상위-하위 프로세스 관계를 기반으로 비정상 패턴 발견
바이러스 백신 및 머신 러닝 기반 맬웨어 탐지에서 파일 기반 공격 탐지의 효율성이 높아짐에 따라 공격자는 최신 보안 소프트웨어를 우회하기 위해 “자급자족(LotL)” 기법으로 전환했습니다. 여기에는 운영 체제에 사전 설치되어 있거나 관리자가 IT 관리 작업 자동화, 정기적으로 스크립트 실행, 원격 시스템에서 코드 실행 등의 작업을 수행하기 위해 가져오는 시스템 도구를 실행하는 것이 포함됩니다. powershell.exe, wmic.exe 또는 schtasks.exe와 같이 신뢰할 수 있는 OS 도구를 사용하는 공격자는 식별하기 어려울 수 있습니다. 이러한 바이너리는 본질적으로 무해하며 대부분의 환경에서 흔히 사용되므로 공격자는 반복적으로 실행되는 작업의 노이즈에 섞여들어가 대부분의 1차 방어를 간단하게 우회할 수 있습니다. 이러한 사후 침해 패턴을 탐지하려면 명확한 시작점 없이 수백만 개의 이벤트를 검토해야 합니다.
이에 대응하여 보안 연구원들은 의심스러운 상위-하위 프로세스 체인을 대상으로 탐지기를 만들기 시작했습니다. MITRE ATT&CK™를 플레이북으로 사용하면 연구원들이 특정 상위 프로세스가 특정 명령줄 인수를 사용해 하위 프로세스를 시작하는 경우 이를 알려주는 탐지 로직을 작성할 수 있습니다. MS Office 프로세스가 base64 인코딩 인수로 powershell.exe를 생성하는 경우 알려주는 것을 예로 들 수 있습니다. 그러나 이는 도메인 전문 지식과 노이즈 탐지기를 튜닝할 수 있는 명시적 피드백 루프가 필요한 시간 소모적인 프로세스입니다.
보안 담당자들은 공격을 시뮬레이션하고 탐지기 성능을 평가하기 위해 몇 가지 레드/블루 프레임워크를 오픈소스화했지만, 탐지기의 성능과 관계없이 이 로직은 오직 하나의 특정 공격만 탐지할 수 있습니다. 탐지기를 일반화하고 새로운 공격을 탐지하는 데 실패함에 따라 머신 러닝에 기회가 찾아왔습니다.
그래프로 생각하기
비정상적 상위-하위 프로세스의 탐지에 대해 고민하기 시작했을 때 저는 이를 그래프 문제로 바꾸는 아이디어를 바로 떠올렸습니다. 어쨌든 프로세스 실행은 특정 호스트에 대한 그래프로 표현할 수 있으니까요. 그래프의 노드는 프로세스 ID(PIP)로 구분된 개별 프로세스이며, 노드를 연결하는 엣지는 process_creation 이벤트입니다. 각 엣지에는 타임스탬프, 명령줄 인수 및 사용자와 같이 이벤트에서 파생된 중요한 메타데이터가 포함됩니다.
