Logstash를 사용해야 하나요, Elasticsearch 수집 노드를 사용해야 하나요?
Logstash는 Elastic Stack의 원래 구성 요소 중 하나로서, 구문을 분석하고, 데이터를 보강하거나 처리할 필요가 있을 때 사용하던 오랜 도구였습니다. 세월이 흐르면서, 수많은 입력과 출력, 필터 플러그인이 추가되었고, 덕분에 수많은 다양한 아키텍처에서 작동될 수 있도록 만들어진 극히 유연하고 강력한 도구가 되었습니다.
수집 노드는 색인에 앞서 Elasticsearch에서 문서를 처리하기 위한 방법으로 Elasticsearch 5.0에서 도입되었습니다. 최소한의 구성 요소로 간단한 아키텍처를 가능하게 하여, 애플리케이션이 처리와 색인을 위해 Elasticsearch로 직접 데이터를 전송하게 해줍니다. 이것은 종종 Elastic Stack에서 작업을 시작하는 것을 간소화해주지만, 또한 데이터 용량이 증가하면서 확장되기도 합니다.
그러나 수집 노드는 Logstash의 일부 기능과 중복됩니다. 따라서 우리 사용자들은 어느 것을 사용해야 하는지 흔히 질문하곤 합니다. 이 블로그 포스트에서는 보다 나은 정보에 입각한 결정을 내리는데 도움이 되도록 둘 중에 선택할 때 사용자가 고려해야 하는 아키텍처 측면에 대해 논의해 보겠습니다.
이것은 사용자들이 흔히 던지는 질문에 대한 답변 시리즈 그 세 번째입니다. 앞의 두 질문은 다음과 같습니다.
데이터를 어떻게 입출력하나요?
Logstash와 수집 노드의 주요한 차이점 중 하나는 데이터가 입출력되는 방식입니다.
수집 노드가 Elasticsearch의 색인 플로우 내에서작동할 때, 데이터는 벌크나 색인 요청을 통해 거기로 푸시되어야 합니다. 그러므로 Elasticsearch에 능동적으로 데이터를 작성하는 프로세스가 있어야 합니다. 수집 노드는 메시지 큐나 데이터베이스와 같은 외부 출처에서 데이터를 뽑아낼 수는 없습니다.
데이터가 처리된 후 유사한 제한이 존재합니다. 유일한 옵션은 데이터를 로컬에서 Elasticsearch로 색인하는 것입니다.
반면에, Logstash는 입력과 출력 플러그인의 폭이 굉장히 넓으며, 아주 다양한 아키텍처를 지원하는데 사용될 수 있습니다. 서버로서도 기능할 수 있고, TCP, UDP, HTTP를 통해 클라이언트가 푸시한 데이터를 받아들일 수도 있으며, 데이터베이스나 메시지 큐 등으로부터 데이터를 능동적으로 뽑아낼 수도 있습니다. 거기서 출력하는 것의 경우를 보면, Kafka와 RabbitM과 같은 메시지 큐 또는 S3나 HDFS 상의 장기 데이터 아카이벌처럼 사용할 수 있는 옵션이 굉장히 다양합니다.
큐잉과 배압(back-pressure)은 어떤가요?
직접이든 수집 파이프라인을 통해서이든 Elasticsearch로 데이터를 전송할 때, 모든 클라이언트는 Elasticsearch가 데이터를 동일한 수준으로 유지하거나 더 많은 데이터를 받아들일 수 없을 때 사례를 처리할 수 있어야 합니다. 이런 것을 가리켜 우리는 배압(back-pressure)을 적용한다고 합니다. 데이터 노드가 데이터를 받아들일 수 없다면, 수집 노드 또한 데이터를 받아들이기를 멈추게 됩니다.
소스에서 또는 그 과정에서, 처리 파이프라인으로 기본 제공되는 큐잉 메커니즘이 없는 아키텍처는 Elasticsearch가 도달할 수 없거나 장기간 동안 데이터를 받아들일 수 없는 경우 데이터 손실을 겪게 될 가능성이 있습니다. 여기에는 파일로부터 데이터를 저장하고 읽을 수 없는 Beats와 아울러 syslog-ng 등 Elasticsearch에 직접 작성할 수 있는 다른 프로세스가 포함됩니다.
Logstash는 큐 영구 저장(Persistent Queue) 기능을 사용해 큐 데이터를 디스크에 저장할 수 있어, Logstash가 최소 한 번 배달 보장을 제공하고 수집량이 급증하는 경우에도 로컬에서 데이터를 버퍼할 수 있도록 합니다. Logstash는 또한 수많은 다른 유형의 메시지 큐와의 통합을 지원하여, 다양한 배포 패턴이 지원되도록 할 수 있습니다.
