RAG com contexto em que você pode confiar
Para conquistar a confiança do usuário, as aplicações de IA precisam fornecer resultados precisos em grande escala. Para isso, utilize grandes modelos de linguagem (LLMs) com a precisão da recuperação híbrida do Elasticsearch e dimensione a Retrieval-Augmented Generation (RAG) com baixa latência e alta eficiência.
RAG projetado para precisão incomparável e redimensionamento eficiente de vetores
Forneça o contexto certo com desempenho vetorial, eficiência de custos e segurança que a produção exige.
Dê às suas aplicações RAG o contexto certo com pesquisa híbrida, reclassificação semântica e inferência integrada, usando modelos de ponta — de terceiros ou nativos — da Jina AI. Substitua a recuperação ingênua baseada apenas em vetores por uma única consulta que combina palavras-chave, vetores e filtros.

Redimensione o contexto em bilhões de documentos — abrangendo dados estruturados, não estruturados e vetoriais — sem precisar abrir mão da qualidade de recuperação ou do custos. A quantização e os algoritmos otimizados para disco, como o DiskBBQ, reduzem o consumo de memória em até 95%, mantendo alta qualidade de classificação com baixa latência.

Simplifique seu pipeline com uma plataforma unificada que extrai contexto de documentos e registros não estruturados e estruturados em uma única consulta. Aplique controles de acesso em nível de documento e RBAC para que os LLMs exponham apenas os dados que o usuário deve ver.
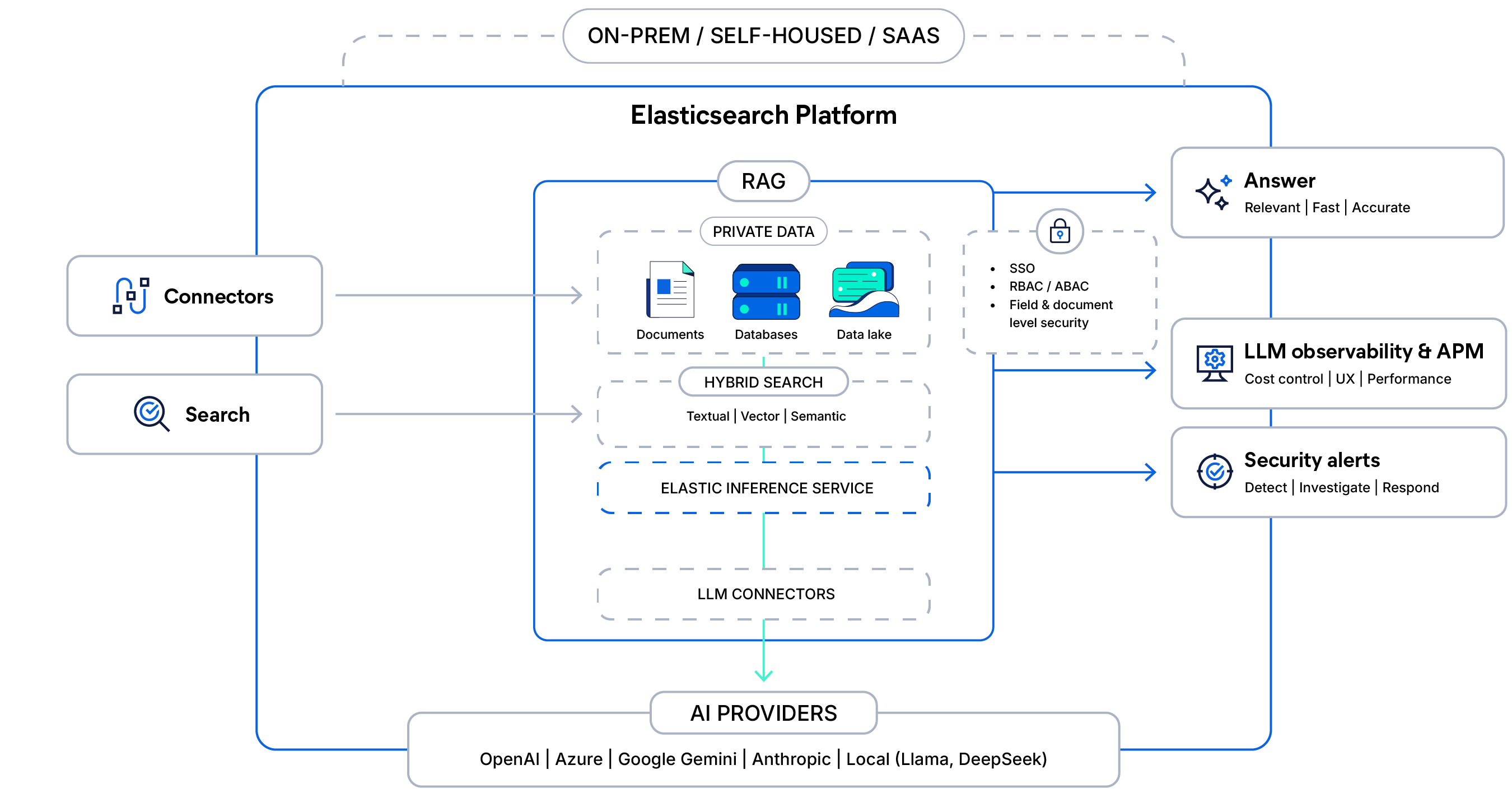
A arquitetura por trás da RAG com reconhecimento de contexto
Conecte seus dados privados com busca híbrida segura e inferência gerenciada, fundamente as respostas LLM com controles de acesso e forneça respostas rápidas, observáveis e prontas para produção em escala.
O que você está construindo?
Construa um chat baseado nos seus dados e em agentes guiados pelo contexto. Explore nosso catálogo completo de treinamentos ou acompanhe nossos tutoriais no Elasticsearch Labs.

