검색 가능한 스냅샷의 새로운 Elasticsearch 콜드 티어를 대규모 운영 환경에서 테스트
Elasticsearch 7.10에서 베타 버전으로 제공되었던 검색 가능한 스냅샷의 콜드 티어가 이제 Elasticsearch 7.11에서 정식 버전으로 출시되었습니다. 이 새로운 데이터 티어를 사용하면 핫 티어 및 웜 티어와 동일한 수준의 안정성과 중복성을 유지하면서 웜 티어와 비교하여 클러스터 저장 공간을 최대 50% 절감할 수 있습니다.
이 블로그에서는 Elastic에서 진행했던 시나리오를 함께 살펴보면서 콜드 티어가 대규모에서도 원활하게 작동하는지 확인하고, Elastic에서 솔루션의 품질과 안정성을 얼마나 중요하게 생각하는지 짚어봅니다.
콜드 티어 요약
콜드 티어는 복제본 샤드의 필요성을 없애고 대신 스냅샷(AWS S3, Google Storage 또는 Microsoft Azure Storage와 같은 객체 스토어에 저장)을 사용하여 필요한 복원력을 제공함으로써 기본 샤드만 로컬 저장 공간에 보관하여 클러스터 비용을 절감합니다. 로컬 저장 공간은 기본적으로 리포지토리에 있는 스냅샷 데이터의 캐시된 버전처럼 작동합니다.
콜드 노드 또는 로컬 저장 공간에 오류가 발생하는 경우 검색 가능한 스냅샷에서 자동으로 복구를 수행하며 해당 샤드를 다른 노드로 리밸런싱합니다.
전체 클러스터 또는 롤링 재시작(또는 노드 재부팅)의 경우 로컬 저장 공간이 지속적으로 유지되며 로컬에서 사용 가능한 데이터는 스냅샷에서 다시 다운로드되지 않으므로, 정상 클러스터로 돌아가는 데 필요한 시간을 최소화할 수 있을 뿐만 아니라 불필요한 네트워크 비용도 방지할 수 있습니다.
운영 규모가 확장되어도 이 모든 기능이 정상적으로 작동하는지 확인하기 위해 다음 요소를 사용한 세 가지 시나리오에 검증 노력을 집중했습니다.
- Elasticsearch 노드 5개(16G 힙)
- RAID-0 구성의 2TB 마그네틱 디스크 6개
- 각각 5개의 샤드가 있는 10개의 인덱스에 분산된 로깅 데이터가 하나의 세그먼트로 강제 병합된 5TB 스냅샷(강제 병합은 읽기 액세스를 위한 인덱스를 최적화하고 장애 발생 시 복원해야 하는 파일 수를 줄임)
시나리오 1: 전체 클러스터 재시작
검증한 첫 번째 시나리오는 전체 클러스터 재시작이었습니다. 이를 확인하기 위해 다음 단계를 수행했습니다.
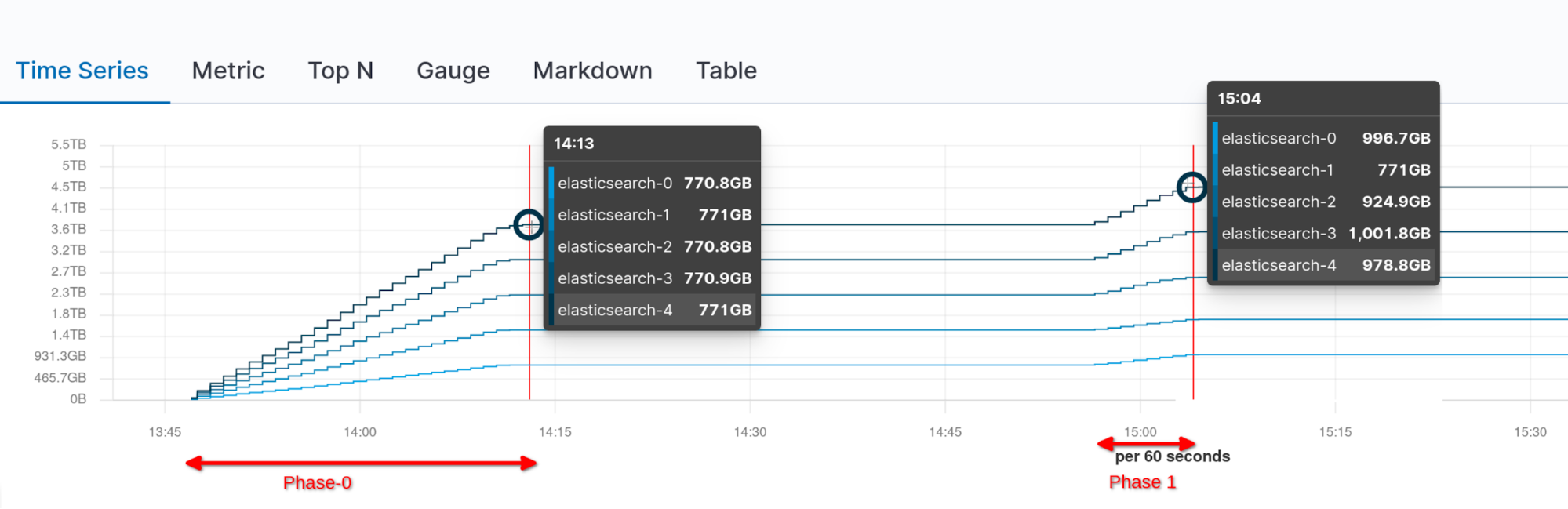
- 5TB의 검색 가능한 스냅샷을 마운트하고 로컬 캐시가 완전히 사전 워밍업될 때까지 기다립니다(페이즈 0).
