Reindex API 사용 및 문제 해결을 위한 3가지 모범 사례


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
Elasticsearch를 사용할 때 한 인덱스에서 다른 인덱스로 데이터를 이동하거나 한 Elasticsearch 클러스터에서 다른 Elasticsearch 클러스터로 데이터를 이동하실 수 있습니다. 사용하실 수 있는 다양한 변형과 기능이 있으며, Reindex API는 그 중 하나입니다.
이 블로그 포스팅에서는, Reindex API, API가 작동하는지 여부를 알 수 있는 방법, 잠재적인 장애를 유발할 수 있는 요소 및 문제 해결 방법에 대해 논의할 예정입니다.
이 블로그 포스팅을 끝까지 읽어보시면, Reindex API의 옵션과 이를 자신 있게 실행하는 방법을 이해하게 됩니다.
Reindex API는 다음과 같은 여러 사용 사례에서 가장 유용한 API 중 하나입니다.
- 클러스터 간에 데이터 전송 (원격 클러스터에서 재색인)
- 매핑 재정의, 변경 및/또는 업데이트
- 수집 파이프라인을 통한 프로세스 및 색인
- 삭제된 문서를 제거하여 저장 공간 다시 확보
- 쿼리 필터를 통해 큰 인덱스를 더 작은 그룹으로 분할
중간 규모 또는 대규모 인덱스에서 Reindex API를 실행하면 전체 재색인에 120초가 넘게 소요될 수 있습니다. 즉, Reindex API 최종 응답이 없을 수 있습니다. 언제 완료되었는지, 잘 작동하는지, 오류가 발생했는지를 알 수가 없습니다.
한 번 살펴봅시다!
증상: Kibana 개발 도구에서 “Backend closed connection(백엔드 연결 끊김)”
중간 규모 또는 대규모 인덱스로 Reindex API를 실행하면, 클라이언트와 Elasticsearch 간의 연결이 시간 초과되지만 재색인이 실행되지 않는 것은 아닙니다.
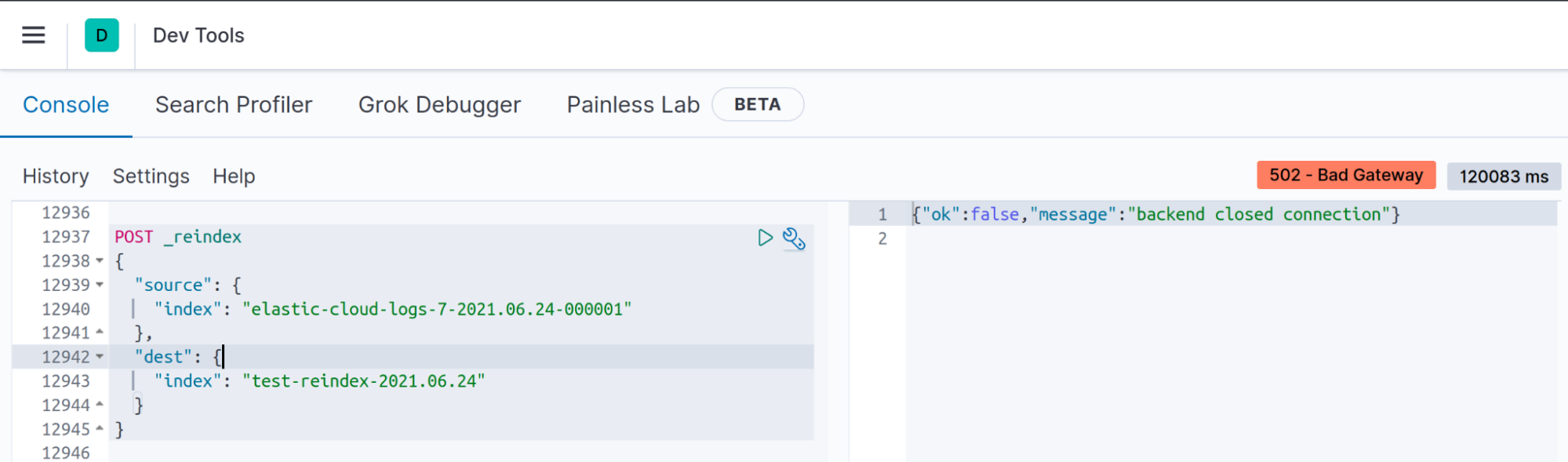
문제
예를 들어, Kibana에서 재색인 작업을 120초(v7.13의 기본 server.socketTimeout 값) 이내에 완료할 수 없는 경우 클라이언트는 N초 후에 비활성 소켓을 닫고 "backend closed connection(백엔드 연결 끊김)" 메시지를 표시합니다.
