据保留多少天?
- 在热区保存几天?
- 在温区保存几天?
- 您将强制执行多少个副本分片?
在确定规模时,我们一般会增加 5% 或 10% 来容纳误差,并增加 15% 以保持在磁盘水位线之下。另外,我们还建议为硬件故障添加一个节点。
我们来计算一下
- 数据总量 (GB) = 每日原始数据量 (GB) * 保留天数 *(副本数 + 1)
- 存储总量 (GB) = 数据总量 (GB) *(1 + 0.15 磁盘水位阈值 + 0.1 误差幅度)
- 数据节点总数 = ROUNDUP(存储总量 (GB) /每个数据节点的内存/内存与数据值比)
在大规模部署的情况下,添加一个节点用于故障转移容量会更安全。
示例:确定小型集群的规模
您可能正在从一些应用程序、数据库、Web 服务器、网络和其他支持服务中提取日志和指标。假设每天提取 1GB 数据,并且需要将数据保留 9 个月。
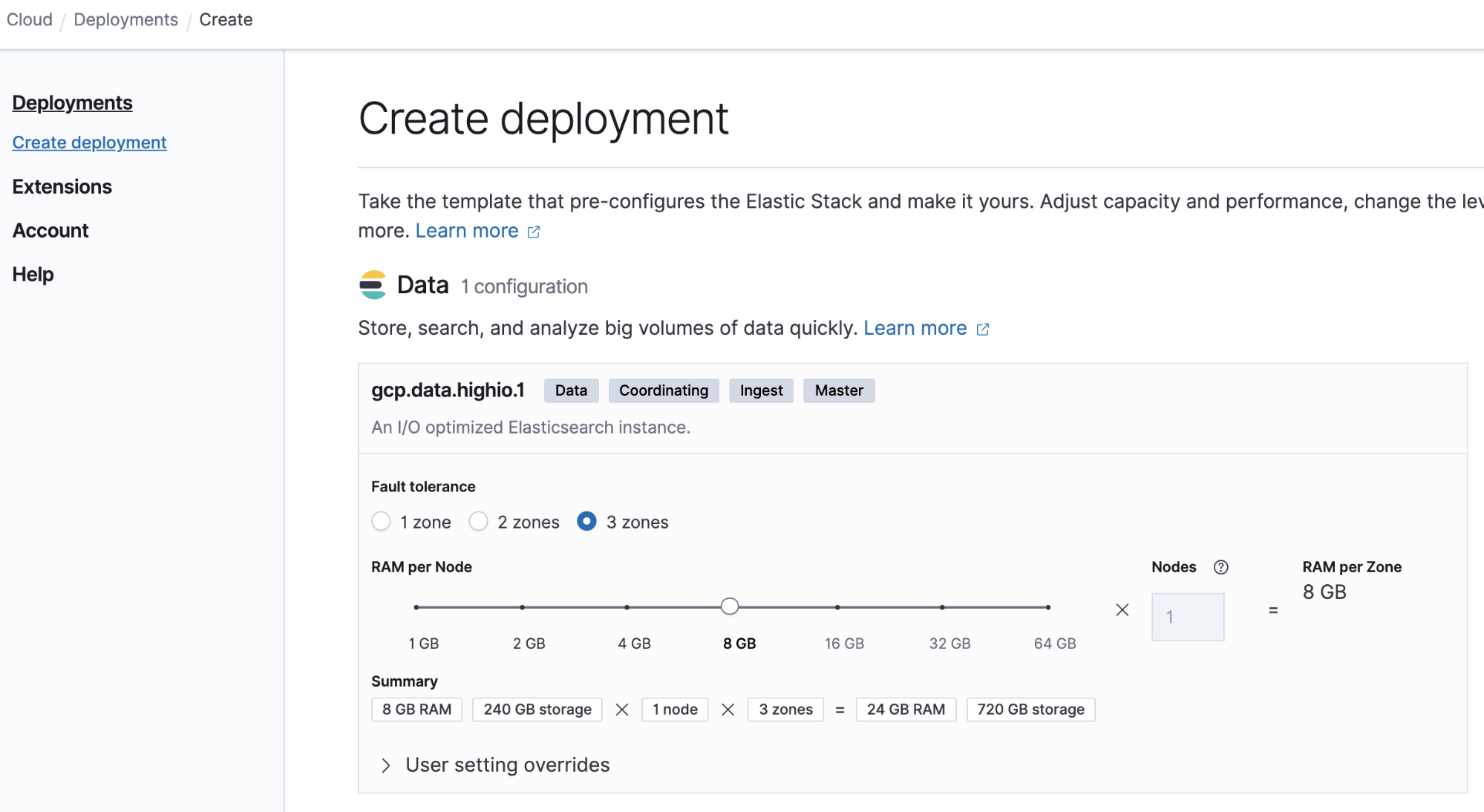
对于这个小型部署,每个节点可以使用 8GB 内存。我们来计算一下:
- 数据总量 (GB) = 1GB x(9 x 30 天)x 2 = 540GB
- 存储总量 (GB) = 540GB x (1+0.15+0.1) = 675GB
- 数据节点总数 = 675GB 磁盘存储量/ 8GB RAM /内存与数据比 30 = 3 个节点
让我们看看在 Elastic Cloud 上构建这个部署有多么简单:
示例:确定大型部署的规模
您成功构建小型部署之后,越来越多的合作伙伴希望使用您的 Elasticsearch 服务,所以您可能需要根据新的需求调整集群的规模。
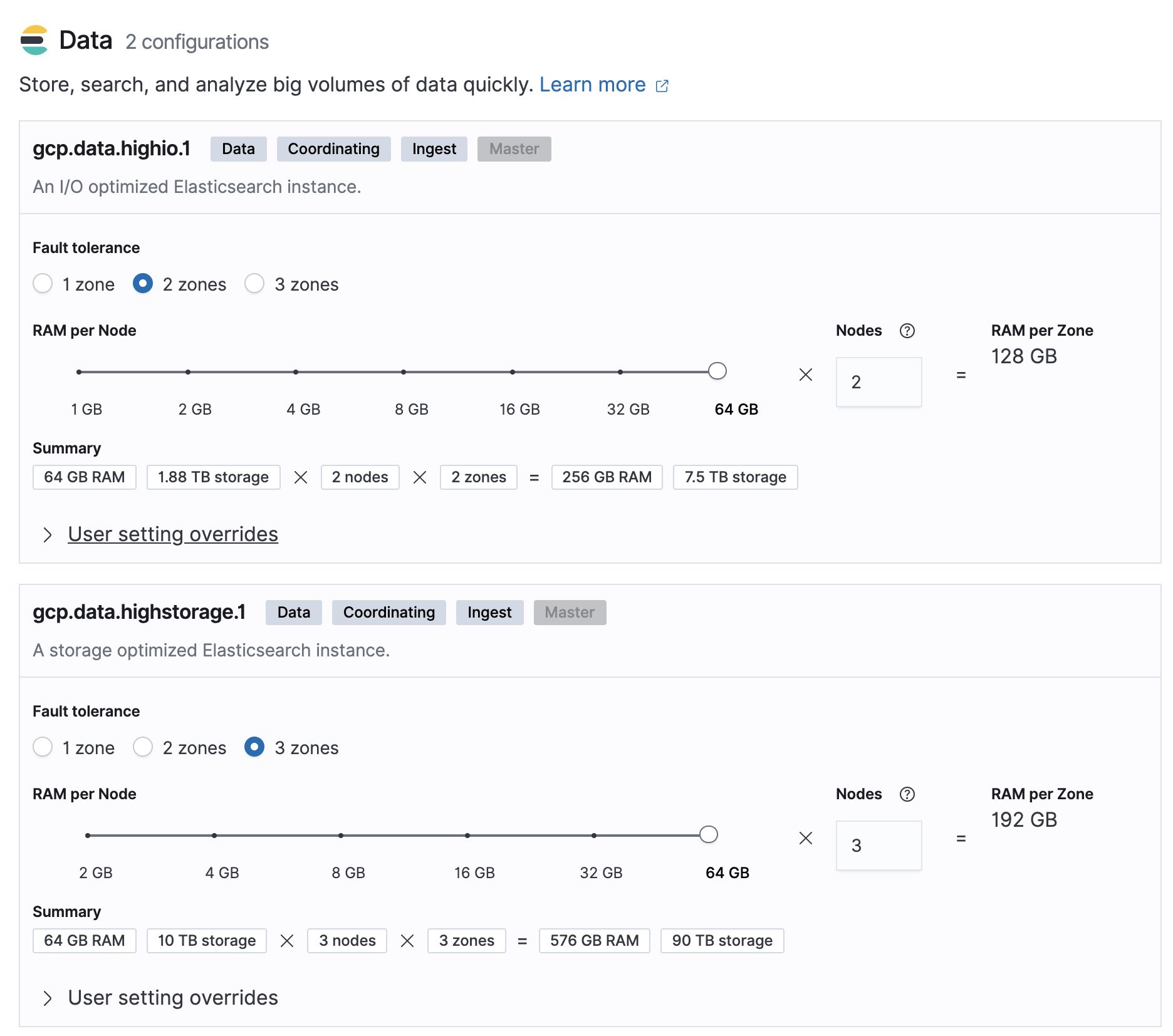
我们根据以下输入计算一下:
- 您每天会收到 100GB 的数据,并且需要将这些数据在热区中保存 30 天,在温区中保存 12 个月。
- 每个节点有 64GB 的内存,其中 30GB 分配给堆,其余分配给 OS 缓存。
- 所用热区内存与数据的典型之比是 1:30,温区是 1:160。
如果我们每天接收 100GB 的数据,并且必须将这些数据保存 30 天,那么我们会得出:
- 热区中的数据总量 (GB) =(100GB x 30 天 * 2)= 6000GB
- 热区中的存储总量 (GB) = 6000GB x (1+0.15+0.1) = 7500GB
- 热区中的数据节点总数 = ROUNDUP(7500 / 64 / 30) + 1 = 5 个节点
- 温区中的数据总量 (GB) =(100GB x 365 天 * 2)= 73000GB
- 温区中的存储总量 (GB) = 73000GB x (1+0.15+0.1) = 91250GB
- 温区中的数据节点总数 = ROUNDUP(91250 / 64 / 160) + 1 = 10 个节点
让我们看看在 Elastic Cloud 上构建这个部署有多么简单:
基准测试
至此,我们已经确定了适当的集群规模,我们接下来需要确认所得出的值在实际条件下能否成立。为了在投入生产环境之前更有把握,我们需要进行基准测试,以确认能够达到预期性能和目标 SLA。
在这项基准测试中,我们将采用 Elasticsearch 工程师使用的工具 — Rally。这个工具易于部署和执行,而且是完全可配置的,因此您可以测试多个场景。进一步了解如何在 Elastic 上使用 Rally。
为了简化结果分析,我们将基准测试分为两部分,即索引和搜索请求。
索引基准测试
对于索引基准测试,我们要尝试弄清楚以下几个问题:
- 集群的最大索引吞吐量是多少?
- 每天可以索引的数据量是多少?
- 集群是过大还是过小?
