¿Qué son las incrustaciones de palabras?
Definición de incrustación de palabras
La incrustación de palabras es una técnica usada en el procesamiento de lenguaje natural (NLP) que representa palabras como números para que una computadora pueda trabajar con ellas. Es un enfoque popular para las representaciones numéricas de texto aprendidas.
Como las máquinas necesitan asistencia con cómo manejar las palabras, cada palabra debe asignarse a un formato de número para que pueda procesarse. Esto puede hacerse a través de algunos enfoques diferentes:
- La codificación one-hot (en caliente) le asigna a cada palabra en el cuerpo de un texto un número único. Este número se convierte en un vector binario (usando ceros y unos) que representa la palabra.
- La representación basada en el recuento cuenta la cantidad de veces que aparece una palabra en el cuerpo de un texto y le asigna un vector correspondiente.
- La combinación SLIM usa estos dos métodos para que una computadora pueda comprender tanto el significado de las palabras y con qué frecuencia aparecen en el texto.
La incrustación de palabras crea un espacio de alta dimensionalidad en el que a cada palabra se le asigna un vector denso (veremos más al respecto a continuación) de números. Una computadora puede luego usar estos vectores para comprender las relaciones entre las palabras y hacer predicciones.
¿Cómo funciona la incrustación de palabras en el procesamiento de lenguaje natural?
La incrustación de palabras funciona en el procesamiento de lenguaje natural representando palabras como vectores densos de números reales en un espacio de alta dimensionalidad, potencialmente con hasta 1000 dimensiones. La vectorización es el proceso de convertir palabras en vectores numéricos. Un vector denso es un vector en el que la mayoría de las entradas son distintas de cero. Es lo opuesto a un vector disperso, como la codificación one-hot, que tiene muchas entradas cero. Este espacio de alta dimensionalidad se denomina el espacio de incrustación.
A las palabras con significados similares o se usan en contextos similares se les asignan vectores similares, lo que significa que están ubicados cerca entre sí en el espacio de incrustación. Por ejemplo, "té" y "café" son palabras similares que estarían ubicadas una cerca de la otra, mientras que "té" y "sé" estarían más apartadas, porque sus significados no son similares y no suelen usarse juntas con frecuencia, a pesar de que se escriben de forma similar.
Si bien hay distintos métodos para crear incrustaciones de palabras en el procesamiento de lenguaje natural, todos involucran entrenamiento con grandes cantidades de datos de texto, lo que se llama corpus. El corpus puede variar; Wikipedia y Google Noticias son dos ejemplos comunes que se usan para preentrenar corpus de integración.
El corpus también puede ser una capa de incrustación personalizada, diseñada específicamente para los casos de uso, cuando otro corpus preentrenado no puede suministrar datos suficientes. Durante el entrenamiento, el modelo aprende a asociar cada palabra con un vector único basado en los patrones de uso de la palabra en esos datos. Estos modelos se pueden usar para transformar palabras de cualquier dato de texto nuevo en vectores densos.
¿Cómo se realizan las incrustaciones de palabras?
Las incrustaciones de palabras pueden hacerse usando una variedad de técnicas. La elección de la técnica depende de los requisitos específicos de la tarea. Debes tener en cuenta el tamaño del set de datos, el dominio de los datos y la complejidad del lenguaje. Así es como funcionan algunas de las técnicas de incrustación de palabras más populares:
- Word2vec es un algoritmo basado en red neuronal de dos capas que recibe un corpus de texto y genera un conjunto de vectores (de allí el nombre). Un ejemplo de Word2vec usado comúnmente es "rey - hombre + mujer = reina". Al reducir la relación entre "rey" y "hombre", y entre "hombre" y "mujer", el algoritmo puede identificar "reina" como la palabra correspondiente adecuada para "rey". Word2vec se entrena usando los algoritmos Skip-Gram o Continuous Bag of Words (CBOW). Skip-Gram intenta predecir las palabras del contexto a partir de una palabra objetivo. Continuous Bag of Words funciona del modo opuesto, predice la palabra objetivo usando el contexto de las palabras que la rodean.
