Descoberta de padrões anômalos com base em relações de processos pai-filho
À medida que os antivírus e os softwares de detecção de malware baseados em machine learning aumentaram sua eficácia contra ataques com foco em arquivos, os adversários migraram para as técnicas “living off the land” para driblar os softwares de segurança modernos. Essas técnicas consistem na execução de ferramentas que vêm pré-instaladas com o sistema operacional ou costumam ser trazidas pelos administradores para trabalhos de rotina como automatizar tarefas administrativas de TI, executar scripts regularmente, executar código em sistemas remotos etc. Pode ser difícil identificar invasores que usam ferramentas confiáveis do sistema operacional como powershell.exe, wmic.exe ou schtasks.exe. Esses binários são inerentemente benignos em si e costumam ser usados na maioria dos ambientes. Dessa forma, os invasores conseguem ignorar trivialmente a maioria das defesas de primeira linha simplesmente misturando-se às tarefas que são executadas de forma recorrente. Para detectar padrões como esse depois que o estrago foi feito, é preciso examinar milhões de eventos sem um ponto de partida claro.
Em resposta, os pesquisadores de segurança começaram a criar detectores cujo alvo são cadeias de processos pai-filho suspeitas. Usando o MITRE ATT&CK™ como manual, os pesquisadores podem escrever uma lógica de detecção para alertar sobre um pai específico que esteja iniciando um processo filho com determinados argumentos de linha de comando. Um bom exemplo é o alerta de um processo do Microsoft Office que inicia o powershell.exe com argumentos codificados em base64. No entanto, esse é um processo demorado que requer conhecimento especializado e um loop de feedback explícito para ajustar os detectores.
Profissionais especialistas em segurança abriram o código de diversos frameworks Vermelho x Azul para simular ataques e avaliar o desempenho do detector. No entanto, qualquer que seja a eficácia do detector, sua lógica pode resolver apenas um ataque específico. A incapacidade dos detectores de generalizar e detectar ataques emergentes constitui uma oportunidade única para o machine learning.
Vamos pensar em termos de gráficos
Quando começamos a pensar em detectar processos pai-filho anômalos, mergulhei imediatamente na ideia de transformar isso em um problema gráfico. Afinal, a execução do processo pode ser expressa como um gráfico para um determinado host. Os nós em nosso gráfico serão processos individuais divididos por ID do processo (PID), enquanto cada uma das bordas, que conectam os nós, será um evento process_creation. Uma determinada borda conterá metadados importantes derivados do evento, como registros de data e hora, argumentos de linha de comando e o usuário.
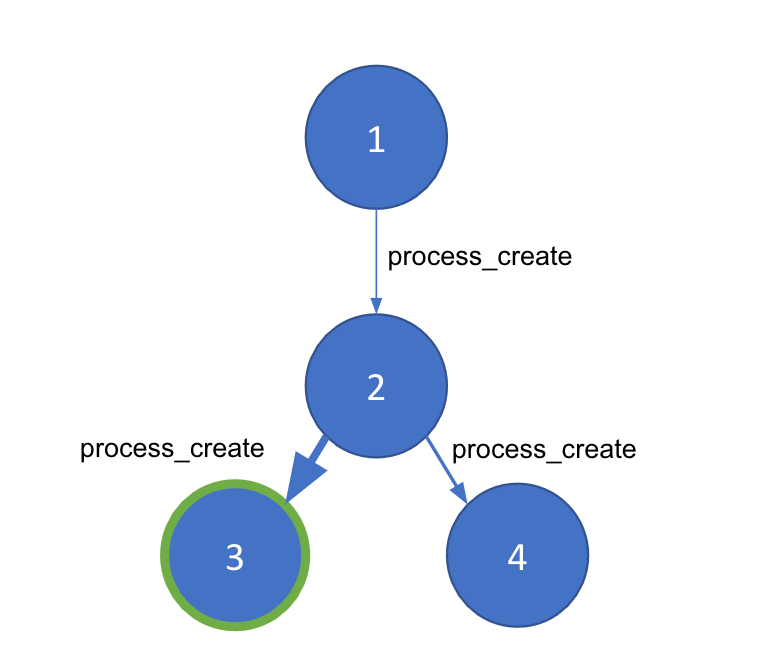
Agora temos uma representação gráfica dos eventos de processo de uma máquina host. No entanto, os ataques “living off the land” podem se originar dos mesmos processos no nível do sistema que estão sempre em execução. Precisamos de uma maneira de separar as cadeias de processos boas e más dentro de um determinado gráfico. A detecção de comunidade é uma técnica que segmenta um gráfico grande em “comunidades” menores, com base na densidade das bordas entre os nossos nós. Para usar isso, precisamos de uma maneira de gerar um peso entre os nós para garantir que a detecção de comunidade funcione corretamente e identifique as partes anômalas do nosso gráfico. Para isso, vamos recorrer ao machine learning.
Machine learning
Para gerar nosso modelo de peso da borda, usaremos o aprendizado supervisionado, uma abordagem de machine learning para a qual é necessário ter dados rotulados alimentando o modelo. Felizmente, podemos usar os frameworks open source Azul e Vermelho mencionados acima para ajudar a gerar alguns dados de treinamento. Abaixo estão alguns dos frameworks open source Vermelho e Azul usados no nosso corpus de treinamento:
Frameworks da equipe Vermelha
- Atomic Red Team (Red Canary)
- Red Team Automation (automação da equipe Vermelha) (Endgame/Elastic)
- Caldera Adversary Emulation (emulação de adversário da Caldera) (MITRE)
- Metta (Uber)
Frameworks da equipe Azul
- Atomic Blue (Endgame/Elastic)
- Cyber Analytics Repository (repositório de ciberanalítica) (MITRE)
- MSFT ATP Queries (consultas MSFT ATP) (Microsoft)
Ingestão e normalização de dados

