Logstash 实用介绍
Elastic Stack 竭尽全力让您能够轻松地向 Elasticsearch 导入数据。Filebeat 是处理文件的一款出色工具,并且配有一个模块集,通过此模块集,您只需进行极少配置,即能导入广泛的常见格式的日志。如果您希望导入的数据不在这些模块的支持范围之内,Logstash 和 Elasticsearch Ingest 节点为您提供了一种强大且不失灵活的方法,助您解析并处理大部分的文本数据类型。
在这篇博文中,我们将会简要介绍 Logstash,并向您展示如何用它来开发配置以解析某些 Squid 缓存的访问日志样本,并将这些日志导入到 Elasticsearch 中。
Logstash 简要概述
Logstash 是一款基于插件的数据收集和处理引擎。Logstash 配有大量的插件,以便人们能够轻松进行配置以在多种不同的架构中收集、处理并转发数据。
处理过程可分为一个或多个管道。在每个管道中,会有一个或多个输入插件接收或收集数据,然后这些数据会加入内部队列。默认情况下,这些数据很少并且会存储于内存中,但是为了提高可靠性和弹性,也可进行配置以扩大规模并长期存储在磁盘上。
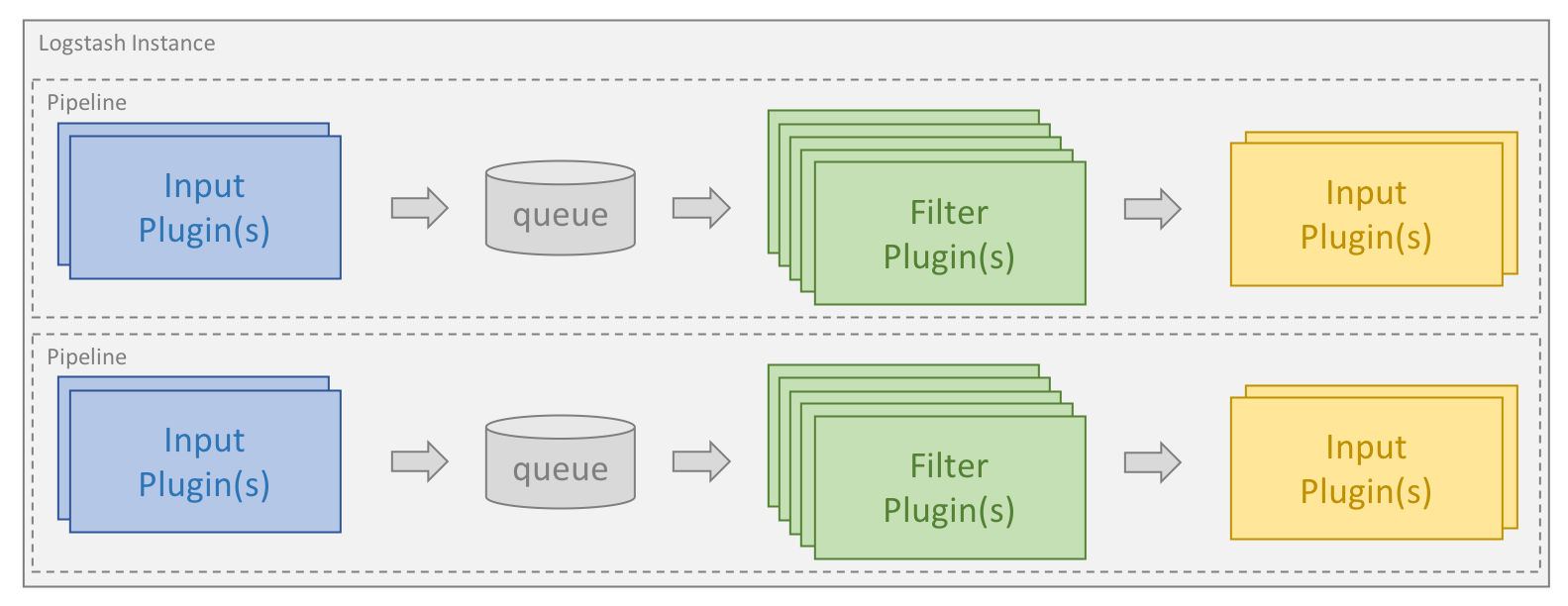
处理线程会以小批量的形式从队列中读取数据,并通过任何配置的过滤插件按顺序进行处理。Logstash 自带大量的插件,能够满足特定类型的操作需要,也就是解析、处理并丰富数据的过程。
处理完数据之后,处理线程会将数据发送到对应的输出插件,这些输出插件负责对数据进行格式化并进一步发送数据(例如发送到 Elasticsearch)。
输入和输出插件也可以配置 codec 插件。这样便可以在将数据添加到内部队列或发送到输出插件之前对数据进行解析和/或格式化。
安装 Logstash 和 Elasticsearch
为了运行这篇博文中的示例,我们首先需要安装 Logstash 和 Elasticsearch。我们在链接中提供了安装说明,请按照说明在您的操作系统上进行安装。我们使用的是 Elastic Stack 6.2.4 版本。
指定管道
Logstash 管道是根据一个或多个配置文件来创建的。在开始之前,我们将会带您快速了解一下有哪些可选项。在此部分中所提到的目录可能会有所不同,具体取决于安装模式和操作系统,已经在此文档中进行了定义。
使用单一配置文件创建单一管道
Logstash 入门的最简单方法是让 Logstash 基于我们在 -f 命令行参数中指定的单一配置文件创建单一管道,这也是我们在本篇博文中贯彻始终所用的方法。
使用多个配置文件创建单一管道
还可将 Logstash 配置为使用特定目录中的所有文件作为配置文件。您可以通过两种方式来完成此配置,既可以使用 logstash.yml,也可以使用 -f 命令行参数来将目录路径传递到整个命令行中。如果您安装的是“Logstash 即服务”,这将是默认设置。
对于特定目录,目录中的所有文件将会按照词典顺序连接在一起,然后 Logstash 会将其作为单一配置文件进行解析。因此,除非您通过条件语句对流进行控制,否则来自所有输入插件的数据都将由所有过滤插件进行处理,并发送给输出插件。
使用多个管道
若要在 Logstash 内使用多个管道,您将需要编辑 Logstash 随附的 pipelines.yml 文件。此文件在设置目录中,包括适用于 Logstash 实例所支持全部管道的配置文件和配置参数。
通过使用多管道,您能够区分不同的逻辑流,这将能够大大降低复杂程度和用到的条件语句数量。这样做的话,您能够更轻松地调整和维护配置。由于同时流经管道的数据会越来越具有同质性,并且输出插件的使用效率也可更高,所以这也可实现更大的性能优势。
创建第一个配置
任何 Logstash 配置都必须至少包括一个输入插件和一个输出插件。过滤插件是可选项。我们希望通过第一个示例让大家看一下简单配置文件的样子,这个示例是这样的,其会从文件读取测试数据集,然后将其以结构化形式输出至控制台。这是创建配置时一个特别实用的配置文件,因为其能允许您快速迭代并构建配置。在本篇博文中,我们假设配置文件名为 test.conf,并且其和包含测试数据的文件一同存储在 “/home/logstash” 目录中。
