Elasticsearch에서 아리랑 한글 분석기 사용하기
이번 블로그 포스트는 한국 Elasticsearch 사용자 그룹의 정호욱님 께서 기고 해 주신 내용입니다.
필자 소개: 저는 2017년 현재 쿠팡 검색팀에서 개발업무를 수행하고 있는 정호욱 입니다. Elastic Stack 을 이용해서 상품검색, 로그분석, 추천 등 다양 서비스에서 사용하고 있습니다. 이런 작업을 하면서 기본적으로 필요 했던게 형태소 분석기 였습니다. 과거 수명님이 오픈소스로 올려 주신 krlucene 때부터 지금의 arirang 으로 오기까지 사용하기 쉽고 Lucene 과도 잘 연동이 된다는 점 때문에 elasticsearch 에서도 활용하게 된것 같습니다. 제가 작업한 것은 analysis plugin 을 만들기 위한 과정이지 실제 형태소 분석기에 대한 작업은 거의 없습니다. 앞으로 많은 개발자 분들이 arirang 에 대한 기여를 해주신다면 좋을 것 같아 글을 작성해 보았습니다. 개인적인 질문이나 궁금한 점은 아래 링크를 통해 올려 주시면 아는 만큼 공유할 수 있도록 하겠습니다.
한국 Elasticsearch 페이스북 그룹 : https://www.facebook.com/groups/elasticsearch.kr/ 개인 블로그 : http://jjeong.tistory.com 개인 링크드인 : https://www.linkedin.com/in/hwjeong/
시작하며
Elasticsearch를 서비스에 사용하면서 한글 처리를 위해 어떤 analyzer를 사용해야 할지 고민해 보신적이 있을 것입니다. 이 블로그 포스트에서는 필자가 사용하고 있는 Lucene Korean Analyzer와 이를 Elasticsearch에 plugin으로 설치하고 사용하는 방법을 알아 보도록 하겠습니다.
Lucene Analyzer
들어가기에 앞서 lucene에서 제공하는 analyzer의 기본 구성과 동작에 대해서 살펴 보겠습니다. Lucene에서 제공하는 analyzer 는 하나의 tokenizer와 다수의 filter로 구성이 됩니다. Filter 는 CharFilter와 TokenFilter 두 가지가 있습니다. CharFilter는 입력된 문자열에서 불필요한 문자를 normalization 하기 위해 사용되며 TokenFilter는 tokenizer에 의해 분해된 token에 대한 filter 처리를 하게 됩니다. 결과적으로 아래와 같은 순서로 analysis 된다고 이해 하면 됩니다.
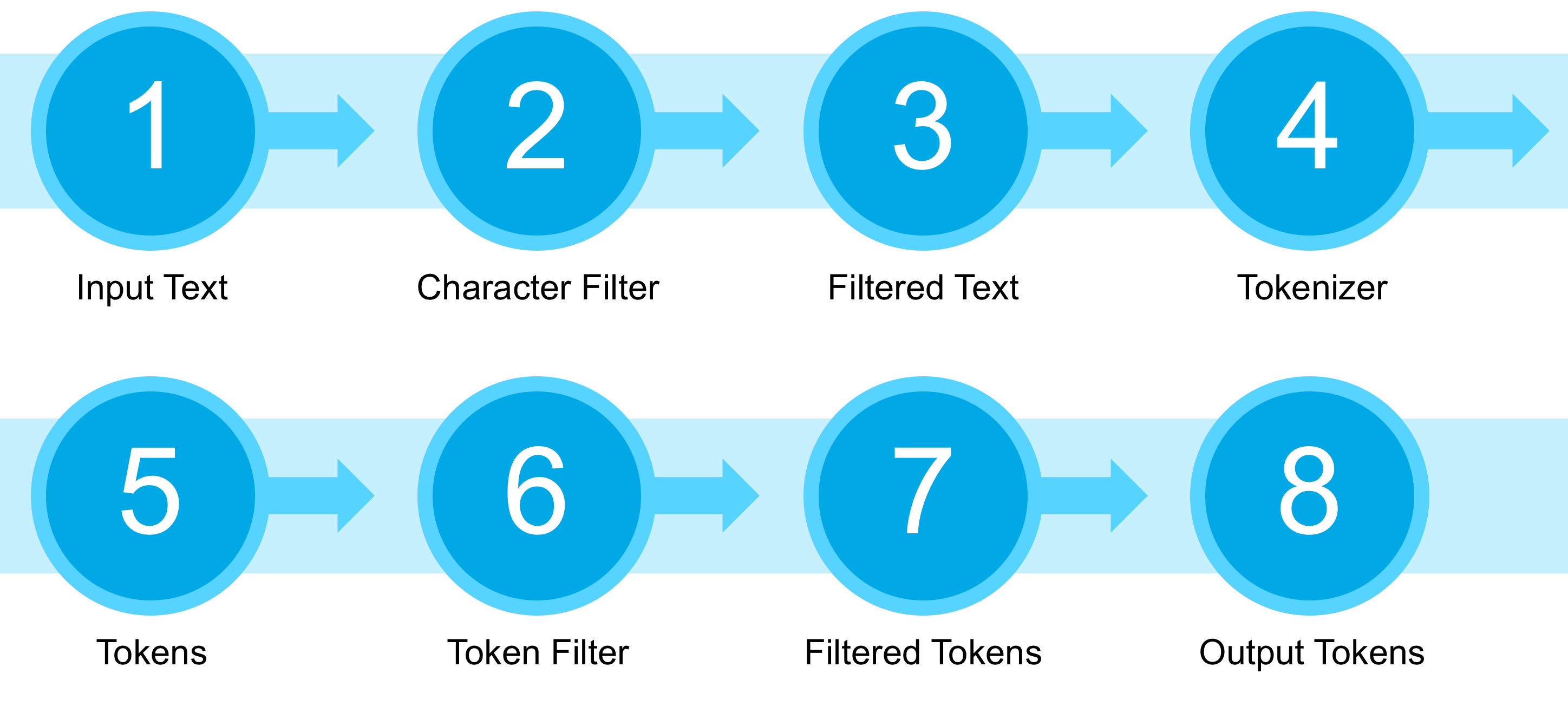
Lucene Korean Analyzer
이제 본론으로 들어 가겠습니다. Lucene Korean Analyzer는 현재 이수명님에 의해 개발 및 유지보수가 되고 있으며 오픈소스로 등록이 되어 있습니다. 관련 소스코드는 아래 두 가지 repository를 통해서 제공 되고 있습니다.
