¿Qué estás respirando? Análisis de la calidad del aire con Elastic Cloud (parte 1)
El Elastic Stack ha probado que está más que a la altura de las tareas de recolección, indexación y provisión de información reveladora a partir de los datos. La administración de la información integrada no solo es posible, sino que incluso, como veremos en la siguiente serie de blogs, puede ser una misión muy agradable. Vamos a recorrer todo el trayecto desde los datos sin procesar y sin sentido, hasta conclusiones que cualquier habitante de una ciudad moderna puede usar en beneficio de su vida cotidiana.
En muchas ciudades del mundo, la creciente población presenta numerosos desafíos. Entre ellos, es probable que la contaminación del aire sea el que tiene un mayor efecto en la salud de quienes habitan estas ciudades. En un esfuerzo por alertar a los ciudadanos y tomar medidas de emergencia, algunas instituciones públicas han desplegado campos de sensores que recopilan información sobre la concentración de diferentes contaminantes en toda la ciudad.
Dado que estas mediciones son responsabilidad de las instituciones públicas, no es raro que se publiquen para que cualquier persona pueda usarlas. Tal es el caso de las muestras tomadas en la tercera ciudad más grande de Europa (en población, con más de tres millones de habitantes): Madrid.
Veamos lo fácil que es utilizar Elasticsearch para hacer que estas mediciones químicas, que de otra forma parecerían confusas, hablen de las costumbres de los habitantes de Madrid.
De archivos CSV a documentos de Elasticsearch
En primer lugar, debemos echar un vistazo al origen de los datos. El Ayuntamiento de Madrid mantiene un Portal de datos abiertos donde se puede encontrar el conjunto de datos sobre las mediciones de la calidad del aire por hora (en español).
Allí también se puede encontrar un punto final HTTP que funciona como archivo CSV, que se actualiza cada hora y contiene las mediciones hasta la última hora del día presente.
Cada fila del archivo corresponde a un par de claves (estación, magnitud) y contiene las mediciones hora por hora para un día completo. El valor de cada hora se captura en una columna.
| ... | ESTACIÓN | QUÍMICO | ... | MES | DÍA | 0 a. m. Medición | 0 a. m. ¿Es válida? | ... | 11 p. m. Medición | 11 p. m. ¿Es válida? |
| Número (Código) | Código (Código) | Número | Número | Número | "V" o "F" (verdadero/falso) | Número | "V" o "F" (verdadero/falso) |
Los campos tales como ESTACIÓN y QUÍMICO están dados como valores numéricos asociados con las posiciones geográficas y la formulación del compuesto, respectivamente. Esa asociación se provee mediante tablas presentes en el sitio de origen de los datos.
Por otro lado, las medidas horarias (i-th a. m./p. m. Medición) y los indicadores que señalan si son válidas (i-th a. m./p. m. ¿Es válida?) se dan como valores sin procesar. Otra tabla de la especificación de origen proporciona las unidades, mientras que el indicador de validación puede tomar los valores "V" o "F" que representan las palabras "verdadero" y "falso".
Los resultados de las muestras químicas se representan como mediciones en tiempo y en espacio. ¿Te suena? Así es: ¡una serie temporal de eventos espaciales! Eso significa que las filas no son eventos. Por el contrario, se recopilan hasta 24 eventos en cada fila, y todos ellos comparten la misma ubicación y el mismo compuesto químico.
Si codificamos cada uno de los eventos como un documento JSON, se verían como el siguiente ejemplo:
{
"timestamp": 1532815200000,
"location": {
"lat": 40.4230897,
"lon": -3.7160478
},
"measurement": {
"value": 7,
"chemical": "SO2",
"unit": "μg/m^3"
}
}
Tenemos la opción de enriquecerlo fácilmente con los límites de la Organización Mundial de la Salud (OMS), tan solo agregando un campo adicional dentro del subdocumento de medición. Desglosar cada fila del CSV en documentos JSON separados hace que estos datos sean más fáciles de entender e incluso más fáciles de ingestar en Elasticsearch.
