Elastic Machine Learning 中的用户注释
用户注释是 Elasticsearch 中的一个新的 Machine Learning 功能,从 6.6 版开始提供。它们提供了一种用描述性领域知识来改善 Machine Learning 作业的方法。当您运行一个 Machine Learning 作业时,它的算法会尝试发现异常,但是它不知道数据本身是关于什么的。 例如,该作业不知道它是在处理 CPU 用量还是网络吞吐量。用户注释提供了一种利用用户对数据的了解来增加结果的方法。
在这篇博客文章中,我们将向您展示用户注释是如何工作的,以及如何将它们应用于不同的用例。我们将分析来自 Hydro Online 的数据,这是一个由奥地利蒂罗尔地方政府运营的开放数据门户。Hydro Online 提供了一个界面来调查天气传感器数据,如累积降雨量、河流高度或积雪总量。如我们之前的一篇博客文章中所述,文件数据可视化工具提供了一种从 CSV 数据中采集数据的强大方法,如本例所示。
使用方法
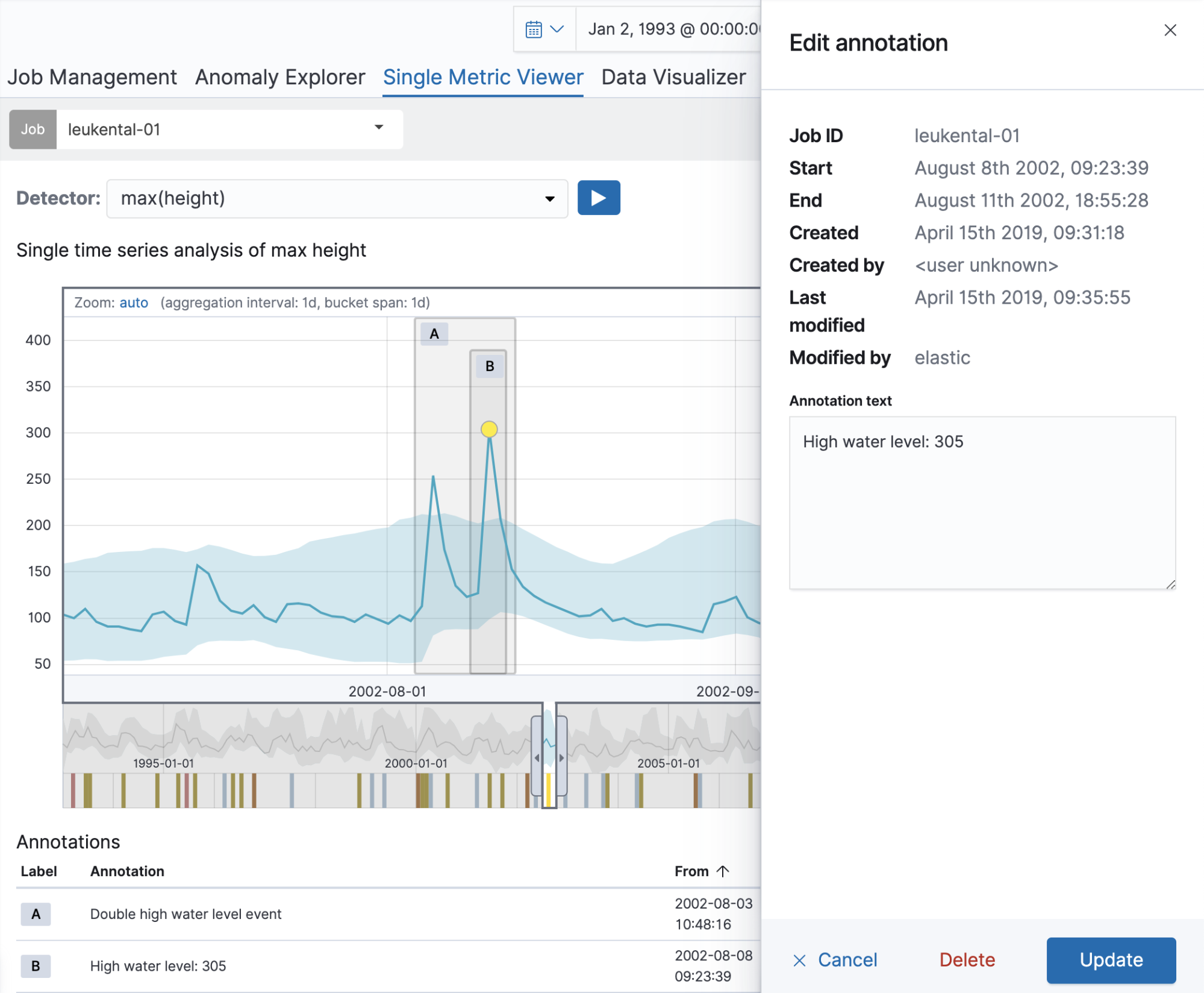
让我们从一个单一的度量工作开始,分析穿过科森村的格罗斯切河的河流高度测量值。创建作业后,可以使用单一指标查看器向分析结果添加注释。只需在图表中的时间范围内拖动即可创建注释。右侧将出现一个弹出式元素,可用于添加自定义描述。在下面的例子中,我们注释了一个异常的河流高度(那天发生了一场大洪水)。通过创建注释,您可以向其他用户提供这些信息。
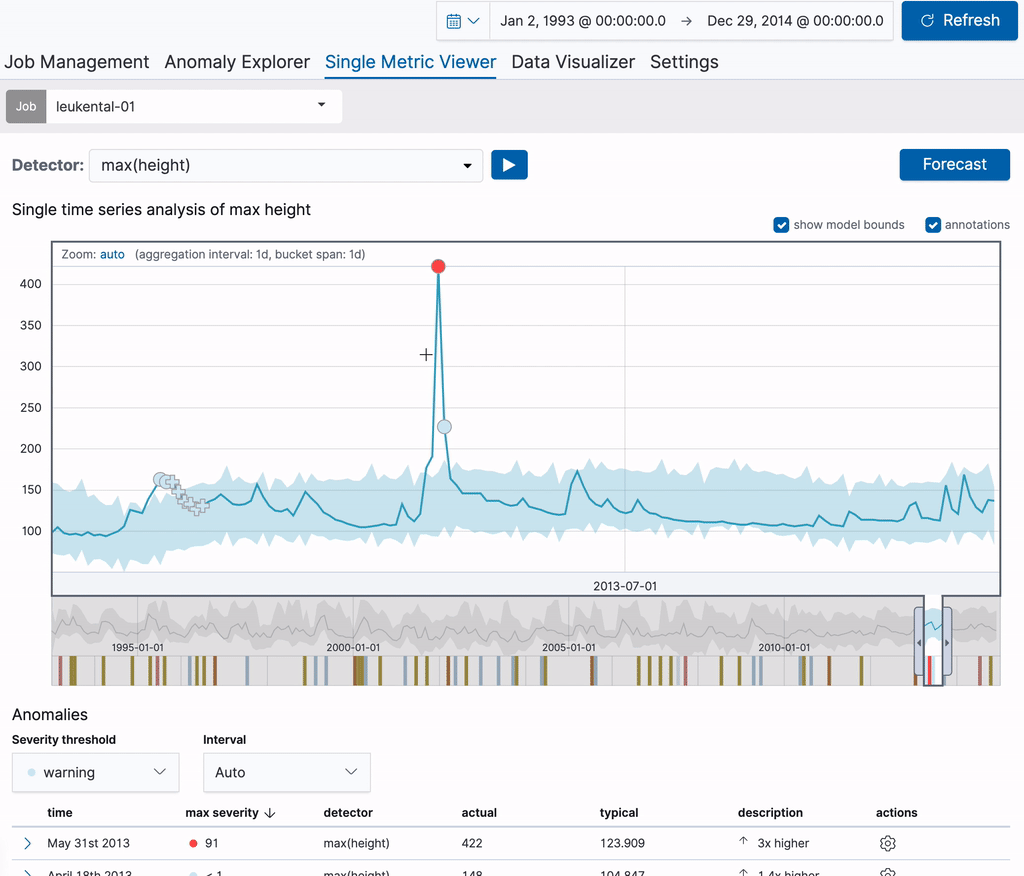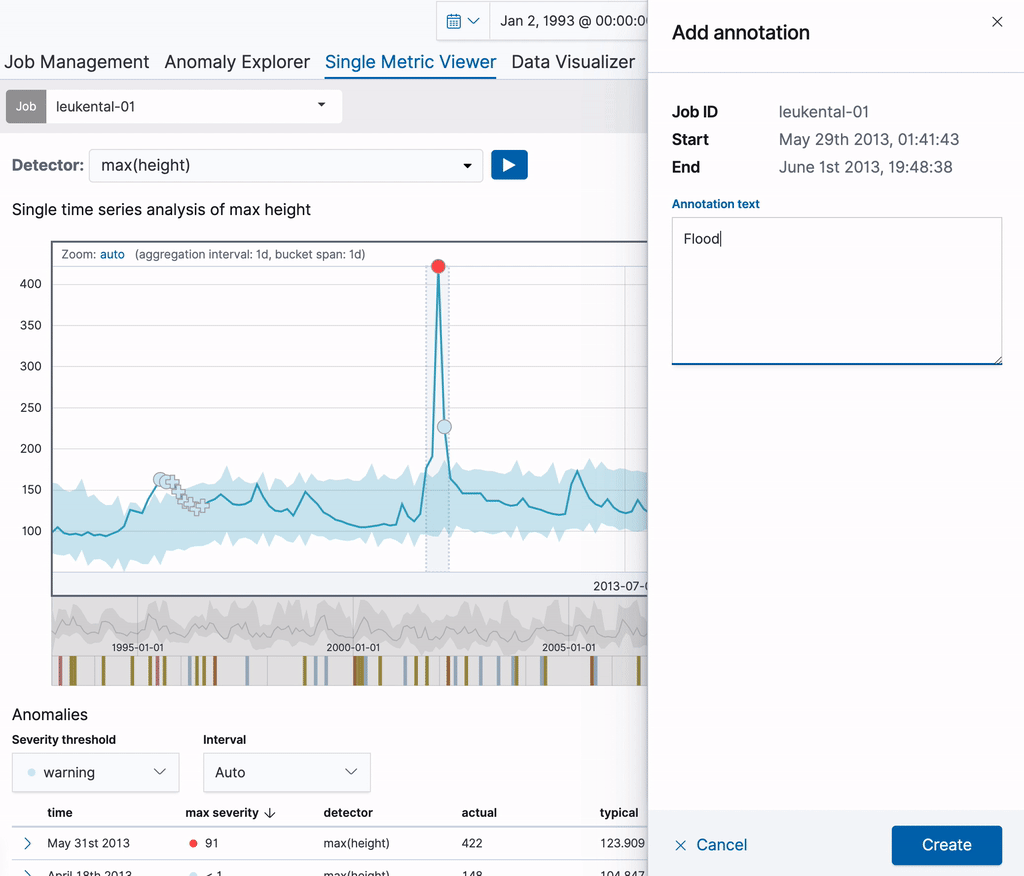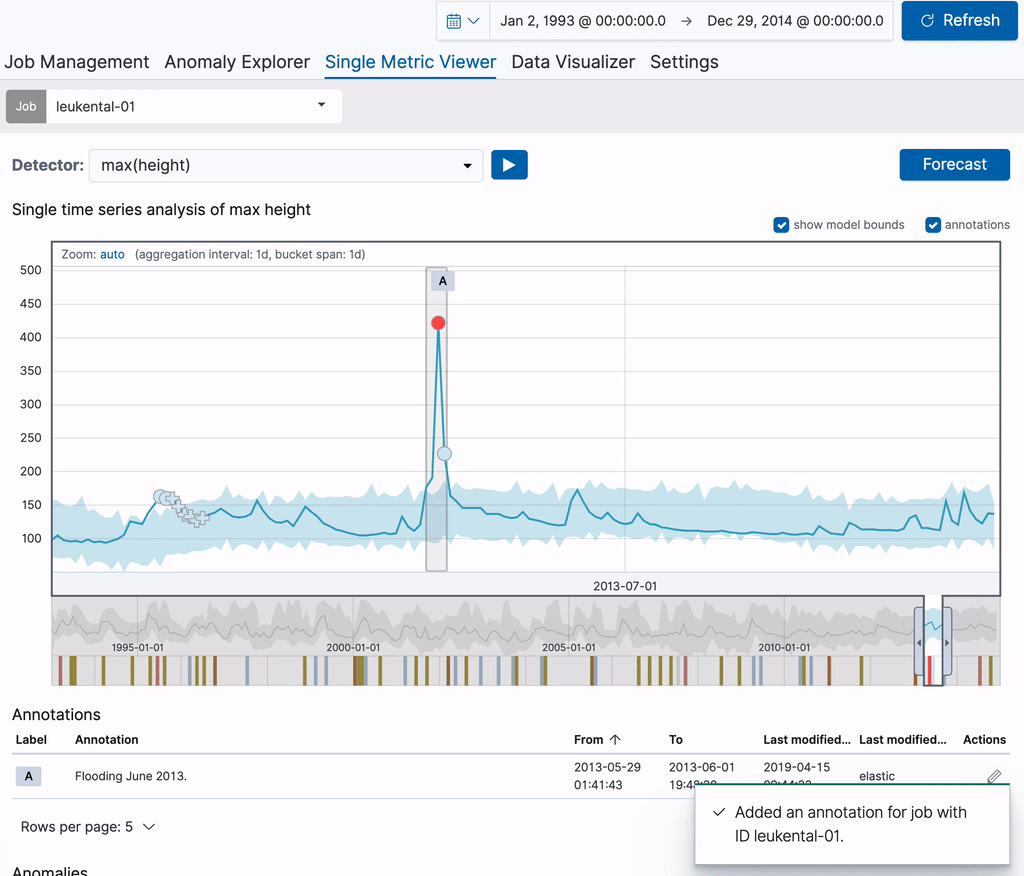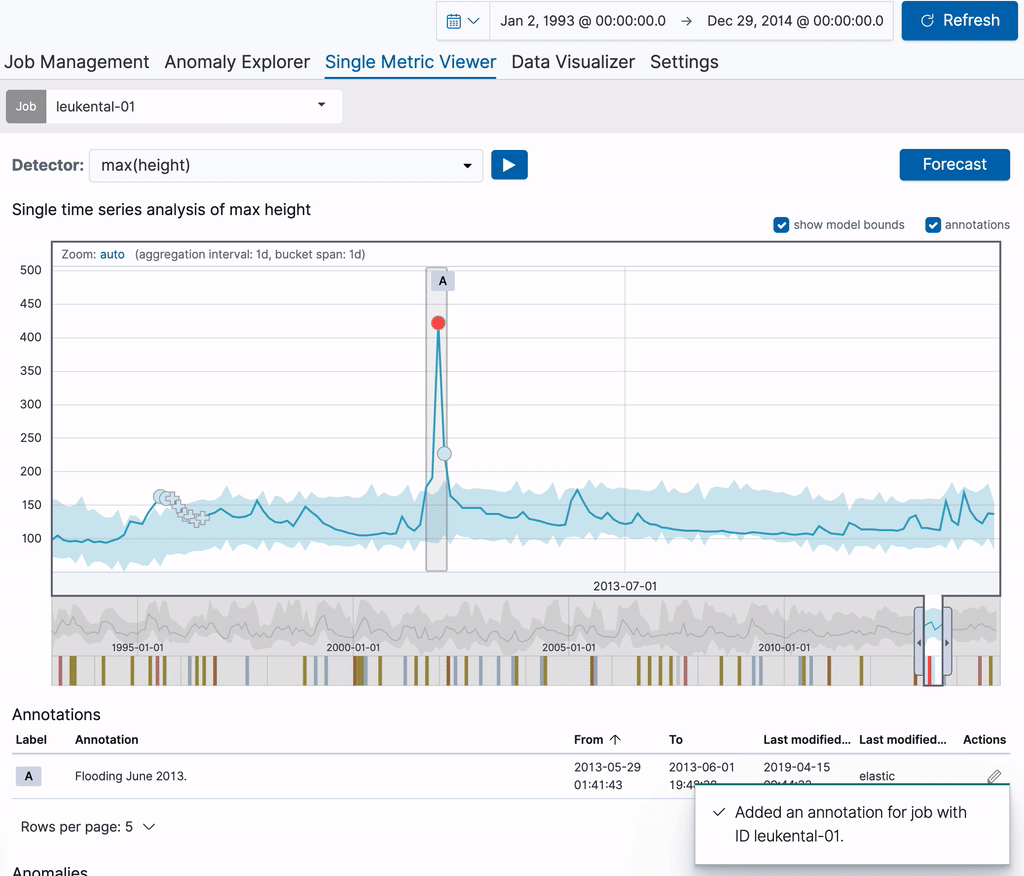
