Elastic Observability로 NVIDIA GPU 메트릭을 모니터링하는 방법
GPU(그래픽 처리 장치)는 PC 게임에만 사용되는 것이 아닙니다. 현재 GPU는 신경망을 훈련하고, 전산 유체 역학을 시뮬레이션하고, 비트코인을 채굴하고, 데이터 센터에서 워크로드를 처리하는 데 사용됩니다. 또한, 거의 모든 고성능 컴퓨팅 시스템의 핵심으로, 오늘날 데이터 센터의 GPU 성능을 모니터링하는 것은 CPU 성능을 모니터링하는 것만큼 중요합니다.
이점을 기억하면서 Elastic Observability를 NVIDIA의 GPU 모니터링 도구와 함께 사용하여 GPU 성능을 관찰하고 최적화하는 방법을 살펴보겠습니다.
종속성
NVIDIA GPU 메트릭을 설정하고 실행하려면 소스 코드(Go)에서 NVIDIA GPU 모니터링 도구를 빌드해야 합니다. 그리고 물론 NVIDIA GPU가 필요합니다. AMD 및 기타 GPU 유형은 다른 Linux 드라이버와 모니터링 도구를 사용하므로, 이는 별도의 게시물에서 다루겠습니다.
NVIDIA GPU는 Google Cloud, Amazon Web Services(AWS) 등 많은 클라우드 서비스 제공자가 제공하지만, 이 게시물에서는 Genesis Cloud에서 실행되는 인스턴스를 사용하겠습니다.
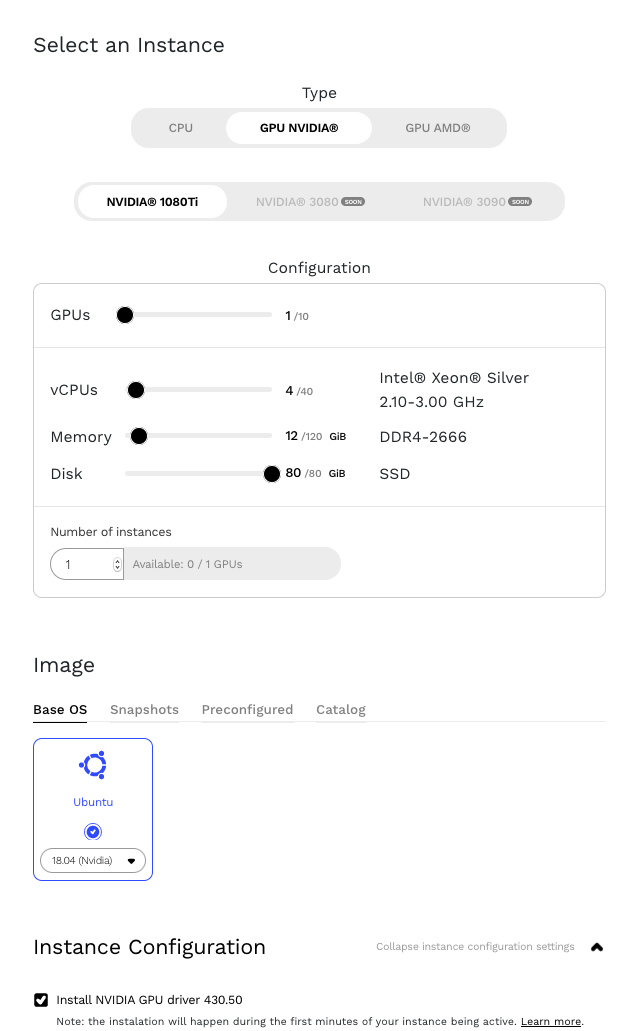
먼저, Ubuntu 18.04용 NVIDIA DCGM 시작 안내서의 설치 섹션에 따라 NVIDIA Datacenter Manager를 설치하겠습니다. 유의사항: 이 안내서를 따라 설치할 때 <architecture> 파라미터를 실제로 사용할 파라미터로 변경해야 합니다. uname 명령을 사용하면 아키텍처 정보를 확인할 수 있습니다.
uname -a
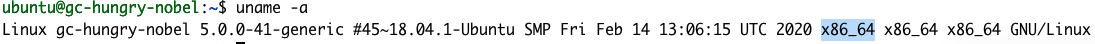
응답을 보면 X86_64가 사용하는 아키텍처라는 것을 알 수 있습니다. 따라서 시작 안내서의 1단계는 다음과 같습니다.
echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
2단계에 오타가 있습니다. $distribution의 뒤에 오는 > 기호를 제거해야 합니다.
