Elastic App Search의 다중 언어 Engine 소개
Elastic App Search Engine을 특정 언어에 대해 바로 최적화시킬 수 있습니다. 이번에 출시하는 13개 언어에는 영어, 스페인어, 독일어, 덴마크어, 러시아어, 중국어, 한국어, 일본어가 포함됩니다.
하지만 이로 인해 근본적인 검색 방법이 달라지게 되나요? 이런 도움이 방문자의 검색 경험을 어떻게 개선하게 되나요? 이런 혜택을 받으려면 구성을 더 추가해야 하나요? 이 블로그를 계속 읽어보시거나, 문서를 참조하셔서 바로 시작해 보세요.
분석과 토큰화를 예로 들어볼까요?
검색은 결국 분석이 관건입니다. 첫번째 분석은 검색 엔진 내에서 인덱스가 구축될 때 발생합니다. 색인하는 과정에서, 문서에 있는 텍스트가 토큰들로 변환됩니다. 그리고 나서 이 토큰들은 인덱스와 대조하여 하나의 용어로 체계화됩니다.
일단 인덱스가 구조화되면, 인덱스와 대조하여 각 검색 쿼리가 발생합니다. 들어오는 텍스트는 분석되고, 토큰으로 변환된 다음, 색인된 용어들과 대조하여 연결됩니다. 들어오는 쿼리 용어가 색인된 용어에 가까울수록, 검색 정확도는 더 높아집니다.
자체적인 검색을 고안하기 위해 Elasticsearch를 사용하고 계시다면, 선택하시는 언어를 심층적으로 가장 잘 처리하기 위해 사용자 정의 분석기를 한 개 또는 여러 개 구성해야 할 수도 있습니다. 토큰이 생성되는 방법과 용어가 구축되는 방법은 분석기 한 개 또는 한 세트를 구성한 방법과 직접적으로 관련이 있습니다. 통상적인 경우 효과적인 언어 분석기는 기본적인 인덱스 생성의 일부로 포함될 수 있지만, 한층 심도 깊은 구성에는 문자 필터, 토크나이저, 토큰 필터의 세부적인 조율이 필요합니다.
App Search는 이 복잡성을 없애고 API 기반의 최적화된 솔루션을 제공하여 애플리케이션에서 사용할 수 있도록 했습니다. 이것이 작동하는 방식을 예시해 드리기 위해, 현재 App Search Engine이 중국어 문자를 해석할 수 있는 방법을 살펴보겠습니다.
높은 일 돈
App Search Engine의 기본 설정은 Universal입니다. 기본 설정은 잘 구성되어 있으며, 대부분의 검색 사례에 이상적입니다. 그러나, 특정 언어가 지정되면, App Search Engine은 해당 언어에 최적화된 맞춤형 분석기를 사용하게 됩니다.
예를 들어, Universal 설정에서, 검색은 각 단어에 대한 독립적인 검색을 실시하는 대신 문서 내에서 서로 잘 맞는 단어에 대한 쿼리 작업을 할 정도의 똑똑한 능력을 갖추고 있습니다. hockey``stick에 대한 검색은 따로 따로 hockey를 찾은 다음 stick을 찾는 식이 아닙니다. 바로 hockey stick을 검색하게 됩니다.
이것이 영어, 또는 Universal 용어 연결에서는 유용한 반면, 다른 언어의 쿼리 작업에서는 어떻게 혼란을 일으킬 수 있는지 살펴보겠습니다.
이 한 쌍의 중국어 문자는 급여라는 뜻을 나타냅니다.
工资 : 급여
이것은 일과 돈이라는 두 개의 다른 문자로 이루어져 있습니다.
工 : 일
资 : 돈
언어와 무관한 분석을 진행하면, 토크나이저는 두 개의 문자를 두 개의 토큰으로 분리시킨 다음, 구문은 모른 채 문자 그대로 대조하여 연결을 찾게 됩니다.
중국의 검색자가 ‘급여'라는 쿼리를 실시했다고 생각해 보면, ‘급여' 대신에 ‘일 돈'에 대한 결과를 얻게 되리라는 것을 예상할 수 있습니다. 얼마나 혼란스러울 수 있을지 아셨죠!
영어에서는 검색이 ‘hockey stick'에서처럼 ‘일 돈’ 사이의 관계를 고려하는 결과를 제공하게 됩니다. 그러나, 중국어에서는, 이 두 개의 문자가 완전히 다른 개념을 나타냅니다.
적절한 중국어 분석기를 사용함으로써, 시스템은 工资이 빅그램(bigram), 즉, 한 쌍의 용어라는 것을 알아차립니다. 그리고 한 쌍으로 함께 토큰 하나를 생성하게 되고, 인덱스 내에서 ‘급여'에 대한 올바른 용어를 구축하게 됩니다. 工资 빅그램은 이제 ‘일 돈' 대신에 ‘급여'와 연관됩니다. 함께 합쳐져서, 토큰은 서로 이질적인 부분들 이상의 것을 의미합니다.
앱 검색 기록
이제 Engine을 만들면서 간단하게 App Search 내에서 특정한 언어를 구성할 수 있습니다.
App Search API를 통해 App Search Engine을 만들고 있다면, 예를 들어 POST가 다음과 같이 보이게 됩니다. 다음은 ‘panda'라고 하는 새로운 중국어(zh) 엔진을 만들게 됩니다.
curl -X POST 'https://host-xxxxxx.api.swiftype.com/api/as/v1/engines' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer private-xxxxxxxxxxxxxxxxxxxx' \
-d '{
"name": "panda",
"language": "zh"
}'
언어는 언어 코드와 일치합니다. 코드는 ISO 639-1 및 ISO 3166-1와 일치하는 IETF RFC 5646를 따릅니다.