注释在图表本身及其下方的“Annotations”(注释)表中都可见。表格第一列中可见的标签可用于标识图表中的注释。这些标签是为显示的注释动态创建的。将鼠标悬停在“注释”表中的一行上时,相应的注释也会在上面的图表中高亮显示。
还可以从“作业管理”页面访问为每个作业创建的注释,在该页面中,通过展开作业列表中的一行,注释会显示在自己的选项卡中。对于表格中的每个注释,右侧列中都有一个链接,通过该链接可返回到单一指标查看器,并重点查看注释所覆盖的时间范围。这些永久链接也可以与其他人共享。这意味着您可以使用注释来创建特定异常的书签,以便以后重新访问它们。

如果有多个注释覆盖同一时间范围,注释将在图表中垂直分布,以避免重叠。要编辑或删除注释,只需在图表中单击该注释即可。弹出元素将再次在右侧打开,您可以在那里编辑文本或删除注释。从 6.7 开始,这也可以通过使用注释表中的编辑按钮来完成,使该功能也可以从作业管理页面获得。
既然我们已经介绍了如何创建和使用用户注释的基本功能,让我们继续讨论一些更多的用例。
使用注释来验证预期的异常
注释可以用来提供一个基本的事实,以验证Machine Learning作业是否产生了预期的结果。在以下示例中,我们再次查看 Hydro Online 中的河流水位数据,现在目标是自动覆盖历史事件,作为异常结果的注释。例如,作为一名数据科学家,您的工作可能包括获取和准备您想要分析的源数据以及验证结果的数据集。
为了我们自己的分析,我们需要原始数据集。
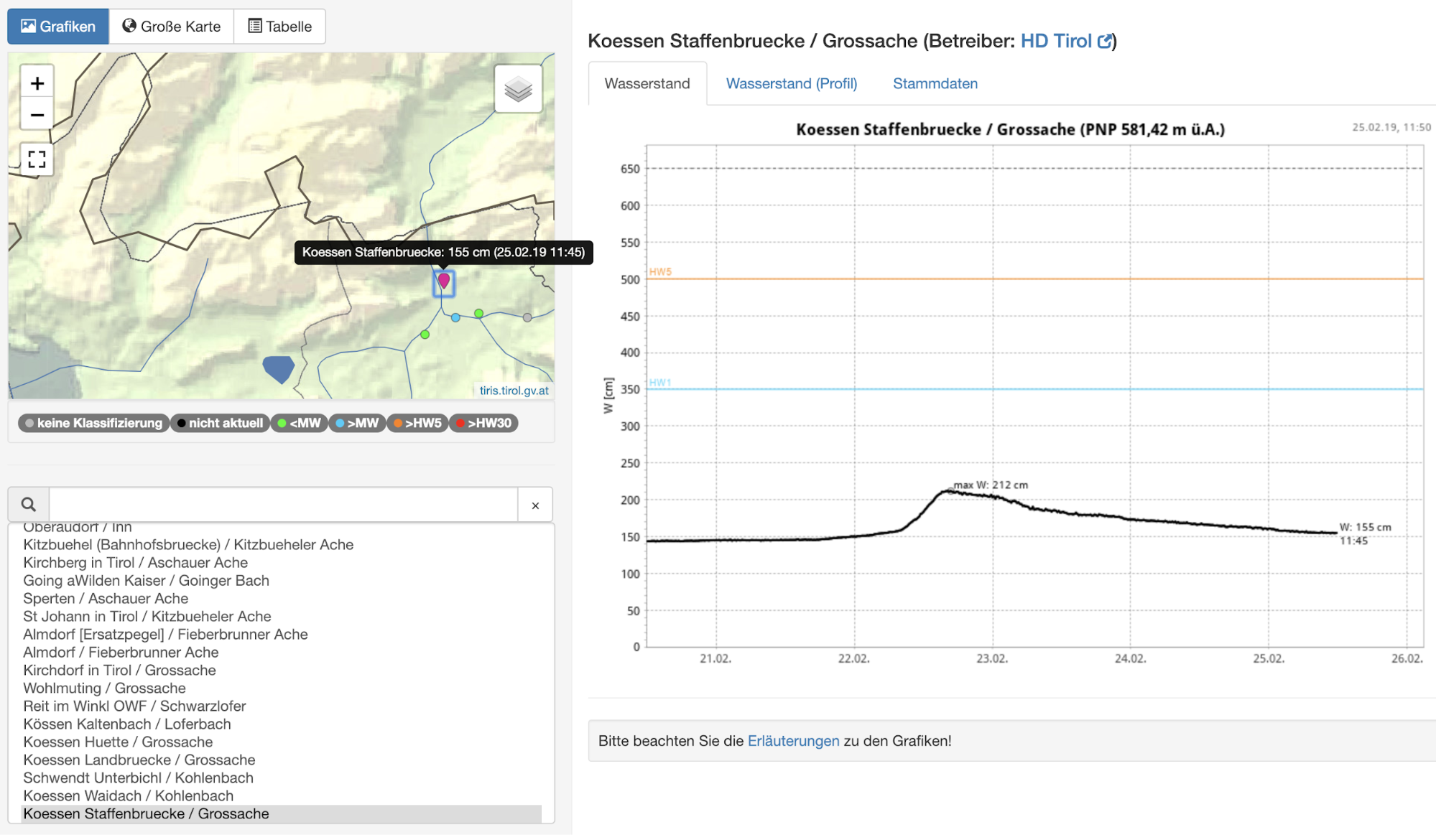