{
"timestamp": 1532815200000,
"location": {
"lat": 40.4230897,
"lon": -3.7160478
},
"measurement": {
"value": 7,
"chemical": "SO2",
"unit": "μg/m^3",
"who_limit": 20
}
}
El conjunto de todos los documentos que coinciden con esta estructura se puede describir a través de otro documento JSON. Este es un mapping en Elasticsearch que utilizaremos para describir cómo se almacenan los documentos en un determinado índice.
{
"air_measurements": {
"properties": {
"timestamp": {
"type": "date"
},
"location": {
"type": "geo_point"
},
"measurement": {
"properties": {
"value": {
"type": "double"
},
"who_limit": {
"type": "double"
},
"chemical": {
"type": "keyword"
},
"unit": {
"type": "keyword"
}
}
}
}
}
}
Despliega un cluster en segundos en Elastic Cloud
En este punto, puedes configurar un cluster de Elasticsearch a nivel local, o bien comenzar una prueba gratuita de 14 días de Elasticsearch Service en Elastic Cloud. Descubre cómo activar un nuevo cluster con unos pocos clicks. Para esta demostración, utilizaré Elastic Cloud.
Una vez que inicies sesión en Elastic Cloud, tendrás que desplegar un nuevo cluster. Para dimensionar el cluster para este caso de uso, debemos considerar que un archivo JSON con un mes de eventos de medición ocupa alrededor de 34 MB de espacio en disco (antes de la indexación), por lo que podemos utilizar el cluster más pequeño disponible (1 GB de RAM/24 GB de espacio en disco). Este pequeño cluster debería ser suficiente para hospedar nuestros datos en un principio. Elastic Cloud facilita el escalado, por lo que, si es necesario, siempre podemos aumentar este tamaño más adelante, al igual que podemos cambiar la cantidad de zonas de disponibilidad o llevar a cabo otros cambios en nuestro cluster.
En menos tiempo del que lleva cocinar una comida en el microondas, tendremos nuestro cluster de Elasticsearch listo para recibir e indexar nuestra colección de eventos de medición.
Extrae, transforma y carga
Pasar los datos del archivo CSV original a una colección de documentos JSON que codifican las mediciones no es una tarea que a alguien le gustaría hacer manualmente (a decir verdad, suena como el castigo de Sísifo). Es una tarea que debe automatizarse.
Para ello, comencemos por redactar un script de automatización para aplanar la tabla CSV en documentos JSON. Para hacerlo, utilicemos Scala:
- Como un lenguaje que permite centrarse en el flujo de datos en lugar de en el flujo del programa, ofrece operaciones para transformar colecciones de documentos con facilidad.
- Incluye numerosas bibliotecas de manipulación de archivos JSON.
- Gracias a Ammonite, es posible escribir scripts de manipulación de datos en un abrir y cerrar de ojos.
El siguiente fragmento del script extractor.sc condensa la lógica de la transformación:
// Obtén el archivo del portal de datos abiertos del Ayuntamiento de Madrid
lazy val sourceLines = scala.io.Source.fromURL(uri).getLines().toList
sourceLines.headOption foreach { head =>
/* La primera línea del archivo CSV contiene las etiquetas de las columnas; no es difícil
calcular un mapa de una etiqueta a una posición, lo que hace que el resto del código sea
más legible. */
lazy val label2pos = head.split(";").zipWithIndex.toMap
// For each line, we'll produce several events, that's easilt via flatMap
lazy val entries = sourceLines.tail flatMap { rawEntry =>
val positionalEntry = rawEntry.split(";").toVector
val entry = label2pos.mapValues(positionalEntry)
/* Las primeras 8 posiciones se utilizan para extraer la información común en las
24 medidas horarias. */
val stationId = entry("ESTACION").toInt
val ChemicalEntry(chemical, unit, limit) = chemsTable(entry("MAGNITUD").toInt)
// Los valores de las mediciones se incluyen en las últimas 24 columnas
positionalEntry.drop(8).toList.grouped(2).zipWithIndex collect {
case (List(value, "V"), hour) =>
val timestamp = new DateTime(
entry("ANO").toInt,
entry("MES").toInt,
entry("DIA").toInt,
hour, 0, 0
)
// Y ahí está: ¡se generó el evento como una clase de caso!
