Previsão sob demanda com aprendizado de máquina no Elasticsearch
Nota do editor (3 de agosto de 2021): este post usa recursos obsoletos. Consulte a documentação de mapeamento de regiões customizadas com geocodificação reversa para obter as instruções atuais.
O mais novo recurso de aprendizado de máquina do X-Pack na versão 6.1 é a previsão sob demanda. Antes, o aprendizado de máquina do Elastic era projetado para usar dados históricos para prever o intervalo normal de valores para “agora” e comparar com os dados que realmente víamos para poder identificar anomalias em tempo real. Agora, o aprendizado de máquina na versão 6.1 pode modelar os dados e vários intervalos de tempo futuros.
Ele se chama “previsão sob demanda” porque os usuários podem obter um trabalho de aprendizado de máquina existente e, usando o modelo preditivo vinculado ao aprendizado de máquina, prever onde há expectativa de esse modelo crescer durante os dias previstos. Os resultados previstos são gravados em um índice do Elasticsearch que permite aos usuários comparar os resultados reais com os modelos previstos.
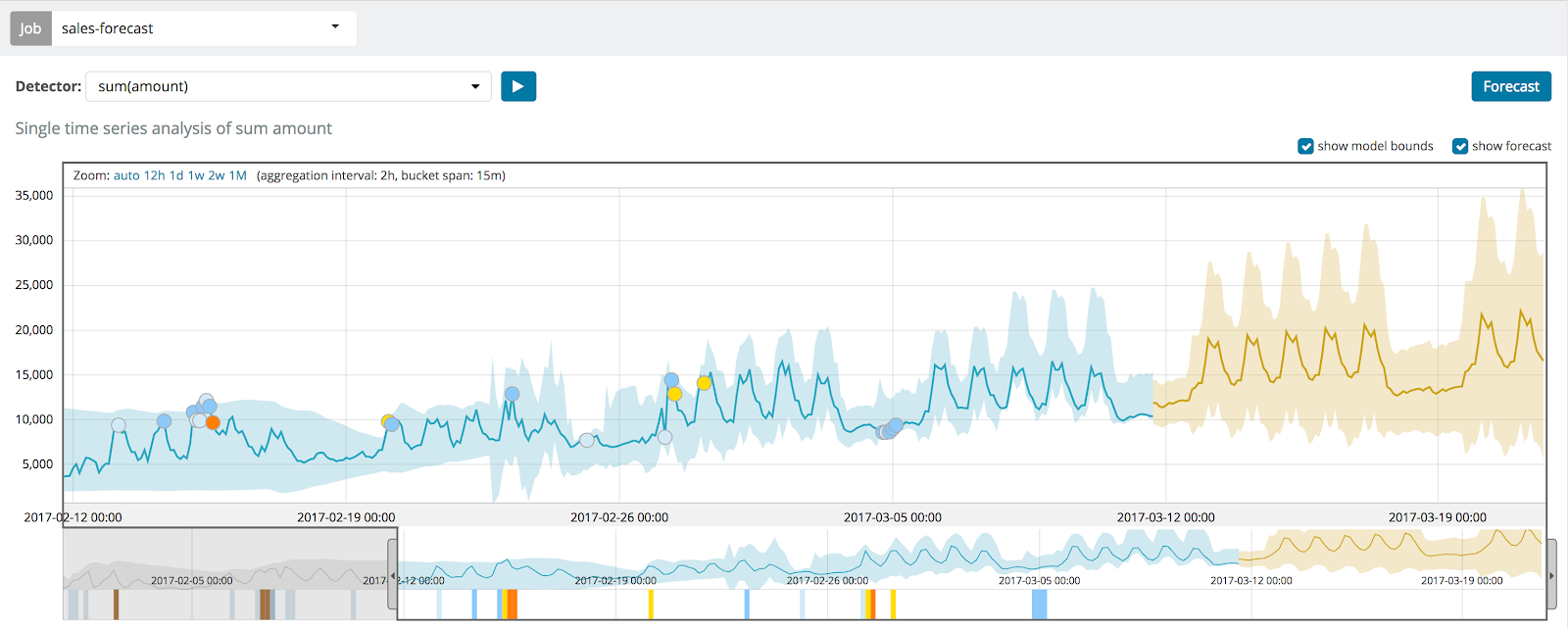
Planejamento de capacidade com aprendizado de máquina e previsão
Muito se falou que o desempenho no passado não é indicativo de resultados no futuro. Entretanto, a melhor maneira de prever resultados para o planejamento da capacidade é usar indicadores de desempenho do passado.
Como é possível determinar quando um determinado recurso atingirá sua capacidade? Por exemplo, se você estiver monitorando o espaço em disco do servidor, talvez seja necessário estimar quando o espaço será esgotado. Você pode usar os modelos de aprendizado de máquina do Elastic para prever o futuro e identificar quando será necessário adicionar armazenamento ao sistema.
Outro método de planejamento da capacidade é prever uma métrica de volume em um tempo específico no futuro. Um exemplo disso seria tentar prever quantas chamadas de clientes seriam esperadas para o seu negócio em uma tarde de segunda-feira. Analisando dados históricos e usando os complexos modelos de aprendizado de máquina, você disporá das informações necessárias para tomar decisões sobre pessoal e recursos.