[svn 주소] https://lucenekorean.svn.sourceforge.net/svnroot/lucenekorean
[github 주소] https://github.com/korlucene
※ Lucene Korean Analyzer 는 지금 Arirang 이라고 부르고 있습니다.
Arirang의 프로젝트 구성은 크게 두 부분으로 나뉩니다.
- arirang analyzer
- arirang morph
1. arirang morph
이 프로젝트는 한글 형태소에 대한 기본 분석과 사전 정보로 구성이 되어 있습니다. 한글 처리와 사전 정보를 변경 하고 싶을 경우 본 프로젝트의 코드를 분석하고 수정 해서 활용을 하실 수 있습니다.
2. arirang analyzer
이 프로젝트는 lucene의 analyzer를 상속받아 lucene에서 사용 할 수 있도록 구성이 되어 있습니다. Lucene의 analyzer pipeline에 필요한
- KoreanAnalyzer
- KoreanFilter
- KoreanFilterFactory
- KoreanToken
- KoreanTokenizer
- KoreanTokenizerFactory
등이 주요 클래스로 구현이 되어 있습니다.
한글 형태소 분석 사전
한글 형태소 분석에서 중요한 역할을 하는 부분으로 사전 이라는 것이 있으며, 이를 알아 보도록 하겠습니다.
arirang.morph 프로젝트에 포함이 되어 있으며 언급 한것과 같이 지속적인 업데이트 및 변경이 가능 합니다.
1. Dictionary classpath
org/apache/lucene/analysis/ko/dic
2. Dictionary files
org/apache/lucene/analysis/ko
korean.properties
org/apache/lucene/analysis/ko/dic
abbreviation.dic
cj.dic
compounds.dic
eomi.dic
extension.dic
josa.dic
mapHanja.dic
occurrence.dic
prefix.dic
suffix.dic
syllable.dic
total.dic
uncompounds.dic
3. 주요 사전 설명
주요 사전 설명 이라고는 했지만 쉽고 빠르게 활용할 수 있는 사전이라고 이해 하시면 좋을 것 같습니다.
total.dic
이 사전 파일은 arirang analyzer 에서 사용하는 기본 사전으로 그대로 사용을 하시면 됩니다. 다만, 수정이 필요 하실 경우 아래 extension.dic 파일을 활용 하시면 됩니다.
extension.dic
확장사전이라고 부르며, 사전 데이터를 추가 해야 할 경우 이 파일에 추가해서 운영 및 관리를 하시면 됩니다.
compounds.dic
복합명사 사전으로 하나의 단어가 여러개의 단어로 구성이 되어 있을 경우 이를 분해하기 위한 사전 정보를 관리 하는 파일 입니다.