input {
file {
path => ["/home/logstash/testdata.log"]
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
}
我们在这里可以看到每个 Logstash 配置都拥有三个顶级分组:input、filter 和 output。我们在输入部分指定了文件输入插件,并且通过 path 指令提供了测试数据的路径。我们将 start_position 指令设置为 “beginning”,这样便能指示插件无论何时发现新文件都从头开始读取文件。
为了跟踪每个输入文件中已处理了哪些数据,Logstash 文件输入插件会使用名为 sincedb 的文件来记录现有位置。由于我们的配置用于开发,所以我们希望能够重复读取文件,并进而希望禁用 sincedb 文件。在 Linux 系统上,将 sincedb_path 指令设置为 “/dev/null” 即可禁用。在 Windows 系统上,则需要设置为 “nul”。
尽管 Logstash 文件输入插件是开始学习配置文件的一种很好的方法,但我们仍推荐使用 Filebeat 来收集日志并将其输送到托管服务器。Filebeat 能够将日志输出至 Logstash,接下来 Logstash 会通过 Beats 输入插件来接收和处理这些日志。虽然我们在本篇博文中所列出的解析逻辑同时适用于这两种情况,但 Filebeat 针对性能进行了更多优化,所用的资源也要少一些,所以是作为代理运行时的理想之选。
stdout 输出插件会向控制台写入数据,而 rubydebug codec 则会帮助显示结构,这能够在配置开发过程中简化故障排查。
启用 Logstash
为了验证 Logstash 和我们的配置文件能否正常运行,我们在 “/home/logstash” 目录中创建了一个名为 “testdata.log” 的文件。其中包括字符串 “Hello Logstash!”,随后是一个新行。
假设我们的路径中有 Logstash 双字节文件,我们可以通过下列命令来启动 Logstash。
logstash -r -f "/home/logstash/test.conf"
除了之前讨论的 -f 命令外,我们还可使用了 -r 旗标。这可以告诉 Logstash,只要确定配置文件已经发生变更,便要自动重新加载配置文件。这一功能用处特别大,在开发时尤其如此。由于我们已经禁用了 sincedb 文件,每次重新加载配置文件时都会重新读取输入文件,这能够允许我们在继续开发的过程中快速测试配置。
Logstash 向控制台提供的输出显示,与其有关的某些日志正在启动。然后,此文件将会得到处理,您便会看到如下面这样的内容:
{
"message" => "Hello Logstash!",
"@version" => "1",
"path" => "/home/logstash/testdata.log",
"@timestamp" => 2018-04-24T12:40:09.105Z,
"host" => "localhost"
}
这便是 Logstash 已经处理的事件。您可看到数据存储在消息字段中,而且 Logstash 已针对该事件添加了某些元数据,采用的是时间戳(表明处理时间和启动位置)的形式。
这一切都很好,表明这一机制运行良好。我们现在要添加一些更加具有实际意义的测试数据,并展示对其进行解析的方式。
我如何解析自己的日志?
有时候,您可以使用堪称完美的过滤插件来解析自己的数据,例如 json 过滤插件,前提是您的日志为 JSON 格式。然而,大部分时候我们并不需要通过不同文本格式类型来解析日志。我们在本篇博文中使用的示例是几行 Squid 缓存访问日志,具体如下:
1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 - 1524206424.145 106 207.96.0.0 TCP_HIT/200 68247 GET http://elastic.co/guide/en/logstash/current/images/logstash.gif - NONE/- image/gif
