7.7의 새로운 기능: Elasticsearch 힙 메모리 사용 대폭 감소
Elasticsearch 사용자가 Elasticsearch 노드에 데이터를 저장할 수 있는 용량의 한계까지 최대한 이용하고 있을 때, 디스크 공간이 부족해지기 전에 힙 메모리가 부족해지는 경우가 가끔 발생합니다. 이러한 사용자에게는 무척 실망스러운 상황입니다. 노드당 가능한 한 많은 데이터를 채우는 것이 종종 비용을 줄이는 데 중요하기 때문입니다.
그러나 왜 Elasticsearch는 데이터를 저장하기 위해 힙 메모리를 필요로 할까요? 왜 그냥 디스크 공간만 필요로 하지 않을까요? 몇 가지 이유가 있지만 주된 이유는 Lucene이 디스크의 어디를 찾아봐야 하는지 알 수 있도록 메모리에 일부 정보를 저장해야 하기 때문입니다. 예를 들어, Lucene의 역 인덱스는 정렬된 순서로 디스크 상에서 용어를 블록으로 그룹화하는 용어 사전과 용어 사전에서 빠르게 찾아보기 위한 용어 인덱스를 구성합니다. 이 용어 인덱스는 용어의 접두사를 해당 접두사를 갖는 용어를 포함하는 블록이 시작되는 디스크의 오프셋과 매핑합니다. 용어 사전은 디스크 상에 있지만 용어 인덱스는 최근까지도 힙에 있었습니다.
인덱스는 얼만큼의 메모리를 필요로 할까요? 통상적으로 인덱스의 GB당 몇 MB 정도입니다. 이것은 그리 많은 것은 아니지만 사용자가 노드에 점점 더 많은 테라바이트의 디스크를 장착하고 있어, 이러한 테라바이트의 인덱스를 저장하려면 인덱스는 금방 10-20GB의 힙 메모리를 필요로 하기 시작합니다. 30GB의 힙을 초과하지 말라는 Elastic의 권장 사항을 고려하면, 이로 인해 집계와 같이 힙 메모리를 사용해야 하는 다른 요소들을 위한 여유가 빠듯하게 되며, JVM이 클러스터 관리 운영을 위해 충분한 공간을 남겨두지 않는 경우 안정성 문제가 시작되게 됩니다.
실제 수치를 살펴봅시다. Elastic은 여러 데이터 세트에 대해 야간 벤치마크를 실행하고, 시간에 걸쳐 다양한 메트릭을, 특히 세그먼트의 메모리 사용을 추적합니다. Geonames 데이터 세트는 흥미로운데, 다음과 같이 Elasticsearch 7.x에서 발생한 다양한 변경 사항의 영향을 분명하게 보여주기 때문입니다.
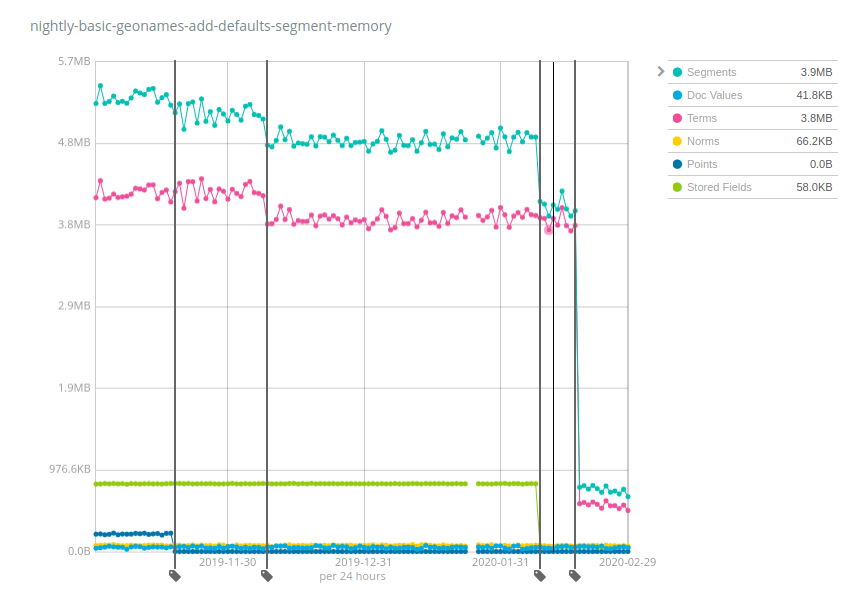
이 인덱스는 디스크에서 약 3GB를 차지하며 6개월 전에는 ~5.2MB의 메모리를 필요로 했었습니다. 이것은 ~1:600의 힙:저장 공간 비율입니다. 따라서 각 노드에 총 10TB를 장착했다면, 10TB / 600 = 17GB의 힙이 필요하게 됩니다. 그래야 Geonames 같은 데이터를 저장하는 인덱스를 계속해서 열어둘 수 있습니다. 그러나 보시다시피, 시간이 지나면서 개선이 이루어졌습니다. 포인트(짙은 파랑색)는 훨씬 더 적은 메모리를 요구하기 시작했고, 그 다음에는 용어(분홍색)가 그 다음에는 저장된 필드(초록색)가 마침내 용어가 다시 큰 요인이 됩니다. 힙:저장 공간 비율은 이제 ~1:4000이며 6.x와 초기 7.x 릴리즈에 비해 거의 7배의 개선을 보여줍니다. 이제 10TB의 인덱스를 계속 열어두는 데 단지 2.5GB의 힙 메모리만 필요하게 됩니다.