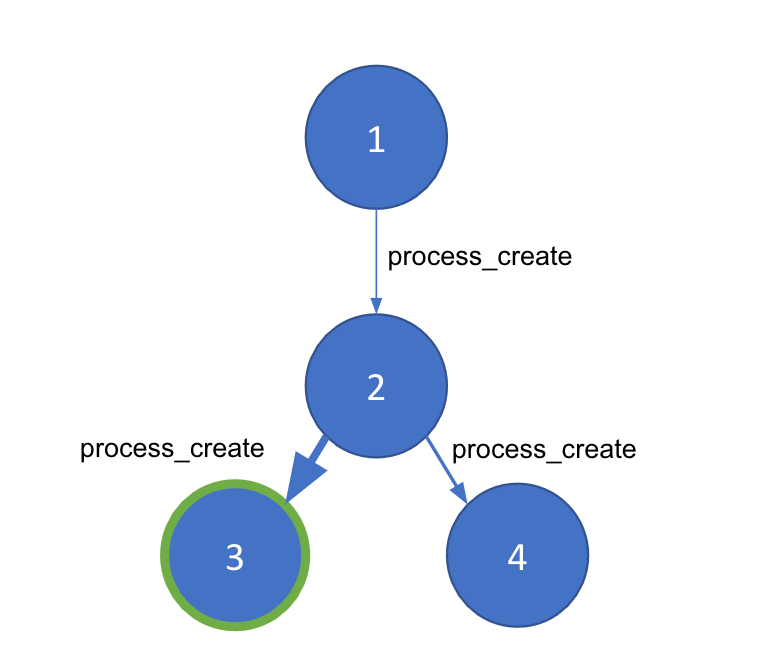
이렇게 호스트 머신의 프로세스 이벤트를 그래프로 표현했습니다. 그러나 “자급자족(LotL)” 공격은 상시 실행되는 동일한 시스템 수준 프로세스에서 발생할 수 있습니다. 따라서 주어진 그래프 내에서 좋은 프로세스 체인과 나쁜 프로세스 체인을 구분하는 방법이 필요합니다. 커뮤니티 탐지는 노드 간 엣지 밀도에 따라 대규모 그래프를 더 작은 “커뮤니티”로 분할하는 기법입니다. 이 기법을 사용하려면 커뮤니티 탐지가 올바르게 작동하고 그래프에서 비정상적인 부분을 식별할 수 있도록 노드 간 가중치를 생성하는 방법이 필요합니다. 이를 위해 머신 러닝을 사용하도록 하겠습니다.
머신 러닝
엣지 가중치 모델을 구축하기 위해 지도 학습을 사용합니다. 이는 모델에 레이블이 지정된 데이터를 공급해야 하는 머신 러닝 접근 방식입니다. 다행히 위에서 언급한 오픈 소스 레드/블루 프레임워크를 사용하여 일부 훈련 데이터를 생성할 수 있습니다. 다음은 훈련 코퍼스에 사용되는 몇 가지 오픈 소스 레드/블루 프레임워크입니다.
레드 팀 프레임워크
- Atomic Red Team(Red Canary)
- Red Team Automation(Endgame/Elastic)
- Caldera Adversary Emulation(MITRE)
- Metta(Uber)
블루 팀 프레임워크
- Atomic Blue(Endgame/Elastic)
- Cyber AnalyticsRepository (MITRE)
- MSFT ATP Queries(Microsoft)
데이터 수집 및 정규화

이벤트 데이터를 수집한 후에는 수치 표현으로 변환해야 합니다(그림 2). 이 수치 표현을 통해 모델은 그저 특징만 학습하는 수준을 벗어나 공격 범위 내에서 상위-하위 관계에 대한 보다 광범위한 세부 정보를 학습할 수 있습니다.
먼저 프로세스 이름 및 명령줄 인수에 대해 기능 엔지니어링(그림 3)을 수행합니다. TF-IDF 벡터화는 데이터 세트 전체에 걸쳐 이벤트에 대한 특정 단어의 통계적 중요성을 포착합니다. 타임스탬프를 정수로 변환하면 상위 프로세스 시작 시간과 하위 프로세스 시작 시간 사이의 델타를 확인할 수 있습니다. 다른 기능은 기본적으로 이진입니다(예: 1 또는 0, 예 또는 아니요). 다음은 이러한 기능 유형의 좋은 예입니다.
- 프로세스에 서명이 되었나요?
- 서명자를 신뢰하나요?
- 프로세스가 승격되었나요?

데이터 세트가 변환된 후에는 이를 사용하여 지도 학습 모델을 훈련합니다(그림 4). 이 모델은 특정 프로세스 생성 이벤트에 대해 0(양성)과 1(비정상) 사이의 “비정상 점수”를 제공합니다. 이 비정상 점수를 그래프에서 엣지 가중치로 사용할 수 있습니다!
