我应该使用 Logstash 还是 Elasticsearch 采集节点呢?
Logstash 是 Elastic Stack 的最初组件之一,而且很长时间以来,人们在需要解析、充实或处理数据时均会用到这一工具。在多年的发展过程中,我们向其中添加了大量的输入、输出和筛选插件,使得其成为一款适用于各种不同架构且极其灵活和强大的工具。
我们在 Elasticsearch 5.0 中推出了采集节点,这样的话,用户在索引之前便可通过采集节点在 Elasticsearch 中对文档进行处理。通过这一方式,用户可以拥有简单的架构,并将架构中组件的数量降至最低;在此架构中,应用程序会将数据直接发送到 Elasticsearch 进行处理和索引。这种方法能够让人们更加轻松地开始使用 Elastic Stack,但是也能随着数据量的增长而横向扩展。
然而,采集节点的确会复制 Logstash 中的部分功能,因此用户面临的一个常见问题是到底应该选择哪一个呢。在这篇博客文章中,我们会讨论您在两者之间进行选择时需要考虑的架构方面的问题,以帮助您做出更加明智的决策。
这是我们针对用户常见问题的系列文章中的第三篇。前两篇分别是:
如何输入和输出数据?
Logstash 和采集节点之间的一点重大区别是数据的输入和输出方式。
由于采集节点在 Elasticsearch 内的索引工作流中运行,所以必须通过批量或索引请求将数据推送到 Elasticsearch。这就必须要有一个流程来将数据主动写到 Elasticsearch 中。采集节点不能从外部来源(例如消息队列或数据库)提取数据。
数据处理完成之后,也存在类似的限制,所以唯一选择就是在本地将数据索引到 Elasticsearch 中。
相比而言,Logstash 则有大量的输入和输出插件可供使用,还可用来支持一系列不同的架构。其还可以作为服务器接受客户端通过 TCP、UDP 和 HTTP 推送的数据,也可主动从数据库和消息队列等外部来源提取数据。关于输出,Logstash 也提供广泛的选择,例如 Kafka 和 RabbitMQ 等消息队列,或者 S3 或 HDFS 上的长期数据归档。
队列和背压呢?
向 Elasticsearch 发送数据时,无论是直接发送,还是通过采集管道,如果 Elasticsearch 速度落后或不能接受更多数据,每个客户端都需要能够应对此种情况。这就是我们所说的“背压“的意思。如果数据节点不能接受数据,采集节点也会停止接受数据。
如果未在架构内的处理管道中构建队列机制(无论是在来源处,还是在传送途中),那么在长时间无法联系上 Elasticsearch 或者 Elasticsearch 无法接受数据的情况下,此架构均有可能会丢失数据。可发生数据丢失的环节包括无法存储数据或无法从文件中读取数据的 Beats,还包括能够直接向 Elasticsearch 中写入内容的其他进程,例如 syslog-ng。
通过持久队列功能,Logstash 能够对磁盘数据进行队列化操作,允许 Logstash 提供至少一次送达保证,并且也允许 Logstash 在本地对数据进行缓冲以应对采集骤升情况。Logstash 同时还支持与大量不同的消息队列类型进行集成,允许支持各种部署模式。
如何充实和处理数据?
采集节点拥有 20 多个不同的处理器,涵盖了最常用 Logstash 插件的功能。但是有一项限制,即采集节点管道只能在单一事件的上下文中运行。还有一点,处理器通常不能调用其他系统或者从磁盘中读取数据,这在一定程度上限制了可以完成的充实类型。
Logstash 中可供选择的插件则要多得多。这其中就包括根据配置文件、Elasticsearch 或关系型数据库中的查询结果添加或转换内容的插件。
Beats 和 Logstash 同时还支持基于可配置条件筛除和弃用事件,目前采集节点还不能实现这一点。
哪一种方法配置更简单呢?