GUI를 사용해 Engine을 만들려고 하는 경우, 언어 선택기는 온보딩 중에는 Engine 생성 내에서 그리고 대시보드 내에서 나타나게 됩니다.
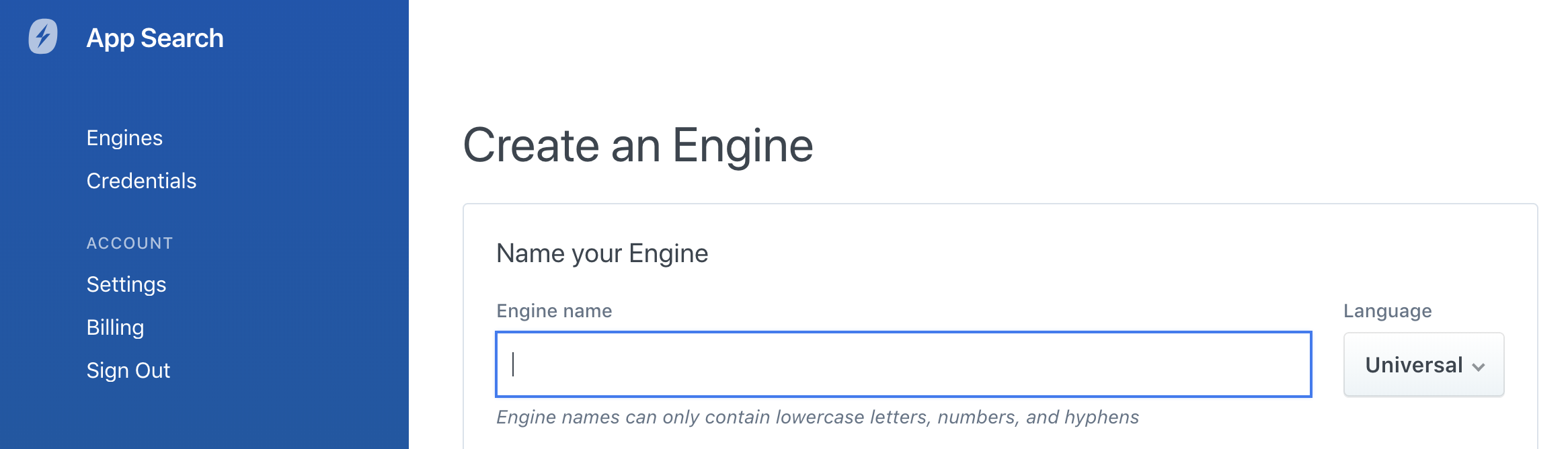
Engine 이름 아래 왼쪽 상단을 보면 Engine이 구성되는 언어를 알 수 있습니다. 언어가 보이지 않는다면, Universal 유형입니다.
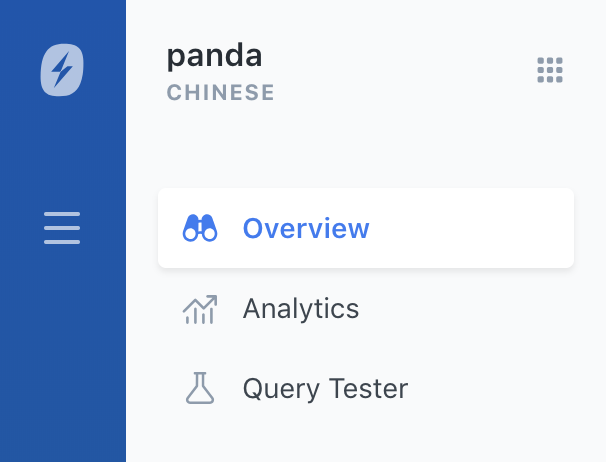
이제 특정 언어에 특화된 Engine이 구성되었으니, 특별한 단계를 또 거쳐야 할까요? 아닙니다! 이 엔진으로 데이터가 색인될 때마다 언어에 특화된 고급 분석이 이루어집니다. 그 후에는 해당 언어의 검색 쿼리가 색인 작업 중에 사용되는 언어에 최적화된 동일한 관련 분석기를 적용하게 됩니다.
요약
한 가지 값, 한 가지 데이터 유형, 한 가지 언어에만 초점을 맞출 수 있다고 해도, 검색은 아주 벅찬 기술적인 도전이 될 것입니다. 실제로, 검색은 훨씬 더 엄청나게 복잡합니다. 우리는 수많은 값과 수많은 데이터 유형과 방대한 범위의 언어들을 지원해야 합니다. 궁극적인 꿈은 극도로 정확하고, 언어와 데이터 유형에 무관한 검색입니다. 머신 러닝으로 컨텍스트가 예측된 것이죠.
그 때까지는, Elastic App Search가 애플리케이션에 방대한 검색 전문지식을 추가하는 효과적인 방법입니다. 잘 최적화된 13개의 언어를 간편하게 갖추게 되면, 직관적인 대시보드와 간단하고 역동적이며 잘 유지관리되는 API를 통해 고품질의 검색을 계속 이어갈 수 있습니다. 14일 체험판 사용 등록을 하셔서 API를 이리 저리 만져보시고 Elastic App Search가 적합한지 알아보세요.
업데이트**: Elastic Site Search 내에서 이제 다중 언어가 지원됩니다. 도메인을 입력하시고, 언어를 선택하신 다음, Site Search Crawler가 페이지 색인 작업을 하도록 하세요. 그 후, 스니펫을 설치하시고 고품질의 검색을 즐겨보세요.