Elasticsearch 캐싱 심층 분석: 한 번에 하나의 캐시로 쿼리 속도 향상
캐시는 빠른 데이터 검색을 위한 아주 좋은 방법입니다. Elasticsearch에서 다양한 캐시를 활용하여 데이터를 최대한 빨리 검색하는 방법에 관심이 있다면, 15분만 시간을 내셔서 이 포스팅을 끝까지 읽어보세요. 이 블로그에서는 초기 데이터 액세스 후 데이터를 더 빨리 검색할 수 있도록 지원하는 Elasticsearch의 다양한 캐싱 기능에 대해 설명합니다. Elasticsearch는 다양한 캐시를 대단히 많이 사용하지만, 이 포스팅에서는 다음 캐시에 대해 중점적으로 살펴보겠습니다.
- 페이지 캐시(파일 시스템 캐시라고도 함)
- 샤드 레벨 요청 캐시
- 쿼리 캐시
이러한 각 캐시의 역할 및 작동 방법과 함께, 각 사용 사례에 가장 적합한 캐시가 무엇인지에 대해 알아봅니다. 또한 캐싱을 제어할 수 있는 경우 및 캐싱을 제대로 수행하기 위해 다른 구성 요소를 신뢰해야 하는 경우도 살펴보겠습니다.
아울러 페이지 캐시가 데이터 만료에 대처하는 방법도 보시게 됩니다. 부실 데이터를 반환하는 캐시는 절대 맞닥뜨리고 싶지 않으실 것입니다. 캐시는 데이터 수명 주기에 바인딩되어야 하며 캐시가 각 데이터 수명 주기별로 어떻게 작동하는지 살펴보겠습니다.
그리고 이 포스팅의 활용 가능성에 대해 조언을 드리자면, Elasticsearch를 직접 실행하거나 Elastic Cloud를 사용하고 있는 경우에는 이러한 캐시를 즉시 활용하게 될 것입니다. 그럼 시작해 보겠습니다.
페이지 캐시
운영 체제 레벨에 첫 번째 캐시가 있습니다. 이 섹션은 주로 Linux 구현에 대한 내용이지만, 다른 운영 체제에도 이와 유사한 기능이 있습니다.
페이지 캐시의 기본 개념은 디스크에서 데이터를 읽은 후 사용 가능한 메모리에 데이터를 넣는 것으로, 다음 읽기는 메모리에서 반환되고 데이터를 가져오는 데 디스크 탐색이 필요 없습니다. 이 모든 것은 동일한 시스템 호출을 실행하는 애플리케이션에 대해 완전히 투명하지만, 운영 체제는 디스크에서 읽는 대신 페이지 캐시를 사용할 수 있습니다.
이 다이어그램을 살펴보면 애플리케이션이 디스크에서 데이터를 읽기 위해 시스템 호출을 실행하고, 커널/운영 체제가 디스크로 이동하여 데이터를 페이지 캐시에, 그리고 메모리에 넣습니다. 두 번째 읽기는 커널에 의해 운영 체제 메모리 내의 페이지 캐시로 리디렉션될 수 있으므로 훨씬 더 빠를 것입니다.