내 데이터를 어떻게 보강하고 처리할 수 있나요?
수집 노드는 20여개의 프로세서와 함께 제공되며, 가장 흔히 사용되는 Logstash 플러그인의 기능을 합니다. 그러나 한 가지 제약은 수집 노드 파이프라인이 단일 이벤트의 맥락에서만 작동 가능하다는 것입니다. 프로세서는 또한 일반적으로 다른 시스템에 호출하거나 디스크로부터 데이터를 읽을 수 없어, 수행될 수 있는 보강 유형에 어느 정도 제한을 둡니다.
Logstash는 플러그인 선택의 폭이 한결 더 넓습니다. 여기에는 구성 파일, Elasticsearch 또는 관계형 데이터베이스에서의 검색을 기반으로 컨텐츠를 추가하거나 변환하기 위한 플러그인이 포함됩니다.
Beats와 Logstash는 또한 구성 가능한 기준을 기반으로 이벤트 필터링 아웃과 드로핑을 지원합니다. 이것은 현재 수집 노드에서 가능하지 않습니다.
어느 쪽이 구성하기 더 쉬운가요?
이것은 아주 주관적인 주제이며, 사용자의 배경과 사용자가 어떤 일을 주로 하는지 등에 따라 달라집니다. 각 수집 노드 파이프라인은 JSON 문서에서 정의되며, 이것은 Elasticsearch에 저장됩니다. 별개의 파이프라인 다수가 정의될 수 있지만, 각 문서는 수집 노드를 통과할 때 단일 파이프라인에 의해서만 처리될 수 있습니다. 