Entry(
timestamp,
location = locations(stationId),
measurement = Measurement(value.toDouble, chemical, unit, limit)
)
}
}
- Obtén el último informe horario publicado, que contiene las mediciones hechas hasta hace una hora.
- Para cada fila:
- Extrae los campos comunes a todos los eventos generados a partir de la fila: ID de estación y químico medido.
- Extrae las mediciones que corresponden a las que se tomaron hasta ese momento durante el día (hasta 24). Filtra aquellas que no están etiquetadas como mediciones válidas.
- Para cada una, genera la marca de tiempo de medición, compuesta por la fecha de la fila y el número de columna de la medición. Combina los campos comunes de la fila, la marca de tiempo y el valor registrado en un objeto de evento único (Entrada).
El script continúa serializando los objetos de Entrada como documentos JSON e imprimiéndolos como una sucesión de archivos JSON independientes.
Extractor.sc puede recibir argumentos que le indiquen que debe obtener los datos para transformarlos de otras fuentes, tales como archivos locales, o para agregar las acciones requeridas por la API de bulk de Elasticsearch al cargar archivos de un día completo a la vez.
extractor --uri String (default http://www.mambiente.munimadrid.es/opendata/horario.csv) --bulkIndex --bulkType
Carga tus datos en Elasticsearch
Así que acabamos de recibir un script que traduce los archivos CSV en listas de documentos. ¿Cómo podemos indexarlos? Es fácil: solo tenemos que hacer un par de llamadas a nuestro cluster.
Creación de índices
Primero lo primero: tenemos que crear el índice. Ya creamos un JSON para nuestros mappings de documentos y lo podemos anidar dentro de nuestra definición de índice: ./payloads/index_creation.json
{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"air_measurements" : {
"properties" : {
"timestamp": { "type": "date" },
"location" : { "type" : "geo_point" },
"measurement": {
"properties": {
"value": { "type": "double" },
"who_limit": { "type": "double" },
"chemical": { "type": "keyword" },
"unit": { "type": "keyword" }
}
}
}
}
}
}
Luego, lo enviamos al punto final de creación de índices de nuestro cluster:
curl -u "$ESUSER:$ESPASS" -X PUT -H 'Content-type: application/json' \
"$ESHOST/airquality" \
-d "@./payloads/index_creation.json"
Después de eso, terminaremos con el índice de calidad del aire.
Carga masiva
La forma más rápida de cargar todos esos datos en Elasticsearch es con la API de bulk. La idea es establecer una conexión, cargar un paquete de documentos y finalizar la operación. Si cargáramos un documento a la vez, tendríamos que establecer una conexión TCP, enviar el documento, recibir confirmación y cerrar la conexión para cada medición en cada fila del archivo CSV. Y eso nos parece muy poco eficiente.
A medida que se establece la documentación de la API de bulk, deberás cargar un archivo NDJSON con dos líneas por documento:
- una con la acción que debe llevarse a cabo en Elasticsearch,
- y otra con el documento al cual afecta esa acción. La acción que nos interesa es la indexación.
Entonces, extractor.sc incluye dos opciones adicionales para controlar la acción de indexación y su apariencia justo antes de cada documento:
- ÍNDICE bulkIndex: si pasa, hace que el script de extracción preceda a cada documento por un índice en la acción de INDEXACIÓN.
- TIPO bulkType: si pasa después de bulkIndex, completa la acción con el tipo de índice con el que el documento debe coincidir.
/* La colección de eventos se serializa y se imprime en la salida estándar.
De esa manera, podemos utilizarlos como un archivo ndjson.