4. total.dic / extension.dic 파일 구조
체언/용언/기타품사/하여(다)동사/되어(다)동사/'내'가 붙을 수 있는 체언/NA/NA/NA/불규칙변경
각 예문의 경우 다음과 같이 표현이 됩니다.
예)
엘사 는 명사이고 동사, 기타품사, 불규칙이 아니다
엘사,100000000X
노래 는 명사이고 하여(다) 동사이다
노래,100100000X
소리 는 명사이고 소리내다 와 같이 내 가 붙을 수 있는 명사이다
소리,100001000X
불규칙 정보는 아래와 같으며 원문을 참고 하시기 바랍니다.
B : ㅂ 불규칙
H : ㅎ 불규칙
L : 르 불규칙
U : ㄹ 불규칙
S : ㅅ 불규칙
D : ㄷ 불규칙
R : 러 불규칙
X : 규칙
※ 원문 : http://cafe.naver.com/korlucene/135
5. compound.dic 파일 구조
분해전 단어:분해후단어1,분해후단어2,…,분해후단어N:DBXX
분해전 단어에 하여(다)동사(D), 되어(다)동사(B) 가 붙을 수 있는지 확인 하셔야 합니다.
예)
객관화:객관,화:1100
이와 같이 된 이유는
- 객관화하다
- 객관화되다
가 되기 때문입니다.
참고) http://krdic.naver.com/search.nhn?query=%EA%B0%9D%EA%B4%80%ED%99%94&kind=all
Elasticsearch plugin 제작
이제 부터는 소스 코드를 내려 받아서 빌드 후 Elasticsearch plugin을 만드는 방법을 알아 보겠습니다.
arirang 프로젝트 구성
1. 프로젝트 clone
기본적으로 master branch 를 받습니다.
$ git clone https://github.com/korlucene/arirang.morph.git
$ git clone https://github.com/korlucene/arirang-analyzer-6.git
2. Maven build
두 프로젝트 모드 maven project로 빌드 장비에 maven 이 설치가 되어 있어야 합니다.
※ maven 설치 참고 : https://maven.apache.org/
arirang-analyzer-6 프로젝트에 기본적으로 arirang.morph 패키지가 등록이 되어 있기 때문에 별도 arirang.morph를 수정 하지 않았다면 arirang-analyzer-6 만 빌드하시면 됩니다.
arirang.morph $ mvn clean package
arirang-analyzer-6 $ mvn clean package
3. 기능 테스트
기능 테스트는 arirang-analyzer-6 프로젝트에 포함된 test code를 이용해서 확인해 보시면 됩니다.
src/test 아래 TestKoreanAnalyzer1 클래스를 참고하시면 됩니다.
☞ 아래는 이해를 돕기 위해 원본 테스트 코드를 추가 하였습니다.
/**
* Created by SooMyung(soomyung.lee@gmail.com) on 2014. 7. 30.