每一行都包括发送给 Squid 缓存的某个请求的相关信息,并且可以拆分为很多不同字段,我们便要对这些字段进行解析。

解析文本日志时,有两个过滤器特别常用:Dissect 会根据分界符来解析日志,而 Grok 则会根据常规的表达式匹配来运行。
如果数据结构定义非常完善,Dissect 过滤插件的运行效果非常好,而且运行速度非常快捷高效。同时,其也更加容易上手,对于不熟悉常规表达式的用户而言,更是如此。
通常而言,Grok 的功能更加强大,而且可以处理各种各样的数据。然而,常规表达式匹配会耗费更多资源,而且速度也会慢一些,如果未能正确进行优化的话,尤为如此。
在我们开始解析之前,我们要用这两个日志行来替换 testdata.log 文件中的内容,并确保每行后边都紧跟一个新行。
使用 Dissect 解析日志
使用 Dissect 过滤插件时,您需要指明提取字段的顺序,还要指明这些字段之间的分界符。过滤插件会对数据进行单次传输,并匹配模式中的分界符。同时,过滤插件还会将分界符之间的数据分配至指定字段。过滤插件不会对所提取数据的格式进行验证。
使用 Dissect 过滤插件解析此数据时会用到分隔符,其在下方以粉色高亮显示。

第一个字段包含时间戳,随后是一个或多个空格,具体取决于随后时长字段的长度。我们可以将时间戳字段指定为 %{timestamp},但是为了让其能够接受以可变空格数量作为分隔符,我们需要为字段加上 -> 后缀。此日志条目中的所有其他分隔符均只包括单一字符。所以,我们可以开始创建模式,结果就是下面的过滤部分:
{
"@version" => "1",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:42:23.003Z,
"path" => "/home/logstash/testdata.log",
"host" => "localhost",
"duration" => "19395",
"timestamp" => "1524206424.034",
"rest" => "TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"client_ip" => "207.96.0.0"
}
我们现在可以开始逐步构建匹配模式。我们成功解析完全部字段后,即可清除消息字段,这样的话,我们便不必将同一数据存储两次。通过 remove_field 指令即可实现这一点,此指令只有在解析成功后才会运行,结果就是下面的过滤块:
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
}
}
针对样本数据运行后,第一条记录如下所示:
{
"user" => "-",
"content_type" => "-",
"host" => "localhost",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:43:07.406Z,
"duration" => "19395",
"request_method" => "GET",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"timestamp" => "1524206424.034",
"status_code" => "304",
"server" => "10.0.5.120",
"@version" => "1",
"client_address" => "207.96.0.0",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT"
}
此文档包含了很多优秀示例,本篇博文会围绕过滤插件的设计和目的开展系列讨论。
很简单,是不是?我们之后会进一步对其进行处理,但是,我们首先要看一下如何使用 Grok 来完成同样的事情。
怎样使用 Grok 实现最佳效果呢?
Grok 使用常规表达式模式来匹配字段和分界符。下图中,以蓝色显示的是采集的字段,以红色显示的则是分界符。

Grok 会从头开始匹配配置模式并一直继续,直至已将整个消息事件映射完毕或者其已确定无法找到匹配项。根据所使用模式类型的不同,这可能需要 Grok 对某些数据部分处理多次。