*/
val asJsonStrings = entries flatMap { (entry: Entry) =>
Some(bulkIndex).filter(_.nonEmpty).toList.map { index =>
val entryId = {
import entry._
val id = s"${timestamp}_${location}_${measurement.chemical}"
java.util.Base64.getEncoder.encodeToString(id.getBytes)
}
/* Otra opción es serializar las acciones masivas para mejorar el rendimiento de la transferencia
de datos. */
BulkIndexAction(
BulkIndexActionInfo(
_index = index,
_id = entryId,
_type = Some(bulkType).filter(_.nonEmpty)
)
).asJson.noSpaces
} :+ entry.asJson.noSpaces
}
asJsonStrings.foreach(println)
De esta forma, podemos generar nuestro enorme archivo NDJSON con todas las entradas del día:
time ./extractor.sc --bulkIndex airquality --bulkType air_measurements > today_bulk.ndjson
En solo 1.46 segundos, generó el archivo que podemos enviar a la API de bulk de la siguiente manera:
time curl -u $ESUSER:$ESPASS -X POST -H 'Content-type: application/x-ndjson' \
$ESHOST/_bulk \
--data-binary "@today_bulk.ndjson" | jq '.'
La solicitud de carga demoró 0.98 segundos en completarse.
El tiempo total que demoró este método fue de 2.44 segundos (1.46 segundos desde la obtención y transformación de datos y 0.98 segundos más desde la solicitud de carga masiva), que es 182 veces más rápido que si cargáramos un documento a la vez. Así es: ¡2.44 segundos frente a 7 minutos y 26 segundos!
Un aporte importante aquí es el siguiente: ¡Utiliza las cargas masivas para procesos de indexación de mayores cantidades de documentos!
De datos a información
¡Felicitaciones! Hemos llegado al punto en el que hemos indexado las mediciones de aire de nuestra ciudad en Elasticsearch. Eso significa que, por ejemplo, podemos buscar y obtener los datos con mucha mayor facilidad que si tuviéramos que descargar, extraer y buscar manualmente la información que estamos buscando.
Tomemos este caso como ejemplo: si después de disfrutar al contemplar Las Meninas tuviéramos que elegir entre las siguientes opciones:
- Pasar un tiempo disfrutando del sol de Madrid al aire libre
- Seguir pasando un buen rato en el Museo del Prado
Podríamos preguntarle a Elasticsearch qué opción sería mejor para nuestra salud pidiéndole que nos diga cuál fue la última medición de NO2 tomada en la estación meteorológica más cercana en un radio de 1 km: ./es/payloads/search_geo_query.json
{
"size": "1",
"sort": [
{
"timestamp": {
"order": "desc"
}
},
{
"_geo_distance": {
"location": {
"lat": 40.4142923,
"lon": -3.6912903
},
"order": "asc",
"unit": "km",
"distance_type": "plane"
}
}
],
"query": {
"bool": {
"must": {
"match": {
"measurement.chemical": "NO2"
}
},
"filter": {
"geo_distance": {
"distance": "1km",
"location": {
"lat": 40.4142923,
"lon": -3.6912903
}
}
}
}
}
}
curl -H "Content-type: application/json" -X GET -u $ESUSER:$ESPASS $ESHOST/airquality/_search -d "@./es/payloads/search_geo_query.json"
Y recibiremos la siguiente respuesta:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4248,
"max_score": null,
"hits": [
{
"_index": "airquality",
"_type": "air_measurements",
"_id": "okzC5mQBiAHT98-ka_Yh",
"_score": null,
"_source": {
"timestamp": 1532872800000,
"location": {
"lat": 40.4148374,
"lon": -3.6867532
},
"measurement": {
"value": 5,
"chemical": "NO2",
"unit": "μg/m^3",
"who_limit": 200
}
},
"sort": [
1532872800000,
0.3888672868035024
]
}
]
}
}
Nos dice que la estación meteorológica de El Retiro reporta un nivel de NO2 de 5 μg/m^3. No es un mal resultado si tenemos en cuenta que el límite sugerido por la OMS es de 200 μg/m^3, así que ¡vámonos a comer unas tapas!