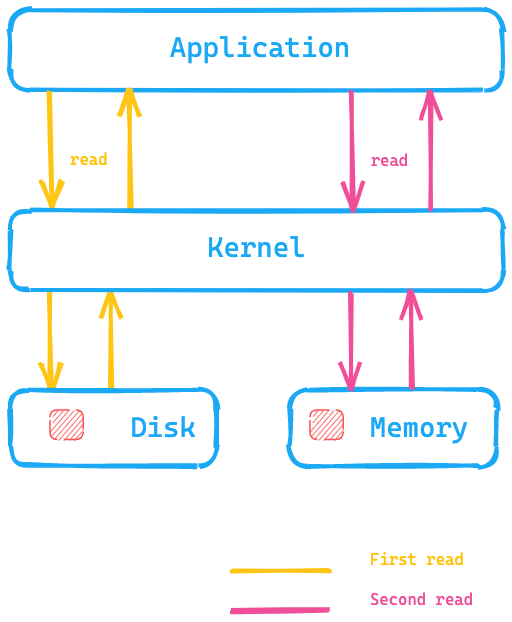
Elasticsearch에서 이것은 무엇을 의미하나요? 디스크에 있는 데이터에 액세스하는 것에 비해, 페이지 캐시는 훨씬 더 빠르게 데이터에 액세스할 수 있습니다. 이것은 Elasticsearch 메모리에 대한 권장 사항이 일반적으로 사용 가능한 총 메모리의 절반 이하인 이유 중 하나입니다. 나머지 절반을 페이지 캐시에 사용할 수 있기 때문입니다. 또한 메모리가 낭비되지 않고 페이지 캐시에 재사용된다는 뜻이기도 합니다.
캐시에서 데이터가 어떻게 만료되나요? 데이터 자체가 변경되면 페이지 캐시는 해당 데이터를 더티(dirty, 변경됨)로 표시하고 페이지 캐시에서 해제됩니다. Elasticsearch 및 Lucene이 포함된 세그먼트는 한 번만 작성되므로 이 메커니즘은 데이터 저장 방식에 매우 적합합니다. 세그먼트는 초기 쓰기 후 읽기 전용이므로 데이터를 변경하면 병합되거나 새 데이터가 추가될 수 있습니다. 이 경우 새 디스크 액세스가 필요합니다. 다른 가능성은 메모리가 가득 차게 되는 것입니다. 이 경우, 캐시는 커널 설명서에 명시된 LRU와 유사하게 동작합니다.
페이지 캐시 테스트
페이지 캐시의 기능을 확인하고 싶다면, hyperfine을 사용하여 확인할 수 있습니다. hyperfine은 CLI 벤치마킹 도구입니다. dd를 통해 10MB 크기의 파일을 만들어 봅시다.
dd if=/dev/urandom of=test1 bs=1M count=10
macOS를 사용하여 위의 내용을 실행하려면, gdd를 대신 사용할 수 있습니다.
그리고 brew를 통해 coreutils가 설치되었는지 확인합니다.
# Linux의 경우 hyperfine --warmup 5 'cat test1 > /dev/null' \ --prepare 'sudo sync; sudo echo 3 > /proc/sys/vm/drop_caches'
# osx의 경우 hyperfine --warmup 5 'cat test1 > /dev/null' --prepare 'sudo purge' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 38.1 ms ± 6.4 ms [User: 1.4 ms, System: 17.5 ms] Range (min … max): 30.4 ms … 50.5 ms 10 runs hyperfine --warmup 5 'cat test1 > /dev/null' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 3.8 ms ± 0.6 ms [User: 0.7 ms, System: 2.8 ms] Range (min … max): 2.9 ms … 7.0 ms 418 runs
따라서 페이지 캐시를 지우지 않고 동일한 cat 명령을 실행하는 로컬 macOS 인스턴스에서 디스크 액세스를 건너뛸 수 있으므로 약 10배 더 빠릅니다. Elasticsearch 데이터에 대해 분명히 이러한 액세스 패턴을 원하시겠죠!
더 깊이 알아보기
Lucene 인덱스 읽기를 담당하는 클래스는 HybridDirectory클래스입니다. Lucene 인덱스 내의 파일 확장명에 기초하여, Java NIO를 사용하여 메모리 매핑을 사용할지 또는 일반적인 파일 액세스를 사용할지 결정할 수 있습니다.
또한 일부 애플리케이션은 자체 액세스 패턴을 더 잘 알고 있으며 매우 구체적이고 최적화된 캐시를 갖추고 있습니다. 그리고 페이지 캐시는 이러한 접근 패턴에 역행할 수 있습니다. 필요한 경우, 파일을 열 때 O_DIRECT를 사용하여 모든 애플리케이션이 페이지 캐시를 무시할 수 있습니다. 이 포스팅의 마지막 부분에서 이 문제로 돌아갈 것입니다.
