Elastic 머신 러닝을 통한 사용자 주석
사용자 각주는 6.6 이상 버전부터 사용할 수 있는 Elasticsearch의 새로운 머신 러닝 기능입니다. 이 기능에서는 설명 도메인 지식을 통해 머신 러닝 작업을 강화할 수 있는 방법을 제공합니다. 머신 러닝 작업을 실행하면 머신 러닝 알고리즘이 변칙 탐색을 시작하지만 데이터 자체가 어떤 것에 대한 것인지는 알 수 없습니다. 예를 들어 작업을 통해서는 데이터가 CPU 사용 또는 네트워크 처리량에 대한 것인지 알 수 없습니다. 사용자 각주는 사용자로서 데이터에 대해 알고 있는 지식을 통해 결과를 강화할 수 있는 방법을 제공합니다.
이 블로그 글에서는 사용자 각주가 어떻게 작용하는지, 그리고 이를 다양한 사용 사례에 적용하는 방법을 보여드리겠습니다. 이제 오스트리아의 Tyrolean 지역 정부에서 운영하는 공개 데이터 포털인 Hydro Online의 데이터를 분석해 보겠습니다. Hydro Online은 강우 누적, 강의 수위 또는 스노우팩 수치의 총계가 얼마인지 조사하는 인터페이스를 제공합니다. 당사의 이전 블로그 게시물에서 설명한 것처럼 파일 데이터 시각화 장치(File Data Visualizer)는 CSV 데이터로부터 인사이트 데이터를 수집하는 다양한 방식을 제공합니다.
사용
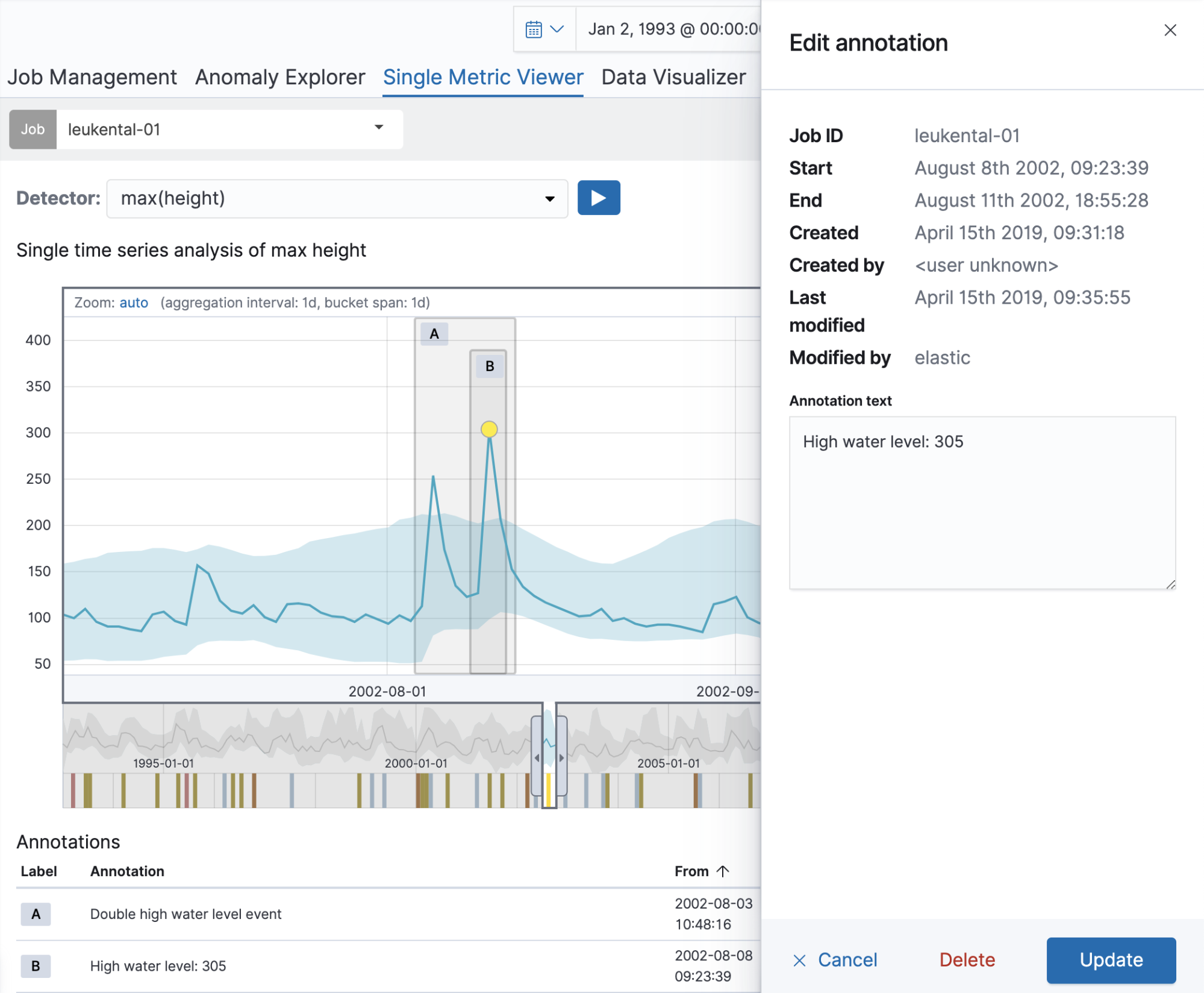
Kössen 지역에서 흐르는 Grossache강의 수위 측정값을 분석하는 이제 단일 메트릭 작업으로부터 시작하겠습니다. 작업이 생성되면 단일 메트릭 뷰어를 사용해 분석 결과에 대한 각주 추가에 사용할 수 있습니다. 차트의 기간 범위에 드래그하여 옮기기만 하면 각주가 생성됩니다. 플라리아웃 요소가 오른쪽에 팝업으로 나타나며 이를 통해 사용자 설명을 추가할 수 있습니다. 아래 예시에서 변칙이 있는 강의 수위에 각주를 추가했습니다(해당 날짜에 주요 범람 발생). 각주를 생성하여 다른 사용자에게 지식을 공개할 수 있습니다.