在这项基准测试中,我们将使用一个 3 节点集群,每个节点的配置如下:
- 8 vCPU
- 标准永久磁盘 (HDD)
- 32GB/16 堆
索引基准测试 1:
这项基准测试使用的数据集是 Metricbeat 数据,规格如下:
- 1,079,600 个文档
- 数据量:1.2GB
- 平均文档大小:1.17 KB
索引性能还将取决于索引层的性能,在本例中为 Rally。在本例中,我们将执行多次基准测试,以找出最优批量大小和最优线程数。
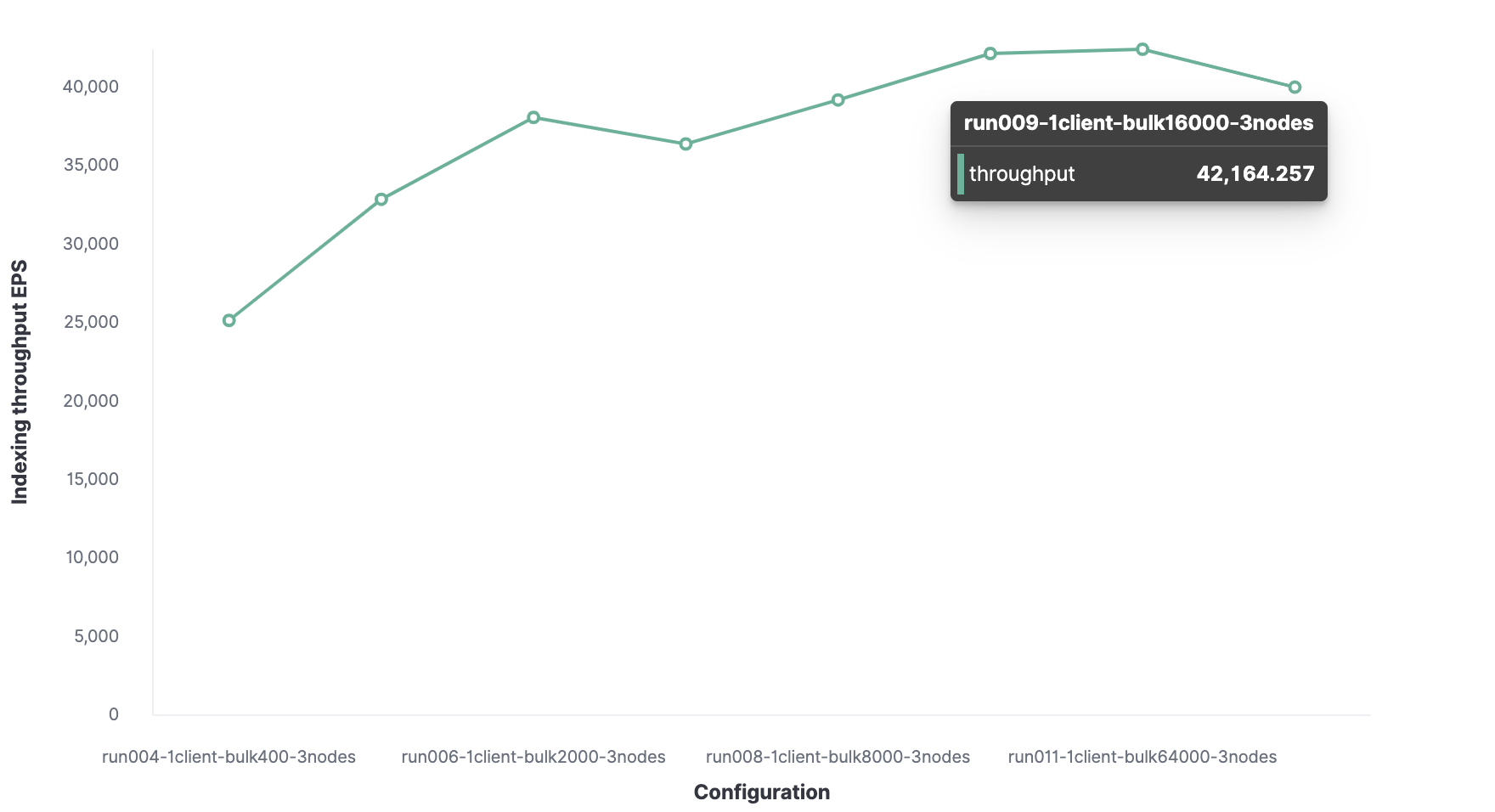
我们将先从 1 个 Rally 客户端开始,以找到最优批量大小。然后从 100 开始,在后续的运行中增加一倍,这可以看到我们的最优批量大小为 12,000(大约 13.7 MB),并且每秒可以索引到 13,000 个事件。
