BM25 na prática — parte 2: o algoritmo BM25 e suas variáveis
Este é o segundo post da série BM25 na prática de três partes sobre classificação de similaridade (relevância). Se você está chegando agora, confira a Parte 1: como os shards afetam a pontuação de relevância no Elasticsearch.
O algoritmo BM25
Tentarei me embrenhar na matemática apenas até onde for estritamente necessário para explicar o que está acontecendo, mas esta é a parte em que examinamos a estrutura da fórmula do BM25 para obter alguns insights. Primeiro veremos a fórmula, depois dividirei cada componente em partes compreensíveis:
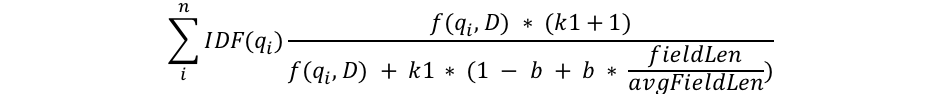
Podemos ver alguns componentes comuns como qi, IDF(qi), f(qi,D), k1, b e algo sobre o tamanho dos campos. Vejamos sobre o que é cada um deles:
- qi é o io termo de consulta.
Por exemplo, se eu faço uma busca por “shane”, há apenas um termo de consulta, então q0 é “shane”. Se eu fizer uma busca por “shane connelly” em inglês, o Elasticsearch verá o espaço em branco e o tokenizará como dois termos: q0 será “shane” e q1 será “connelly”. Esses termos de consulta são inseridos nas outras partes da equação, e tudo isso é resumido. - IDF(gi) é a frequência de documento inversa do io termo de consulta.
Para quem já trabalhou com TF/IDF antes, o conceito de IDF pode ser familiar. Se não, não se preocupe! (E se for, observe que há uma diferença entre a fórmula do IDF no TF/IDF e do IDF no BM25.) O componente IDF da nossa fórmula mede a frequência com que um termo ocorre em todos os documentos e “penaliza” os termos que são comuns. A fórmula real que o Lucene/BM25 usa para esta parte é: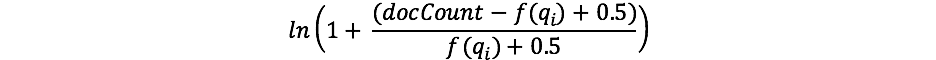
Onde docCount é o número total de documentos que têm um valor para o campo no shard (nos shards, se você estiver usandosearch_type=dfs_query_then_fetch) e f(qi) é o número de documentos que contêm o io termo de consulta. Podemos ver no nosso exemplo que “shane” ocorre em todos os quatro documentos, portanto, para o termo “shane”, terminamos com um IDF(“shane”) de: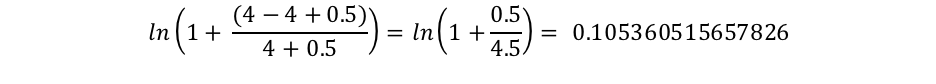
No entanto, podemos ver que “connelly” aparece apenas em dois documentos, então obtemos um IDF(“connelly”) de: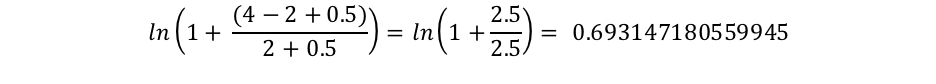
Podemos ver aqui que as consultas que contêm esses termos mais raros (“connelly” sendo mais raro que “shane” em nosso corpus de quatro documentos) têm um multiplicador maior, portanto, contribuem mais para a pontuação final. Isso faz sentido intuitivamente: o termo “the” provavelmente ocorre em quase todos os documentos em inglês, então quando um usuário procura algo como “the elephant”, “elephant” é provavelmente mais importante — e queremos que contribua mais para a pontuação — do que o termo “the” (que estará em quase todos os documentos).
- Vemos que o tamanho do campo é dividido pela média de tamanho dos campos no denominador como fieldLen/avgFieldLen.
Podemos pensar nisso como o tamanho de um documento em relação à média de tamanho dos documentos. Se um documento é maior que a média, o denominador fica maior (diminuindo a pontuação) e, se é menor que a média, o denominador fica menor (aumentando a pontuação). Observe que a implementação do tamanho do campo no Elasticsearch é baseada no número de termos (em vez de algo como o comprimento do caractere). Isso é exatamente igual ao descrito no documento original do BM25, embora tenhamos um flag especial (discount_overlaps) para lidar com sinônimos de forma especial se você desejar. A maneira de pensar sobre isso é a seguinte: quanto mais termos no documento (pelo menos aqueles que não correspondem à consulta), menor a pontuação do documento. Novamente, isso faz sentido intuitivamente: se um documento tem 300 páginas e menciona meu nome uma vez, é menos provável que tenha tanto a ver comigo quanto um tweet curto que me menciona uma vez. - Vemos uma variável b que aparece no denominador e que é multiplicada pela proporção do tamanho do campo que acabamos de discutir. Se b é maior, os efeitos do tamanho do documento em comparação com o tamanho médio são mais amplificados. Para ver isso, você pode imaginar que, se definisse b como 0, o efeito da proporção do tamanho seria completamente anulado e o tamanho do documento não teria influência na pontuação. Por padrão, b tem um valor de 0,75 no Elasticsearch.