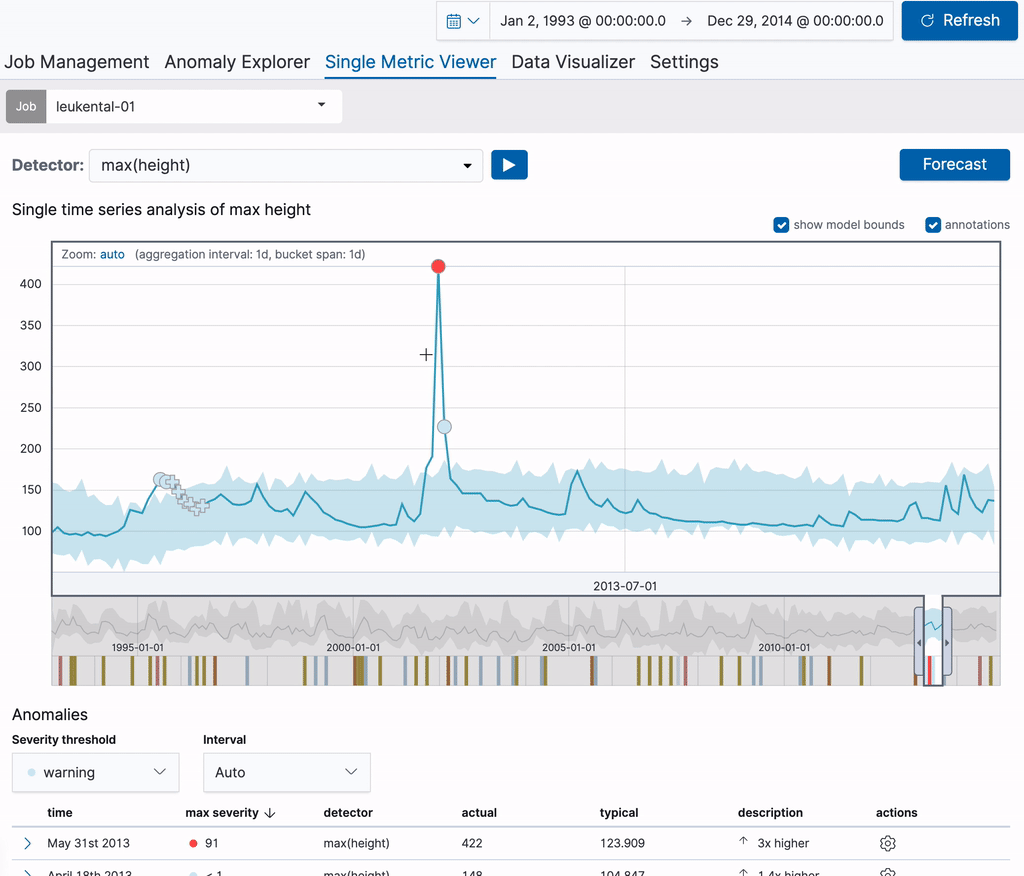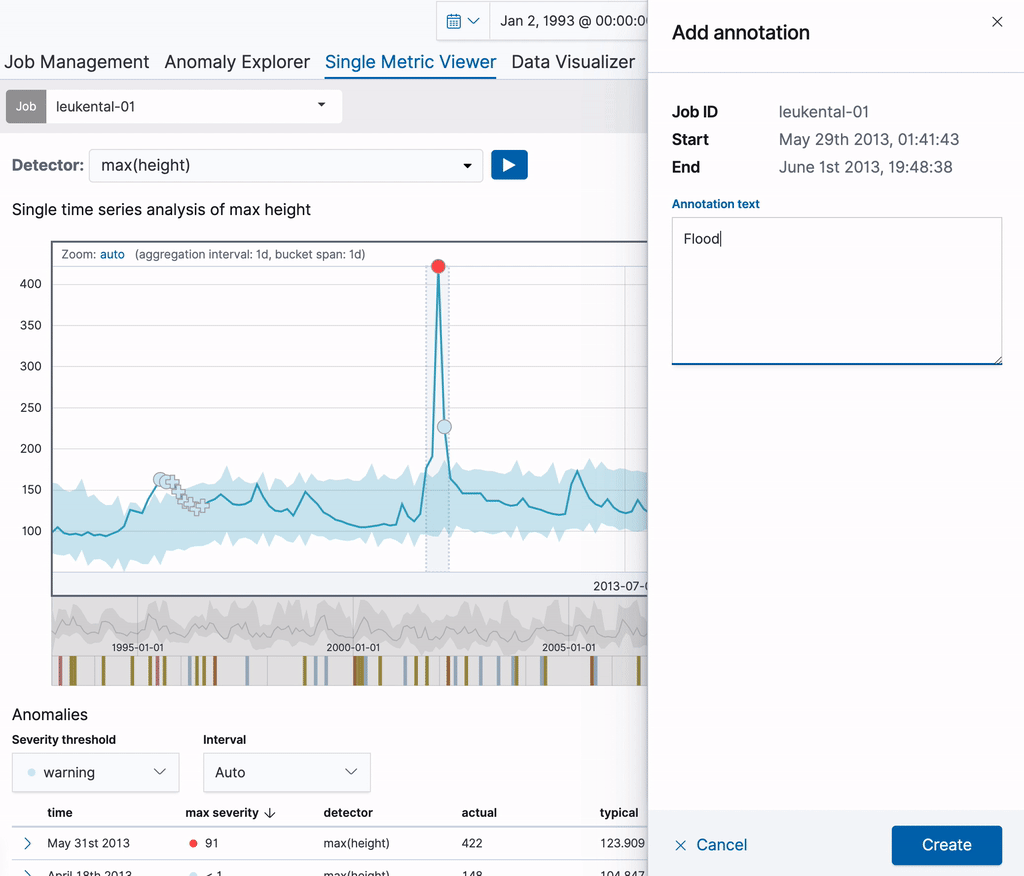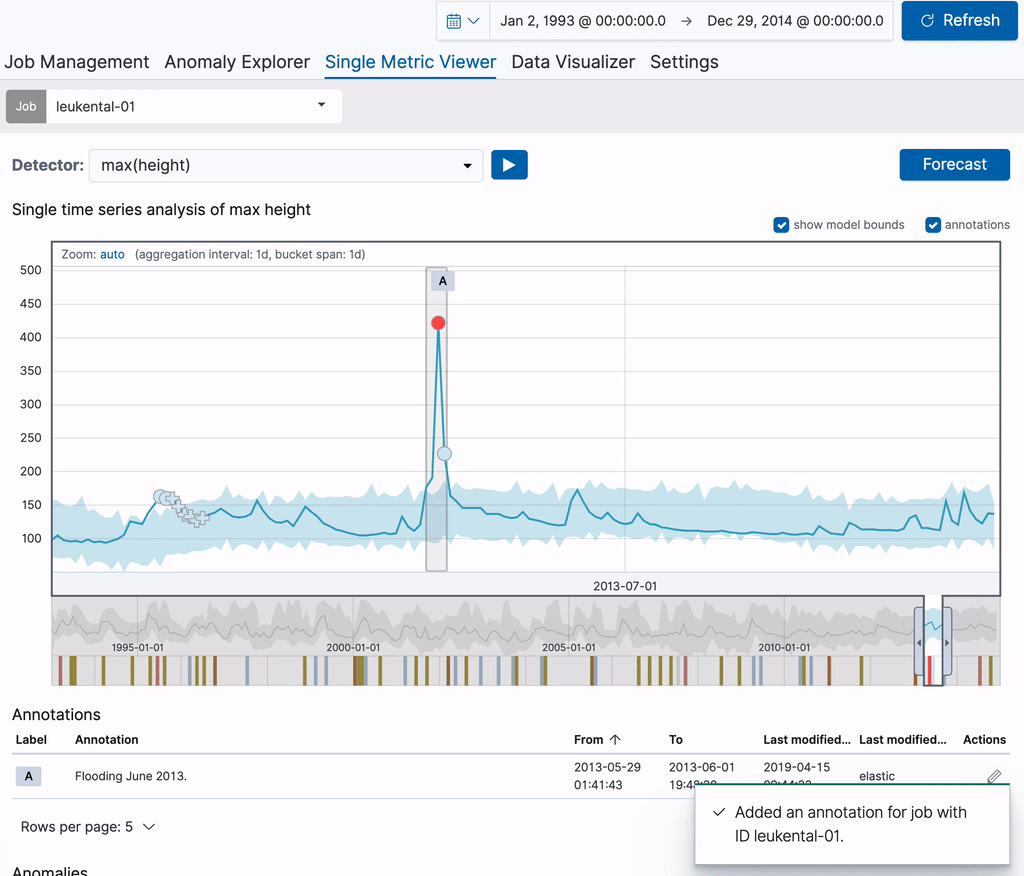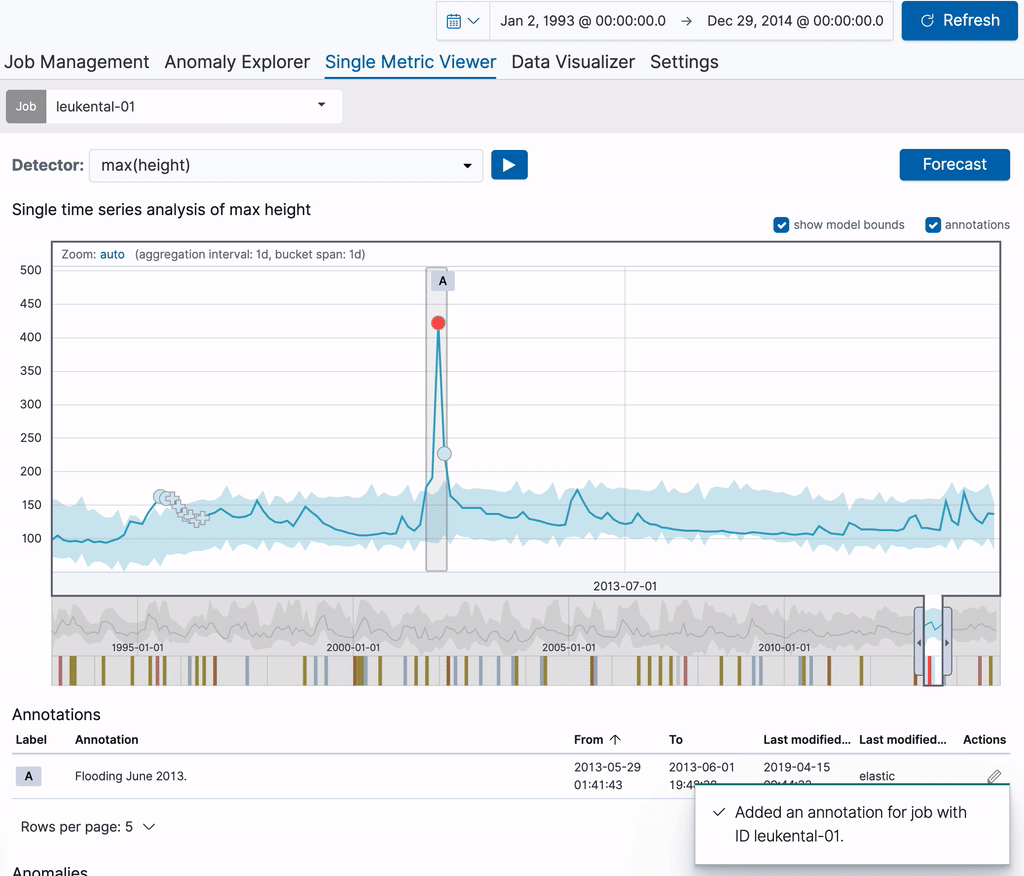
각주는 차트 자체와 아래 각주표에서 볼 수 있습니다. 표의 첫 번째 열에서 볼 수 있는 라벨은 차트의 각주를 확인하는 데 사용할 수 있습니다. 이러한 라벨은 디스플레이의 각주에 대해 동적 생성됩니다. 각주 표의 행에 커서를 놓고 있으며 해당 각주도 위 차트에 강조표시됩니다.