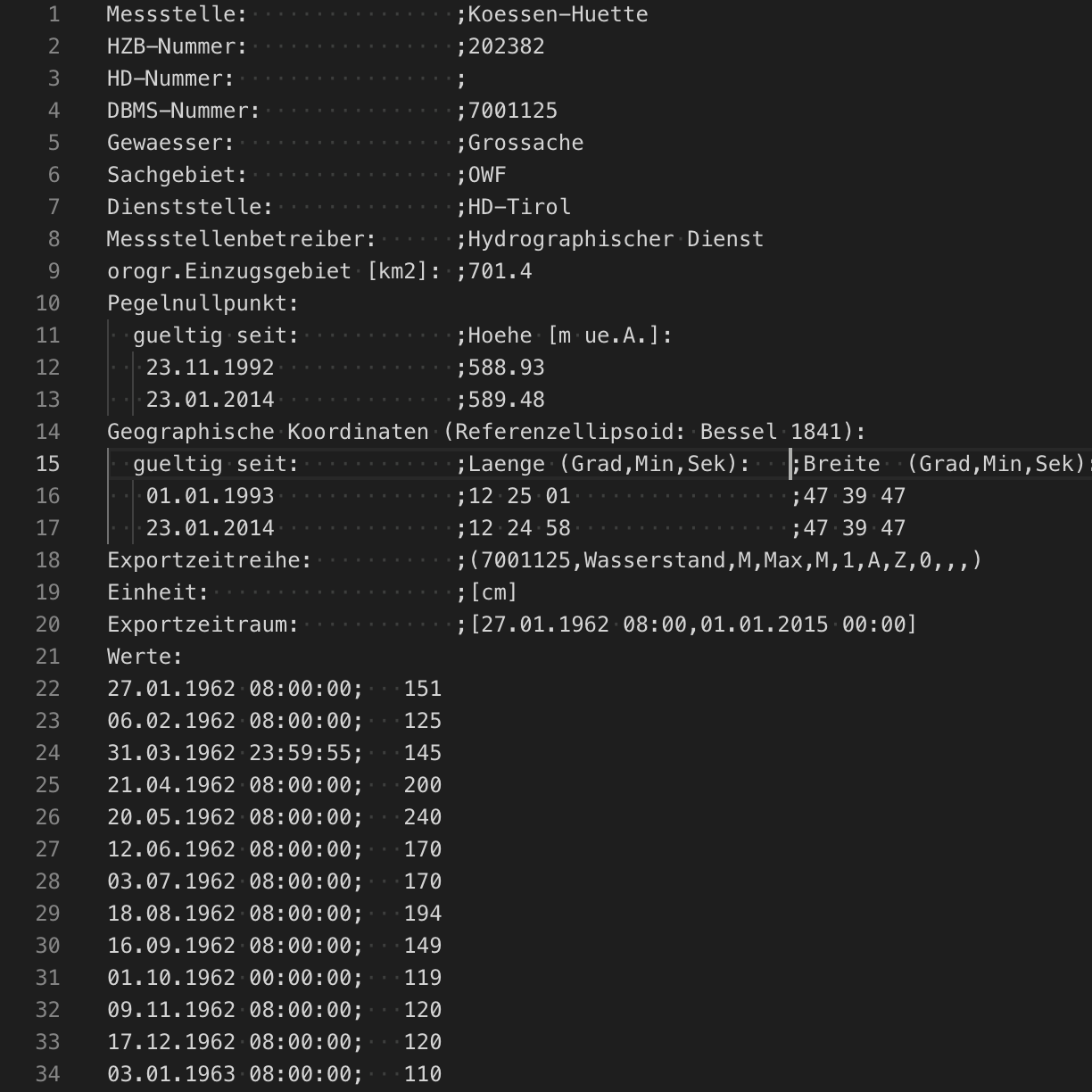
幸运的是,在这种情况下,除了通过网络界面调查数据,我们还可以下载历史数据进行进一步分析。对于本例,我们将使用在 “Huette” 测量点测量的格罗斯切河的河高数据。从涵盖所需地面真相的注释将从描述严重河流高度和洪水的文件中创建。
|

|
除了使用前面描述的用户界面,Machine Learning 注释作为文档存储在单独的标准 Elasticsearch 索引中。 注释也可以使用标准的 Elasticsearch API 以编程方式或手动方式创建。注释存储在版本特定的索引中,应该通过别名<code>.ml-annotations-read 和 .ml-annotations-write 访问。对于本例,我们将在创建 Machine Learning 作业之前添加注释来反映历史河流事件。
{
"_index":".ml-annotations-6",
"_type":"_doc",
"_id":"DGNcAmoBqX9tiPPqzJAQ",
"_score":1.0,
"_source":{
"timestamp":1368870463669,
"end_timestamp":1371015709121,
"annotation":"2013 June; 770 m3/s; 500 houses flooded.",
"job_id":"annotations-leukental-4d-1533",
"type":"annotation",
"create_time":1554817797135,
"create_username":"elastic",
"modified_time":1554817797135,