솔루션 #1 - 클러스터에서 실행 중인 작업 목록 가져오기
Kibana에 이 메시지가 있더라도 Elasticsearch는 Reindex API를 뒤에서 실행하고 있으며, 이것은 실제 문제가 아닙니다.
다음과 같이 Reindex API의 실행을 추적하고 _task API를 사용하여 모든 메트릭을 확인하실 수 있습니다.
GET _tasks?actions=*reindex&wait_for_completion=false&detailed이 API는 Elasticsearch 클러스터에서 현재 실행 중인 모든 Reindex API를 보여주게 되며, 이 목록에 Reindex API가 없으면 이미 완료되었음을 의미합니다.

이미지에서 볼 수 있듯이, 생성되거나 업데이트된 문제 또는 심지어 충돌에 대한 세부 정보가 있습니다.
솔루션 #2 - _tasks에 재색인 결과 저장
재색인 작업이 120초가 넘게(120초는 Kibana 개발 도구 시간 초과입니다) 걸릴 것임을 알고 있는 경우 쿼리 매개 변수 wait_for_completion= false를 사용하여 Reindex API 결과를 저장할 수 있습니다. 이를 통해 _task API를 사용하여 Reindex API의 끝에서 상태를 가져올 수 있습니다(wait_for_completion=false의 설명서에 설명되어 있는 대로, ".tasks" 인덱스로부터 문서를 가져올 수도 있습니다).
POST _reindex?wait_for_completion=false
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
"wait_for_completion=false"로 재색인을 실행하면 다음과 같은 응답이 됩니다.
{
"task" : "a9Aa_I_ZSl-4bjR5vZLnSA:247906"
}
재색인 결과를 검색하려면 여기에 제공된 작업을 유지하셔야 합니다(생성된 문서 수, 충돌 수 또는 오류 수가 표시되고, 완료되면 소요 시간, 배치 수 등이 표시됩니다).
GET _tasks/a9Aa_I_ZSl-4bjR5vZLnSA:247906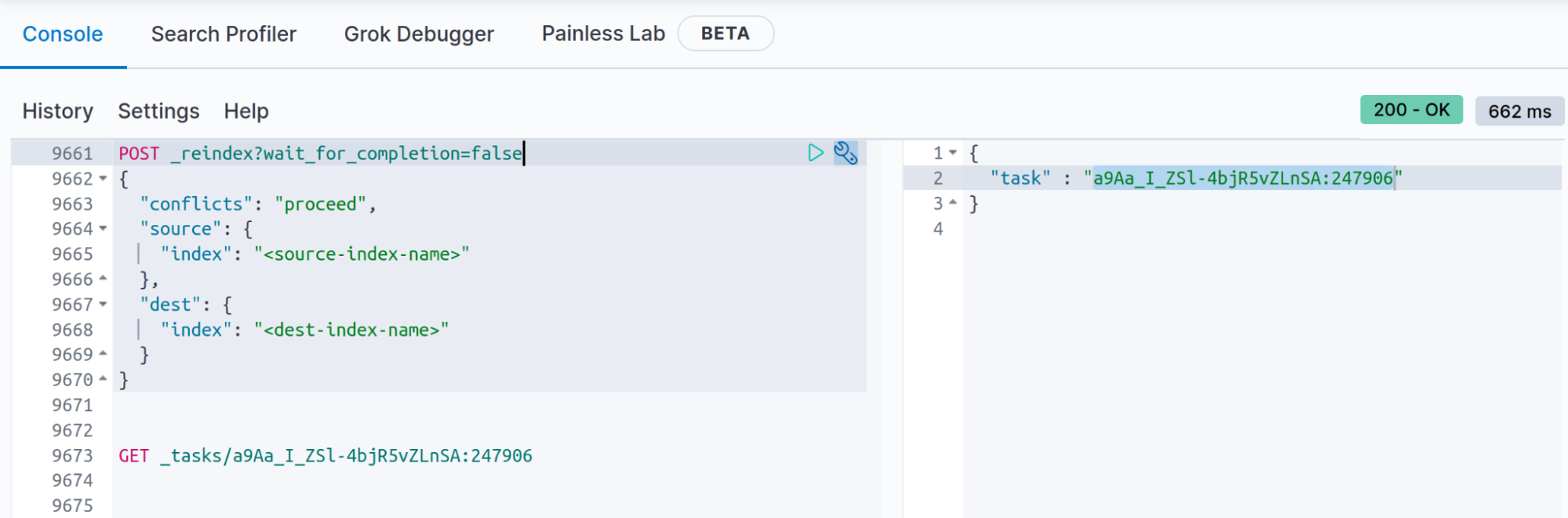
증상: Reindex API가 _task API 목록에 없음
위에 언급된 API를 사용하여 Reindex API 작업을 찾을 수 없다면 다른 문제일 수 있습니다. 하나씩 진행해 보겠습니다.