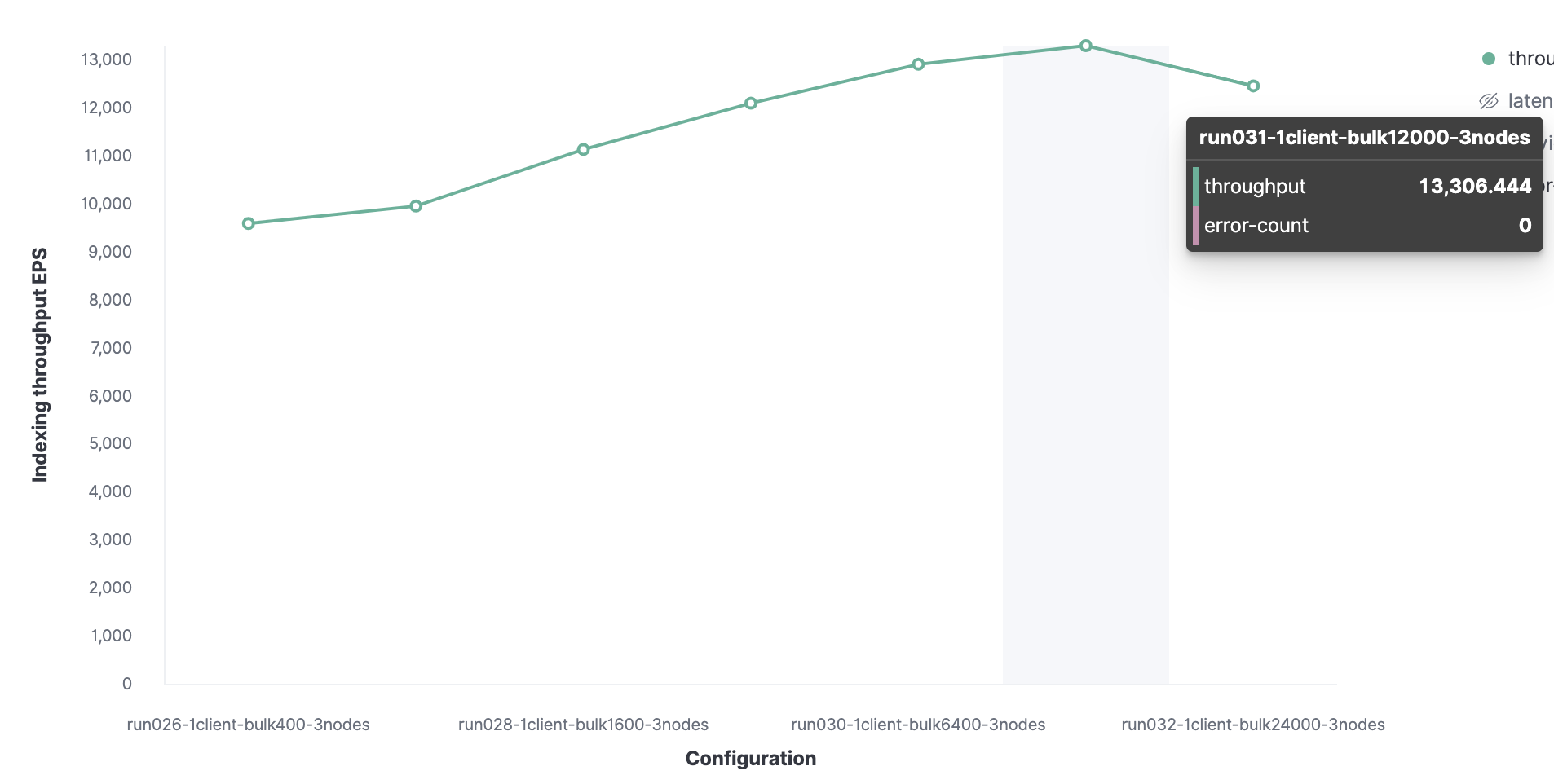
接下来,使用类似方法,我们发现客户端的最优数量是 16个,使我们可以达到每秒索引 62,000 个事件。
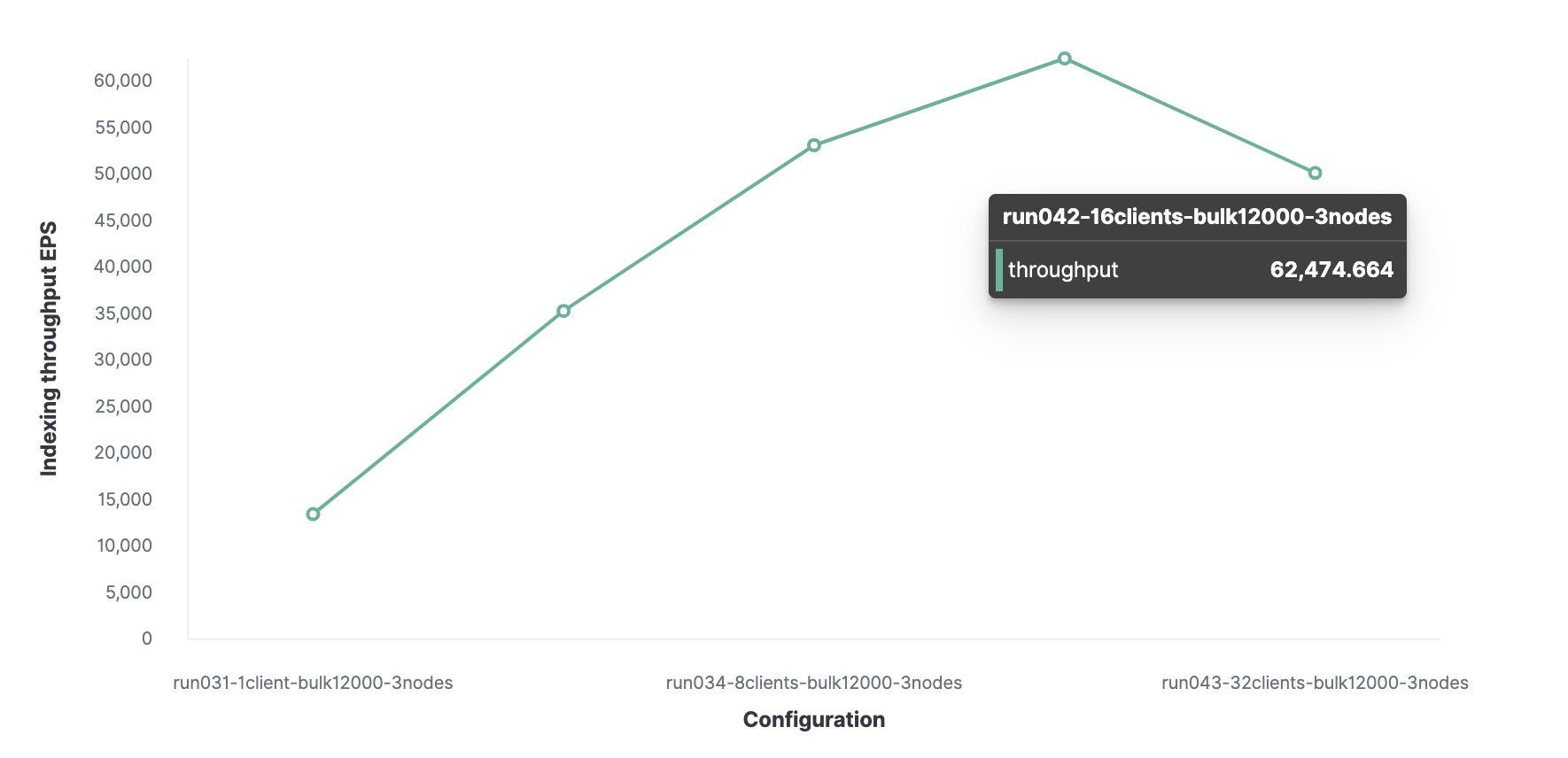
我们集群的最大索引吞吐量每秒可处理 62,000 个事件。为了更进一步,我们需要添加一个新节点。
我很想知道一个节点可以处理多少个索引请求,所以我在一个节点集群和两个节点集群上执行了相同的跟踪,看看有什么不同。
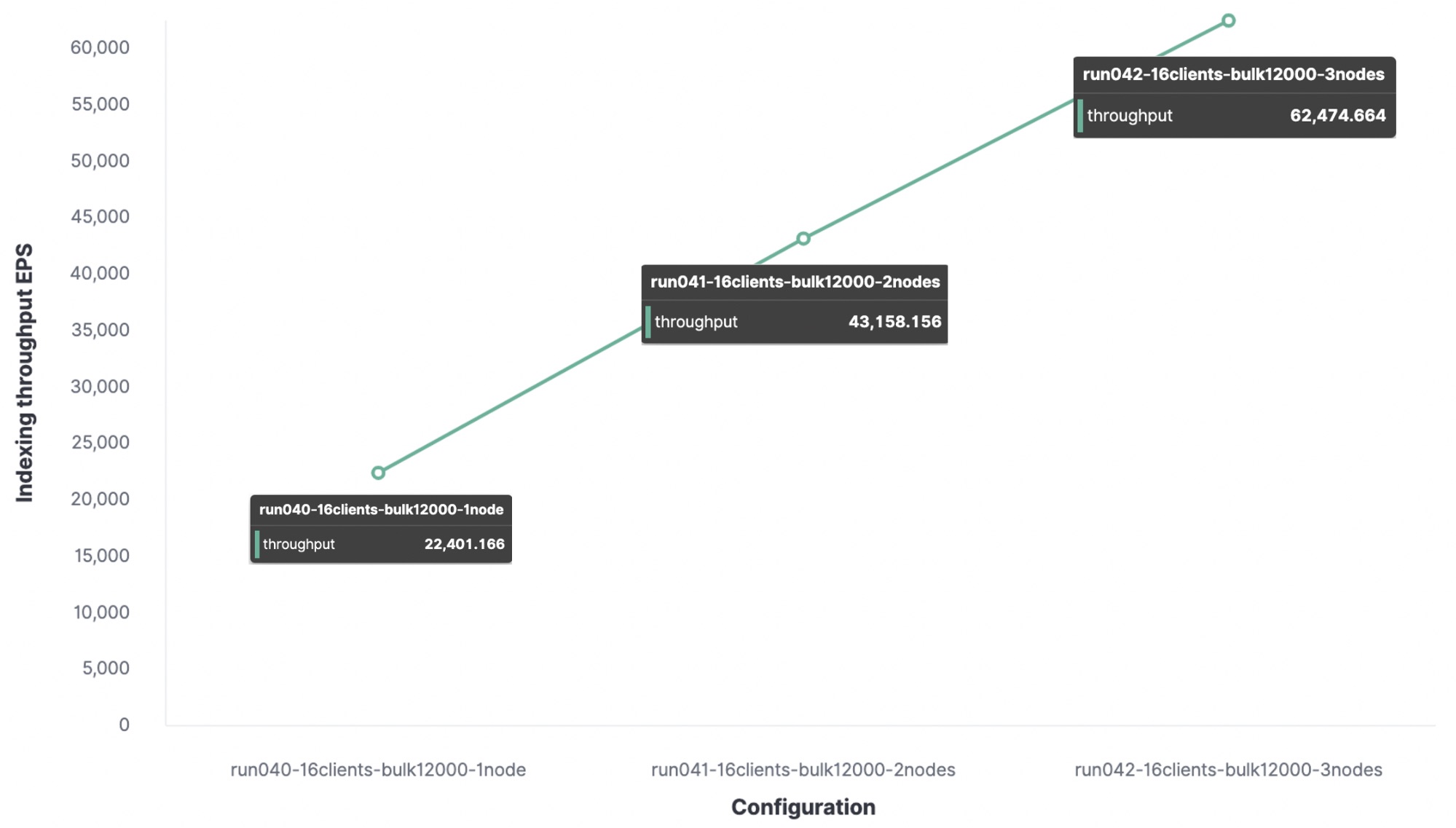
结论:在我的测试环境中,最大索引吞吐量为
- 使用 1 个节点和 1 个分片,我们每秒得到 22,000 个事件。
