Modèles Jina AI
Modèles de pointe pour chaque étape du pipeline de récupération
Conçus pour la recherche, les modèles Jina offrent précision et rapidité surpassant les modèles cinq fois plus volumineux. Multilingue, multimodal natif (texte, images, audio et vidéo) sur Elasticsearch.

Découvrez les modèles Jina AI
Nos modèles de pointe constituent la base de recherche pour des systèmes de recherche d'entreprise et de Retrieval-Augmented Generation (RAG) de haute qualité.



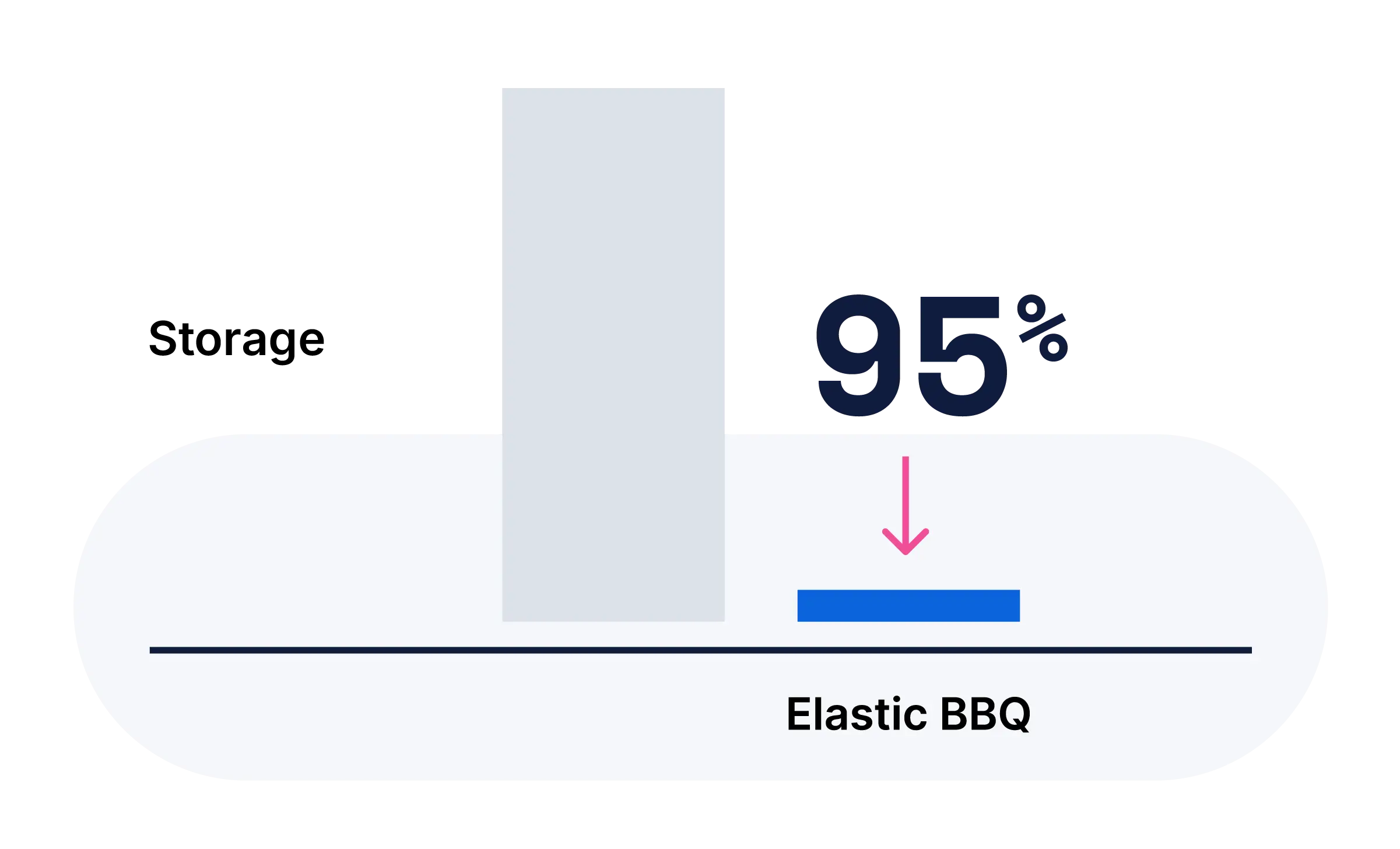
Compact par conception, précis dans les résultats
Passez des données brutes à des résultats de haute précision avec une seule API.