Introdução ao uso da previsão
As previsões podem ser executadas a partir do Single Metric Viewer dos trabalhos de aprendizado de máquina existentes. Depois que um sistema for atualizado para a versão 6.1, haverá um novo botão de opções, no canto superior direito, para prever trabalhos.
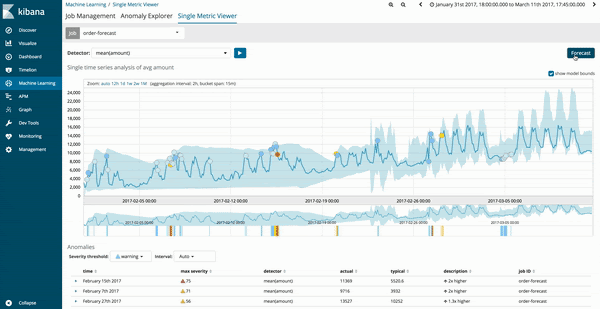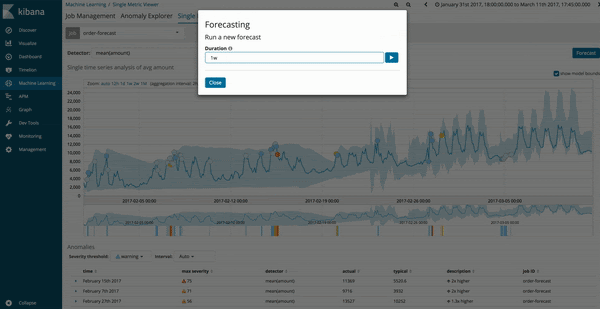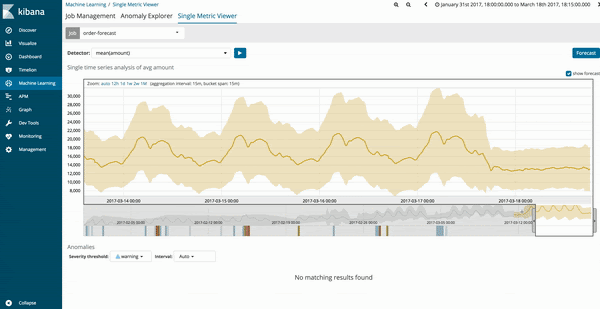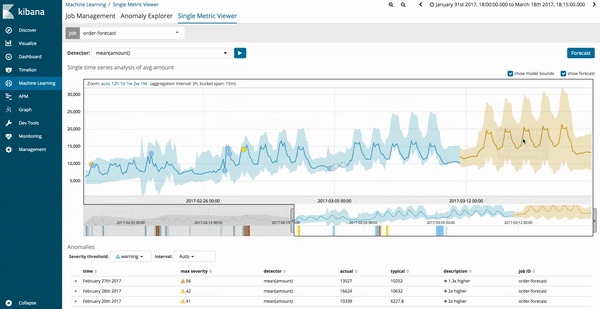
Os resultados da previsão para o trabalho de aprendizado de máquina serão estimados na linha de tendência amarelo-escura com o modelo de confiança em uma faixa amarela mais clara. Se a faixa amarelo-clara for fina, isso indicará uma maior confiança na previsão. A faixa amarelo-clara fica mais grossa à medida que o modelo de previsão fica menos confiável.
Avaliações ao criar uma previsão
Há vários detalhes que devem ser avaliados ao criar modelos de previsão para entender melhor os resultados. Os resultados de previsão podem não ter a aparência esperada, e eles não funcionam com qualquer conjunto de dados.
É recomendável coletar dados históricos suficientes antes de tentar executar um trabalho de aprendizado de máquina para previsão. O momento ideal normalmente é de cerca de três semanas ou três intervalos inteiros de dados periódicos. Se você executar uma previsão com muita antecedência na etapa de aprendizado, antes de o modelo ficar estabelecido, provavelmente ele exibirá resultados inúteis.
Se os níveis de confiança da previsão ultrapassarem os limites razoáveis, o modelo de previsão será interrompido prematuramente. O trabalho de previsão será interrompido e aparecerá uma mensagem (como esta abaixo) indicando que o nível de confiança ficou fora dos limites aceitáveis.

Os resultados da previsão serão bem mais fáceis de entender se a plotagem do modelo estiver ‘ligada’. Isso é uma opção, e em trabalhos de métrica única, ligado é o padrão. Para trabalhos de várias métricas, a opção de plotagem de modelo pode ser ligada configurando a opção ‘model-plot-config’ na configuração de trabalho de aprendizado de máquina.
Para ajudar a rastrear qualquer previsão específica fora do Single Metric Viewer, cada previsão receberá um ID exclusivo, chamado forecast_ID, para que cada previsão possa ser consultada separadamente. Várias previsões podem ser executadas para a mesma métrica, mas a interface de usuário exibirá somente as cinco últimas previsões executadas para qualquer métrica. Ainda assim, todas as previsões ficam disponíveis e assumem o espaço de índice correspondente. Os resultados da previsão serão excluídos automaticamente depois de 14 dias se você executá-los a partir da interface de usuário, enquanto o uso direto da API permite especificar a validade dos dados. Consulte a documentação de previsão para saber detalhes.
O recurso de aprendizado de máquina é fornecido com uma assinatura do Elastic Platinum, mas você pode fazer download de uma avaliação gratuita do X-Pack e fazer um teste.