데이터 세트에 따라 수치는 엄청나게 다양한데, 좋은 소식은 Geonames가 힙 사용량이 가장 적게 감소된 것으로 나타나는 데이터 세트 중 하나라는 것입니다. 힙 사용량이 Geonames에서 7배까지 줄어든 반면 NYC taxis와HTTP logs 데이터 세트에서는 100배 이상 줄어들었습니다. 다시 한 번 알 수 있지만, 이러한 변화는 Elasticsearch의 이전 버전이 감당할 수 있었을 것보다 노드당 훨씬 더 많은 데이터를 저장함으로써 비용을 줄이는 데 도움이 됩니다.
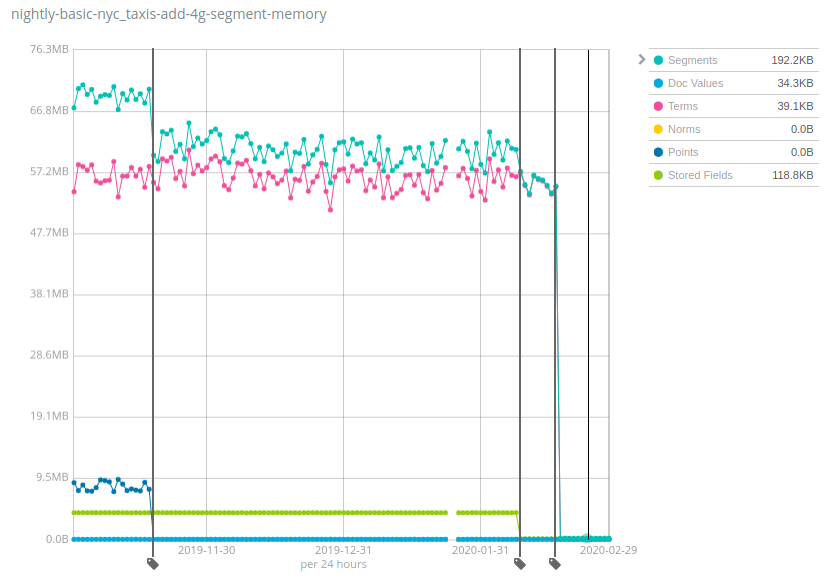
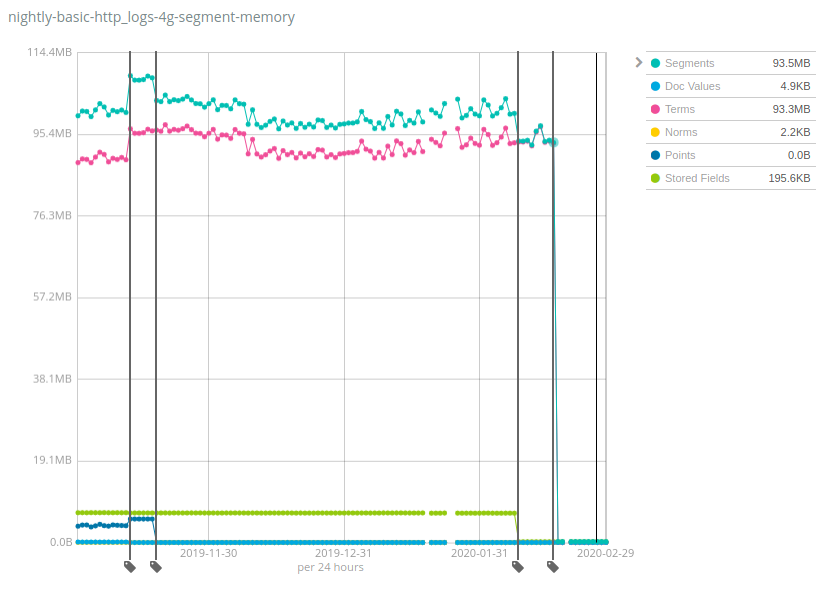
이것은 어떻게 작동하며 그 함정은 무엇일까요? 동일한 방법을 Lucene 인덱스의 여러 구성 요소에 시간을 두고 적용해 보았습니다. 데이터 구조를 JVM 힙에서 디스크로 이동하고 메모리의 핫 비트를 유지하기 위해 파일 시스템 캐시(종종 페이지 캐시 또는 OS 캐시라고 부름)에 의존하는 것입니다. 이것은 이 메모리가 아직도 사용되며 그냥 다른 곳에 할당되는 것으로 해석할 수도 있지만 현실은 이 메모리의 상당 부분이 사용 사례에 따라 그저 한 번도 사용되지 않았다는 것입니다. 예를 들어 용어의 최종 드랍은 디스크 상의 _id 필드의 용어 인덱스를 옮기는 것 때문이었으며, 이것은 GET API를 사용할 때나 또는 명시적인 ID를 가진 문서를 색인할 때만 유용합니다. 로그와 메트릭을 Elasticsearch로 색인하는 대다수의 사용자는 전혀 이러한 작업을 하지 않으며 따라서 그러한 사용자에게 이것은 리소스의 순이익이 됩니다.
7.7로 Elasticsearch 힙을 줄이세요!
Elasticsearch 7.7에서 제공될 이러한 개선 사항에 대해 정말 기대가 됩니다. 여러분도 그러시길 바랍니다. 향후 릴리즈 발표를 지켜봐 주시고, 그 다음에 직접 테스트해 보세요. 여러분의 기존 배포에서 사용해 보거나 Elastic Cloud의 Elasticsearch Service 무료 체험판을 사용해 보세요(무료 체험판은 언제나 Elasticsearch의 최신판입니다). 여러분의 피드백을 듣고 싶습니다. 어떻게 생각하시는지 토론 게시판에서 알려주세요.