"modified_username":"elastic"
}
}
现在,我们将创建一个 Machine Learning 作业,使用与上面注释中的作业_id字段匹配的名称来查找最大河流高度的异常,以便获取手动创建的注释。一旦我们将历史河流数据采集到 Elasticsearch 索引中,该作业在单一指标向导中的外观如下:
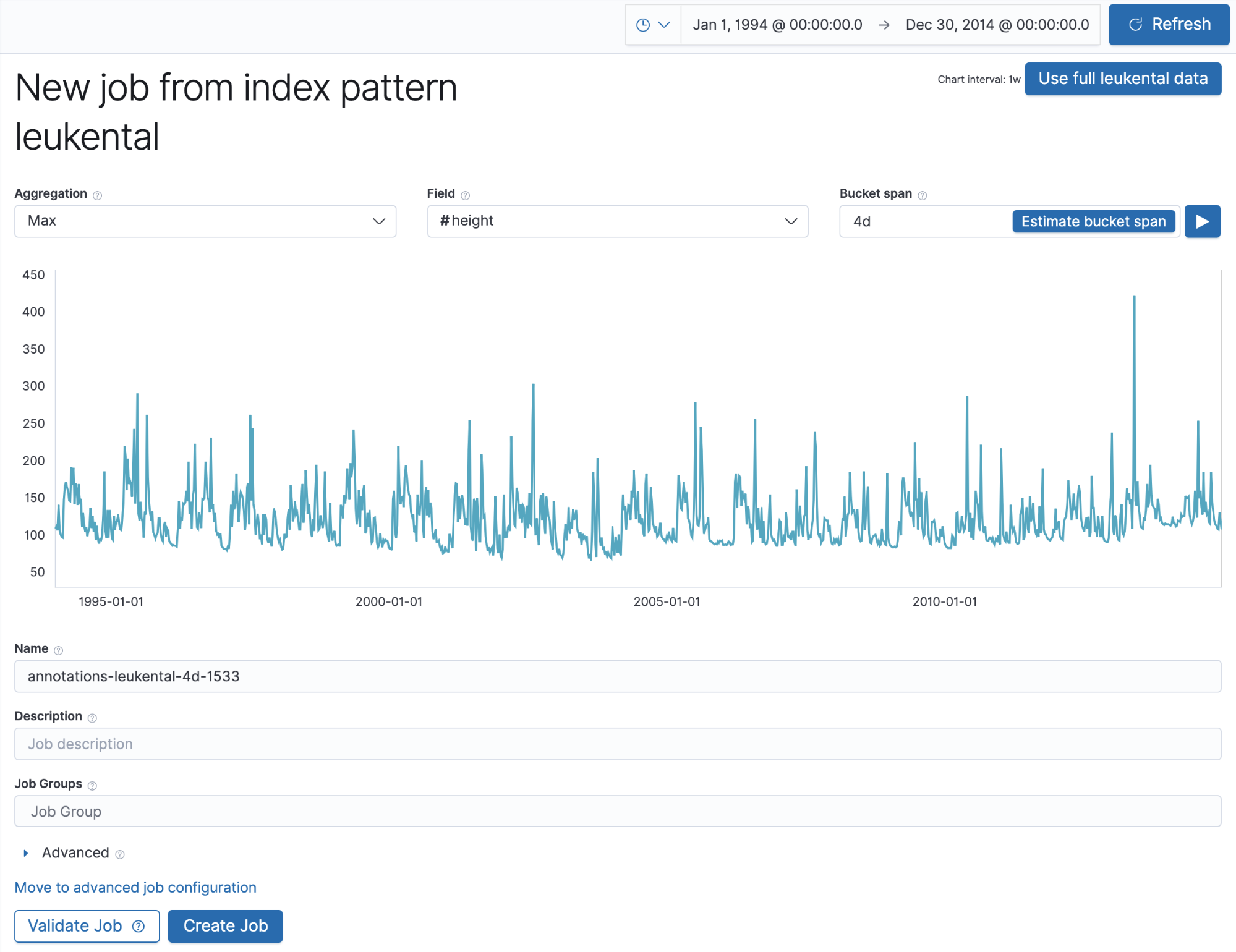
这里重要的一点是,我们选择的作业名称与注释中使用的名称相匹配。一旦我们运行作业并移动到单一指标查看器,我们应该会看到与 Machine Learning 作业检测到的河流高度异常相对应的注释:
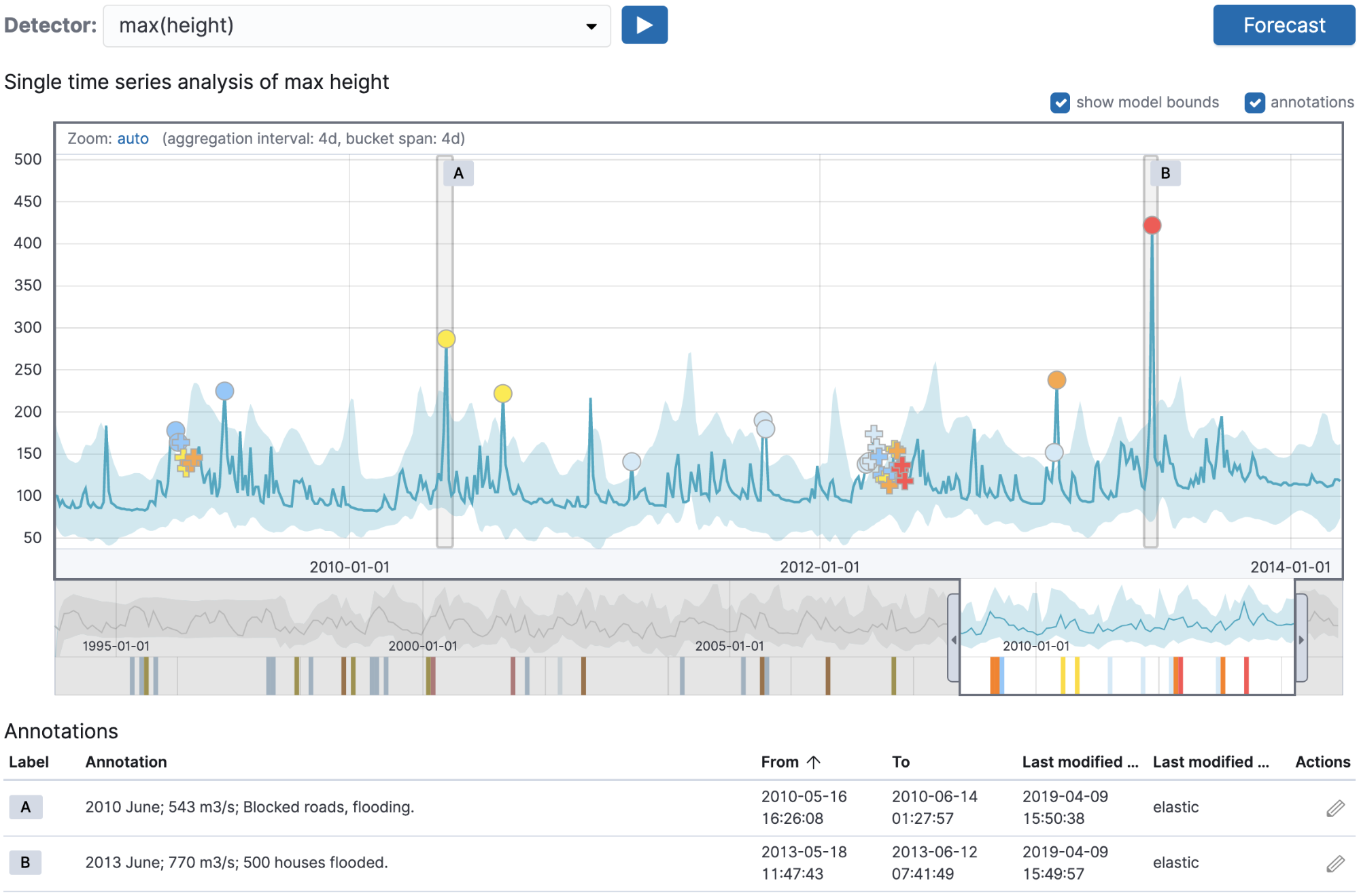
这种技术提供了一种很好的方法来验证您正在运行的分析与作为注释存储的现有验证数据相比是否有效。
系统事件的注释
除了上面用户生成的注释之外,Machine Learning 后端在某些情况下会自动为系统事件创建注释。
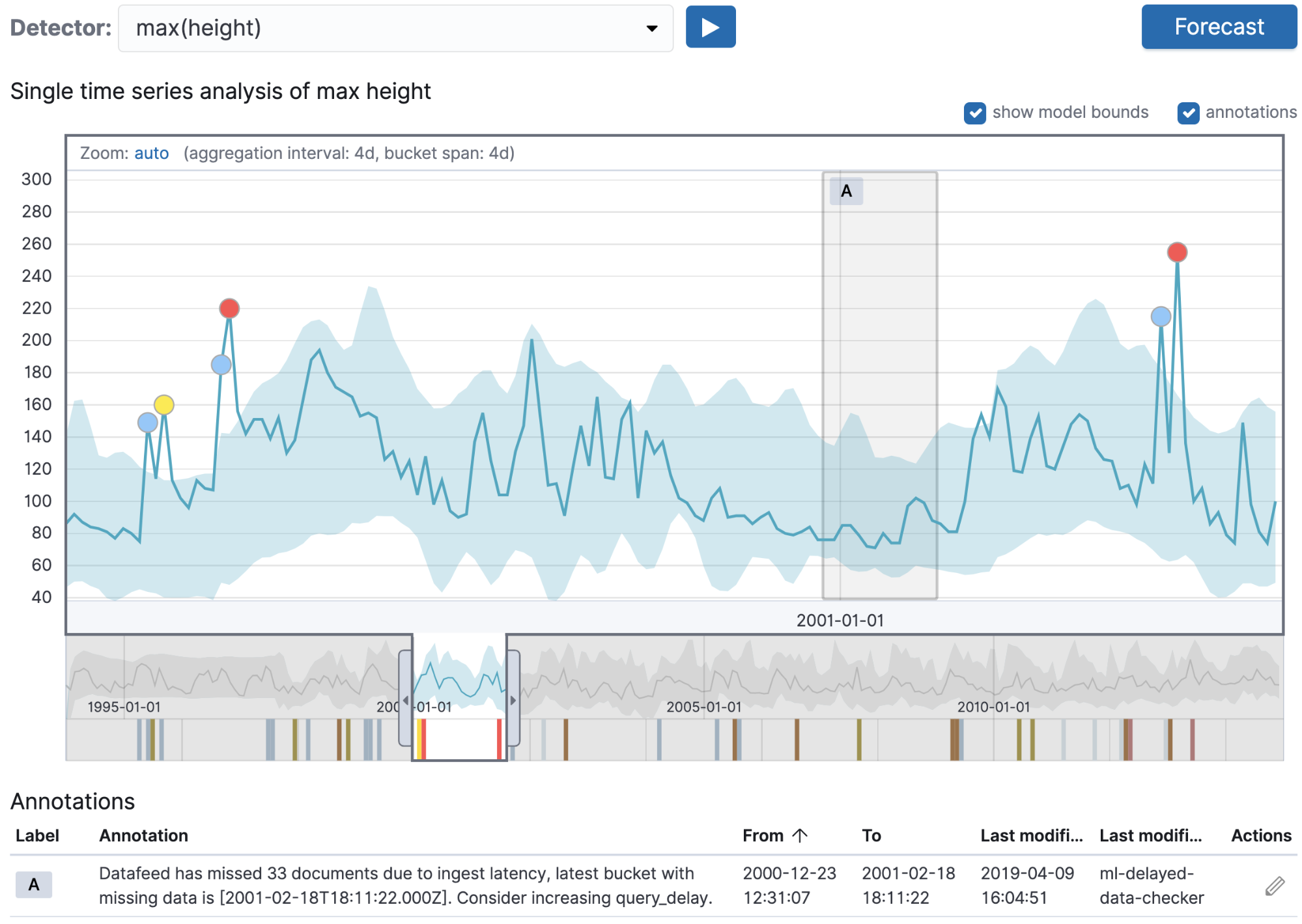
上面的截图显示了一个自动创建注释的例子。在这种情况下,运行了一个实时 Machine Learning 作业,但是数据采集无法跟上作业所需的采集速率。这意味着在作业对桶进行分析后,文档被添加到索引中。自动创建的注释突出了这个以前很难发现和调试的问题。注释文本特性详细说明了识别出的问题,并提供了解决问题的建议——在这种情况下,增加了 query_delay 设置。
警报整合