Utilisez les modèles Jina partout où vous développez
De la gestion complète à l’auto-hébergement, les modèles Jina s’adaptent à vos données. Choisissez l’accès qui vous convient.



Nos recherches




Rejoignez notre communauté open source
Les modèles de Jina sont en accès libre et disponibles gratuitement sur Hugging Face, avec des millions de téléchargements mensuels. Le code source est public sur GitHub. La communauté a un accès direct à nos développeurs.

Accédez à nos modèles pour les embeddings, les rerankers et les petits modèles de langage pour mieux rechercher.



Questions fréquentes
Qu'est-ce que les modèles de recherche Jina ?
Qu'est-ce que les modèles de recherche Jina ?
Les modèles Jina sont des modèles d'IA d'avant-garde open source pour la recherche documentaire. Ils comprennent des modèles d'intégration pour les vecteurs, des modèles de repositionnement pour la précision et des lecteurs pour l'extraction et la structuration du contenu des URL et des documents.
Ai-je besoin d’une expertise en IA ou en machine learning pour les utiliser ?
Ai-je besoin d’une expertise en IA ou en machine learning pour les utiliser ?
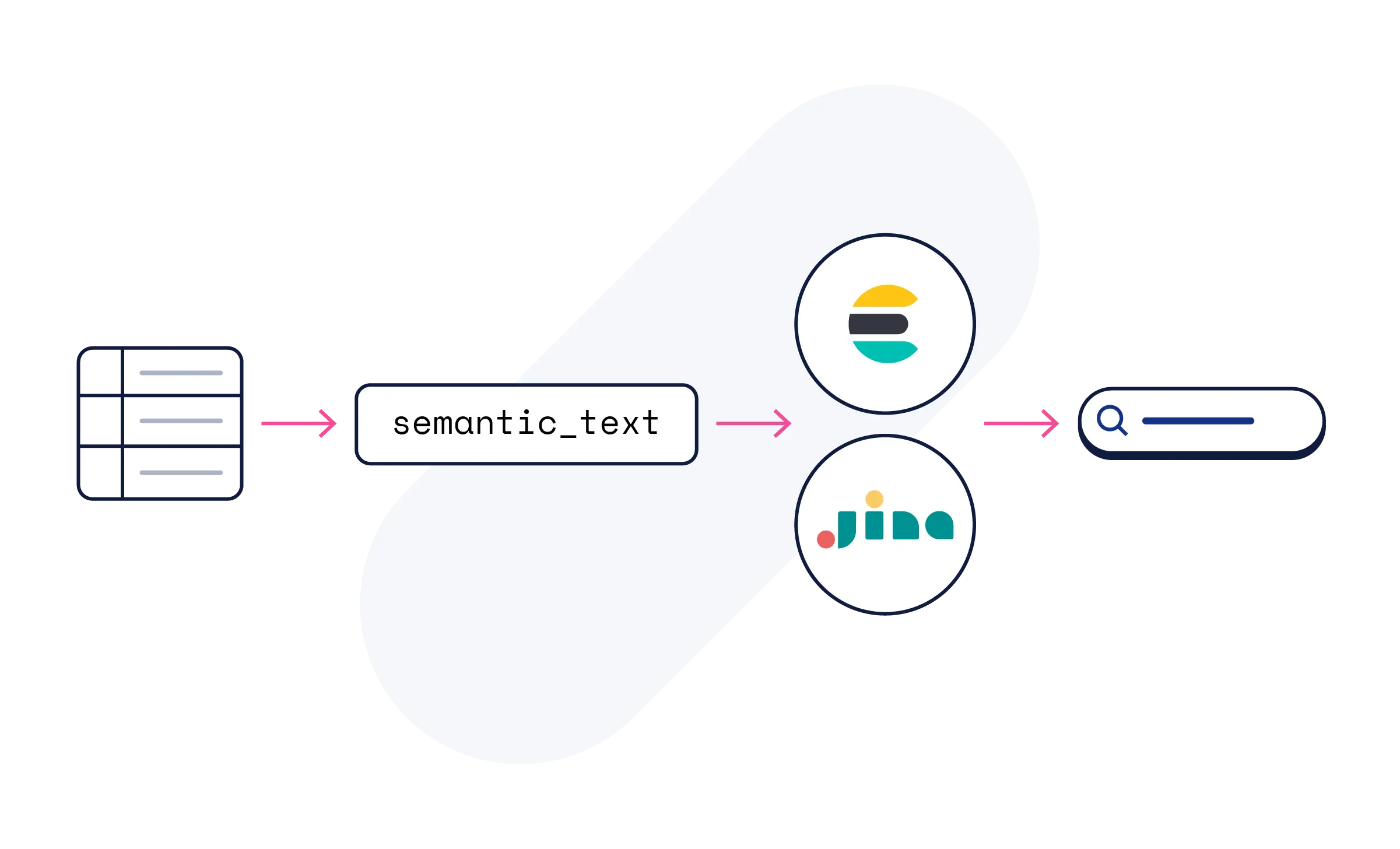
Non. Utilisez le champ semantic_text d'Elasticsearch, et le traitement de l'IA se fait automatiquement. Les modèles de Jina rendent votre contenu sémantiquement consultable — aucune configuration de modèle ou expertise ML n'est requise.
Comment puis-je me lancer ?
Comment puis-je me lancer ?
Les modèles Jina sont disponibles sur Elastic Inference Service sur Elastic Cloud, inclus dans tous les essais. Commencez par semantic_text, ou explorez les sous-pages de modèles pour des exemples de code, des références API et des tutoriels.