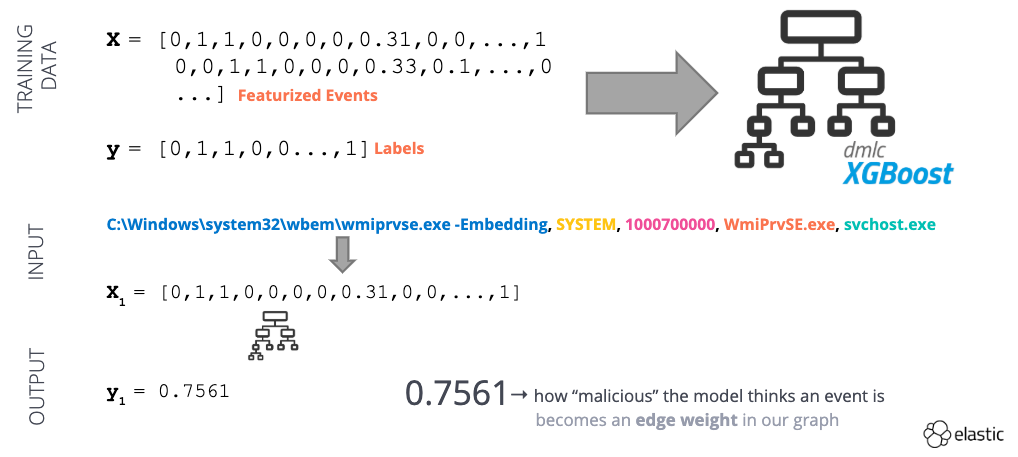
그림 4 – 지도 머신 러닝 워크플로우 예제
출현(prevalence) 서비스


그림 5 – 출현(prevalence) 엔진에서 사용하는 조건부 확률
머신 러닝 모델 덕분에 이제 가중치 그래프가 완성되었습니다. 미션이 완수되었죠. 우리가 훈련한 모델은 좋은 프로세스 체인과 나쁜 프로세스 체인에 대한 전반적인 이해를 기반으로 특정 상위-하위 체인에 대해 "좋음/나쁨" 결정을 내리는 데 큰 역할을 합니다. 그러나 모든 고객 환경은 다릅니다. 지금까지 관찰하지 못한 프로세스가 있을 수 있고 모든 작업에 PowerShell을 사용하는 시스템 관리자가 있을 수도 있습니다.
기본적으로 이 모델만 사용한다면 오탐이 폭주하고 분석가가 검토해야 할 데이터의 양만 늘어날 수 있습니다. 이러한 잠재적 문제를 상쇄하기 위해 Elastic에서는 특정 상위-하위 프로세스 체인이 해당 환경에서 얼마나 일반적인지 알려주는 출현(prevalence) 서비스를 개발했습니다. 환경의 지역적 뉘앙스를 이해하면 좀 더 확신을 갖고 의심스러운 이벤트를 승격 또는 억제하고 비정상적 프로세스 체인을 정확히 찾아낼 수 있습니다.
출현(prevalence) 서비스(그림 5)는 조건부 확률에서 파생된 두 가지 통계를 사용하며, 이를 통해 “이 상위 프로세스에서 이 하위 프로세스를 다른 하위 프로세스보다 X% 더 많이 보았습니다.” 그리고 “이 프로세스에서 이 명령줄을 해당 프로세스에 연결된 다른 명령줄보다 X% 더 많이 보았습니다.”라고 명시할 수 있습니다. 출현(Prevalence) 서비스를 배포하면 핵심 탐지 로직인 find_bad_communities를 추가로 보완할 수 있습니다.
“나쁜” 커뮤니티 찾기

그림 6 – 비정상적 커뮤니티 탐색을 위한 Python 코드
위의 그림 6에서 나쁜 커뮤니티를 생성하는 데 사용된 Python 코드를 확인했습니다. find_bad_communities의 로직은 매우 간단합니다.
- 호스트 머신의 각 process_create 이벤트를 분류하여 노드 쌍(예: 상위 노드와 하위 노드) 및 관련 가중치(예: 모델의 출력)를 생성합니다.
- 방향성 그래프를 구성합니다.
- 커뮤니티 탐지를 수행하여 그래프에 커뮤니티 목록을 생성합니다.
- 각 커뮤니티 내에서 상위-하위 이벤트가 얼마나 널리 퍼져 있는지 파악합니다(예: 각 연결). 최종 anomalous_score에서 상위-하위 이벤트의 보편성을 확인합니다.
- anomalous_score가 임계값을 충족하거나 초과하는 경우 분석가의 검토를 위해 해당하는 전체 커뮤니티를 따로 구분해 둡니다.