캐시 적중률을 확인하려면 perf-tools의 일부인 cachestat를 사용할 수 있습니다
이제 Elasticsearch에 대해 마지막으로 한 가지만 더 얘기하겠습니다. 인덱스 설정을 통해 데이터를 페이지 캐시에 사전 로드하도록 Elasticsearch를 구성할 수 있습니다. 페이지 캐시가 끊임없이 휴지통으로 이동되지 않도록 이 설정을 전문가 설정으로 간주하고 이 설정에 주의하세요.
요약
페이지 캐시는 운영 체제의 기본 메모리에 전체 인덱스 데이터 구조를 로드하여 임의 검색을 더 빨리 실행할 수 있도록 지원합니다. 세분화는 더 이상 존재하지 않으며 데이터의 액세스 패턴만을 기반으로 합니다. 운영 체제가 제거를 처리합니다.
다음 단계의 캐시로 넘어가겠습니다.
샤드 레벨 요청 캐시
이 캐시는 집계로만 구성된 검색 응답을 캐싱하여 Kibana의 속도를 높이는 데 많은 도움이 됩니다. 이 캐시로 해결된 문제를 시각화하기 위해 여러 인덱스에서 가져온 데이터로 집계의 응답을 오버레이해 보겠습니다.
사무실의 Kibana 대시보드는 일반적으로 여러 인덱스의 데이터를 표시하며 간단히 지난 7일과 같은 시간 범위를 지정할 수 있습니다. 쿼리된 인덱스나 샤드의 수는 상관 없습니다. 따라서 시간 기반 인덱스에 데이터 스트림을 사용할 경우, 다음과 같은 5가지 인덱스를 시각화할 수 있습니다.
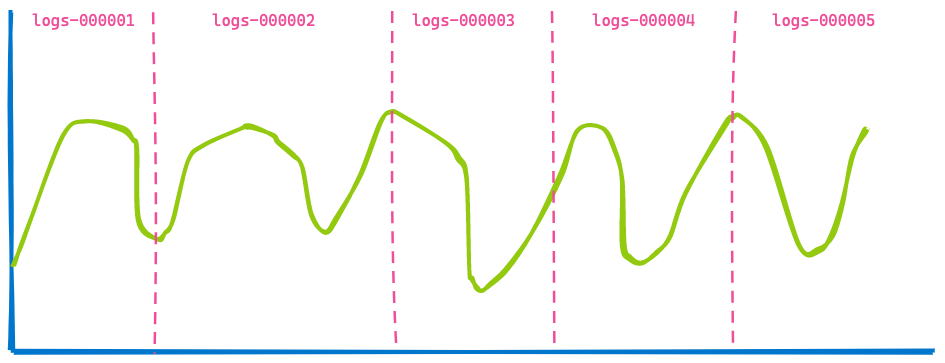
이제 앞으로 3시간을 건너뛰어, 동일한 대시보드를 표시해 보겠습니다.
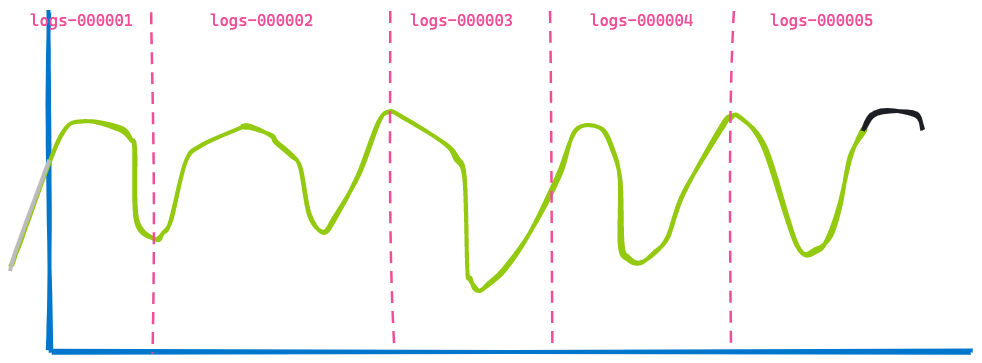
두 번째 시각화는 첫 번째 시각화와 매우 유사합니다. 일부 데이터는 만료되어 더 이상 표시되지 않습니다(파란색 선 왼쪽). 일부 데이터는 끝에 추가되어 검은색 선으로 표시되어 있습니다. 변하지 않은 것을 찾아내실 수 있나요? 인덱스 logs-000002, logs-000003 및 logs-000004에서 반환된 데이터입니다.