각 작업에 대해 생성된 각주는 작업 관리(Job Management) 페이지에서도 확인할 수 있으며, 여기에서는 작업 목록에서 행을 확장하면 각 해당 탭에 표시됩니다. 표의 각 각주에는 오른쪽 열에 있는 링크가 포함되며 이를 통해 각주에서 다루고 있는 기간에 중점을 둔 단일 메트릭 뷰어로 돌아갑니다. 이러한 퍼머링크도 다른 사람과 공유할 수 있습니다. 이는 각주를 사용해 특정 변칙에 북마크를 생성하여 나중에 다시 확인할 수 있음을 뜻합니다.

동일한 시간 범위를 다루는 다수의 각주가 있을 경우 각주는 겹치지 않도록 차트에서 수직으로 분배됩니다. 각주를 편집하거나 삭제하려면 차트에서 각주를 클릭하기만 하면 됩니다. 플라이아웃 요소가 오른쪽에 다시 열리며 여기에서 텍스트를 편집하거나 각주를 삭제할 수 있습니다. 6.7 버전부터는 각주표에서 편집 버튼을 사용해도 가능하며, 작업 관리 페이지에서도 이 기능을 사용할 수 있습니다.
이제 사용자 각주에 대한 생성 및 작업 방법의 기본 기능을 살펴보았으니 일부 추가 사용 사례들을 더 살펴보겠습니다.
각주를 사용해 예상되는 변칙을 확인
머신 러닝 작업이 예상되는 결과를 생산하는 경우 각주는 지상 실측을 제공하는 데 사용합니다. 다음 예시에서는 다시 한번 Hydro Online에서 강의 수위 데이터를 살펴보고 자동으로 과거의 이벤트를 변칙 결과의 각주로서 자동으로 오버레이하는 것을 목표로 하겠습니다. 예를 들어 데이터 과학자로서 여러분의 작업에는 분석하고자 하는 소스 데이터와 결과를 검증하기 위해 설정하는 데이터를 획득 및 준비하는 작업이 포함됩니다.
자체적인 분석을 위해서는 원본 데이터세트가 필요합니다.
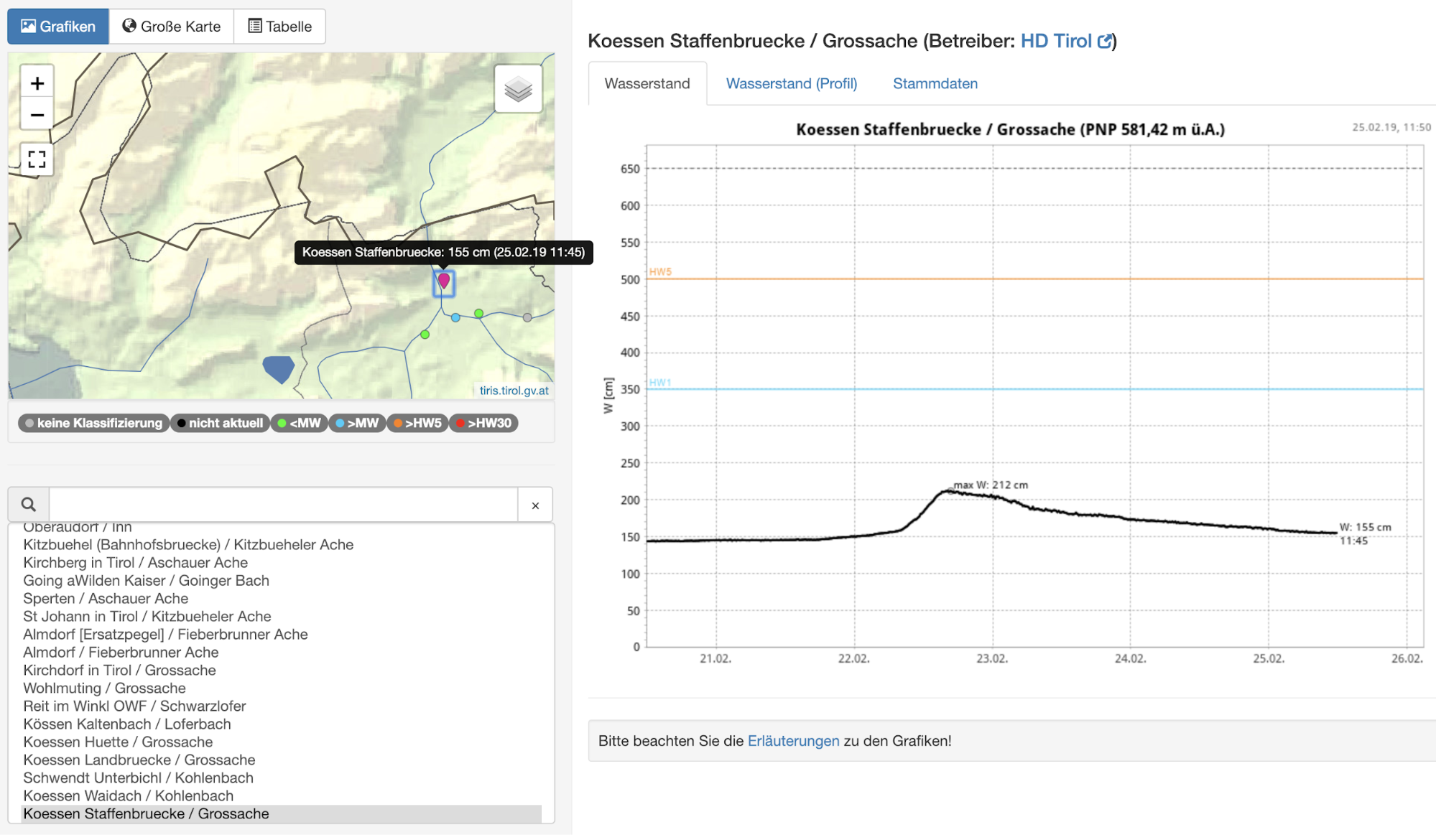
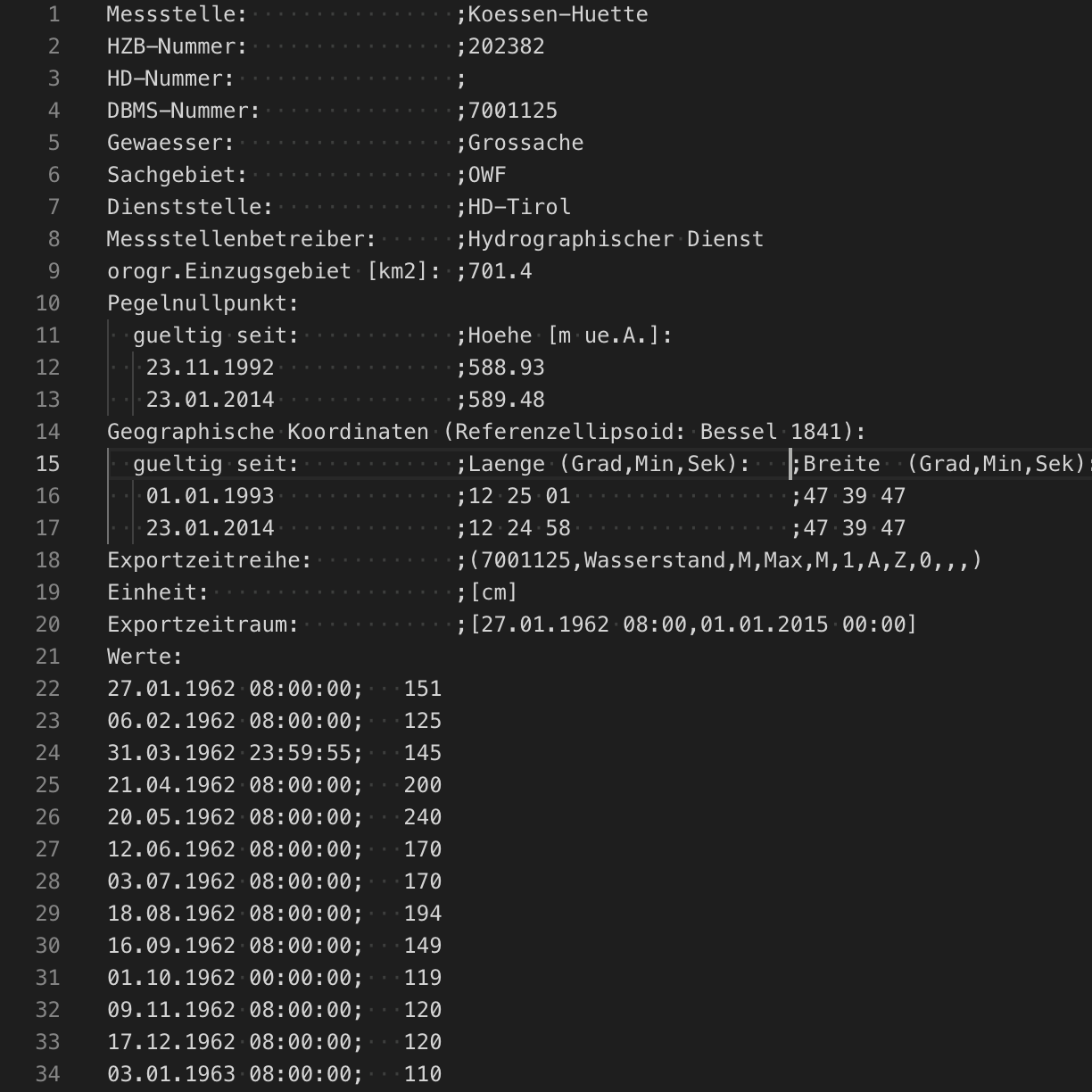