- 使用 2 个节点和 2 个分片,我们每秒得到 43,000 个事件。
- 使用 3 个节点和 3 个分片,我们每秒得到 62,000 个事件。
任何其他索引请求都会被放入队列中,当队列变满后,节点会发送拒绝响应。
我们的数据集会影响集群的性能,这就是为什么使用自己的数据执行这些跟踪非常重要。
索引基准测试 2:
在接下来的步骤中,我使用以下配置对 HTTP 服务器日志数据执行了相同的跟踪:
- 数据量:31.1GB
- 文档数:247,249,096
- 平均文档大小:0.8 KB
最优批量大小为 16,000 个文档。
得出的最优客户端数为 32 个。
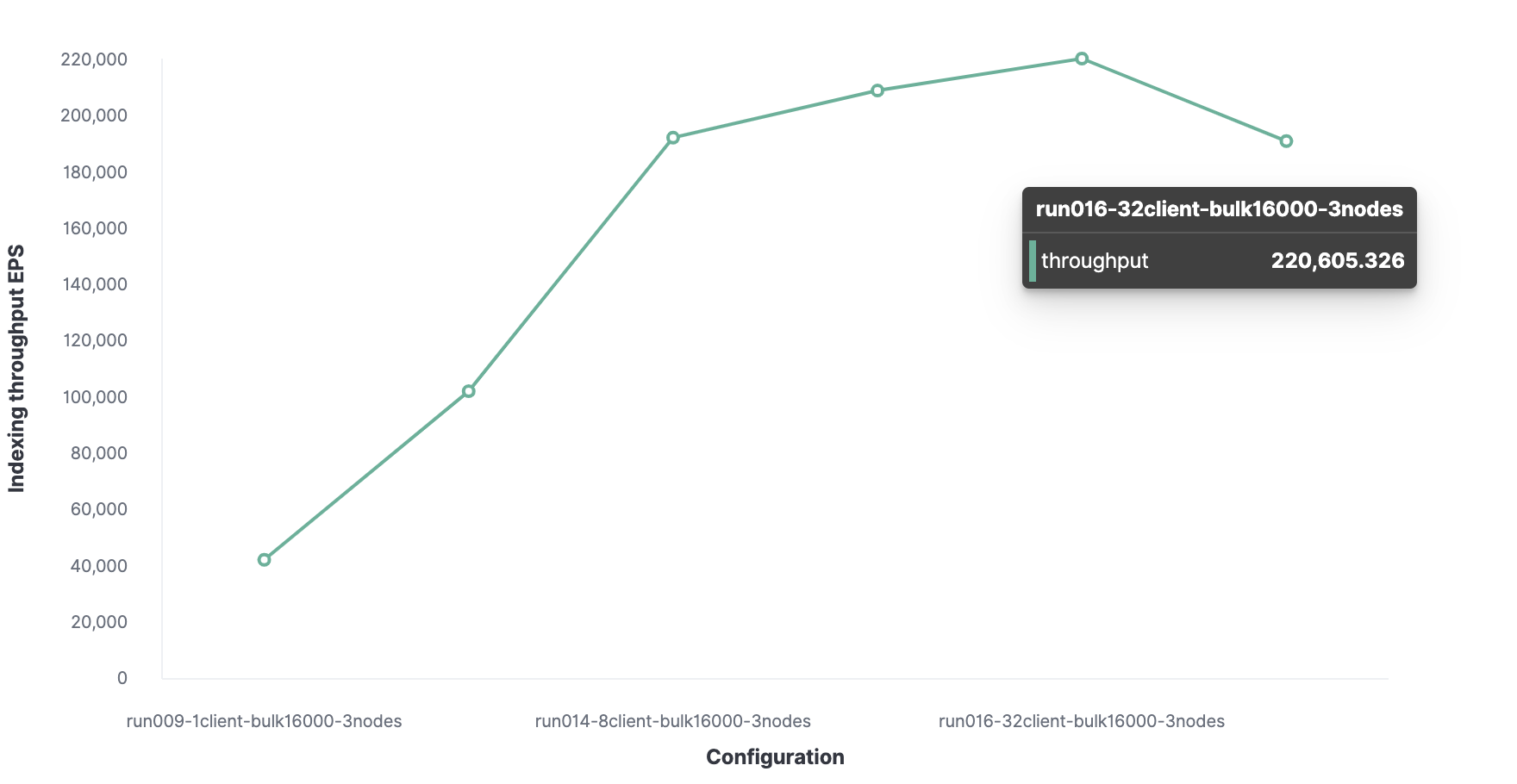
HTTP 服务器日志数据的最大索引吞吐量为每秒 220,000 个事件。
搜索基准测试