이 포맷은 Logstash 구성 파일 포맷보다 사용하기가 조금 더 쉬울 수 있습니다. 최소한, 합리적으로 단순하며 잘 정의된 파이프라인에 대해서는 그렇습니다. 여러 데이터 포맷을 처리하는 좀더 복잡한 파이프라인의 경우, Logstash가 플로우를 제어하기 위해 조건문을 사용하도록 허용한다는 사실이 사용을 좀더 쉽게 하는 경우가 많습니다. Logstash는 또한 여러 개의 논리적으로 분리된 파이프라인 정의를 지원하며, 이것은 Kibana 기반의 사용자 인터페이스를 통해 관리될 수 있습니다.
또한 모니터링을 지원하며 병목현상과 잠재적인 문제를 신속하게 찾아내는 데 사용할 수 있는 탁월한 파이프라인 탐색기 UI를 갖추고 있어, 파이프라인 성능 측정과 최적화가 일반적으로 Logstash에서보다 더 쉽다는 것도 언급할 가치가 있습니다.
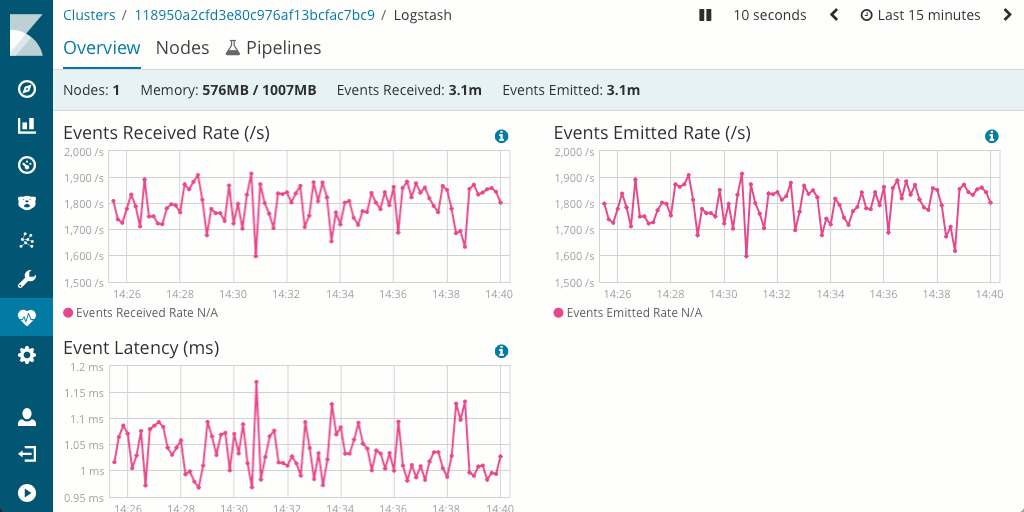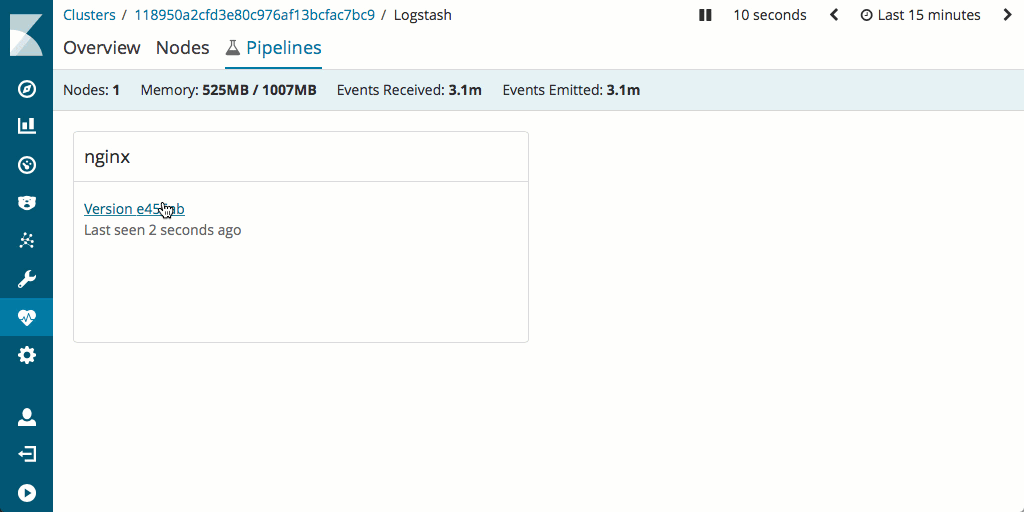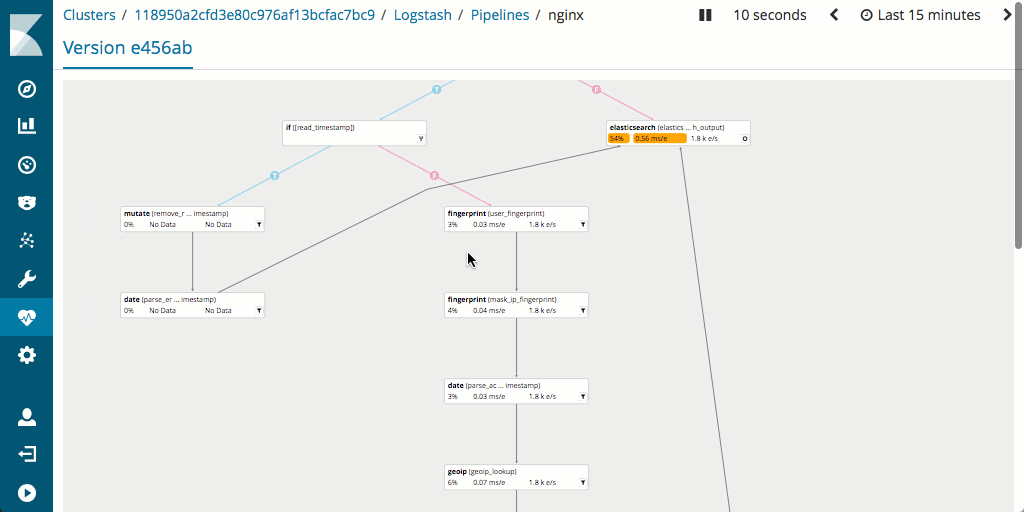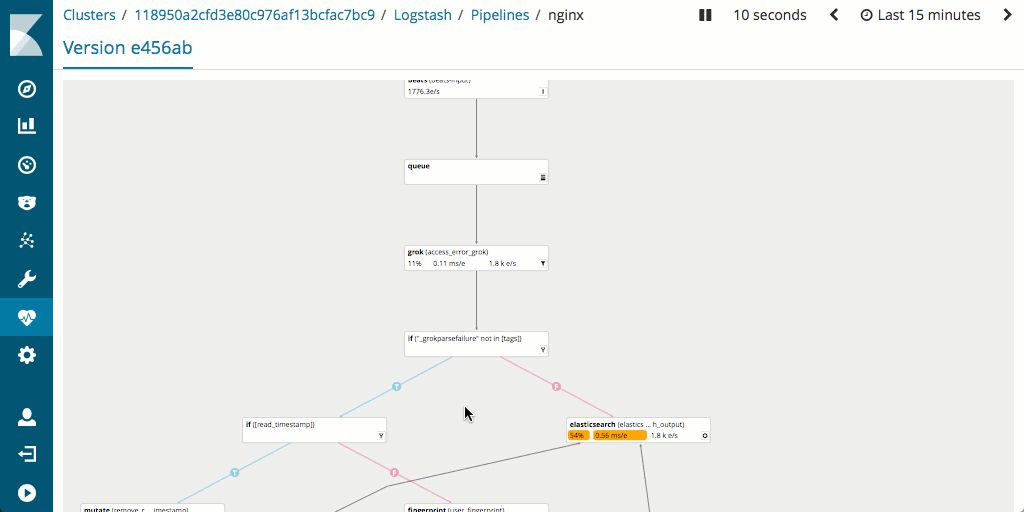
하드웨어 풋프린트에는 어떤 영향을 미치나요?