- 전체 클러스터 재시작 지침에 따라 전체 클러스터 재시작을 실행합니다.
- 할당을 다시 활성화한 후 클러스터가 다음을 완료하는 데 걸리는 시간을 측정합니다.
- 정상 상태로 전환
- 모든 백그라운드 다운로드를 완료하여 캐시 사전 워밍업
- 3단계 이후에 추가로 샤드 리밸런싱이 일어나지 않도록 해야 합니다.
Elasticsearch 7.11에 새롭게 도입된 영구 계층 덕분에 모든 노드를 시작하고 할당을 재활성화한 후에는 클러스터가 즉시 정상 상태가 되고 백그라운드 다운로드가 발생하지 않았습니다.
아래 그래프를 보면 마운트 중(페이즈 0)과 전체 클러스터 재시작 및 할당 재활성화 후(페이즈 1, 추가 네트워크 트래픽 없음)의 누적 네트워크 트래픽을 확인할 수 있습니다.

시나리오 2: 롤링 재시작
검증한 두 번째 시나리오는 일반적인 롤링 클러스터 재시작 사례였습니다.
실험 방식은 전체 클러스터 재시작과 비슷했습니다.
- 5TB의 검색 가능한 스냅샷을 마운트하고 로컬 캐시가 완전히 사전 워밍업될 때까지 기다립니다.
- 각 노드를 중지하기 전에 샤드 할당을 비활성화하여 첫 번째 노드에 대한 롤링 재시작 절차를 실행합니다.
- 노드를 시작하고 샤드 할당을 다시 활성화한 후, 정상 상태로 전환되는 데 걸리는 시간을 측정합니다. 영구 캐시 덕분에 빠르게 전환될 것으로 예상했습니다. 또한 재시작 후 불필요한 백그라운드 다운로드가 발생하지 않도록 했습니다.
- 클러스터의 다른 모든 노드에 대해 2단계와 3단계를 반복합니다.
이 실험 또한 성공적이었습니다. Elasticsearch 7.11에 도입된 영구 캐시 덕분에 거의 즉각적으로 정상 상태로 전환되었으며 스냅샷에서 추가적인 백그라운드 다운로드가 발생하지 않았습니다.
시나리오 3: 노드 장애
마지막으로 노드 하나에 장애가 발생할 때 적절한 조치가 이루어지는지 확인하고자 다음 실험을 수행했습니다.
- 5TB의 검색 가능한 스냅샷을 마운트하고 로컬 캐시가 완전히 사전 워밍업될 때까지 기다립니다(페이즈 0).
- Elasticsearch 노드 5개 중 하나(node-1)를
SIGKILL을 사용하여 종료하고 클러스터가 다시 정상 상태로 바뀔 때까지 기다립니다(페이즈 1).- 종료된 노드에 호스팅된 샤드로부터 데이터를 수신하는 것과 백그라운드 다운로드가 관련이 있는지 확인합니다.
- 정상 상태로 전환된 후에는 추가적인 리밸런싱이 수행되어서는 안 됩니다.
- 장애가 발생한 노드를 다시 시작합니다(페이즈 2).
- 나머지 노드 4개에 모든 데이터가 있으므로 피어 복구만 수행하여 샤드를 리밸런싱해야 합니다.
- 클러스터가 정상 상태로 전환되어야 합니다.
이번 실험도 성공적이었습니다. node-1이 종료된 후, 나머지 노드가 종료된 노드에 호스팅된 샤드를 검색 가능한 스냅샷에서 자동으로 복원했습니다.
노드별 네트워크 트래픽을 시각화한 아래 차트에서 볼 수 있듯이, 클러스터가 정상 상태로 전환된 후에는 추가적인 리밸런싱이 발생하지 않았습니다.
누락된 노드를 되살린 후에는 피어 복구가 시작되었고 균등하게 분산된 클러스터를 만들기 위해 필요한 양만큼의 샤드를 node-1이 다시 호스팅하게 되었습니다.

지금 바로 시작
지금까지 기능 검증을 수행해 보았는데요. 흥미로운 시간이 되셨길 바랍니다!
검색 가능한 스냅샷을 시작하고 콜드 티어에 데이터를 저장하려면 Elastic Cloud에서 클러스터를 구동하거나 Elastic Stack의 최신 버전을 설치하세요. 이미 Elasticsearch를 실행 중이신가요? 그렇다면 클러스터를 7.11로 업그레이드하신 후 다시 사용해 보세요. 자세한 내용은 데이터 티어 및 검색 가능한 스냅샷 설명서에서 확인하실 수 있습니다.