Quels modèles Jina sont disponibles aujourd’hui ?
Quels modèles Jina sont disponibles aujourd’hui ?
Notre dernière version v5-text (nano/small) comprend la fonctionnalité 32K de contexte, des dimensions Matryoshka et la dernière architecture — ainsi que Jina-embeddings-v3 et Reranker v2 et v3 — tous disponibles sur Elastic Inference Service.
Combien de langues sont prises en charge ?
Combien de langues sont prises en charge ?
Jina-embeddings-v5-text prend en charge plus de 30 langues — une requête dans une langue trouve du contenu pertinent écrit dans une autre, sans qu’aucun pipeline de traduction ne soit nécessaire.
Comment cela se rapporte à ELSER ?
Comment cela se rapporte à ELSER ?
ELSER prend en charge la recherche sémantique en anglais. Jina ajoute une couverture multilingue sur plus de 30 langues avec une précision optimale — les deux fonctionnent au sein du framework de rechercher hybride d’Elasticsearch.
S'agit-il d'un produit distinct ?
S'agit-il d'un produit distinct ?
Non. Les modèles de recherche Jina sur Elastic Inference Service sont disponibles pour tous les utilisateurs d'Elastic Cloud avec une tarification basée sur la consommation. Aucune licence, aucun abonnement ou clé API distinct n'est requis.
Comment cela se rapporte-t-il à la page de la base vectorielle d'Elastic ?
Comment cela se rapporte-t-il à la page de la base vectorielle d'Elastic ?
La page sur la base vectorielle explique comment les vecteurs sont stockés et recherchés à grande échelle. Cette page décrit les modèles d'IA qui les génèrent et les réorganisent. Ensemble : stockage, calcul et application.