*/
public class TestKoreanAnalyzer1 extends TestCase {
public void testKoreanAnalzer() throws Exception {
String[] sources = new String[]{
"고려 때 중랑장(中郞將) 이돈수(李敦守)의 12대손이며",
"이돈수(李敦守)의",
"K•N의 비극",
"金靜子敎授",
"天國의",
"기술천이",
"12대손이며",
"明憲淑敬睿仁正穆弘聖章純貞徽莊昭端禧粹顯懿獻康綏裕寧慈溫恭安孝定王后",
"홍재룡(洪在龍)의",
"정식시호는 명헌숙경예인정목홍성장순정휘장소단희수현의헌강수유령자온공안효정왕후(明憲淑敬睿仁正穆弘聖章純貞徽莊昭端禧粹顯懿獻康綏裕寧慈溫恭安孝定王后)이며 돈령부영사(敦寧府領事) 홍재룡(洪在龍)의 딸이다. 1844년, 헌종의 정비(正妃)인 효현왕후가 승하하자 헌종의 계비로써 중궁에 책봉되었으나 5년 뒤인 1849년에 남편 헌종이 승하하고 철종이 즉위하자 19세의 어린 나이로 대비가 되었다. 1857년 시조모 대왕대비 순원왕후가 승하하자 왕대비가 되었다.",
"노벨상을"
};
KoreanAnalyzer analyzer = new KoreanAnalyzer();
for (String source : sources) {
TokenStream stream = analyzer.tokenStream("dummy", new StringReader(source));
CharTermAttribute termAtt = stream.addAttribute(CharTermAttribute.class);
PositionIncrementAttribute posIncrAtt = stream.addAttribute(PositionIncrementAttribute.class);
PositionLengthAttribute posLenAtt = stream.addAttribute(PositionLengthAttribute.class);
TypeAttribute typeAtt = stream.addAttribute(TypeAttribute.class);
OffsetAttribute offsetAtt = stream.addAttribute(OffsetAttribute.class);
MorphemeAttribute morphAtt = stream.addAttribute(MorphemeAttribute.class);
stream.reset();
while (stream.incrementToken()) {
System.out.println(termAtt.toString() + ":" + posIncrAtt.getPositionIncrement() + "(" + offsetAtt.startOffset() + "," + offsetAtt.endOffset() + ")");
}
stream.close();
}
}
}
Elasticsearch plugin 빌드
이제 arirang에 대한 빌드와 기능테스트가 끝났으니 elasticsearch에 설치 하기 위한 plugin 만드는 방법을 알아 보도록 하겠습니다. 먼저, elasticsearch에서 제공하는 plugins 관련 문서를 시간이 된다면 한번 읽어 보시고 아래 내용을 보시길 추천 드립니다.
※ Elasticsearch Plugins and Integrations : https://www.elastic.co/guide/en/elasticsearch/plugins/5.5/index.html
Elastic에서 공식문서에서 제공해 주고 있는 예제는 아래 링크에 나와 있으니 구현 시 참고하시기 바랍니다. ☞ https://github.com/elastic/elasticsearch/tree/master/plugins/jvm-example
※ 필자가 추천하는 것은 elasticsearch source code를 다운받아 official하게 작성된 plugin 코드를 참고하여 구현하는 방법 입니다.
그럼 analysis plugin의 기본 프로젝트 구조를 살펴 보겠습니다.
1. Project Directory
src/main
assemblies
plugin.xml
java
org/elasticsearch
index/analysis
${CUSTOM-ANALYZER-NAME}AnalyzerProvider
${CUSTOM-ANALYZER-NAME}TokenFilterFactory
${CUSTOM-ANALYZER-NAME}TokenizerFactory
plugin/analysis/arirang
Analysis${CUSTOM-ANALYZER-NAME}Plugin
resources
plugin-descriptor.propeties
2. Files and classes
plugin.xmlmaven assembly plugin을 이용한 패키징을 하기 위한 설정을 구성 합니다.plugin-descriptor.propetiesplugin authors 정보를 구성 합니다. elasticsearch reference: https://www.elastic.co/guide/en/elasticsearch/plugins/5.5/plugin-authors.html${CUSTOM-ANALYZER-NAME}AnalyzerProvidercustom analyzer 생성자 제공을 위한 코드를 작성 합니다.${CUSTOM-ANALYZER-NAME}TokenFilterFactorycustom filter 생성자 제공을 위한 코드를 작성 합니다.${CUSTOM-ANALYZER-NAME}TokenizerFactorycustom tokenizer 생성자 제공을 위한 코드를 작성 합니다.Analysis${CUSTOM-ANALYZER-NAME}Plugincustom analyzer plugin 등록을 위한 코드를 작성 합니다.
이와 같은 구조를 이용하여 elasticsearch-analysis-arirang plugin을 만들어 보도록 하겠습니다.
본 plugin에서는 arirang에서 제공하는 dynamic dictionary reload 기능을 사용하기 위한 Rest Handler도 추가해서 만들어 보도록 하겠습니다.