이 데이터가 페이지 캐시에 있었더라도, 결과뿐 아니라 검색과 집계를 실행해야 했을 것입니다. 그러니까, 이 이중 작업을 할 필요가 없습니다. 이 작업을 수행하기 위해 Elasticsearch에 최적화 한 가지가 더 추가되었습니다. 쿼리를 다시 작성할 수 있는 기능입니다. 로그 인덱스 logs-000002, logs-000003 및 logs-000004에 대한 타임스탬프 범위를 지정하는 대신, 해당 인덱스 내의 모든 문서가 타임스탬프에 관해서는 일치할 때 내부적으로 match_all 쿼리에 다시 쓸 수 있습니다(물론, 다른 필터는 계속 적용됩니다). 이 다시 쓰기를 사용하면, 두 요청이 이제 이 세 인덱스에서 결국 정확히 동일한 요청이 되므로 캐시할 수 있습니다.
이것은 샤드 레벨 요청 캐시가 되었습니다. 부실 데이터를 반환하지 않도록 데이터가 변경되지 않은 한, 요청의 전체 응답을 캐싱하여 검색을 실행할 필요가 없으며 기본적으로 응답을 즉시 반환할 수 있습니다.
더 깊이 알아보기
캐싱을 담당하는 구성 요소는 IndicesRequestCache 클래스입니다. 이 메서드는 쿼리 단계를 실행할 때 SearchService 내에서 사용됩니다. 또한 쿼리가 캐시에 적합한지 여부를 추가로 확인합니다. 예를 들어, 프로파일링 중인 쿼리는 결과가 왜곡되지 않도록 캐시되지 않습니다.
이 캐시는 기본적으로 활성화되어 있고, 총 힙의 최대 1%를 차지할 수 있으며, 필요한 경우 요청별로 구성할 수도 있습니다. 기본적으로 이 캐시는 검색 결과를 반환하지 않는 검색 요청에 대해 활성화됩니다. 바로 Kibana 시각화 요청이 그렇죠! 그러나 요청 매개 변수를 통해 캐시를 활성화하여 검색 결과가 반환되는 경우에도 이 캐시를 사용할 수 있습니다.
다음을 통해 이 캐시 사용에 대한 통계를 검색할 수 있습니다.
GET /_nodes/stats/indices/request_cache?human
요약
샤드 레벨 요청 캐시는 검색 요청에 대한 전체 응답을 기억하고, 디스크나 페이지 캐시를 건드리지 않고 동일한 쿼리가 다시 들어오는 경우 해당 응답을 반환합니다. 이름에서 알 수 있듯이, 이 데이터 구조는 데이터를 포함하는 샤드에 묶여 있으며 부실 데이터도 반환하지 않습니다.
쿼리 캐시
이 포스팅에서 살펴볼 마지막 캐시는 쿼리 캐시입니다. 다시 말씀드리지만, 이 캐시의 작동 방식은 다른 캐시와는 다소 다릅니다. 페이지 캐시는 쿼리에서 실제로 읽은 이 데이터의 양에 관계없이 데이터를 캐시합니다. 샤드 레벨 쿼리 캐시는 유사한 쿼리를 사용할 때 데이터를 캐시합니다. 쿼리 캐시는 더욱 세분화되어 서로 다른 쿼리 간에 재사용되는 데이터를 캐시할 수 있습니다.