다행히도 이 경우에는 웹 인터페이스를 통해 데이터를 조사하는 것뿐만 아니라 추가 분석을 위해 과거의 데이터를 다운로드할 수도 있습니다. 이 예시에서는 “Huette” 측정점에서 측정한 Grossache강의 수위 데이터를 사용하겠습니다. 원하는 지상 실측을 다루는 각주는 심각한 강의 수위 및 홍수를 설명하는 문서에서 생성됩니다.
|

|
이전에 설명한 UI를 사용하는 것 이외에 머신 러닝 각주는 별도의 표준 Elasticsearch 색인에 문서로 저장됩니다. 각주는 또한 표준 Elasticsearch API를 사용해 프로그래밍 또는 수동으로 생성할 수 있습니다. 각주는 버전별 색인으로 저장되며 .ml-annotations-read 및 .ml-annotations-write라는 가칭으로 액세스해야 합니다. 이 예시에 대해서는 자체 머신 러닝 작업을 생성하기 전 과거의 강 이벤트를 반영하도록 각주를 추가하겠습니다.
{
"_index":".ml-annotations-6",
"_type":"_doc",
"_id":"DGNcAmoBqX9tiPPqzJAQ",
"_score":1.0,
"_source":{
"timestamp":1368870463669,
"end_timestamp":1371015709121,
"annotation":"2013 June; 770 m3/s; 500 houses flooded.",
"job_id":"annotations-leukental-4d-1533",
"type":"annotation",
"create_time":1554817797135,
"create_username":"elastic",
"modified_time":1554817797135,
"modified_username":"elastic"
}
}
이제 머신 러닝 작업을 생성해 수동으로 생성한 각주를 찾을 수 있도록 위 각주의 job_id 필드와 일치하는 이름을 사용해 강의 최대 수위에 대한 변칙을 찾아내겠습니다. 이는 과거의 강 데이터를 Elasticsearch 색인에 수집하면 단일 메트릭 마법사에서는 작업이 다음과 같이 나타납니다.