소스코드 참고) https://github.com/HowookJeong/elasticsearch-analysis-arirang/tree/5.5.0
Step1)
- Maven project를 생성 합니다.
pom.xml구성은 github에 등록된 파일을 참고 하셔서 작성 하시면 됩니다. https://github.com/HowookJeong/elasticsearch-analysis-arirang/blob/5.5.0/pom.xml
Step2)
- Plugin project structure를 구성 합니다.
Step3)
- root path에 lib 폴더를 생성하고 arirang analyzer 관련 jar 파일을 복사해 놓습니다.
arirang.lucene-analyzer-VERSION.jararirang-morph-VERSION.jar
Step4)
-
<dependency> <groupId>com.argo</groupId> <artifactId>morph</artifactId> <version>${morph.version}</version> <scope>system</scope> <systemPath>${project.basedir}/lib/arirang-morph-${morph.version}.jar</systemPath> <optional>false</optional> </dependency> <dependency> <groupId>com.argo</groupId> <artifactId>arirang.lucene-analyzer-${lucene.version}</artifactId> <version>${morph.version}</version> <scope>system</scope> <systemPath>${project.basedir}/lib/arirang.lucene-analyzer-${lucene.version}-${morph.version}.jar</systemPath> <optional>false</optional> </dependency>pom.xml에서 local jar 파일에 대한 dependency 설정을 추가해 줍니다.
Step5)
-
analysis plugin 관련 코드를 작성 합니다.
@Override public List<RestHandler> getRestHandlers(Settings settings, RestController restController, ClusterSettings clusterSettings, IndexScopedSettings indexScopedSettings, SettingsFilter settingsFilter, IndexNameExpressionResolver indexNameExpressionResolver, Supplier<DiscoveryNodes> nodesInCluster) { return singletonList(new ArirangAnalyzerRestAction(settings, restController)); }
@Override public Map<String, AnalysisProvider<TokenFilterFactory>> getTokenFilters() { return singletonMap("arirang_filter", ArirangTokenFilterFactory::new); }
@Override public Map<String, AnalysisProvider<TokenizerFactory>> getTokenizers() { Map<String, AnalysisProvider<TokenizerFactory>> extra = new HashMap<>(); extra.put("arirang_tokenizer", ArirangTokenizerFactory::new);
return extra;}
@Override public Map<String, AnalysisProvider<AnalyzerProvider<? extends Analyzer>>> getAnalyzers() { return singletonMap("arirang_analyzer", ArirangAnalyzerProvider::new); }
Step6)
-
analysis 관련 코드를 작성 합니다.
// ArirangAnalyzerProvider private final KoreanAnalyzer analyzer;
public ArirangAnalyzerProvider(IndexSettings indexSettings, Environment env, String name, Settings settings) throws IOException { super(indexSettings, name, settings);
analyzer = new KoreanAnalyzer();}
@Override public KoreanAnalyzer get() { return this.analyzer; }
// ArirangTokenFilterFactory public ArirangTokenFilterFactory(IndexSettings indexSettings, Environment env, String name, Settings settings) { super(indexSettings, name, settings); }
@Override public TokenStream create(TokenStream tokenStream) { return new KoreanFilter(tokenStream); }
// ArirangTokenizerFactory public ArirangTokenizerFactory(IndexSettings indexSettings, Environment env, String name, Settings settings) { super(indexSettings, name, settings); }
@Override public Tokenizer create() { return new KoreanTokenizer(); }
Step7)
-
rest action 관련 코드를 작성 합니다.
// ArirangAnalyzerRestAction @Inject public ArirangAnalyzerRestAction(Settings settings, RestController controller) { super(settings);
controller.registerHandler(RestRequest.Method.GET, "/_arirang_dictionary_reload", this);}
@Override protected RestChannelConsumer prepareRequest(RestRequest restRequest, NodeClient client) throws IOException { try { DictionaryUtil.loadDictionary(); } catch (MorphException me) { return channel -> channel.sendResponse(new BytesRestResponse(RestStatus.NOT_ACCEPTABLE, "Failed which reload arirang analyzer dictionary!!")); } finally { }
return channel -> channel.sendResponse(new BytesRestResponse(RestStatus.OK, "Reloaded arirang analyzer dictionary!!"));}
// ArirangAnalyzerRestModule @Override protected void configure() { // TODO Auto-generated method stub bind(ArirangAnalyzerRestAction.class).asEagerSingleton(); }
Step8)
-
plugin-descriptor.properties관련 코드를 작성 합니다.classname=org.elasticsearch.plugin.analysis.arirang.AnalysisArirangPlugin name=analysis-arirang jvm=true java.version=1.8 site=false isolated=true description=Arirang plugin version=${project.version} elasticsearch.version=${elasticsearch.version} hash=${buildNumber} timestamp=${timestamp}
Step9)
-
패키징을 하기 위한
<file> <source>lib/arirang.lucene-analyzer-6.5.1-1.1.0.jar</source> <outputDirectory>elasticsearch</outputDirectory> </file> <file> <source>lib/arirang-morph-1.1.0.jar</source> <outputDirectory>elasticsearch</outputDirectory> </file> <file> <source>target/elasticsearch-analysis-arirang-5.5.0.jar</source> <outputDirectory>elasticsearch</outputDirectory> </file> <file> <source>${basedir}/src/main/resources/plugin-descriptor.properties</source> <outputDirectory>elasticsearch</outputDirectory> <filtered>true</filtered> </file>plugin.xml관련 코드를 작성 합니다.