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub
설치가 완료된 후 nvidia-smi 명령을 실행하면 GPU 세부 정보가 표시됩니다.
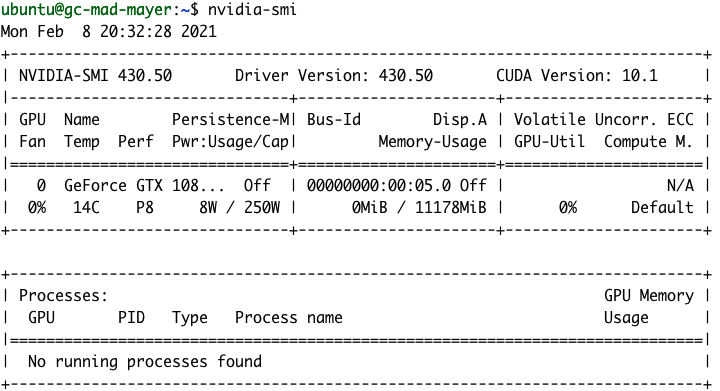
NVIDIA gpu-monitoring-tools
NVIDIA의 gpu-monitoring-tools를 빌드하려면 아래와 같이 Golang을 설치해야 합니다.
cd /tmp wget https://golang.org/dl/go1.15.7.linux-amd64.tar.gz sudo mv go1.15.7.linux-amd64.tar.gz /usr/local/ cd /usr/local/ sudo tar -zxf go1.15.7.linux-amd64.tar.gz sudo rm go1.15.7.linux-amd64.tar.gz
GitHub에 있는 NVIDIA gpu-monitoring-tools를 설치하면 NVIDIA 설정이 완료됩니다.
cd /tmp git clone https://github.com/NVIDIA/gpu-monitoring-tools.git cd gpu-monitoring-tools/ sudo env "PATH=$PATH:/usr/local/go/bin" make install
Metricbeat
이제 Metricbeat를 설치할 수 있습니다. elastic.co에서 Metricbeat 최신 버전을 확인한 후 아래 명령의 버전 번호를 수정합니다.
cd /tmp wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.10.2-amd64.deb sudo dpkg -i metricbeat-7.10.2-amd64.deb # 7.10.2가 버전 번호임
Elastic Cloud
이번에는 Elastic Stack을 실행하겠습니다. 새로 생성되는 GPU 모니터링 데이터를 저장할 장소가 필요합니다. 이를 위해 Elastic Cloud에 새로운 배포를 생성합니다. Elastic Cloud를 사용하고 있는 고객이 아니라면 14일 무료 체험판에 가입하시면 됩니다. 아니면 로컬로 자체 배포를 설정할 수도 있습니다.
그런 다음 Elastic Cloud에서 새로운 Elastic Observability 배포를 생성합니다.