Após ingerirmos alguns dados do evento, precisaremos transformá-los em uma representação numérica (Figura 2). Essa representação permitirá que o modelo aprenda detalhes mais amplos de um relacionamento pai-filho no escopo de um ataque, o que ajuda a evitar o mero aprendizado de assinaturas.
Primeiro, realizamos a engenharia de recursos (Figura 3) em nomes de processos e argumentos de linha de comando. A vetorização TF-IDF capturará a importância estatística de uma determinada palavra para um evento em nosso conjunto de dados. A conversão de registros de data e hora em números inteiros nos permitirá determinar o delta entre a hora de início do processo pai e quando um processo filho foi iniciado. Outros recursos são de natureza binária (por exemplo, 1 ou 0, sim ou não). Alguns bons exemplos desse tipo de recurso:
- O processo está assinado?
- Confiamos no assinante?
- O processo é elevado?

Após a transformação do nosso conjunto de dados, nós o usaremos para treinar um modelo de aprendizado supervisionado (Figura 4). O modelo serve para fornecer uma “pontuação de anomalia” para um determinado evento de criação de processo entre 0 (benigno) e 1 (anômalo). Podemos usar a pontuação de anomalia como um peso para a borda no nosso gráfico!
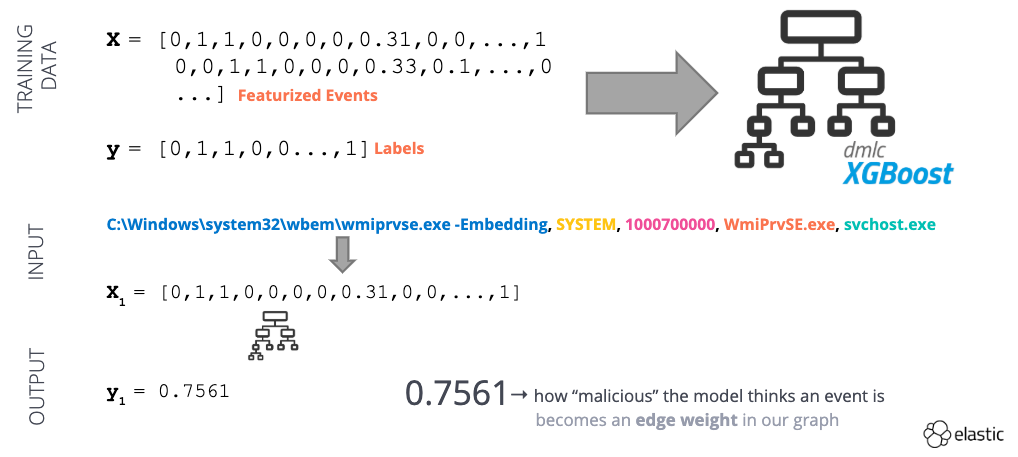
Figura 4 — Exemplo de um fluxo de trabalho supervisionado de machine learning
Serviço de prevalência


Figura 5 — Probabilidades condicionais usadas pelo Mecanismo de Prevalência
Agora temos um gráfico de pesos — cortesia do nosso modelo de machine learning. Missão cumprida, certo? O modelo que treinamos faz um ótimo trabalho ao tomar uma decisão boa/má para uma determinada cadeia pai-filho, com base em nossa compreensão global do que é bom e do que é mau. Mas cada ambiente de cada cliente será diferente. Haverá processos que nunca observamos antes e administradores de sistemas que usam o PowerShell para... bem, para tudo.
Basicamente, se usássemos apenas esse modelo e nada mais, provavelmente veríamos uma infinidade de falsos positivos e aumentaríamos a quantidade de dados que um analista precisaria examinar. Para compensar esse problema em potencial, desenvolvemos um serviço de prevalência para nos dizer o quanto uma determinada cadeia de processos pai-filho é comum dentro desse ambiente. Ao levar em conta as nuances locais do ambiente, poderemos elevar ou suprimir eventos suspeitos com mais confiança e extrair as cadeias de processos verdadeiramente anômalas.
O serviço de prevalência (Figura 5) baseia-se em duas estatísticas derivadas da probabilidade condicional que nos permitem afirmar o seguinte: “Desse pai, vi esse filho mais do que X% de outros processos filho” E “Desse processo, vi essa linha de comando mais do que X% de outras linhas de comando associadas ao processo”. Após implementarmos o Serviço de Prevalência, podemos fazer os retoques finais em nossa lógica de detecção principal, find_bad_communities.
Encontrar comunidades “más”