这是一个仁者见仁、智者见智的问题,取决于您的背景知识和使用习惯。每个采集节点管道都在 JSON 文档(存储于 Elasticsearch 内)中进行了定义。尽管可以定义大量的不同管道,但是在通过采集节点时每个文档只能由单一管道进行处理。与 Logstash 配置文件的格式相比,采集节点管道的格式可能更加易于操作,至少对较为简单且定义清晰的管道而言是如此。对于需要处理多种数据格式的更加复杂的管道,由于 Logstash 可以通过条件语句控制工作流,所以其更加易于使用。Logstash 也支持定义多个在逻辑上独立的管道,并且这些管道可以通过基于 Kibana 的用户界面进行管理。
还有一点需要您注意,在 Logstash 中通常可更轻松地衡量和优化管道性能,这是因为其支持监测,并且还有出色的管道查看器 UI,通过此 UI 用户能够快速找到瓶颈和潜在问题。
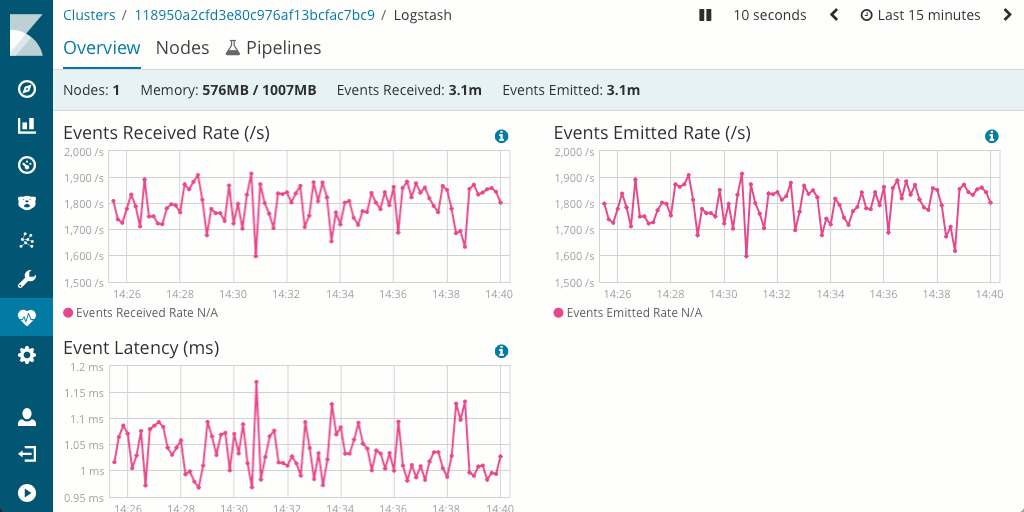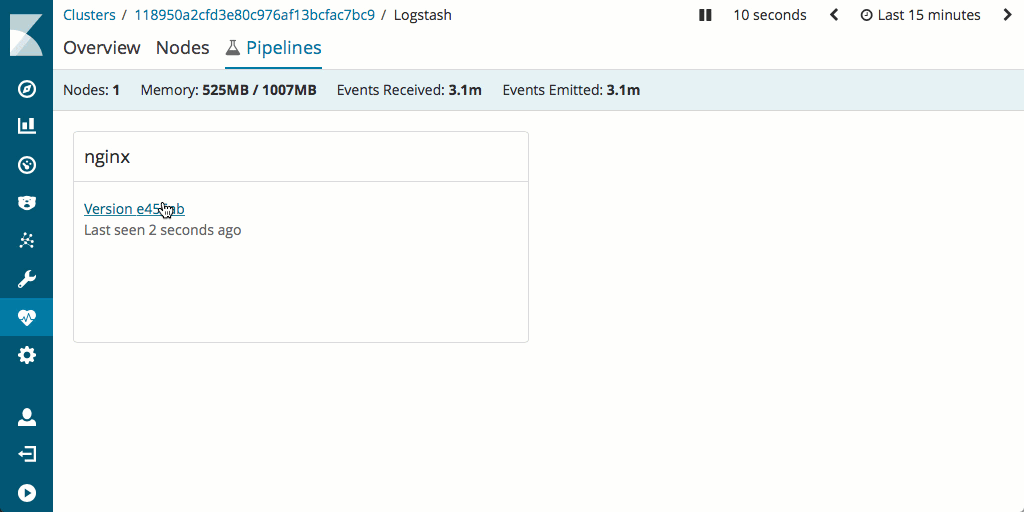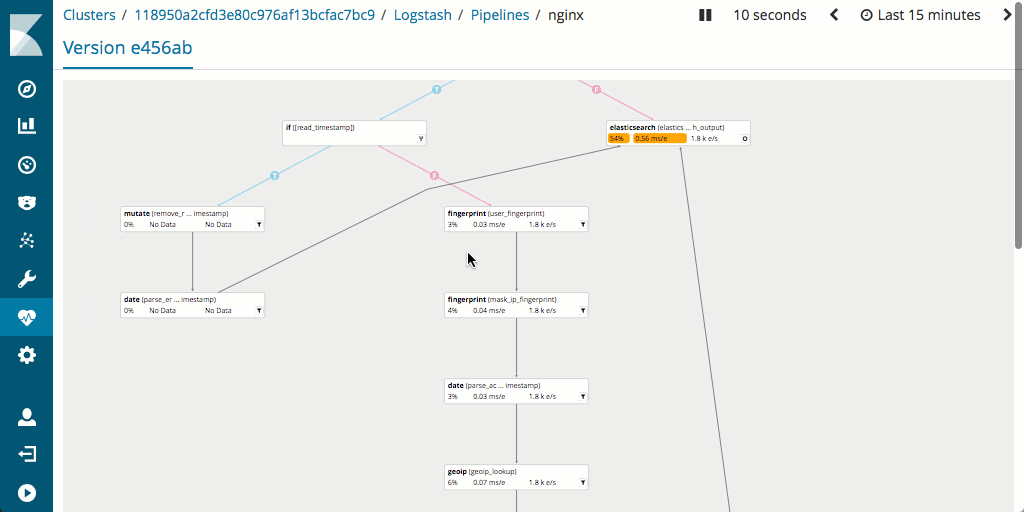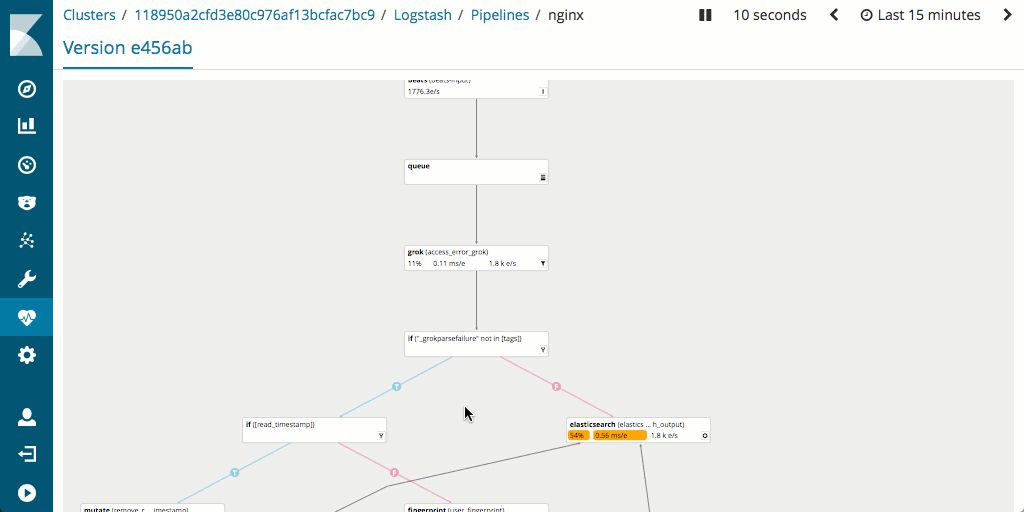
对硬件所占空间有何影响?
采集节点的一大好处就是其允许使用非常简单的架构,Beats 在此架构中可以直接向采集节点管道中写入内容。Elasticsearch 集群上的每个节点都可以作为一个采集节点,这能够减少硬件所占空间,并降低架构的复杂程度,至少对较小规模的用例而言是这样。
数据量增长上来后,或者处理过程更加复杂时,就会导致集群中的 CPU 负载提高,我们这时通常建议转而使用专用型采集节点。这时就需要额外的硬件来对专用型采集节点或 Logstash 进行托管,硬件所占空间各不相同,在很大程度上取决于用例。