Grok 提供广泛的即用型模式。在此处可找到比较常用的一些,但是这一存储库中还包括大量适用于常见数据类型的非常专业的模式。尽管确实有一个模式可用来解析 Squid 访问日志,但是我们在这里并不会直接使用此模式,相反,我们将会向大家演示如何从头进行构建。在这里,大家可以看到,在开始创建自定义模式之前,在这个存储库中找一下是否存在任何合适的模式,可能也是一个不错的选择。
创建 Grok 配置文件时,有大量的常用标准模式:
- WORD - 匹配单个词汇的模式
- NUMBER - 匹配整数或浮点数(正值或负值均可)的模式
- POSINT - 匹配正整数的模式
- IP - 匹配 IPv4 或 IPv6 IP 地址的模式
- NOTSPACE - 匹配非空格的任何内容的格式
- SPACE - 匹配任何数量的连续空格的模式
- DATA - 匹配任何数据类型的限定数量的模式
- GREEDYDATA - 匹配剩余所有数据的格式
在我们创建自己的 Grok 配置时,便要用到这些模式。通常而言,创建 Grok 配置的方法是从左侧开始,然后逐渐完成模式构建,会使用 GREEDYDATA 模式来采集剩余数据。我们在开始时可以使用下面的模式和过滤块:
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{GREEDYDATA:rest}"
}
}
}
此模式会指示 Grok 在字符串开始处寻找数字,并将其存储在名为 timestamp 的字段内。然后,其会匹配大量空格,再然后会将其余数据存储在名为 rest 的字段内。如果我们转到这个字符串的 Dissect 过滤块,出现的第一条记录如下:
{
"timestamp" => "1524206424.034",
"rest" => "19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"path" => "/home/logstash/testdata.log",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:45:11.026Z,
"@version" => "1",
"host" => "localhost"
}
使用 Grok Debugger
尽管我们可以通过这种方法来开发整个模式,但是在 Kibana 中有一款工具能够帮助简化 Grok 模式的创建过程,即 Grok Debugger。在下面的视频中,我们将会展示如何使用这一工具为本篇博文中所用到的示例日志创建模式。
配置构建完毕之后,我们可以在成功完成解析过程后立即丢弃消息字段,这样的话,过滤块将会如下所示:
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{NUMBER:duration}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code}\s%{NUMBER:bytes}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
这与预置模式十分相似,但是并不完全相同。如果针对样本数据运行的话,第一条记录的解析方式与我们使用 Dissect 过滤插件进行解析的方式完全相同。
{
"request_method" => "GET",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:48:15.123Z,
"timestamp" => "1524206424.034",
"user" => "-",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT",
"duration" => "19395",
"client_address" => "207.96.0.0",
"@version" => "1",
"status_code" => "304",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"content_type" => "-",