为了对搜索性能进行基准测试,我们将考虑使用 20 个客户端,目标吞吐量为 1000 OPS。
对于搜索,我们将执行三项基准测试:
1. 查询的服务时间
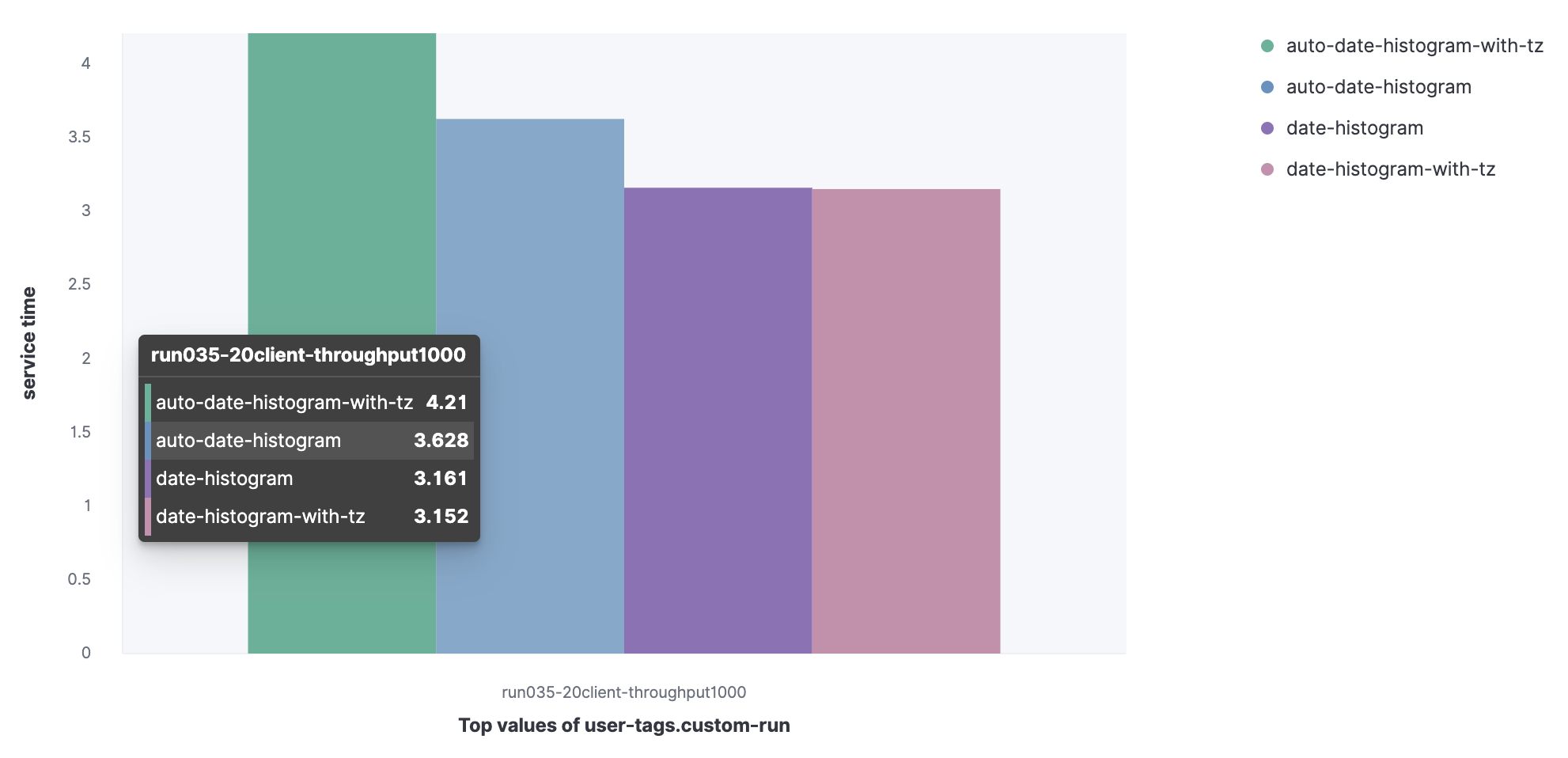
我们将比较一组查询的服务时间 (90%)。
Metricbeat 数据集
- auto-date-historgram
- auto-data-histogram-with-tz
- date-histogram
- Date-histogram-with-tz
我们可以观察到,auto-data-histogram-with-tz 查询的服务时间更长。
HTTP 服务器日志数据集
- Default
- Term
- Range
- Hourly_agg
- Desc_sort_timestamp