- GloVe (Global Vectors) se basa en la idea de que el significado de una palabra puede inferirse mediante su coocurrencia con otras palabras en un corpus de texto. El algoritmo crea una matriz de coocurrencia que captura la frecuencia con la que aparecen juntas las palabras en el corpus.
- fasText es una extensión del modelo Word2vec y se basa en la idea de representar palabras como una bolsa de n-gramas de caracteres o unidades de subpalabras, en lugar de como palabras individuales solamente. Usando un modelo similar a Skip-Gram, fasText captura información sobre la estructura interna de las palabras que lo ayuda a procesar vocabulario nuevo y desconocido.
- ELMo (Embeddings from Language Models) es distinto a las incrustaciones de palabras como las mencionadas antes porque usa una red neuronal profunda que analiza el contexto completo en el que aparece la palabra. Esto le permite detectar matices sutiles de significado que otras técnicas de incrustación pueden pasar por alto.
- TF-IDF (frecuencia del término - frecuencia inversa de documento) es un valor matemático determinado por la multiplicación de la frecuencia del término (TF) por la frecuencia inversa de documento (IDF). La TF se refiere a la proporción de términos objetivo en el documento en comparación con el total de términos en el documento. La IDF es un logaritmo de la proporción de los documentos totales y la cantidad de documentos que contienen el término objetivo.
¿Cuáles son las ventajas de las incrustaciones de palabras?
Las incrustaciones de palabras ofrecen varias ventajas sobre los enfoques tradicionales para representar palabras en el procesamiento de lenguaje natural. La incrustación de palabras se ha convertido en un enfoque estándar en el NLP, con muchas incrustaciones preentrenadas disponibles para su uso en varias aplicaciones. Esta amplia disponibilidad ha facilitado para los investigadores y desarrolladores incorporarlas en sus modelos sin tener que entrenarlas desde cero.
La incrustación de palabras se ha usado para mejorar el modelado de lenguaje, que es la tarea de predecir la palabra siguiente en una secuencia de texto. Al presentar las palabras como vectores, los modelos pueden capturar mejor el contexto, en el que una palabra aparece y hace predicciones más precisas.
Crear incrustaciones de palabras puede ser más rápido que las técnicas de ingeniería tradicionales, porque el proceso de entrenar una red neuronal con un corpus grande de datos de texto no tiene supervisión, lo que ahorra tiempo y esfuerzo. Una vez entrenada la incrustación, se puede usar como características de entrada para un amplio rango de tareas de NLP sin la necesidad de realizar ingeniería adicional de características.
Las incrustaciones de palabras suelen tener una dimensionalidad mucho más baja que los vectores codificados one-hot. Esto significa que requieren menos memoria y recursos informáticos para almacenamiento y manipulación. Como la incrustación de palabras es una representación de vectores densa de palabras, representa palabras de forma más eficiente que las técnicas de vectores dispersos. Esto le permite capturar mejor las relaciones semánticas entre las palabras.
¿Cuáles son las desventajas de las incrustaciones de palabras?
Si bien las incrustaciones de palabras tienen muchas ventajas, también hay algunas desventajas que vale la pena considerar.
Entrenar las incrustaciones de palabras puede ser costoso en términos informáticos, en especial al usar grandes sets de datos o modelos complejos. Las incrustaciones preentrenadas también pueden requerir un importante espacio de almacenamiento, lo que puede resultar ser un problema para las aplicaciones con recursos limitados. Las incrustaciones de palabras se entrenan con un vocabulario finito; es decir que es posible que no puedan representar palabras que no están incluidas en dicho vocabulario. Esto puede ser un problema para los idiomas con un gran vocabulario o para terminología específica para la aplicación.
Si las entradas de datos para la incrustación de una palabra contienen sesgos, la incrustación de la palabra puede reflejar esos sesgos. Por ejemplo, las incrustaciones de palabras pueden codificar sesgos de género, raza u otros estereotipos, y esto puede tener consecuencias en situaciones de la vida real en las que se usen.