어떻게 작동하는지 한 번 볼까요? 로그를 검색한다고 생각해 봅시다. 세 명의 다른 사용자가 이번 달의 데이터를 검색하고 있을 수 있습니다. 그러나 각 사용자는 다음과 같이 다른 검색어를 사용합니다.
- 사용자1은 "failure"를 검색했습니다.
- 사용자2는 "Exception"을 검색했습니다.
- 사용자3은 "pcre2_get_error_message"를 검색했습니다.
모든 검색은 서로 다른 결과를 반환하지만 동일한 시간대 내에 있습니다. 여기서 쿼리 캐시가 제공됩니다. 쿼리의 해당 부분만 캐시할 수 있습니다. 기본 아이디어는 디스크에 있는 정보를 캐시하고 해당 제품에서만 검색하는 것입니다. 쿼리는 다음과 같이 보일 수 있습니다.
GET logs-*/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "pcre2_get_error_message"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
}
]
}
}
}
모든 쿼리에 대해 filter 부분은 동일하게 유지됩니다. 이 보기는 역 인덱스에서 데이터가 어떻게 표시되는지를 매우 단순화하여 보여줍니다. 각 타임스탬프는 문서 ID에 매핑됩니다.
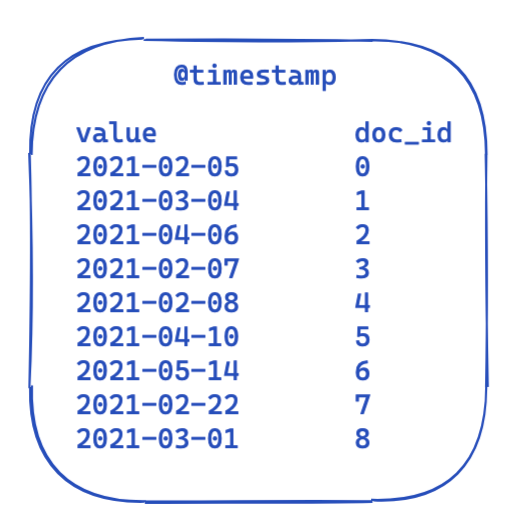
그러면 쿼리 전체에서 최적화하고 재사용할 수 있는 방법은 무엇일까요? 여기서 비트 세트(비트 배열이라고도 함)가 작동하기 시작합니다. 비트 세트는 기본적으로 각 비트가 문서를 나타내는 배열입니다. 한 달에 걸쳐 특정 @timestamp 필터에 대한 전용 비트 세트를 생성할 수 있습니다. 0은 문서가 이 범위를 벗어났다는 것을 의미하고, 1은 문서가 이 범위 내에 있다는 것을 의미합니다. 결과 비트 세트는 다음과 같이 보일 수 있습니다.
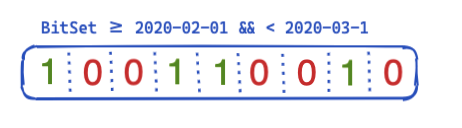
세그먼트별로 이 비트 세트를 생성한 후에는(병합 후 또는 새 세그먼트가 생성될 때마다 다시 생성해야 함), 다음 쿼리는 필터를 실행하기 전에 4개의 문서를 제외하기 위해 디스크 액세스를 수행할 필요가 없습니다. 비트 세트에는 몇 가지 흥미로운 속성이 있습니다. 우선, 서로 결합될 수 있습니다. 두 개의 필터와 두 개의 비트 세트가 있는 경우, 두 비트가 모두 설정된 문서를 쉽게 찾거나 OR 쿼리를 함께 병합할 수 있습니다. 비트 세트의 또 다른 흥미로운 측면은 압축입니다. 기본적으로 문서당 하나의 비트가 필요합니다. 그러나 고정 비트 세트가 아니라 Roaring bitmap과 같은 다른 구현을 사용하면 메모리 요구 사항을 줄일 수 있습니다.