- Asc_sort_timestamp
我们可以观察到,desc_sort_timestamp and desc_sort_timestamp 查询的服务时间更长。
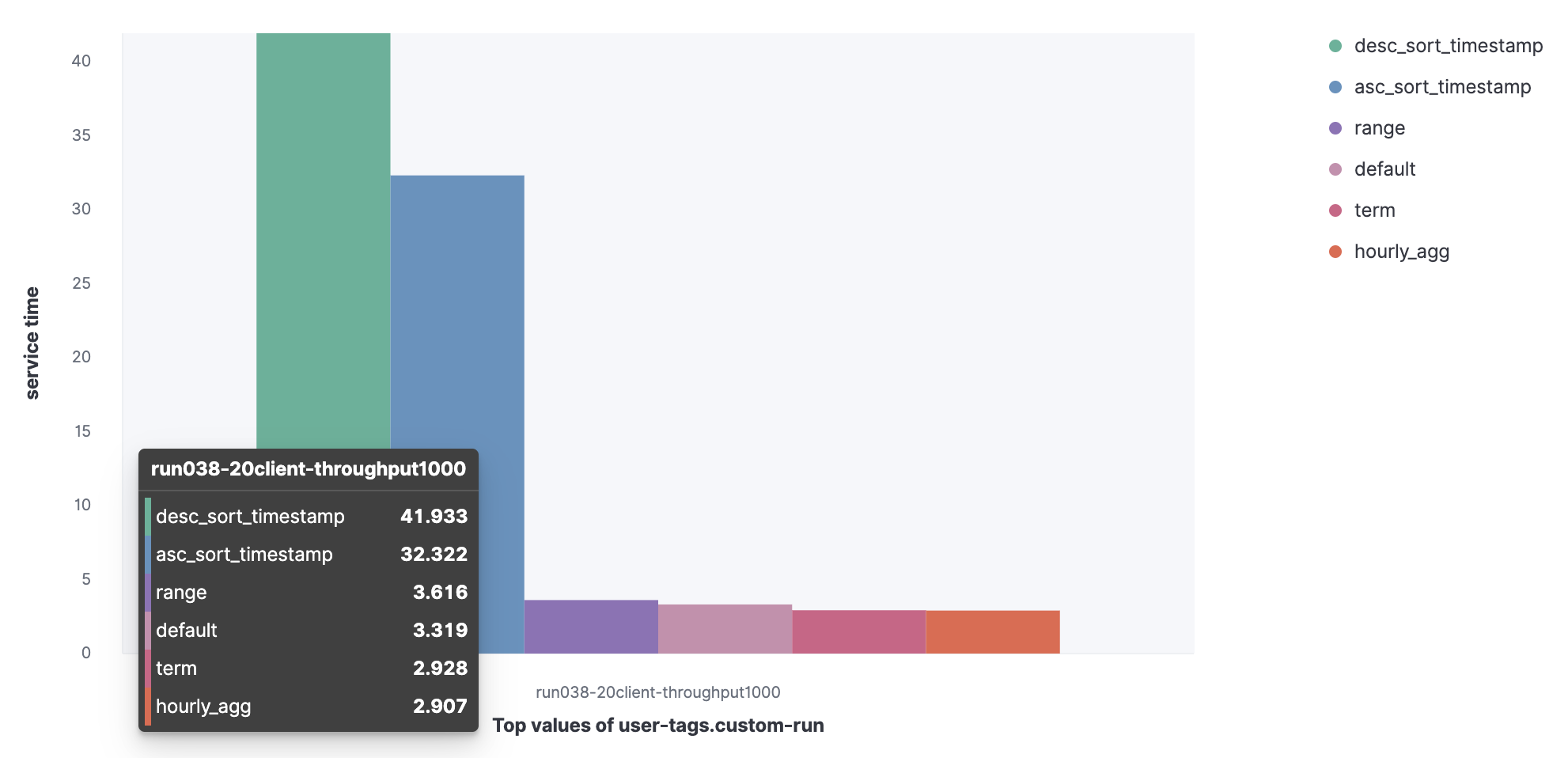
2. 并行查询的服务时间
我们来看看,如果并行执行查询,90% 服务时间会增加。
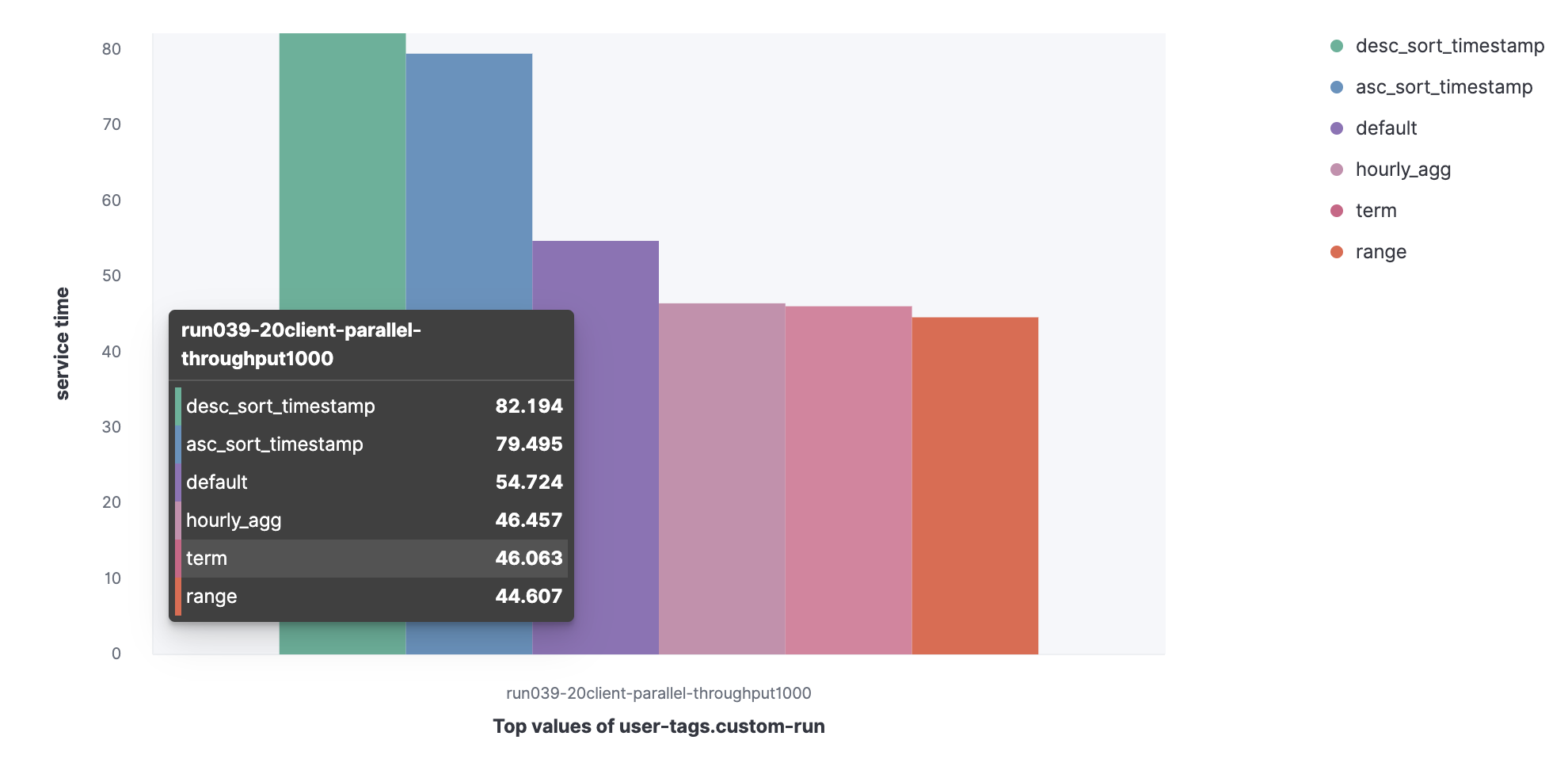
3. 并行索引的索引率和服务时间
我们将执行并行索引任务和搜索,以查看这些查询的索引率和服务时间。
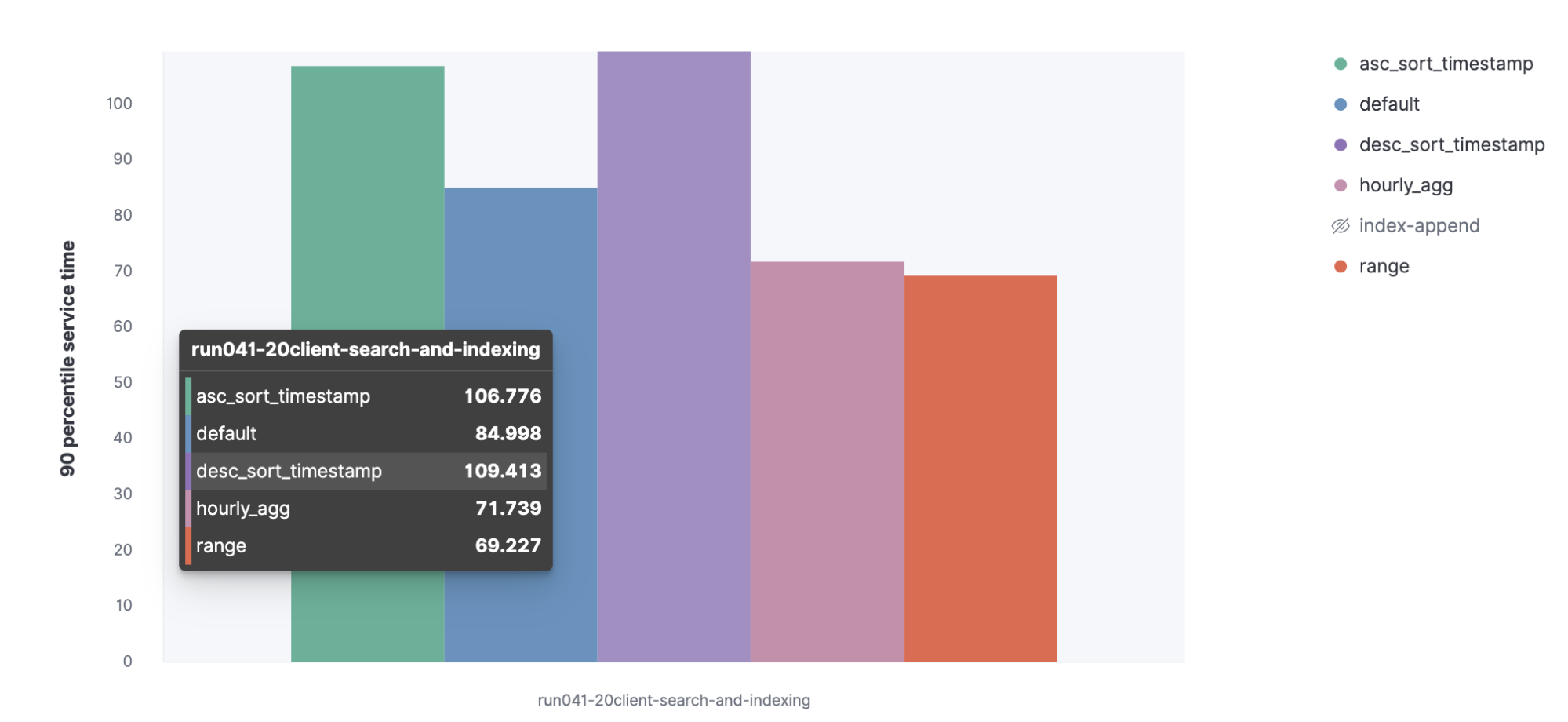
我们来看看,当与索引操作并行执行时,查询的 90% 服务时间会增加。
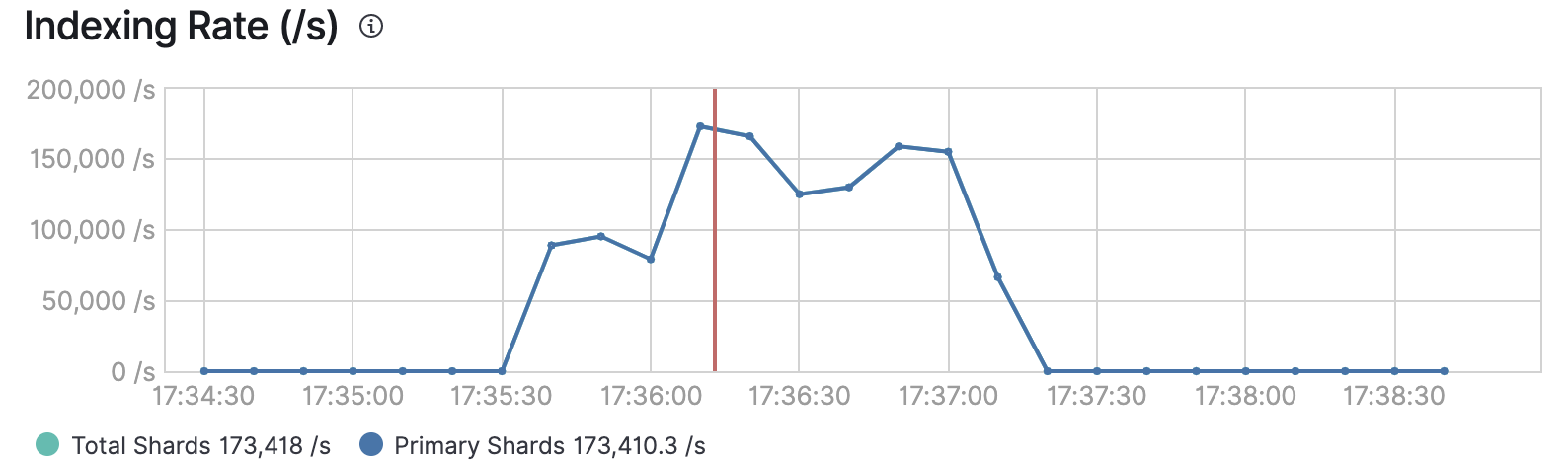
读取我们的结果
在 32 个客户端用于索引,20 个用户用于搜索时:
- 索引吞吐量为 173,000,小于先前提到的 220,000。
- 搜索吞吐量为每秒 1000 个事件。
结论
规模确定练习可为您提供一组方法,方便您根据数据量计算所需的节点数。为了更好地规划集群的未来性能,您还需要对基础架构进行基准测试 — 我们已经在 Elastic Cloud 中考虑到了这一点。由于性能还取决于您的用例,所以我们建议使用最接近实际情况的数据和查询进行测试。有关如何定义定制工作负载的详细信息,请参阅 Rally 文档。
在进行基准测试练习之后,您应该对基础架构性能有了更好的了解,所以可以继续微调 Elasticsearch 来提高索引速度。在本次点播网络研讨会中,请继续学习 Elasticsearch 规模确定和容量规划。