문제
Reindex API가 나열되지 않으면 재색인할 문서가 더 이상 없거나 오류가 발생하여 종료되었음을 의미합니다.
_cat count API를 사용하여 양쪽 인덱스에 저장된 문서 수를 확인합니다. 이 숫자가 동일하지 않으면 Reindex API 실행이 어떤 식으로든 실패한 것입니다.
GET _cat/count/<source-index-name>?h=count
GET _cat/count/<dest-index-name>?h=count
솔루션 #1 - 충돌 문제입니다
가장 자주 발생하는 오류 중 하나는 충돌이 있다는 것입니다. 기본적으로 Reindex API는 충돌이 있을 경우 중단됩니다.
이제 다음과 같은 두 가지 옵션이 있습니다.
- Reindex API가 색인할 수 없는 문서를 무시하고 다른 문서를 색인할 수 있도록 "충돌(conflicts)" 설정을 "진행(proceed)"으로 설정합니다.
- 또는 모든 문서를 재색인할 수 있도록 충돌을 수정할 수 있는 옵션이 있습니다.
충돌 설정이 있는 첫 번째 옵션은 다음과 같습니다.
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
또는 두 번째 옵션에서, 충돌을 일으키는 오류를 검색하고 수정합니다.
- 이 문제를 피할 수 있는 최선의 방법은 대상 인덱스에 매핑 또는 템플릿을 정의하는 것입니다. 이러한 오류의 99%는 소스 인덱스와 대상 사이에 일치하지 않는 필드 유형입니다.
- 매핑 또는 템플릿을 정의한 후에도 문제가 남아 있으면, 일부 문서를 색인할 수 없으며 기본적으로 오류가 기록되지 않습니다. 로거가 Elasticsearch 로그의 오류를 볼 수 있도록 설정해야 합니다.
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":"DEBUG"
}
}
- 로거가 활성화된 상태에서, Reindex API를 한 번 더 실행해야 합니다. 가능한 경우, 소스 인덱스와 대상 인덱스 간에 충돌이 있는 필드가 두 개 이상 있는 경우마다 "충돌(conflicts)" 설정을 "진행(proceed)"으로 설정합니다.
- 이제 Reindex API가 실행되고 있으므로, "failed to execute bulk item" 또는 "MapperParsingException" 로그를 grep/검색합니다.
failed to execute bulk item (index) index {[my-dest-index-00001][_doc][11], source[{
"test-field": "ABC"
}
또는
"org.elasticsearch.index.mapper.MapperParsingException: failed to parse field [test-field] of type [long] in document with id '11'. Preview of field's value: 'ABC'",
"at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:216) ~[elasticsearch-7.13.4.jar:7.13.4]",
이 스택 추적을 통해 우리는 이미 충돌이 무엇인지 이해할 수 있는 충분한 정보를 가지고 있고, 내 Reindex API에서 대상 인덱스는 [long] 유형의 [test-field] 필드를 가지고 있으며, Reindex API는 이 필드를 스트링 'ABC'('ABC'는 여러분만의 콘텐츠 필드로 대체됨)로 설정하려고 합니다.
Elasticsearch에서 필드 데이터 유형을 정의할 수 있으며, 인덱스를 생성하는 동안 또는 템플릿을 사용하여 이러한 필드 데이터 유형을 설정할 수 있습니다. 인덱스를 만든 후에는 유형을 변경할 수 없습니다. 먼저 대상 인덱스를 삭제한 다음, 이전에 제공된 옵션으로 새 고정 매핑을 설정해야 합니다.
- 오류를 수정한 후에는 로거를 다음과 같이 덜 상세한 모드로 이동해야 합니다.