Figura 6 — Código Python para descobrir comunidades anômalas
Acima (Figura 6), vemos o código Python usado para gerar as comunidades más. A lógica para find_bad_communities é muito direta:
- Classifique cada evento process_create de uma máquina host para gerar um par de nós (por exemplo, nó pai e nó filho) e um peso associado (por exemplo, a saída do nosso modelo)
- Construa um gráfico direcionado
- Execute a detecção de comunidade para gerar uma lista de comunidades no gráfico.
- Em cada comunidade, determinamos a prevalência de um pai-filho (por exemplo, cada conexão). Nós levamos em conta o quanto um evento pai-filho é comum no anomalous_score final.
- Se o anomalous_score atinge ou excede um limite, separamos a comunidade inteira para os analistas examinarem
- Depois que cada comunidade foi analisada, retornamos uma lista de comunidades “más” classificadas pelo anomalous_score máximo
Resultados
Treinamos o modelo final com uma combinação de dados benignos e maliciosos, simulados e do mundo real. Os dados benignos consistiram em três dias de dados de eventos de processos do Windows reunidos em nossa rede interna. As fontes desses dados foram uma mistura de estações de trabalho de usuários e servidores para replicar uma pequena organização. Geramos dados maliciosos detonando todas as técnicas do ATT&CK disponíveis por meio do framework de RTA da Endgame, além de executar malware baseado em macro e binário de adversários avançados como FIN7 e Emotet.
Para o nosso experimento principal, decidimos usar dados de eventos da Avaliação do MITRE ATT&CK fornecida pelo projeto Mordor de Roberto Rodriguez. A Avaliação do ATT&CK procurou emular a atividade do APT3 usando ferramentas disponíveis comercialmente e software open source gratuito como PSEmpire e CobaltStrike. Essas ferramentas permitem que as técnicas “living off the land” sejam encadeadas para executar tarefas de Execução, Persistência ou Evasão da Defesa.
O framework foi capaz de identificar diversas cadeias de ataque com várias técnicas usando exclusivamente eventos de criação de processos. Descoberta (Figura 7) e movimento lateral (Figura 8) que descobrimos e destacamos para os analistas examinarem.

Figura 7 — Cadeia de processos executando técnicas de “Descoberta”

Figura 8 — Cadeia de processos executando movimento lateral
Redução de dados
Um subproduto da nossa abordagem é não apenas a capacidade de descobrir cadeias de processos anômalos, mas também a capacidade de demonstrar o valor do mecanismo de prevalência na supressão de falsos positivos. Em conjunto, conseguimos reduzir drasticamente a quantidade de dados de eventos que precisavam ser examinados por um analista. Em números:
- Registramos cerca de dez mil eventos de criação de processos por endpoint no cenário do APT3 (total de cinco endpoints).
- Identificamos cerca de seis comunidades anômalas por endpoint.
- Cada comunidade consistia em cerca de seis a oito eventos cada.
Um olhar para o futuro
Estamos no processo de fazer essa pesquisa evoluir de uma prova de conceito para uma solução integrada como um recurso do Elastic Security. O recurso mais promissor é o mecanismo de prevalência. Mecanismos de prevalência que destacam a frequência da ocorrência de arquivos são comuns, mas descrever a prevalência das relações entre eventos ajudará os profissionais de segurança a detectar ameaças de novas maneiras, observando o que é raro/comum em sua empresa e, por fim, ampliando com mensurações do que é raro globalmente.
Conclusão
Apresentamos esse framework baseado em gráficos (chamado ProblemChild) no VirusBulletin e na CAMLIS no ano passado, com o objetivo de reduzir a necessidade de conhecimento especializado no processo de desenvolvimento de detectores. Ao aplicar o machine learning supervisionado para derivar um gráfico ponderado, demonstramos a capacidade de identificar comunidades de eventos aparentemente díspares em sequências de ataques maiores. Nosso framework aplica probabilidade condicional para classificar comunidades anômalas automaticamente, bem como suprimir cadeias pai-filho que ocorrem com frequência. Quando aplicado a ambos os objetivos, esse framework pode ser usado pelos analistas para auxiliar na elaboração ou ajuste de detectores e reduzir os falsos positivos ao longo do tempo.