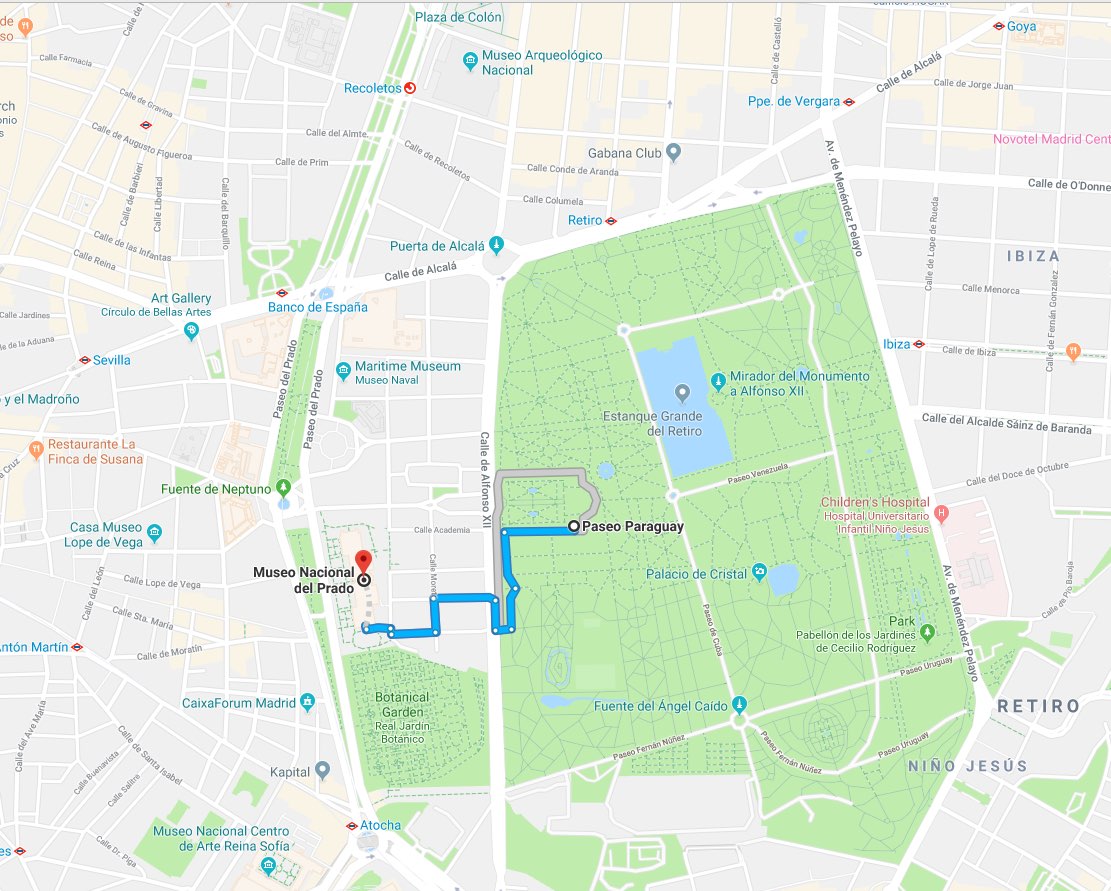
A decir verdad, nunca conocí a nadie que sacara una laptop y comenzara a escribir comandos cURL dentro de un museo. Sin embargo, estas solicitudes son tan fáciles de codificar en prácticamente cualquier lenguaje de programación que permiten proporcionar aplicaciones frontend en unos pocos días. Es decir, ya tenemos un backend de analíticas completo con nuestro índice de información.
Visualiza lo invisible con Kibana
¿Qué pasaría si no necesitáramos escribir la aplicación en absoluto? ¿Qué pasaría si, con el cluster actual, pudiéramos comenzar a explorar los datos haciendo click durante nuestro trayecto para obtener información reveladora? Gracias a Kibana, eso definitivamente es posible. Podemos ir a la sección de administración de clusters en cloud.elastic.co y hacer click en el enlace que nos da acceso al despliegue de Kibana:
Con Kibana, podemos crear visualizaciones y dashboards integrales a partir de los documentos indexados en Elasticsearch.