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":NULL
}
}
솔루션 #2 - 충돌 오류가 없지만 재색인이 계속 실패합니다
재색인 실행 중이라면 Elasticsearch 로그에서 다음 추적을 찾을 수 있습니다.
'search_phase_execution_exception', 'No search context found for id [....]')
다음과 같은 다른 이유일 수 있습니다.
- 클러스터에 몇 가지 불안정성 문제가 있으며 재색인 실행 중에 일부 데이터 노드가 다시 시작되었거나 사용할 수 없습니다.
이러한 이유로 인해, 재색인을 실행하기 전에 클러스터가 안정적이고 모든 데이터 노드가 제대로 작동하는지 확인하세요. - 원격에서 재색인 작업을 수행하고 있으며, 노드 간의 네트워크가 안정적이지 않다는 것을 알고 있는 경우:
- 스냅샷 API는 (이 블로그 포스팅의 결론에 설명된 바와 같이) 훌륭한 옵션입니다.
- Reindex API를 수동으로 슬라이스할 수 있으며, 이 작업을 통해 요청 프로세스를 더 작은 부분으로 분할할 수 있게 됩니다(이 옵션은 동일한 클러스터 내에서 Reindex API를 사용하고 있는 경우입니다).
Elasticsearch 클러스터에 오버샤딩 문제, 높은 리소스 점유율 또는 가비지 컬렉션 문제가 있는 경우, 스크롤 검색 쿼리 중에 시간 초과가 발생할 수 있습니다. 기본 스크롤 시간 초과 값은 5분이므로, 더 높은 값으로 Reindex API에서 스크롤 설정을 시도할 수 있습니다.
POST _reindex?scroll=2h
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
}
}
증상: Elasticsearch 로그의 "Node not connected"(노드가 연결되지 않음)
Reindex API는 항상 안정적이고 정상적으로 작동 중인 클러스터로 실행하는 것이 좋습니다. 클러스터는 검색 및 색인 작업을 실행하기에 충분한 용량이 필요합니다.
문제
NodeNotConnectedException[[node-name][inet[ip:9300]] Node not connected]; ]
로그에 이 오류가 있으면 클러스터에 안정성 및 연결 문제가 있으며, Reindex API만 실패하는 것이 아니라는 뜻입니다.
그러나 연결 문제에 대해 알고 있지만 Reindex API를 실행해야 한다고 가정해 보겠습니다.
솔루션
연결 문제를 해결합니다.
그러나 연결 문제에 대해 알고 있지만 Reindex API를 실행해야 한다고 가정해 보겠습니다. 실패할 가능성을 줄일 수 있지만 이는 수정을 통해 해결한 것이 아니며, 다른 모든 경우에 적용되지 않습니다.
- 연결 문제가 있는 노드에서 소스 또는 대상 인덱스(기본 또는 복제본)의 샤드를 이동합니다. 할당 필터링 API를 사용하여 샤드를 이동합니다.
- 대상 인덱스의(대상 인덱스에서만) 복제본을 제거할 수도 있으며, 이를 통해 Reindex API 속도가 빨라지고, 재색인이 더 빨리 실행되면 오류가 발생할 가능성이 줄어듭니다.
PUT /<dest-index-name>/_settings
{
"index" : {
"number_of_replicas" : 0
}
}
이 두 작업을 통해 성공적으로 Reindex API를 얻을 수 없는 경우, 먼저 안정성 문제를 해결해야 합니다.
증상: 로그에 오류는 없지만 두 인덱스의 문서 수가 일치하지 않음
때때로 Reindex API가 완료되었지만 소스의 문서 수가 대상과 일치하지 않을 수 있습니다.
문제
하나의 대상에서 여러 소스로부터 재색인을 시도하는 경우(하나에 여러 인덱스를 병합), 해당 문서들에 할당한 _id가 문제가 될 수 있습니다.
다음과 같은 2개의 소스 인덱스가 있다고 가정해 보세요.
- _id: 1과 메시지: "Hello A"가 있는 인덱스 A
- _id: 1과 메시지: "Hello B"가 있는 인덱스 B
C에서 두 인덱스의 병합은 다음과 같게 됩니다.
- _id: 1과 메시지: "Hello B"가 있는 인덱스 C
두 문서 모두 동일한 _id를 가지고 있기 때문에, 색인된 마지막 문서는 이전 문서보다 우선하게 됩니다.