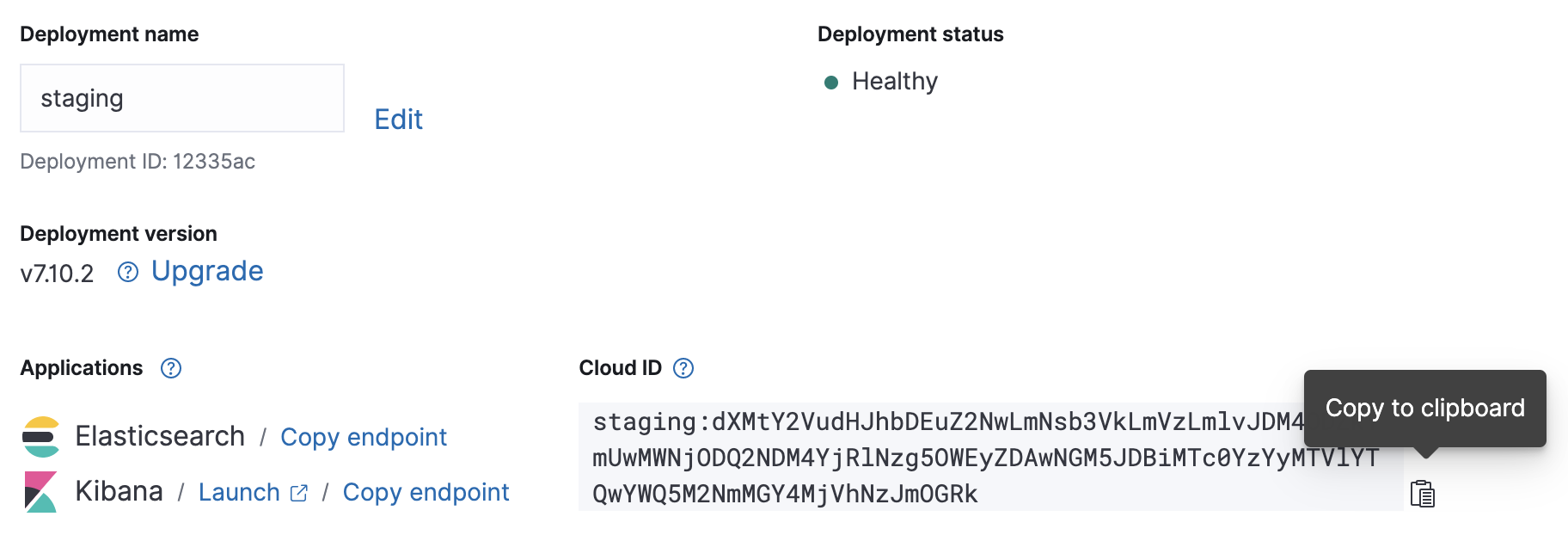
클라우드 배포가 실행되면 클라우드 ID와 인증 자격 증명을 적어둡니다. 이는 잠시 후에 Metricbeat를 구성할 때 필요합니다.
구성
Metricbeat 구성 파일은 /etc/metricbeat/metricbeat.yml에 있습니다. 원하는 편집기에서 이 구성 파일을 열고 적어둔 정보에 따라 cloud.id 및 cloud.auth 파라미터를 수정합니다.
위의 스크린샷을 사용한 Metricbeat 구성 변경 예시:
cloud.id: "staging:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvJDM4ODZkYmUwMWNjODQ2NDM4YjRlNzg5OWEyZDAwNGM5JDBiMTc0YzYyMTVlYTQwYWQ5M2NmMGY4MjVhNzJmOGRk" cloud.auth: "elastic:J7KYiDku2wP7DFr62zV4zL4y"
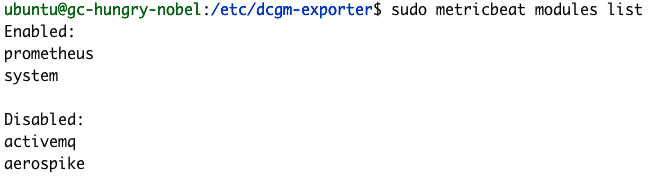
Metricbeat의 입력 구성은 모듈식입니다. NVIDIA gpu-monitoring-tools는 Prometheus를 통해 GPU 메트릭을 게시하므로 지금 미리 Prometheus Metricbeat 모듈을 활성화해 두겠습니다.