그렇다면, Elasticsearch와 Lucene에서는 이것이 어떻게 구현될까요? 한 번 살펴볼까요?
더 깊이 알아보기
Elasticsearch는 IndicesQueryCache 클래스 기능을 갖추고 있습니다. 이 클래스는 IndicesService의 수명 주기에 바인딩되어 있습니다. 즉, 인덱스당 기능이 아니라 노드당 기능입니다. 캐시 자체에서 Java 힙을 사용하므로 말이 됩니다. 쿼리 캐시에 대한 인덱스는 두 가지 구성 옵션을 차지합니다.
indices.queries.cache.count: 총 캐시 항목 수, 기본값은 10,000개입니다.indices.queries.cache.size: 이 캐시에 사용된 Java 힙의 백분율, 기본값은 10%입니다.
IndicesQueryCache 생성자에서 새로운 ElasticsearchLRUQueryCache가 설정됩니다. 이 캐시는 Lucene LRUQueryCache 클래스에서 확장됩니다. 해당 클래스에는 다음과 같은 생성자가 있습니다.
public LRUQueryCache(int maxSize, long maxRamBytesUsed) {
this(maxSize, maxRamBytesUsed, new MinSegmentSizePredicate(10000, .03f), 250);
}
MinSegmentSizePredicate는 10,000개 이상의 문서가 있는 세그먼트만 캐싱할 수 있으며 이 샤드의 전체 문서의 3% 이상을 차지하도록 보장합니다.
하지만, 여기서부터 일이 조금 더 복잡합니다. 데이터가 JVM 힙에 있더라도, 가장 일반적인 쿼리 부분만 추적하여 해당 캐시에만 넣는 다른 메커니즘이 있습니다. 그러나 이 추적은 샤드 레벨에서 수행됩니다. FrequencyTrackingRingBuffer를 사용하는 UsageTrackingQueryCachingPolicy 클래스가 있습니다(고정 크기 정수 배열을 사용하여 구현). 또한 이 캐싱 정책에는 shouldNeverCache 메서드에 추가 규칙이 있습니다. 이 방법은 기간 쿼리, match all/no 문서 쿼리 또는 빈 쿼리와 같은 특정 쿼리의 캐싱을 금지합니다. 이러한 쿼리는 캐시 없이 충분히 빠르기 때문입니다. 또한 한 번의 호출로 인해 캐시가 채워지지 않도록 캐싱에 적합한 최소 빈도에 대한 조건이 있습니다. 다음을 통해 사용, 캐시 적중률 및 기타 정보를 추적할 수 있습니다.
GET /_nodes/stats/indices/query_cache?human
요약
쿼리 캐시는 다음 세분화된 레벨에 도달하며 쿼리 전체에서 다시 사용할 수 있습니다! 내장된 휴리스틱을 통해 여러 번 사용되는 필터만 캐싱하고 필터를 기반으로 캐싱 가치가 있는지 또는 기존 쿼리 방법이 힙 메모리 낭비를 방지할 수 있을 만큼 빠른지 여부를 결정합니다. 이러한 비트 세트의 수명 주기는 부실 데이터가 반환되지 않도록 세그먼트의 수명 주기에 바인딩되어 있습니다. 새 세그먼트가 사용 중이면, 새 비트 세트를 생성해야 합니다.
캐시가 작업 속도를 높일 수 있는 유일한 가능성인가요?