Step10)
-
빌드를 합니다.
$ mvn clean package -DskipTests=true
여기서는 작성된 코드는 일부만 발췌 했기 때문에 github에 올라간 소스코드를 참고하시기 바랍니다. 또한, 위 단계는 순서가 중요한 것이 아니며 구성과 어떻게 구현을 해야 하는지를 이해 하시는게 중요 합니다.
플러그인 설치 및 기능 확인
이제 빌드가 완료 되었으니 설치 및 기능 점검을 수행해 보도록 하겠습니다.
1. 설치
$ bin/elasticsearch-plugin install --verbose file:///path/elasticsearch-analysis-arirang-5.5.0.zip
2. 기능점검
-
실행
$ bin/elasticsearch [2017-08-22T18:56:17,223][INFO ][o.e.n.Node ] [singlenode] initializing ... [2017-08-22T18:56:17,289][INFO ][o.e.e.NodeEnvironment ] [singlenode] using [1] data paths, mounts [[/ (/dev/disk1)]], net usable_space [489.3gb], net total_space [930.3gb], spins? [unknown], types [hfs] [2017-08-22T18:56:17,289][INFO ][o.e.e.NodeEnvironment ] [singlenode] heap size [1.9gb], compressed ordinary object pointers [true] [2017-08-22T18:56:17,309][INFO ][o.e.n.Node ] [singlenode] node name [singlenode], node ID [saCA_25vSxyUwF-RagteLw] [2017-08-22T18:56:17,309][INFO ][o.e.n.Node ] [singlenode] version[5.5.0], pid[12613], build[260387d/2017-06-30T23:16:05.735Z], OS[Mac OS X/10.12.5/x86_64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/1.8.0_72/25.72-b15] [2017-08-22T18:56:17,309][INFO ][o.e.n.Node ] [singlenode] JVM arguments [-Xms2g, -Xmx2g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -XX:+DisableExplicitGC, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -Djdk.io.permissionsUseCanonicalPath=true, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Dlog4j.skipJansi=true, -XX:+HeapDumpOnOutOfMemoryError, -Des.path.home=/Users/jeonghoug/dev/server/elastic/elasticsearch-5.5.0] [2017-08-22T18:56:18,131][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [aggs-matrix-stats] [2017-08-22T18:56:18,131][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [ingest-common] [2017-08-22T18:56:18,131][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [lang-expression] [2017-08-22T18:56:18,131][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [lang-groovy] [2017-08-22T18:56:18,131][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [lang-mustache] [2017-08-22T18:56:18,131][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [lang-painless] [2017-08-22T18:56:18,131][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [parent-join] [2017-08-22T18:56:18,131][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [percolator] [2017-08-22T18:56:18,131][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [reindex] [2017-08-22T18:56:18,132][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [transport-netty3] [2017-08-22T18:56:18,132][INFO ][o.e.p.PluginsService ] [singlenode] loaded module [transport-netty4] [2017-08-22T18:56:18,132][INFO ][o.e.p.PluginsService ] [singlenode] loaded plugin [analysis-arirang] [2017-08-22T18:56:19,195][INFO ][o.e.d.DiscoveryModule ] [singlenode] using discovery type [zen] [2017-08-22T18:56:19,686][INFO ][o.e.n.Node ] [singlenode] initialized [2017-08-22T18:56:19,687][INFO ][o.e.n.Node ] [singlenode] starting ... [2017-08-22T18:56:24,837][INFO ][o.e.t.TransportService ] [singlenode] publish_address {127.0.0.1:9300}, bound_addresses {[fe80::1]:9300}, {[::1]:9300}, {127.0.0.1:9300} [2017-08-22T18:56:27,899][INFO ][o.e.c.s.ClusterService ] [singlenode] new_master {singlenode}{saCA_25vSxyUwF-RagteLw}{_fn1si8zTT6bkZK1q6ilxQ}{127.0.0.1}{127.0.0.1:9300}, reason: zen-disco-elected-as-master ([0] nodes joined) [2017-08-22T18:56:27,928][INFO ][o.e.h.n.Netty4HttpServerTransport] [singlenode] publish_address {127.0.0.1:9200}, bound_addresses {[fe80::1]:9200}, {[::1]:9200}, {127.0.0.1:9200}
-
형태소분석기 확인
http://localhost:9200/_analyze?pretty&analyzer=arirang_analyzer&text=한국 엘라스틱서치 사용자 그룹의 HENRY 입니다.