sudo metricbeat modules enable prometheus
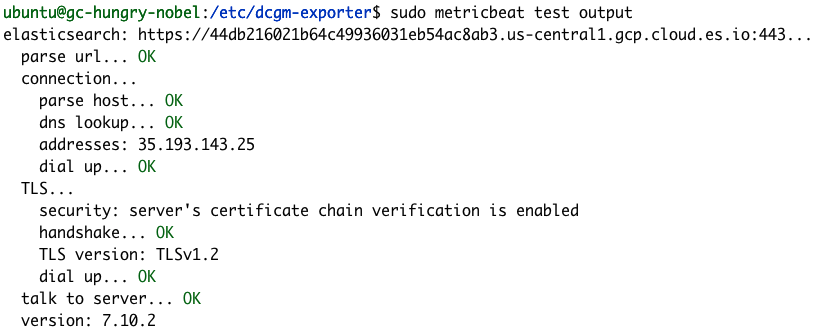
Metricbeat 테스트 및 모듈 명령을 사용하면 Metricbeat이 성공적으로 구성되었는지 확인할 수 있습니다.
sudo metricbeat test config

sudo metricbeat test output
sudo metricbeat modules list
위의 예시처럼 구성 테스트에 성공하지 못한 경우 Metricbeat 문제 해결 안내서를 참조하세요.
설정 명령을 실행하면 기본 대시보드가 로드되고 인덱스 매핑이 설정되면서 Metricbeat 구성이 완료됩니다. 설정 명령은 일반적으로 완료되는 데 몇 분 정도 걸립니다.
sudo metricbeat setup

메트릭 내보내기
이제 메트릭을 내보낼 차례입니다. NVIDIA의 dcgm-exporter를 시작하겠습니다.
dcgm-exporter --address localhost:9090 # 출력 INFO[0000] Starting dcgm-exporter INFO[0000] DCGM successfully initialized! INFO[0000] Not collecting DCP metrics: Error getting supported metrics: This request is serviced by a module of DCGM that is not currently loaded INFO[0000] Pipeline starting INFO[0000] Starting webserver
참고: DCP 경고는 무시해도 좋습니다.
dcgm-exporter 메트릭의 구성은 /etc/dcgm-exporter/default-counters.csv 파일에 정의되어 있으며, 기본적으로 정의되어 있는 메트릭은 38개입니다. 구성 가능한 값의 전체 목록은 DCGM Library API Reference Guide를 참조하세요.
다른 콘솔에서 Metricbeat를 시작합니다.
sudo metricbeat -e
이제 Kibana 인스턴스로 이동하여 ‘metricbeat-*’ 인덱스 패턴을 갱신합니다. Stack Management > Kibana> Index Patterns로 이동하여 목록에서 metricbeat-* 인덱스 패턴을 선택하면 됩니다. 그런 다음 Refresh field list를 클릭합니다.
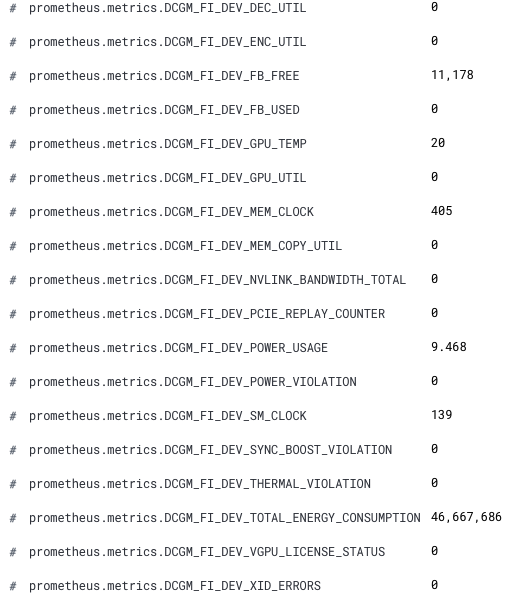
이제 Kibana에서 새로운 GPU 메트릭을 사용할 수 있습니다. 새로운 필드 이름은 prometheus.metrics.DCGM_로 시작합니다. 다음은 Discover에 표시된 새로운 필드 일부입니다.
축하합니다! 이제 Elastic Observability에서 GPU 메트릭을 분석할 준비가 되었습니다.