即使在 Machine Learning 的用户注释可用之前,您也可以使用 Watcher 根据 Machine Learning 作业识别的异常创建警报。虽然与基本阈值上的警报相比,这是一个很大的改进,但是对于接收警报的目标组来说,警报可能过于精细。作为 Machine Learning 作业的用户,注释可以为您提供一种方法,来管理什么被触发为观察者警报,什么被传递给其他利益相关者。由于注释存储在它们自己的 Elasticsearch 索引中,您可以使用 Watcher 简单地对索引中新创建的文档做出反应并触发通知。Watcher 还可以配置为向 Slack 通道发送警报。以下配置为您提供了一个示例,说明如何创建一个监视,以便在创建新注释时触发 Slack 消息:
{
"trigger": {
"schedule": {
"interval":"5s"
}
},
"input": {
"search": {
"request": {
"search_type": "query_then_fetch",
"indices": [
".ml-annotations-read"
],
"rest_total_hits_as_int": true,
"body": {
"size":1,
"query": {
"range": {
"create_time": {
"gte": "now-9s"
}
}
},
"sort": [
{
"create_time": {
"order": "desc"
}
}
]
}
}
}
},
"condition": {
"compare": {
"ctx.payload.hits.total": {
"gte":1
}
}
},
"actions": {
"notify-slack": {
"transform": {
"script": {