"host" => "localhost",
"server" => "10.0.5.120"
}
对 Grok 进行调整以优化性能
Grok 是一款十分强大且灵活的数据解析工具,但是如果模式的使用效率低下的话,可能会导致性能低于预期。因为我们推荐您在满怀热情地开始使用 Grok 之前,先阅读这篇有关如何调整 Grok 以提高性能的博文。
确保字段类型正确
如您在上述示例中所看到的那样,所有字段均已解析为字符串字段。在我们将这些信息以 JSON 文档的形式发送到 Elasticsearch 之前,我们想将 bytes、duration 和 status_code 字段更改为整数,想将 timestamp 字段更改为浮点。
想完成这一点,有一种方法就是使用 mutate 过滤插件及其提供的 convert 选项。
mutate {
convert => {
"bytes" => "integer"
"duration" => "integer"
"status_code" => "integer"
"timestamp" => "float"
}
}
我们也可以在 Dissect 和 Grok 过滤插件中直接实现这一点。在 Dissect 过滤插件中,我们会通过 convert_datatype 指令来完成。
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
convert_datatype => {
"bytes" => "int"
"duration" => "int"
"status_code" => "int"
"timestamp" => "float"
}
}
}
如果使用 Grok,您可以在模式内字段名称的后面直接指定类型。
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp:float}%{SPACE}%{NUMBER:duration:int}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code:int}\s%{NUMBER:bytes:int}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
使用日期过滤插件
从这篇日志中提取出来的时间戳是自 epoch(纪元)以来经过的秒数和微秒数。我们希望将此数据转换为可以存储在 @timestamp 字段的标准时间戳格式。这次,我们要将日期过滤插件和与我们拥有的数据相匹配的 UNIX 模式一起使用。
date {
match => [ "timestamp", "UNIX" ]
}
存储在 Elasticsearch 中的所有标准时间戳均为 UTC 时区。由于这一点同样适用于我们所提取的时间戳,所以我们没有必要指明任何时区。如果您的时间戳为其他格式,您可以不用预先定义的 UNIX 模式,自行指定这种格式。
将这些内容和类型转换添加到我们的配置中后,第一个事件会如下所示:
{
"duration" => 19395,
"host" => "localhost",
"@timestamp" => 2018-04-20T06:40:24.034Z,
"bytes" => 15363,
"user" => "-",
"path" => "/home/logstash/testdata.log",
"content_type" => "-",
"@version" => "1",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"server" => "10.0.5.120",
"client_address" => "207.96.0.0",
"timestamp" => 1524206424.034,
"status_code" => 304,
"cache_result" => "TCP_MISS",
"request_method" => "GET",
"hierarchy_code" => "DIRECT"
}
现在我们已经拥有了想要的格式,可以开始准备将这些数据发送到 Elasticsearch 了。
如何将数据发送到 Elasticsearch?