솔루션
수집 파이프라인과 같은 다른 옵션이 있거나 Reindex API에서 painless를 사용합니다. 이 블로그 포스팅의 경우, 요청 본문에 “painless”가 있는 스크립트 옵션을 사용합니다.
정말 간단합니다. 다음과 같이 original _id를 사용하고 소스 인덱스 이름을 추가하겠습니다.
POST _reindex
{
"source": {
"index": "<source-index-name>"
},
"dest": {
"index": "<dest-index-name>"
},
"script": {
"source": "ctx._id = ctx._id + '-' + ctx._index;"
}
}
앞의 예를 들어 보면, 다음과 같습니다.
- _id: 1과 메시지: "Hello A"가 있는 인덱스 A
- _id: 1과 메시지: "Hello B"가 있는 인덱스 C
C에서 두 인덱스의 병합은 다음과 같게 됩니다.
- _id: 1-A와 메시지: "Hello A"가 있는 인덱스 C
- _id: 1-B와 메시지: "Hello B"가 있는 인덱스 C
결론
Reindex API는 일부 필드의 형식을 변경해야 할 때 유용한 옵션입니다. Reindex API가 가능한 한 원활하게 작동할 수 있도록 하는 몇 가지 주요 측면을 소개해 드립니다.
- 대상 인덱스에 대한 매핑(또는 템플릿)을 만들고 정의합니다.
- 대상 인덱스를 조정하여 Reindex API가 문서를 최대한 빠르게 색인할 수 있도록 합니다. 인덱세이션을 조정하고 속도를 높일 수 있는 모든 옵션이 포함된 설명서 페이지가 있습니다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html - 소스 인덱스의 크기가 중간 규모 또는 대규모인 경우, "wait_for_completion=false" 설정을 정의하여 _tasks API에 Reindex API 결과가 저장되도록 합니다.
- 인덱스를 더 작은 그룹으로 분할합니다. 쿼리(범위, 단어 등)를 사용하여 다른 그룹을 정의하거나 슬라이싱 기능을 사용하여 요청을 더 작은 부분으로 분할할 수 있습니다.
- Reindex API를 실행할 때 안정성이 중요합니다. Reindex API와 관련된 인덱스는 정상적인 작동 상태여야 합니다(최악의 경우, 노란색 상태). 그런 다음 데이터 노드에서 GarbageCollections가 길지 않고 CPU 및 디스크 사용량이 정상 값인지 확인합니다.
v7.11 이래로, 데이터를 재색인할 필요가 없는 새로운 기능을 출시했으며, 이 기능을 "런타임 필드"라고 합니다. 이 API를 사용하면 인덱스 매핑에서 또는 검색 요청에서 런타임 필드를 정의할 수 있으므로 데이터를 다시 색인할 필요 없이 오류를 수정할 수 있습니다. 두 가지 옵션을 모두 사용하면 수집 후 문서의 스키마를 변경하고 검색 쿼리의 일부로만 존재하는 필드를 생성할 수 있게 됩니다.
런타임 필드 기능의 좋은 예는 매핑에 이미 존재하는 필드와 동일한 이름의 런타임 필드를 만드는 기능입니다. 런타임 필드는 매핑된 필드를 긴밀히 따르며, 테스트하려면 여기에서 제공되는 단계를 따르시기만 하면 됩니다.
런타임 필드에 대한 자세한 내용은 Elastic의 설명서나 시작하기 블로그 포스팅에서 확인하실 수 있습니다.
클러스터 간에 데이터를 이동하려는 경우, 스냅샷-복구 API를 사용하실 수 있습니다. 스냅샷을 사용하면, 클러스터가 데이터를 검색한 다음 재색인할 필요가 없으므로 데이터를 더 빠르게 옮길 수 있습니다. 두 클러스터 모두 동일한 스냅샷 리포지토리에, 스냅샷 API에 대한 자세한 정보에 액세스할 수 있어야 합니다.
지금까지 재색인 관련 자주 묻는 질문과 일반적인 오류 해결 방법에 대해 다루었습니다. 현재 문제를 해결하는 데 어려움을 겪고 계시다면, 언제든지 연락하시기 바랍니다. Elastic이 기꺼이 도와드리겠습니다! Elastic 토론 게시판, Elastic 커뮤니티 Slack, 컨설팅, 교육 및 지원을 통해 연락하실 수 있습니다.
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기