Las incrustaciones de palabras suelen considerarse una caja negra porque sus modelos subyacentes, como las redes neuronales de GloVe o Word2Vec, son complejos y difíciles de interpretar.
Una incrustación de palabra es solo tan buena como sus datos de entrenamiento. Es importante asegurarse de que los datos sean suficientes para que la incrustación de palabras los use en la práctica. Mientras que las incrustaciones de palabras captan la relación general entre las palabras, es posible que se pierdan de ciertos matices humanos, como el sarcasmo, que son más difíciles de reconocer.
Como una incrustación de palabra asigna un vector a cada palabra, puede tener problemas con los homógrafos, que son palabras que se escriben igual, pero tienen distintos significados. (Por ejemplo, la palabra "nada", que puede significar ninguna cosa o referirse a la conjugación del verbo nadar).
¿Por qué se usan las incrustaciones de palabras?
Las incrustaciones de palabras se usan para habilitar la búsqueda de vectores. Son esenciales para las tareas de procesamiento de lenguaje natural, como análisis de sentimiento, clasificación de texto y traducción de idiomas. Las incrustaciones de palabras proporcionan una ruta efectiva para que las máquinas reconozcan y capturen las relaciones semánticas entre las palabras. Esto hace que los modelos de NLP sean más precisos y eficientes que con la ingeniería de características manual. Por lo tanto, el resultado final es más accesible y efectivo para los usuarios.
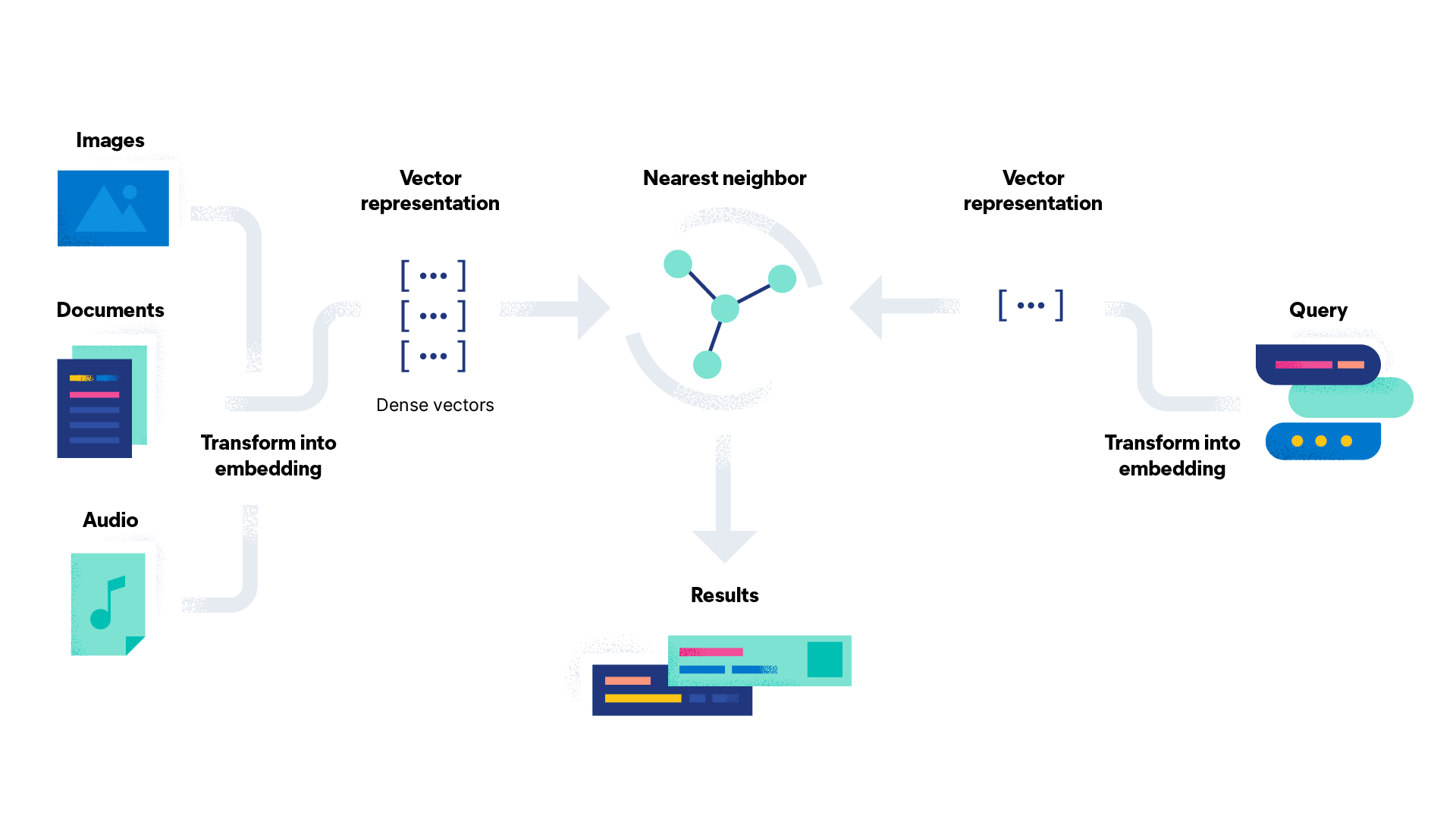
La incrustación de palabras se puede usar para una variedad de tareas. Estos son algunos casos de uso de incrustación de palabras:
- Análisis de sentimiento: el análisis de sentimiento categoriza un fragmento de texto como positivo, negativo o neutral con la incrustación de palabras. Las empresas suelen usar el análisis de sentimiento para analizar comentarios sobre sus productos hechos en reseñas y publicaciones de redes sociales.
- Sistemas de recomendación: los sistemas de recomendación sugieren productos o servicios a los usuarios basándose en sus interacciones anteriores. Por ejemplo, un servicio de streaming puede usar incrustaciones de palabras para recomendar nuevos títulos basados en el historial de visualización de un usuario.