경우에 따라 다릅니다. (이미 이 답변이 언제쯤엔가 이 블로그에 올라와 있어야 한다고 생각하셨죠?) io_uring 같은 리눅스 커널의 최근 개발은 상당히 유망합니다. 이것은 Linux 5.1부터 제공되는 완료 큐를 사용하여 Linux에서 비동기 I/O를 수행하는 새로운 방법입니다. io_uring은 여전히 상당한 개발 중에 있습니다. 그러나 Java 세계에서는 io_uring을 netty와 같이 사용하는 시도가 처음 있습니다. 간단한 애플리케이션을 위한 성능 테스트는 매우 훌륭합니다. 실제 성능 수치도 크게 달라질 것으로 예상하지만, 조금만 더 기다려봐야 할 것 같습니다. 언젠가 JDK 내에서도 이를 위한 지원이 가능해지기를 기대해 봅니다. Project Loom의 일부로 io_uring을 지원할 계획이 있으며, 이를 통해 io_uring을 JVM으로 가져올 수도 있습니다. madvise()를 통해 Linux 커널에 대한 액세스 패턴의 힌트를 제공할 수 있는 것과 같은 더 많은 최적화 또한 JVM에서 아직 노출되지 않았습니다. 이 힌트는 커널이 다음 읽기를 예상할 때 필요한 것보다 더 많은 데이터를 읽으려고 하는 read-ahead 문제를 방지하며, 랜덤 액세스가 필요할 때는 쓸모가 없습니다.
그게 전부가 아닙니다! Lucene 개발자들은 항상 어떤 시스템에서도 최대한 활용하기 위해 분주합니다. Foreign Memory API를 사용하여 Lucene MMapDirectory를 다시 쓴 초안이 있으며, 이것은 Java 16에서 미리보기 기능이 될 수도 있습니다. 그러나 이는 성능상의 이유로 이루어진 것이 아니라 현재의 MMap 구현으로 특정한 한계를 극복하기 위한 것이었습니다.
Lucene의 또 다른 최근 변화는 FileChannel 클래스에서 direct i/o(O_DIRECT)를 사용하여 네이티브 확장을 제거하는 것이었습니다. 즉, 데이터를 쓰는 것이 페이지 캐시를 휴지통으로 이동시키지 않게 된다는 뜻입니다. 이것은 Lucene 9 기능이 됩니다.
때로는 더 이상 캐시에 대해 생각조차 할 필요가 없도록 작업 속도를 높여 운영 복잡성을 줄일 수도 있습니다. 최근 여러 차례 date_histogram 집계 속도가 크게 향상되었습니다. 시간을 내셔서 길지만 여러 가지 새로운 생각을 보여줄 그 블로그 포스팅을 읽어보시기 바랍니다.
(캐싱이 없는) 엄청난 개선의 또 다른 매우 좋은 예는 Elasticsearch 7.0에서 block-max WAND의 구현이었습니다. Adrien Grand의 이 블로그 포스팅에서 그에 대한 모든 것을 읽어보실 수 있습니다.
캐싱 심층 분석 마무리
다양한 캐시에서 즐거운 시간을 보내셨기를 바랍니다. 이제 어느 캐시가 언제 시작될지 파악하셨겠죠. 또한 캐시 모니터링은 캐시가 적절한지 또는 지속적인 추가 및 만료로 인해 계속 폐기되는지 여부를 파악하는 데 특히 유용할 수 있습니다. Elastic 클러스터의 모니터링을 사용하도록 설정하면, 노드의 고급 탭과 인덱스별로 쿼리 캐시 및 요청 캐시의 메모리 사용량을 확인할 수 있습니다.
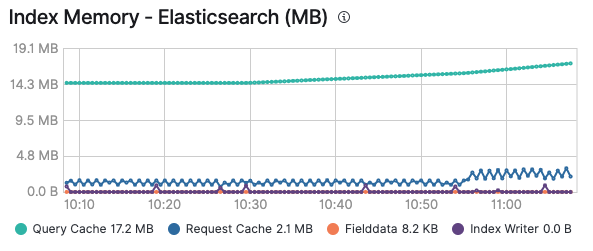
Elastic Stack 뿐 아니라 모든 기존 솔루션은 이러한 캐시를 사용하여 쿼리를 실행하고 가능한 한 빨리 데이터를 전송할 수 있도록 합니다. 클릭 한 번으로 Elastic Cloud에서 로깅 및 모니터링을 사용하도록 설정하고 추가 비용 없이 모든 클러스터를 모니터링할 수 있습니다. 직접 사용해 보세요!