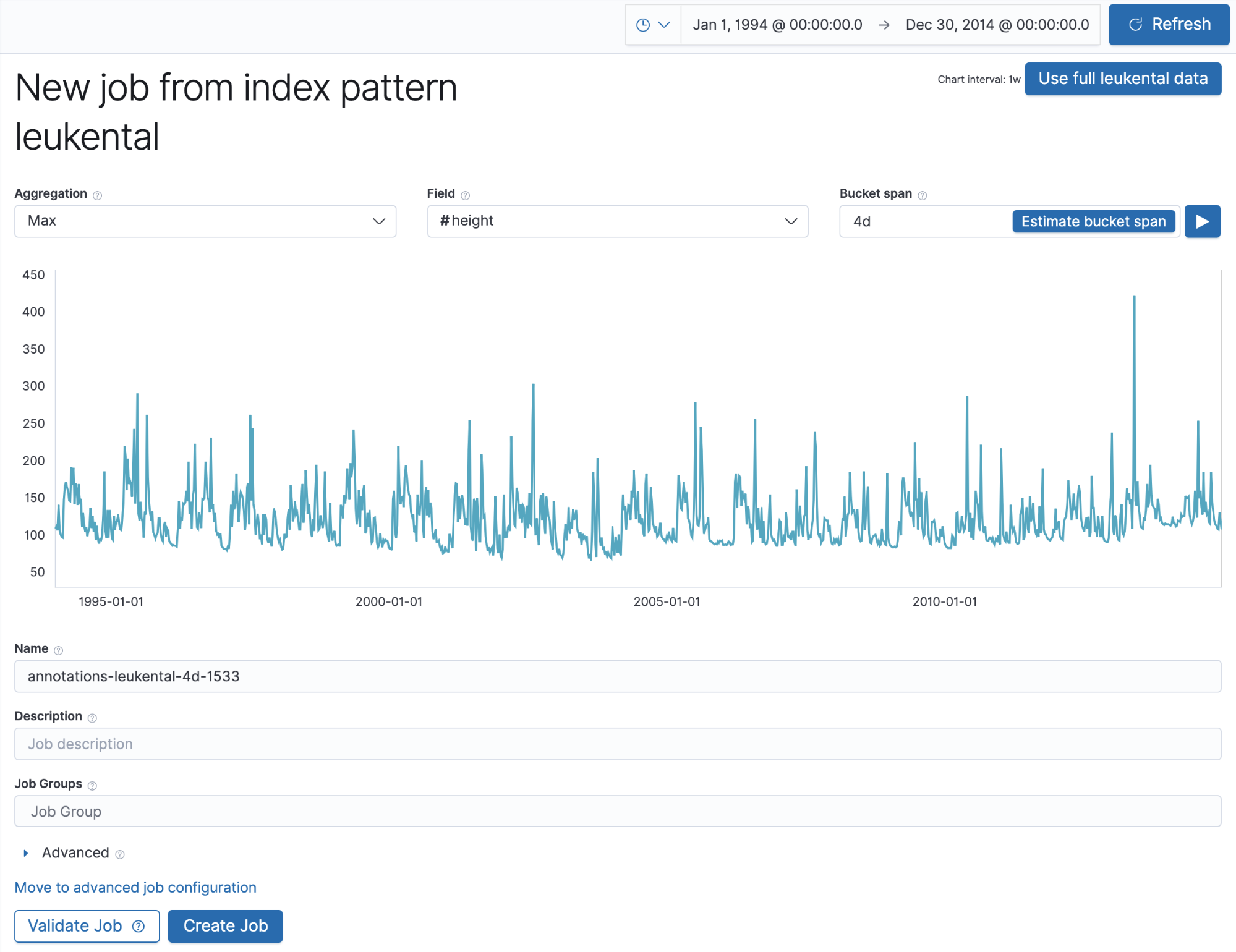
여기서 중요한 점은 선택한 작업 이름이 각주에 대해 사용한 것과 일치한다는 점입니다. 작업을 실행하고 단일 메트릭 뷰어로 이동하면 머신 러닝 작업이 감지한 강의 수위 변칙에 해당하는 각주를 볼 수 있습니다.
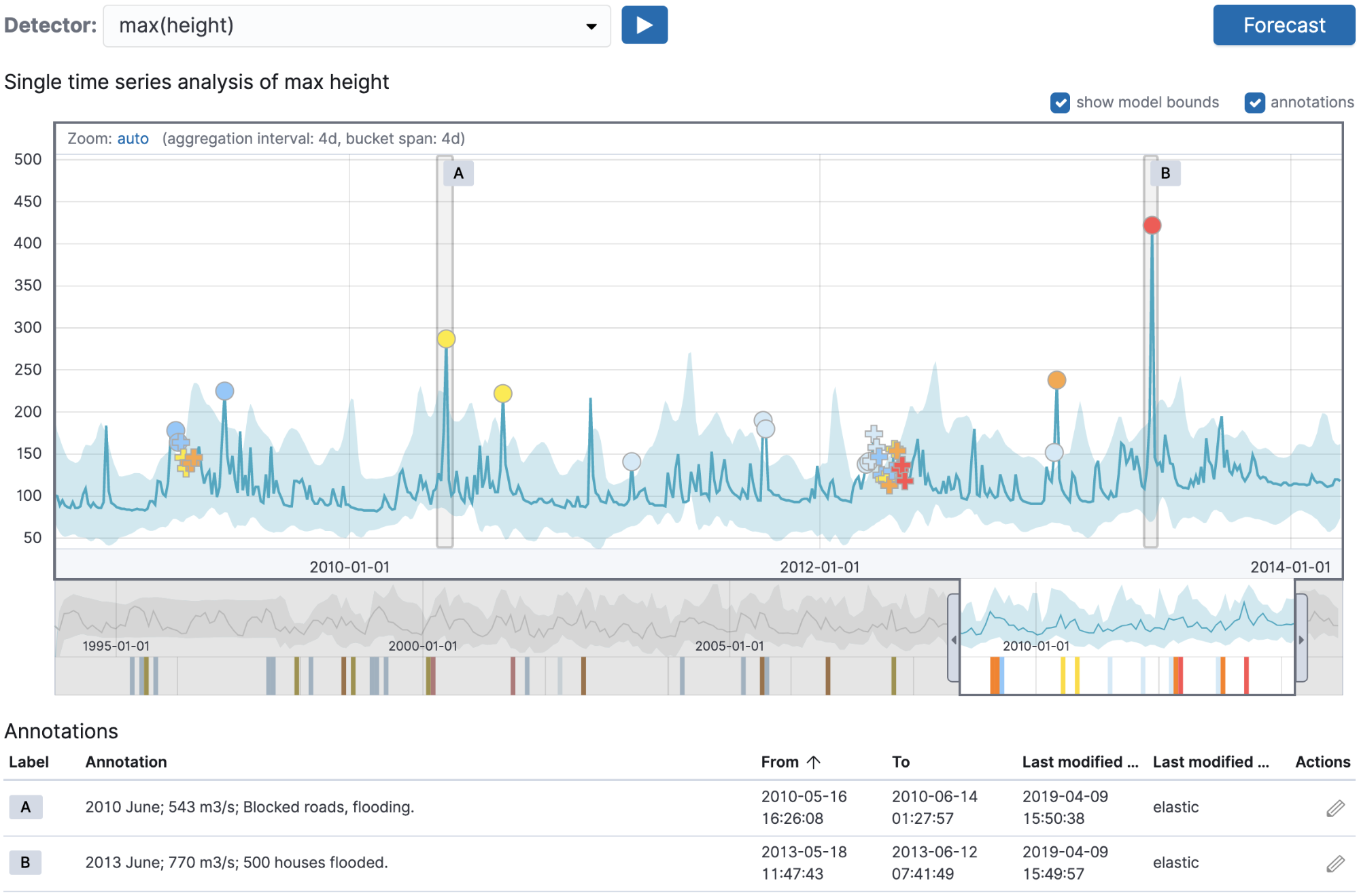
이 기술은 각주로 저장된 기존의 검증 데이터와 비교했을 때 실행하는 분석이 유효한지 확인할 수 있는 훌륭한 방법을 제공합니다.
시스템 이벤트에 대한 각주
사용자가 생성한 각주 이외에도 머신 러닝 백엔드는 시스템 이벤트에 대한 일부 상황에서 자동으로 각주를 생성합니다.