- Por fim, vemos dois componentes da pontuação que aparecem tanto no numerador quanto no denominador: k1 e f(qi,D). Como aparecem em ambos os lados, fica difícil ver o que eles fazem apenas olhando para a fórmula, mas vamos examinar rapidamente.
- f(qi,D) é “quantas vezes o io termo de consulta ocorre no documento D?” Em todos esses documentos, f(“shane”,D) é 1, mas f(“connelly”,D) varia: é 1 para os documentos 3 e 4, mas 0 para os documentos 1 e 2. Se houvesse um 5 o documento que tivesse o texto “shane shane”, ele teria um f(“shane”,D) de 2. Nós podemos ver que f(qi,D) está no numerador e no denominador, e há aquele fator especial “k1” que abordaremos a seguir. A maneira de interpretar f(qi,D) é a seguinte: quanto mais vezes os termos de consulta ocorrerem em um documento, maior será sua pontuação. Isso faz sentido intuitivamente: um documento que contém nosso nome muitas vezes tem mais probabilidade de estar relacionado a nós do que um documento que o menciona apenas uma vez.
- k1 é uma variável que ajuda a determinar as características de saturação da frequência do termo. Ou seja, limita o quanto um único termo de consulta pode afetar a pontuação de um determinado documento. Ele faz isso se aproximando de uma assíntota. Você pode ver a comparação do BM25 com o TF/IDF aqui:
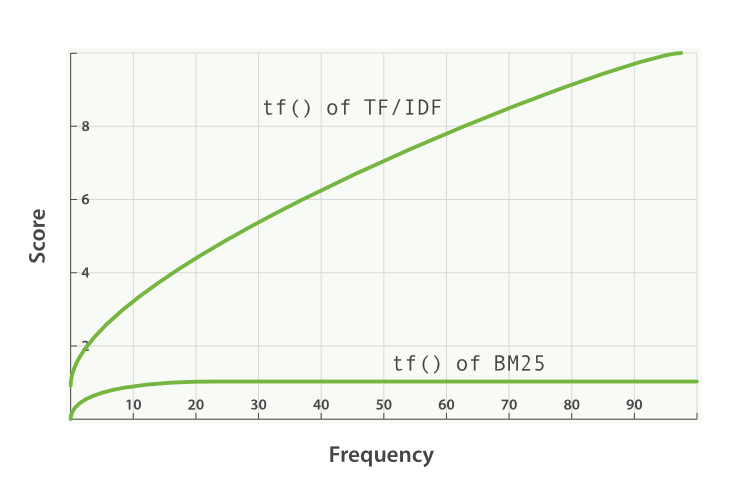
Um valor de k1 mais alto/mais baixo significa que a inclinação da curva “tf() de BM25” muda. Isso tem o efeito de mudar como “termos que ocorrem vezes extras adicionam pontuação extra”. Uma interpretação de k1 é que, para documentos de tamanho médio, é o valor da frequência do termo que dá uma pontuação de metade da pontuação máxima para o termo considerado. A curva do impacto de tf na pontuação cresce rapidamente quando tf() ≤ k1 e cada vez mais lenta quando tf() > k1.
Continuando com nosso exemplo, com k1 estamos controlando a resposta para a pergunta “quanto a mais a adição de um segundo 'shane' ao documento deveria contribuir para a pontuação do que o primeiro ou o terceiro em comparação com o segundo?” Um k1 mais alto significa que a pontuação para cada termo pode continuar subindo relativamente mais para mais instâncias desse termo. Um valor de 0 para k1 significaria que tudo exceto IDF(qi) seria cancelado. Por padrão, k1 tem um valor de 1,2 no Elasticsearch.
Revisitando nossa busca com nosso novo conhecimento
Excluiremos nosso índice people e o recriaremos com apenas um shard para que não precisemos usar search_type=dfs_query_then_fetch. Vamos testar nosso conhecimento configurando três índices: um com o valor de k1 como 0 e b como 0,5, um segundo índice (people2) com o valor de b como 0 e de k1 como 10 e um terceiro índice (people3) com um valor de b ccomo 1 e k1 como 5.
DELETE people
PUT people
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0.5,
"k1": 0
}
}
}
}
}
PUT people2
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0,
"k1": 10
}
}
}
}
}
PUT people3
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 1,
"k1": 5
}
}
}
}
}
Agora adicionaremos alguns documentos a todos os três índices:
POST people/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people2/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people3/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
Agora, quando executamos:
GET /pt/people/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
Podemos ver em people que todos os documentos têm uma pontuação de 0,074107975. Isso corresponde ao nosso entendimento de ter k1 definido como 0: apenas o IDF do termo de busca é importante para a pontuação!