有没有某些事务仅可通过采集节点完成 ,而 Logstash 却无法完成?
目前看来,采集节点貌似仅能提供 Logstash 所支持功能的一部分而已;然而,这一说法却不尽准确。
采集节点支持采集附件处理器插件,此插件可用来处理和索引常见格式(例如 PPT、XLS 和 PDF)的附件。目前在 Logstash 中还没有可提供对等功能的插件,所以如果您正计划对各种附件类型进行索引,可能必须使用采集节点。
由于在即将对数据进行索引之前才会执行采集管道,所以采集管道是对数据进行索引时添加时间戳的最可靠方法,以便达成准确衡量和分析采集延时之类的目的。在数据成功到达 Elastisearch 之前就进行设置的话,可能会造成混淆,因为在添加时间戳和将数据索引至 Elasticsearch 之间可能会有延时,举两个例子,如果正在应用背压,或者需要客户端对数据多次尝试进行强制索引时,便会发生这种情况。这种类型的时间戳可用来测量每份文档的采集延时。
我可以同时使用 Logstash 和采集节点吗?
尽管人们通常倾向于二选一,但毫无疑问用户能够将二者结合起来使用,因为 Logstash 支持向采集管道发送数据。对于更加复杂的结构而言,可能还会有多个逻辑工作流,而且每个工作流会有截然不同的要求。部分内容会通过 Logstash 来完成,而其他部分则会直接发送到 Elasticsearch 采集节点。使用对于每个数据流最为合理的方式,这通常能够允许用户更加轻松地维护架构。
结论
Logstash 和 Elasticsearch 采集节点的功能之间有重合部分。这意味着某些架构使用两种技术进行实施均可。然而,这两个选项各有优缺点,所以您必须分析自己整个处理管道的要求和架构,并基于本篇博客文章所讨论的条件选择最为合适的技术,这一点十分重要。并非必须要二选一,您也可以同时使用二者,也可对处理管道中的不同部分并行使用二者。