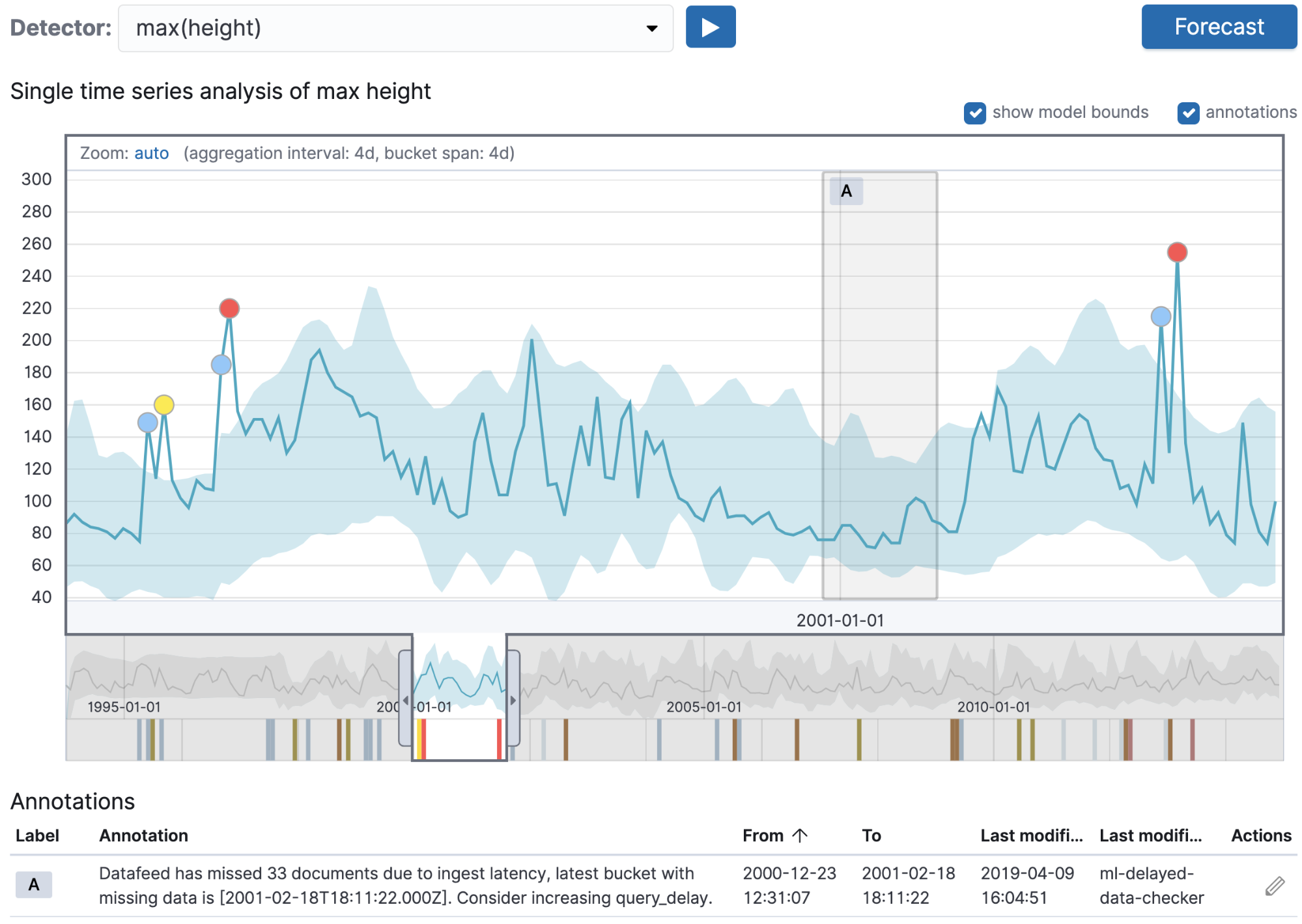
위 스크린샷에는 자동으로 생성한 각주의 예시가 나와 있습니다. 이 경우 실시간 머신 러닝 작업이 실행 중이었지만 데이터 수집이 작업에 필요한 수집 속도를 따라잡지 못했습니다. 이는 작업이 버킷에 대해 분석을 실행한 이후 색인에 문서가 추가되었음을 의미합니다. 자동으로 생성된 각주는 이전에 찾아내고 디버그하기 어려웠던 이 문제를 강조표시합니다. 각주 텍스트는 확인한 문제를 자세히 설명하고 해결 방법에 대한 제안을 제공합니다. 이 경우에는 query_delay 설정값을 증가시키는 것입니다.