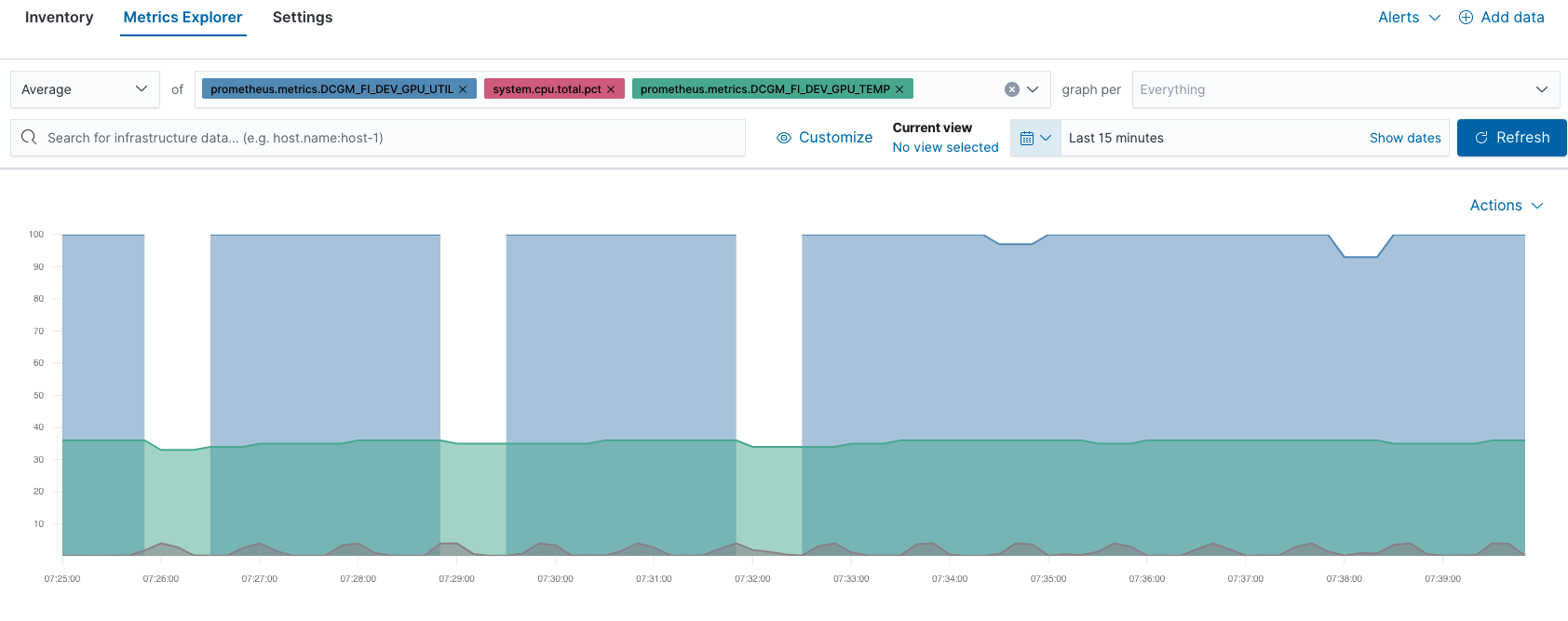
예를 들어 Metrics Explorer에서 GPU와 CPU 성능을 비교할 수 있습니다.