Agora vamos verificar people2, que tem b = 0 e k1 = 10:
GET /pt/people2/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
Aprendemos duas coisas com os resultados dessa busca.
Primeiro, podemos ver que as pontuações são puramente ordenadas pelo número de vezes que “shane” aparece. Os documentos 1, 2, 3 e 4 têm “shane” uma vez e, portanto, compartilham a mesma pontuação de 0,074107975. O documento 5 tem “shane” duas vezes, então tem uma pontuação mais alta (0,13586462) graças a f(“shane”,D5) = 2 e o documento 6 tem uma pontuação mais alta novamente (0,18812023) graças a f(“shane”,D6) = 3. Isso se encaixa em nossa intuição de definir b como 0 em people2: o tamanho — ou o número total de termos no documento — não afeta a pontuação; apenas a contagem e a relevância dos termos correspondentes.
A segunda coisa a observar é que as diferenças entre essas pontuações não são lineares, embora pareçam ser bem próximas do linear com esses seis documentos.
- A diferença de pontuação entre ter nenhuma ocorrência do nosso termo de busca e a primeira é 0,074107975
- A diferença de pontuação entre adicionar uma segunda ocorrência do nosso termo de busca e a primeira é 0,13586462 - 0,074107975 = 0,061756645
- A diferença de pontuação entre adicionar uma terceira ocorrência do nosso termo de busca e a segunda é 0,18812023 - 0,13586462 = 0,05225561
0,074107975 é bem próximo de 0,061756645, que é bem próximo de 0,05225561, mas os números estão claramente diminuindo. A razão pela qual isso parece quase linear é porque k1 é grande. Podemos pelo menos ver que a pontuação não está aumentando linearmente com ocorrências adicionais — se estivesse, esperaríamos ver a mesma diferença a cada termo adicional. Voltaremos a essa ideia depois de conferir people3.
Agora vamos verificar people3, que tem k1 = 5 e b = 1:
GET /pt/people3/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
Recebemos os seguintes hits:
"hits": [
{
"_index": "people3",
"_type": "_doc",
"_id": "1",
"_score": 0.16674294,
"_source": {
"title": "Shane"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "6",
"_score": 0.10261105,
"_source": {
"title": "Shane Shane Shane Connelly Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "2",
"_score": 0.102611035,
"_source": {
"title": "Shane C"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "4",
"_score": 0.102611035,
"_source": {
"title": "Shane Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "5",
"_score": 0.102611035,
"_source": {
"title": "Shane Shane Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "3",
"_score": 0.074107975,
"_source": {
"title": "Shane P Connelly"
}
}
]
Podemos ver em people3 que agora a proporção de termos correspondentes (“shane”) para termos não correspondentes é a única coisa que afeta a pontuação relativa. Portanto, documentos como o documento 3, que tem apenas um termo correspondente de três pontuações menores que 2, 4, 5 e 6, que correspondem exatamente à metade dos termos, e aqueles todos que têm pontuação inferior ao documento 1, que corresponde exatamente ao documento.
Novamente, podemos observar que há uma “grande” diferença entre os documentos com pontuação mais alta e os documentos com pontuação mais baixa em people2 e people3. Isso se deve (novamente) a um valor grande para k1. Como um exercício adicional, tente excluir people2/people3 e configurá-los novamente com algo como k1 = 0,01 e você verá que as pontuações entre os documentos com menos é menor. Com b = 0 e k1 = 0,01:
- A diferença de pontuação entre ter nenhuma ocorrência do nosso termo de busca e a primeira é 0,074107975
- A diferença de pontuação entre adicionar uma segunda ocorrência do nosso termo de busca e a primeira é 0,074476674 - 0,074107975 = 0,000368699
- A diferença de pontuação entre adicionar uma terceira ocorrência do nosso termo de busca e a segunda é 0,07460038 - 0,074476674 = 0,000123706
Portanto, com k1 = 0,01, podemos ver que a influência da pontuação de cada ocorrência adicional cai muito mais rapidamente do que com k1 = 5 ou k1 = 10. A 4a ocorrência acrescentaria muito menos à pontuação do que a 3a e assim por diante. Em outras palavras, as pontuações de termo são saturadas muito mais rapidamente com esses valores k1 menores. Exatamente como esperávamos!
Espero que isso ajude a ver o que esses parâmetros estão fazendo em vários conjuntos de documentos. Com esse conhecimento, veremos a seguir como escolher um b e um k1 apropriados e como o Elasticsearch fornece ferramentas para entender as pontuações e iterar em sua abordagem.
Continue esta série com: Parte 3: considerações para escolher b e k1 no Elasticsearch