경보 통합
머신 러닝에 대한 사용자 각주의 가용성 이전에도 Watcher를 사용해 머신 러닝 작업을 통해 확인한 변칙에 따라 경보를 생성할 수 있습니다. 기본 임계값에 대해 경보하는 것에 비할 때 뚜렷한 개선을 보이지만, 경보는 경보를 받는 목표 대상에 대해 너무 세분화된 것일 수 있습니다. 머신 러닝 작업의 사용자에게 각주는 무엇이 Watcher 경보로 트리거되고 무엇이 다른 이해관계자에게 전달되는지 큐레이팅하는 방식을 제공합니다. 각주가 자체적인 Elasticsearch 색인에 저장되는만큼, Watcher를 사용해 해당 색인에 새로 생성된 문서에 대응하고 알림을 트리거하기만 하면 됩니다. Watcher를 Slack 채널에 경보를 전송하도록 구성할 수도 있습니다. 다음 구성은 새로운 각주가 생성되었을 때 Slack 메시지를 트리거하도록 감시하는 방법에 대한 예시를 보여줍니다.
{
"trigger": {
"schedule": {
"interval": "5s"
}
},
"input": {
"search": {
"request": {
"search_type": "query_then_fetch",
"indices": [
".ml-annotations-read"
],
"rest_total_hits_as_int": true,
"body": {
"size": 1,
"query": {
"range": {
"create_time": {
"gte": "now-9s"
}
}
},
"sort": [
{
"create_time": {
"order": "desc"
}
}
]
}
}
}
},
"condition": {
"compare": {
"ctx.payload.hits.total": {
"gte": 1
}
}
},
"actions": {
"notify-slack": {
"transform": {
"script": {
"source": "def payload = ctx.payload; DateFormat df = new SimpleDateFormat(\"yyyy-MM-dd'T'HH:mm:ss.SSS'Z'\"); payload.timestamp_formatted = df.format(Date.from(Instant.ofEpochMilli(payload.hits.hits.0._source.timestamp))); payload.end_timestamp_formatted = df.format(Date.from(Instant.ofEpochMilli(payload.hits.hits.0._source.end_timestamp))); return payload",
"lang": "painless"
}
},
"throttle_period_in_millis": 10000,
"slack": {
"message": {
"to": [
"#<slack-channel>"
],
"text": "New Annotation for job *{{ctx.payload.hits.hits.0._source.job_id}}*: {{ctx.payload.hits.hits.0._source.annotation}}",
"attachments": [
{
"fallback": "View in Single Metric Viewer http://<kibana-host>:5601/app/ml#/timeseriesexplorer?_g=(ml:(jobIds:!({{ctx.payload.hits.hits.0._source.job_id}})),refreshInterval:(pause:!t,value:0),time:(from:'{{ctx.payload.timestamp_formatted}}',mode:absolute,to:'{{ctx.payload.end_timestamp_formatted}}'))&_a=(filters:!(),mlSelectInterval:(interval:(display:Auto,val:auto)),mlSelectSeverity:(threshold:(color:%23d2e9f7,display:warning,val:0)),mlTimeSeriesExplorer:(zoom:(from:'{{ctx.payload.timestamp_formatted}}',to:'{{ctx.payload.end_timestamp_formatted}}')),query:(query_string:(analyze_wildcard:!t,query:'*')))",
"actions": [
{
"name": "action_name",
"style": "primary",
"type": "button",
"text": "View in Single Metric Viewer",
"url": "http://<kibana-host>:5601/app/ml#/timeseriesexplorer?_g=(ml:(jobIds:!({{ctx.payload.hits.hits.0._source.job_id}})),refreshInterval:(pause:!t,value:0),time:(from:'{{ctx.payload.timestamp_formatted}}',mode:absolute,to:'{{ctx.payload.end_timestamp_formatted}}'))&_a=(filters:!(),mlSelectInterval:(interval:(display:Auto,val:auto)),mlSelectSeverity:(threshold:(color:%23d2e9f7,display:warning,val:0)),mlTimeSeriesExplorer:(zoom:(from:'{{ctx.payload.timestamp_formatted}}',to:'{{ctx.payload.end_timestamp_formatted}}')),query:(query_string:(analyze_wildcard:!t,query:'*')))"
}
]
}
]
}
}
}
}
}
위 구성에서 설정으로 <slack-channel> 및 <kibana-host>를 대체하고 이를 사용해 고급 감시를 생성하면 됩니다. 모든 설정이 끝나면 새로운 각주를 생성할 때마다 각주 텍스트 및 단일 메트릭 뷰어로 돌아가는 링크와 함께 Slack 알림을 받게 됩니다.

요약
이 글에서는 Elasticsearch 머신 러닝에 대한 새로운 각주 기능을 소개해드렸습니다. 이는 UI를 통한 각주 추가 및 백엔드 작업을 통해 트리거된 시스템 각주에 대해 사용할 수 있습니다. 이러한 각주는 작업 관리 페이지를 통해 북마크로 사용할 수 있으며 링크로 다른 사람과공유할 수 있습니다. 각주는 외부 데이터에서 프로그래밍을 통해 생성하여, 감지된 변칙에 대한 지상 실측 오버레이로 사용할 수 있습니다. 마지막으로 각주가 Watcher 및 Elasticsearch의 Slack 조치와 함께 큐레이팅한 경보에 대해 어떻게 사용되는지 살펴보았습니다. 각주와 함께 즐거운 작업을 진행하시길 바라며, 질문이 있으시면 토론 포럼에 글을 남겨 주십시오.