在使用 Elasticsearch 输出插件向 Elasticsearch 发送之前,我们需要了解一下映射的角色,以及这与您在 Logstash 内可以转化成的类型有何不同。
Elasticsearch 能够自动检测字符串和数字字段,所选的映射将会基于其遇到的拥有新字段的第一个文档。根据数据的具体情况,这可能会给出正确的匹配,也有可能不会给出正确的匹配;举个例子,如果我们的某个字段通常都是浮点式,但是在某些数据中可能为 “0”,则有可能会将此字段匹配为整数,而非浮点,具体取决于先处理哪个文件。
Elasticsearch 同时还能够自动检测日期字段,前提是这些字段是日期过滤插件生成的标准格式。
其他字段类型,例如 geo_point 和 ip,则不能自动检测出来,必须通过 索引模板明确地进行定义。索引模板可通过 API 在 Elasticsearch 内直接进行管理,但是还有可能会借助 Logstash 来确保已通过 Elasticsearch 输出插件加载正确的模板。
对我们的数据而言,默认映射通常就能满足要求。server 可能会包括小横杠或有效的 IP 地址,因此我们不会将其映射为 IP 字段。有一个字段需要手动映射,即 client_address 字段,因为我们希望其类型为 ip。我们可能还想让某些字符串字段可以进行聚合,但是不需要针对这些字段进行自由文本搜索。我们会明确地将这些字段映射为关键字字段。这些字段分别是 user、path、content_type、cache_result、request_method、server 和 hierarchy_code。
我们希望将数据存储为以 squid- 为前缀的时序性索引。在这个示例中,我们假设 Elasticsearch 在与 Logstash 相同的主机上采用默认配置运行。
然后我们可以创建下面的模板,其存储在名为 squid_mapping.json 的文件中:
{
"index_patterns": ["squid-*"],
"mappings": {
"doc": {
"properties": {
"client_address": { "type": "ip" },
"user": { "type": "keyword" },
"path": { "type": "keyword" },
"content_type": { "type": "keyword" },
"cache_result": { "type": "keyword" },
"request_method": { "type": "keyword" },
"server": { "type": "keyword" },
"hierarchy_code": { "type": "keyword" }
}
}
}
}
这一模板的配置适用于与索引类型 squid-* 匹配的所有索引。对文件类型 doc(Elasticsearch 6.x 中的默认类型)而言,其指定将 client_address 字段映射为 ip,将其他指定字段映射为 keyword。
我们可以将其直接上传至 Elasticsearch,但是我们在这里要给大家展示如何通过配置 Elasticsearch 输出插件来处理这种情况。在 Logstash 配置的输出部分,我们将添加譬如下面所示的代码块:
elasticsearch {
hosts => ["localhost:9200"]
index => "squid-%{+YYYY.MM.dd}"
manage_template => true
template => "/home/logstash/squid_mapping.json"
template_name => "squid_template"
}
如果我们运行此配置并将样本文件索引到 Elasticsearch 中,则在我们通过获取映射 API 提取索引映射时,会得到下面内容:
{
"squid-2018.04.20" : {
"mappings" : {
"doc" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"bytes" : {
"type" : "long"
},
"cache_result" : {
"type" : "keyword"
},
"client_address" : {
"type" : "ip"
},
"content_type" : {
"type" : "keyword"
},
"duration" : {
"type" : "long"
},
"hierarchy_code" : {
"type" : "keyword"
},
"host" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"path" : {
"type" : "keyword"
},
"request_method" : {
"type" : "keyword"
},
"server" : {
"type" : "keyword"
},
"status_code" : {
"type" : "long"
},
"timestamp" : {
"type" : "float"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"user" : {
"type" : "keyword"
}
}
}
}
}
}
大家可以看到,我们的模板已经应用,并且我们指定的字段已正确映射。由于本篇博文的主要关注点是 Logstash,所以我们在这里只是涉及了映射的简单运行原理。您可以参阅此文档了解有关这一重要主题的详细信息。
结论
在本篇博文中,我们向大家展示了在开发样本时,如何最充分地利用 Logstash,还讲到了定制配置,以及如何确保将其成功写入 Elasticsearch。然而,我们在这里只是涉及了 Logstash 能够实现的浅显的内容。请阅读我们在本篇博文中所引用的全部链接中的文档和博文,但是也要参考正式入门指南,而且还要参考一下提供的所有输入、输出和过滤插件。等到您透彻理解这些内容时,Logstash 很快就会变成您处理数据时的一把无敌利器。
如果遇到问题或者有其他问题,您可以随时在讨论论坛的 Logstash 类别下与我们联系。如果您希望查阅其他样本数据以及 Logstash 配置,可以前往 https://github.com/elastic/examples/ 参考更多示例。
祝您解析愉快!!!