- Chatbots: los chatbots se comunican con los clientes usando procesamiento de lenguaje natural para generar respuestas apropiadas a las consultas de los usuarios.
- Motores de búsqueda: la búsqueda de vectores se usa en los motores de búsqueda para mejorar la precisión de los resultados. Usa las incrustaciones de palabras a fin de analizar las búsquedas del usuario en comparación con el contenido de las páginas web para crear mejores coincidencias.
- Contenido original: el contenido original se crea transformando los datos en lenguaje natural legible. La incrustación de palabras puede aplicarse a un amplio rango de tipos de contenido, desde descripciones de producto hasta reportes deportivos posteriores a los encuentros.
Da los primeros pasos con las incrustaciones de palabras y la búsqueda de vectores con Elasticsearch
Elasticsearch es un motor de analítica y búsqueda distribuido, gratuito y abierto para todos los tipos de datos, incluidos los análisis de texto estructurados y no estructurados. Almacena de forma segura tus datos para una búsqueda rápida, relevancia ajustada y analíticas poderosas que escalan de forma eficiente. Elasticsearch es el componente principal del Elastic Stack, un conjunto de herramientas gratuitas y abiertas para la ingesta, el enriquecimiento, el almacenamiento, el análisis y la visualización de datos.
Elasticsearch te ayuda a lo siguiente:
- Mejorar las experiencias de los usuarios y aumentar las conversiones
- Habilitar nueva información, automatización, analíticas y reportes
- Aumentar la productividad de los empleados en las aplicaciones y los documentos internos
Recursos de incrustación de palabras
- Cómo desplegar NLP: Incrustaciones de texto y búsqueda de vectores
- Cinco razones por las que los líderes de TI necesitan búsqueda de vectores para mejorar su experiencia de búsqueda
- Búsqueda por similitud de texto con campos de vectores
- How to deploy a text embedding model and use it for semantic search (Cómo desplegar un modelo de incrustación de texto y usarlo para la búsqueda semántica)