- 각 커뮤니티를 분석한 후 max anomalous_score로 정렬된 “나쁜” 커뮤니티 목록을 반환합니다.
결과
실제와 시뮬레이션된 양성 및 악성 데이터를 조합하여 최종 모델을 훈련했습니다. 양성 데이터는 내부 네트워크에서 3일 동안 수집한 Windows 프로세스 이벤트 데이터로 구성되었습니다. 소규모 조직을 복제하기 위해 사용자 워크스테이션과 서버를 혼합하여 양성 데이터의 소스를 만들었습니다. 악성 데이터는 Endgame RTA 프레임워크를 통해 사용할 수 있는 모든 ATT&CK 기법을 동원하고 FIN7 및 Emotet와 같은 고급 공격자의 매크로 및 바이너리 기반 맬웨어를 시작하여 생성했습니다.
본 실험에서는 Roberto Rodriguez의 Mordor 프로젝트에서 제공한 MITRE ATT&CK Evaluation의 이벤트 데이터를 사용하기로 했습니다. ATT&CK Evaluation은 PSEmpire 및 CobaltStrike와 같은 FOSS/COTS 도구를 사용하여 APT3 활동을 에뮬레이팅하려고 했습니다. 이러한 도구를 사용하면 자급자족(LotL) 기법을 연결하여 실행, 지속 또는 방어 회피 작업을 수행할 수 있습니다.
이 프레임워크에서는 프로세스 생성 이벤트만 사용하여 여러 다기법 공격 체인을 식별할 수 있었습니다. “탐색”(그림 7)과 “수평 이동”(그림 8)이 수행되는 것을 발견했고 분석가의 검토를 위해 강조 표시를 했습니다.

그림 7 – “탐색” 기법을 수행하는 프로세스 체인

그림 8 – “수평 이동”을 수행하는 프로세스 체인
데이터 감소
이 접근 방식은 비정상 프로세스 체인을 발견하고 오탐을 억제하는 출현(prevalence) 엔진의 가치를 입증하는 부가적인 기능을 보여주었습니다. 이와 함께 분석가가 검토해야 하는 이벤트 데이터의 양을 대폭 줄일 수 있었습니다. 숫자상으로 보면 다음과 같습니다.
- APT3 시나리오에서 엔드포인트당 최대 10,000개의 프로세스 생성 이벤트가 집계되었습니다(총 5개의 엔드포인트).
- 엔드포인트당 최대 6개의 비정상 커뮤니티가 식별되었습니다.
- 각 커뮤니티는 6~8개의 이벤트로 구성되었습니다.
다음 단계
현재 이 연구를 개념 증명에서 통합 솔루션으로 전환하여 Elastic Security의 한 기능으로 구현하려는 작업이 진행 중입니다. 가장 유력한 기능은 출현(prevalence) 엔진입니다. 파일의 발생 빈도를 보여주는 출현 엔진은 흔하지만, 이벤트 간 관계의 출현을 설명하는 기능은 보안 전문가가 자사에서 드문 이벤트와 흔한 이벤트가 무엇인지 살펴보고 전역적으로 드문 이벤트를 측정하여 보강함으로써 새로운 방식으로 위협을 탐지하는 데 도움이 됩니다.
결론
Elastic에서는 탐지기 작성 프로세스에서 도메인 전문 지식의 필요성을 줄이기 위해 작년에 VirusBulletin 및 CAMLIS에 이 그래프 기반 프레임워크(ProblemChild)를 발표했습니다. 지도 머신 러닝을 적용하여 가중치 그래프를 도출함으로써 별개로 보이는 이벤트로 이루어진 커뮤니티에서 더 큰 공격 시퀀스를 식별할 수 있는 기능을 입증했습니다. 이 프레임워크는 조건부 확률을 적용하여 비정상 커뮤니티의 순위를 자동으로 매기고 흔히 발생하는 상위-하위 체인을 억제합니다. 두 가지 목표 모두에 적용할 경우 분석가는 이 프레임워크를 사용하여 탐지기를 제작하거나 튜닝하고 시간이 지나면서 오탐을 줄일 수 있습니다.