Perguntas e respostas sobre seus dados. Construa um sistema RAG com Gemma, Hugging Face e Elasticsearch.

Construa apps RAG agentivos mais rapidamente usando LangGraph e Elasticsearch.

A Elastic criou um Assistente de Suporte com GenAI — explore a arquitetura, técnicas e práticas recomendadas para criar o seu próprio.
Perguntas frequentes
O que é RAG em IA?
O que é RAG em IA?
A Retrieval-Augmented Generation (comumente chamada de RAG) é um padrão de processamento de linguagem natural que permite que as empresas pesquisem fontes de dados proprietárias e forneçam contexto que fundamenta grandes modelos de linguagem.Isso possibilita respostas mais precisas e em tempo real em aplicações de IA generativa (GenAI).
Quais são os benefícios do RAG?
Quais são os benefícios do RAG?
Quando implementada de forma otimizada, a RAG fornece acesso seguro a dados proprietários relevantes e específicos do domínio em tempo real. Ela pode reduzir a incidência de alucinações em aplicações de IA generativa e aumentar a precisão das respostas.
Quais são os benefícios de usar a Elastic para fluxos de trabalho RAG?
Quais são os benefícios de usar a Elastic para fluxos de trabalho RAG?
A Elastic deixa a RAG pronta para produção ao resolver, de forma nativa, os desafios mais complexos: ingestão e fundamentação de dados de alta qualidade, entrega de recuperação precisa e eficiente em escala, aplicação de segurança em nível de função e de documento, e preservação da atribuição de fontes para respostas confiáveis. Com recuperação vetorial, lexical e híbrida nativas; modelos próprios como o ELSER e integrações flexíveis com modelos de terceiros em todo o ecossistema de GenAI; além de desempenho comprovado em escala empresarial, a Elastic ajuda equipes a criar sistemas de RAG mais rápidos de lançar, mais fáceis de ajustar e confiáveis em produção.
Como o Elasticsearch possibilita a engenharia de contexto?
Como o Elasticsearch possibilita a engenharia de contexto?
O Elasticsearch foi projetado para relevância em escala, que é a base da engenharia de contexto. Ele reúne busca vetorial, palavra-chave e estruturada com análises, inferência e observabilidade em uma única plataforma. Isso facilita para os desenvolvedores armazenar, recuperar e classificar dados empresariais estruturados e não estruturados com precisão, para que os agentes sempre obtenham o contexto correto.
Com o Agent Builder, o Elasticsearch leva isso além, trazendo chat, recuperação, criação de ferramentas e orquestração diretamente para a plataforma. Desenvolvedores podem construir, testar e escalar agentes orientados por contexto em minutos usando seus próprios dados, modelos e ferramentas, todos suportados pela relevância, segurança e desempenho do Elasticsearch.