-
형태소분석기 결과 확인
{ "tokens" : [ { "token" : "한국", "start_offset" : 0, "end_offset" : 2, "type" : "korean", "position" : 0 }, { "token" : "엘라스틱서치", "start_offset" : 3, "end_offset" : 9, "type" : "korean", "position" : 1 }, { "token" : "엘라", "start_offset" : 3, "end_offset" : 5, "type" : "korean", "position" : 1 }, { "token" : "스틱", "start_offset" : 5, "end_offset" : 7, "type" : "korean", "position" : 2 }, { "token" : "서치", "start_offset" : 7, "end_offset" : 9, "type" : "korean", "position" : 3 }, { "token" : "사용자", "start_offset" : 10, "end_offset" : 13, "type" : "korean", "position" : 4 }, { "token" : "그룹", "start_offset" : 14, "end_offset" : 16, "type" : "korean", "position" : 5 }, { "token" : "henry", "start_offset" : 18, "end_offset" : 23, "type" : "word", "position" : 6 }, { "token" : "입니다", "start_offset" : 24, "end_offset" : 27, "type" : "korean", "position" : 7 } ] }
-
형태소분석기 RESTful endpoint 실행 및 결과
실행)
http://localhost:9200/_arirang_dictionary_reload
결과)
Reloaded arirang analyzer dictionary!!
사전 데이터 수정 및 반영
이제 기본적인 arirang analyzer와 elasticsearch용 plugin 까지 살펴 보았습니다. 마지막으로 arirang analyzer의 사전 데이터 수정과 반영을 살펴 보겠습니다.
☞ arirang 에서 제공하는 기본 dictionary path 변경을 하지 않고 사전 내용만 변경 하는 것으로 하겠습니다.
1. 사전 파일에 대한 classpath 설정
-
elasticsearch 실행 시 사전 파일에 대한 classpath 등록이 되어 있어야 정상적으로 로딩이 됩니다.
-
elasticsearch.in.sh 파일을 수정해 줍니다.
ES_CLASSPATH="$ES_HOME/lib/elasticsearch-5.5.0.jar:$ES_HOME/lib/*:$ES_CONF_PATH/dictionary"
예) 위에서 언급한 사전 관련 path와 파일들이 존재해야 합니다.
config/dictionary/org/apache/lucene/analysis/ko
config/dictionary/org/apache/lucene/analysis/ko/dic
- ESCONFPATH는 기본 path.conf 정보와 동일해야 합니다.
2. 사전 정보 수정 및 반영
- 1번 path에 위치한 사전 파일을 수정합니다.
3. 사전 reload
-
elasticsearch restart 없이
/_arirang_dictionary_reload
API를 호출하여 반영 합니다.
여기까지 오셨으면 이제 arirang analyzer와 elasticseearch-analysis-arirang plugin 그리고 dictionary에 대한 기본 활용을 하실수 있게 되셨다고 생각합니다. 기술된 모든 정보는 모두 오픈소스이기 때문에 출처를 정확히 명시해 주시고 언제든지 오류와 개선에 대해서는 적극적인 참여 부탁 드립니다.
참고 사이트) http://cafe.naver.com/korlucene https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html https://www.elastic.co/guide/en/elasticsearch/plugins/current/index.html