Los patrones de índices son nuestra manera de registrar los índices en Kibana para que puedan utilizarse en visualizaciones para la extracción de datos. Por lo tanto, el primer paso que debemos tomar antes de crear los gráficos para nuestro índice de calidad del aire es registrarlo.
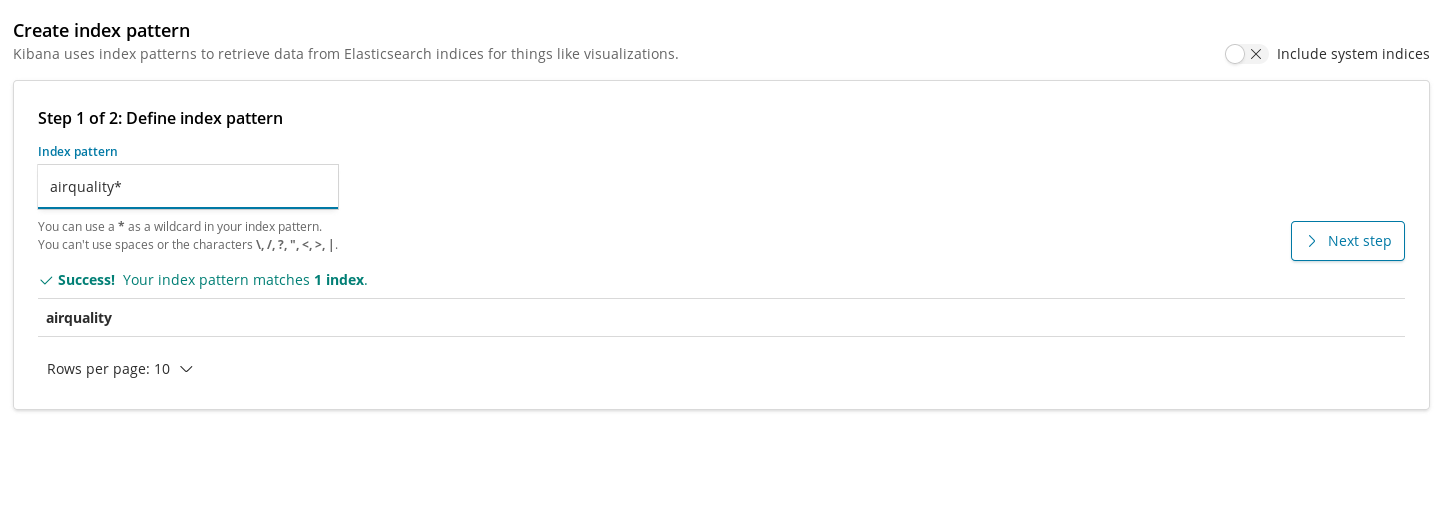
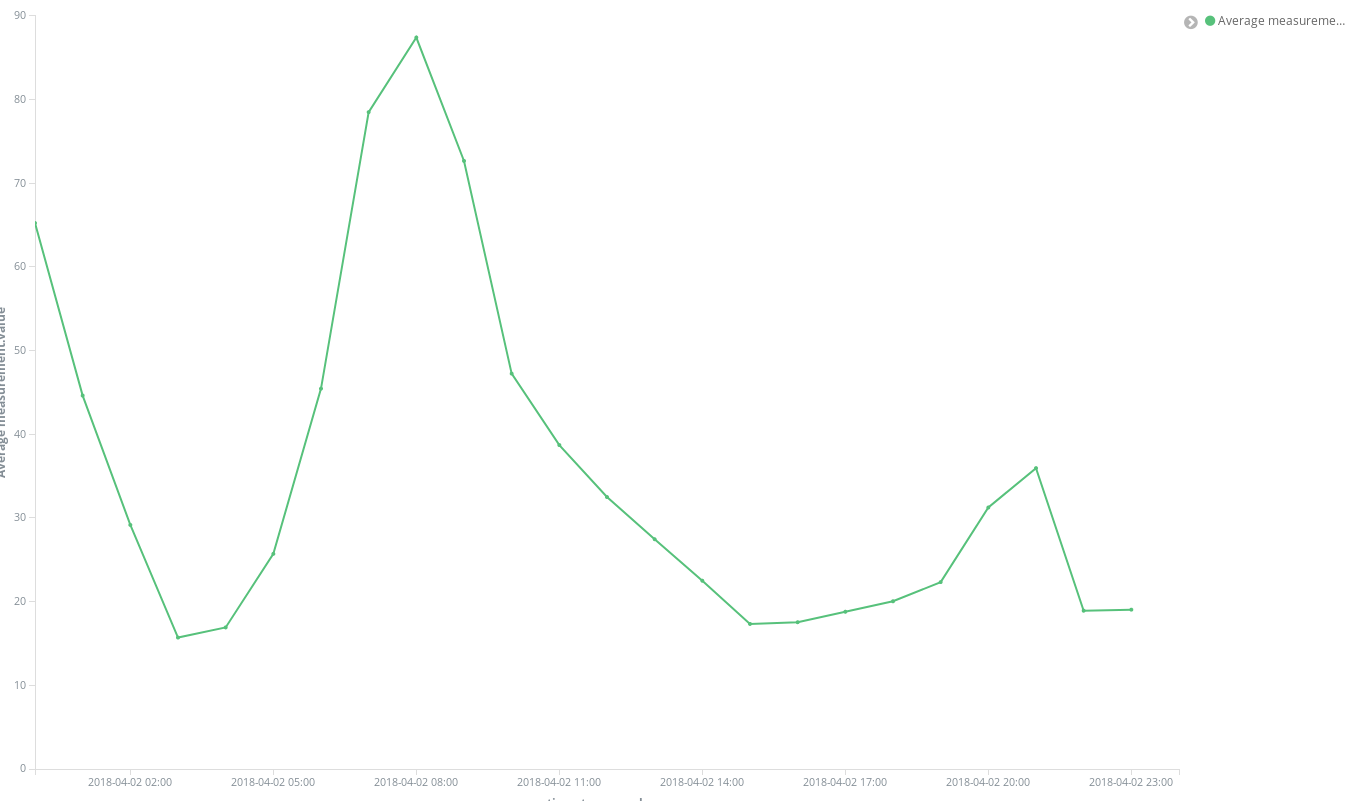
Una vez que lo creamos, podemos agregar nuestra primera visualización. Comencemos por algo simple: vamos a trazar la evolución en el tiempo de los niveles de concentración promedio para un determinado químico en toda la ciudad. Probemos con el NO2:
Primero, debemos crear un gráfico de líneas en el que el eje Y sea una agregación promedio para el campo valor de la medición en las cubetas de horas representadas en el eje X. Para seleccionar el químico objetivo, podemos utilizar la barra de búsqueda de Kibana, que facilita el filtrado de las mediciones de NO2 y, al habilitar la característica de autocompletar, podemos obtener sugerencias que nos guían a través del proceso de definición de la búsqueda.
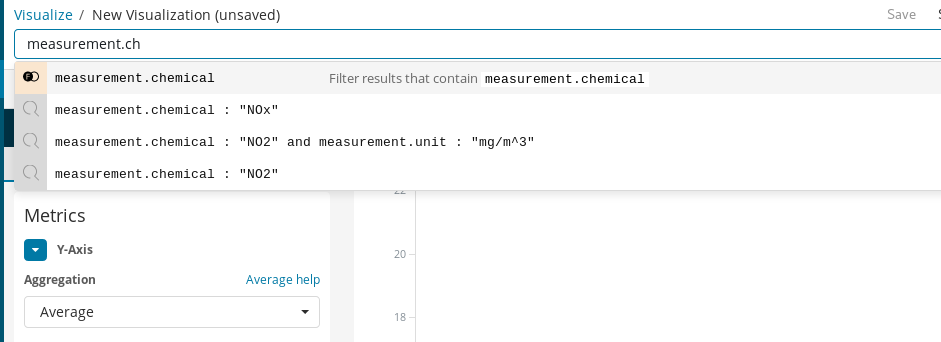
Finalmente, en el campo intervalo de tiempo elegimos el periodo de vigencia de los datos visualizados.