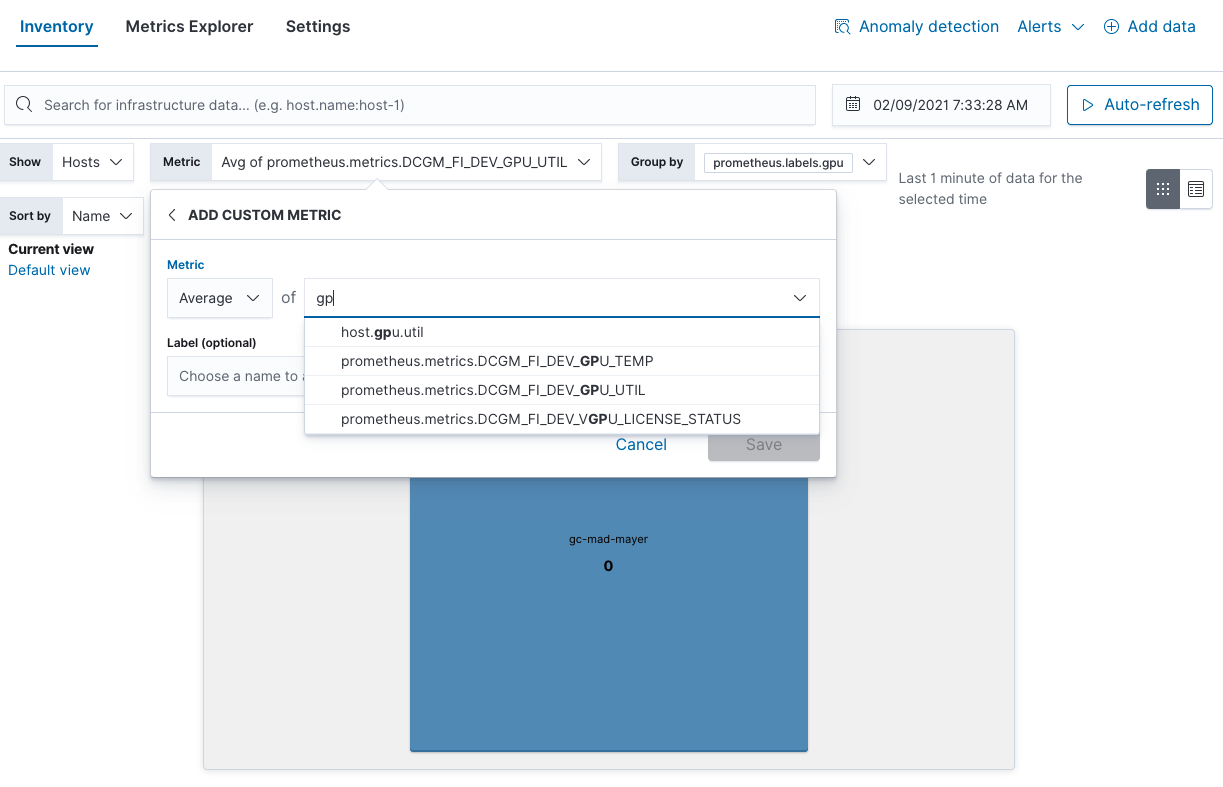
Inventory 보기에서는 GPU 사용량이 많은 핫스팟을 확인할 수 있습니다.
GPU 모니터링 시 고려 사항
이 게시물이 도움이 되셨기를 바랍니다. 위에서 설명해 드린 것은 몇 가지 모니터링 옵션에 불과하며 Elastic Observability를 사용하면 원하는 모든 작업을 할 수 있습니다. 다음은 몇 가지 다른 GPU 항목으로 NVIDIA별로 모니터링하면 유용합니다.
- GPU 온도: 핫스팟 확인
- GPU 전력 사용량: 예상 전력량보다 큰 경우, 하드웨어 문제일 수 있음
- 현재 클록 속도: 예상보다 느린 경우, 전력 캡핑(소비 전력 제한) 또는 하드웨어 문제일 수 있음
GPU 로드를 시뮬레이션해야 하는 경우가 생긴다면 dcgmproftester10 명령을 사용하면 됩니다.
dcgmproftester10 --no-dcgm-validation -t 1004 -d 30
Elastic 경보를 사용하여 NVIDIA 권장 사항을 자동화하고 머신 러닝으로 GPU 인프라에서 이상 징후를 탐색하면 모니터링을 더욱 강화할 뿐만 아니라 한 차원 발전시킬 수 있습니다. Elastic Cloud를 사용하고 있는 고객은 아니지만 이 블로그 게시물에 소개된 단계를 따라 해보고 싶다면 14일 무료 체험판에 가입하시면 됩니다.