수집 노드의 아주 좋은 점 중 하나는 Beats가 수집 노드 파이프라인에 직접 작성할 수 있는, 대단히 간단한 아키텍처를 허용한다는 것입니다. Elasticsearch 클러스터의 모든 노드는 수집 노드로 기능할 수 있는데, 이것은 하드웨어 풋프린트를 억제하며, 아키텍처의 복잡성을 줄일 수 있습니다. 최소한 보다 규모가 작은 사용 사례의 경우에는 그렇습니다.
데이터 용량이 증가하거나 프로세싱이 좀더 복잡해지면, 결과적으로 클러스터에서 좀더 높은 CPU 로드가 발생하며, 일반적으로 전용 수집 노드 사용으로 전환할 것을 권장합니다. 현재, 추가적인 하드웨어가 전용 수집 노드나 Logstash를 호스팅하기 위해 필요하게 되며, 하드웨어 풋프린트에서의 모든 차이는 사용 사례에 따라 많이 달라집니다.
Logstash에서는 가능하지 않는 수집 노드만의 기능이 있나요?
현재까지 수집 노드는 Logstash의 일부 기능만 지원하는 것처럼 보입니다. 하지만 이 말이 완전히 정확한 것은 아닙니다.
수집 노드는 수집 첨부 프로세서 플러그인을 지원하며, 이것은 PPT, XLS, PDF 같이 흔한 형식에서 첨부물을 프로세스하고 색인하는데 사용될 수 있습니다. 현재 Logstash에 대해서는 이용 가능한 동등한 플러그인이 없습니다. 따라서 다양한 유형의 첨부물에서 색인을 계획하고 있으면, 수집 노드가 필요할 수 있습니다.
수집 파이프라인이 데이터가 색인되기 직전에 실행되므로, 수집 지연을 정확하게 측정하고 분석하기 위해 언제 이벤트가 색인되었는지를 가리키는 타임스탬프를 추가하는 가장 믿을 수 있는 방법입니다. “배압(back-pressure)”이 적용되거나 클라이언트가 여러 차례 데이터 색인을 재시도해야 하는 경우, 데이터가 성공적으로 Elasticsearch에 도달하기 전에 이것을 설정하면 설정되는 타임스탬프와 Elasticsearch로 색인되는 데이터 간에 지연이 있을 수 있기 때문에 오해의 소지가 생길 수 있습니다. 이런 유형의 타임스탬프는 문서 당 수집 지연을 측정하는데 사용될 수 있습니다.
Logstash와 수집 노드를 함께 사용할 수 있나요?
둘 중 하나를 우선적으로 선택하는 경우가 종종 있지만, Logstash는 수집 파이프라인으로 데이터 전송을 지원하므로 두 개를 함께 사용하는 것 또한 당연히 가능합니다. 좀더 복잡한 아키텍처의 경우, 아주 다른 요건을 가질 수 있는 여러 개의 논리 흐름이 있을 수도 있습니다. 일부는 Logstash를 통할 수 있으며, 반면에 다른 것들은 Elasticsearch 수집 노드로 직접 전송됩니다. 각 데이터 스트림에 대해 가장 합리적인 것을 사용하는 것이 일반적으로 아키텍처를 유지보수하기 더 쉽게 해줍니다.
결론
Logstash와 Elasticsearch 수집 노드 사이에는 기능 상 겹치는 부분이 있습니다. 이것은 일부 아키텍처가 어느 한 쪽의 테크놀로지로 실행될 수 있다는 뜻입니다. 두 가지 옵션은 그러나 서로 다른 강점과 약점이 있습니다. 따라서 전체 프로세싱 파이프라인의 요건과 아키텍처를 분석하고, 이 블로그 포스트에서 논의된 기준을 바탕으로 가장 적절한 것을 선택하는 것이 중요합니다. 선택은 항상 어느 한 쪽이 우세한 것은 아닙니다. 두 가지가 함께 사용될 수 있으며, 또는 프로세싱 파이프라인의 다른 부분에서 병행해서 사용될 수도 있습니다.