"source": "def payload = ctx.payload; DateFormat df = new SimpleDateFormat(\"yyyy-MM-dd'T'HH:mm:ss.SSS'Z'\"); payload.timestamp_formatted = df.format(Date.from(Instant.ofEpochMilli(payload.hits.hits.0._source.timestamp))); payload.end_timestamp_formatted = df.format(Date.from(Instant.ofEpochMilli(payload.hits.hits.0._source.end_timestamp))); return payload",
"lang": "painless"
}
},
"throttle_period_in_millis":10000,
"slack": {
"message": {
"to": [
"#<slack-channel>"
],
"text":"New Annotation for job *{{ctx.payload.hits.hits.0._source.job_id}}*: {{ctx.payload.hits.hits.0._source.annotation}}",
"attachments": [
{
"fallback":"View in Single Metric Viewer http://<kibana-host>:5601/app/ml#/timeseriesexplorer?_g=(ml:(jobIds:!({{ctx.payload.hits.hits.0._source.job_id}})),refreshInterval:(pause:!t,value:0),time:(from:'{{ctx.payload.timestamp_formatted}}',mode:absolute,to:'{{ctx.payload.end_timestamp_formatted}}'))&_a=(filters:!(),mlSelectInterval:(interval:(display:Auto,val:auto)),mlSelectSeverity:(threshold:(color:%23d2e9f7,display:warning,val:0)),mlTimeSeriesExplorer:(zoom:(from:'{{ctx.payload.timestamp_formatted}}',to:'{{ctx.payload.end_timestamp_formatted}}')),query:(query_string:(analyze_wildcard:!t,query:'*')))",
"actions": [
{
"name": "action_name",
"style": "primary",
"type": "button",
"text":"View in Single Metric Viewer",
"url": "http://<kibana-host>:5601/app/ml#/timeseriesexplorer?_g=(ml:(jobIds:!({{ctx.payload.hits.hits.0._source.job_id}})),refreshInterval:(pause:!t,value:0),time:(from:'{{ctx.payload.timestamp_formatted}}',mode:absolute,to:'{{ctx.payload.end_timestamp_formatted}}'))&_a=(filters:!(),mlSelectInterval:(interval:(display:Auto,val:auto)),mlSelectSeverity:(threshold:(color:%23d2e9f7,display:warning,val:0)),mlTimeSeriesExplorer:(zoom:(from:'{{ctx.payload.timestamp_formatted}}',to:'{{ctx.payload.end_timestamp_formatted}}')),query:(query_string:(analyze_wildcard:!t,query:'*')))"
}
]
}
]
}
}
}
}
}
在上面的配置中,只需用您的设置替换 <slack-chahhel> 和<kibaha-host>,并使用它创建高级观察。设置好所有内容后,每次创建新注释时,您都应该会收到一个 Slack 通知,包括注释文本和返回到单一指标查看器的链接。

结论
本文介绍了Elasticsearch Machine Learning 的新注释特性。它可以用于通过用户界面添加注释,也可以用于通过后端任务触发的系统注释。这些注释可通过作业管理页面作为书签使用,并可作为链接与其他人共享。注释可以通过编程方式从外部数据创建,用作检测到的异常的基本事实叠加。最后,结合 Watcher 和 Elasticsearch 中的 Slack 动作,我们已经看到了如何使用注释来管理警报。享受注释的乐趣,如果您有任何问题,请访问讨论论坛。