Con un par de clicks, obtenemos resultados de inmediato:
Uno de los gráficos más reveladores que podemos utilizar para este conjunto de datos son los mapas de coordenadas. Dado que cada medición incluye las coordenadas de la estación que la capturó, podemos representar puntos críticos de contaminación. Es decir, podemos pasar de calcular promedios de entradas espaciales en intervalos de tiempo a calcular promedios de entradas temporales en ubicaciones espaciales. Así que las cubetas ahora son agregaciones de Geohash sobre la ubicación, el campo que contiene el punto de medición.
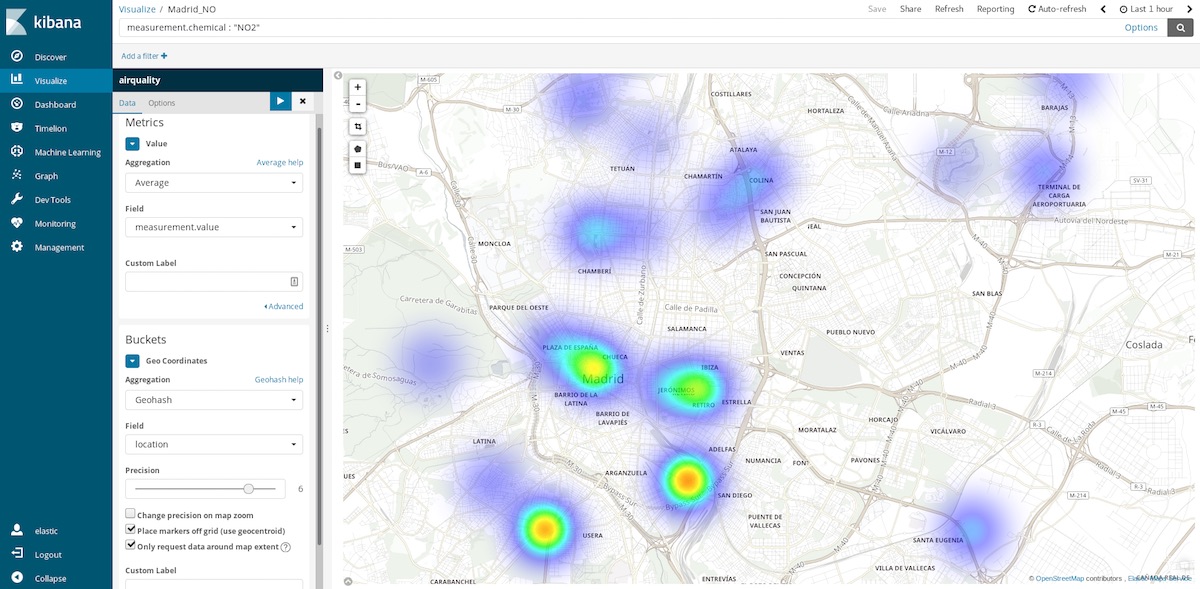
Si seleccionamos el intervalo de tiempo de la última hora, podemos hacernos una idea de cuáles son las áreas más limpias para visitar en este momento. Los intervalos de tiempo anuales nos dicen cuáles son las áreas más limpias en promedio y pueden ayudarnos, por ejemplo, a tomar una decisión sobre dónde deberíamos comprar una casa para llevar una vida más saludable.
Campos con scripts
Dado que nuestros documentos se basan en los niveles recomendados por la OMS para algunos químicos, es posible visualizar cuán poco saludable es el aire. Una forma de hacerlo es mediante el uso de la visualización de la medición sobre la proporción de un nivel medido y el límite de la OMS. Sin embargo, cuando cargamos los datos, no hicimos esa división. Eso no es un problema, ya que todavía es posible generar nuevos campos a partir de los campos indexados mediante el lenguaje de scripting Painless, que es fácil de entender y de escribir por cualquier persona que haya utilizado Java (a partir de la versión 6.4 de Kibana, también se puede obtener una vista previa de los resultados obtenidos por el script de Painless).
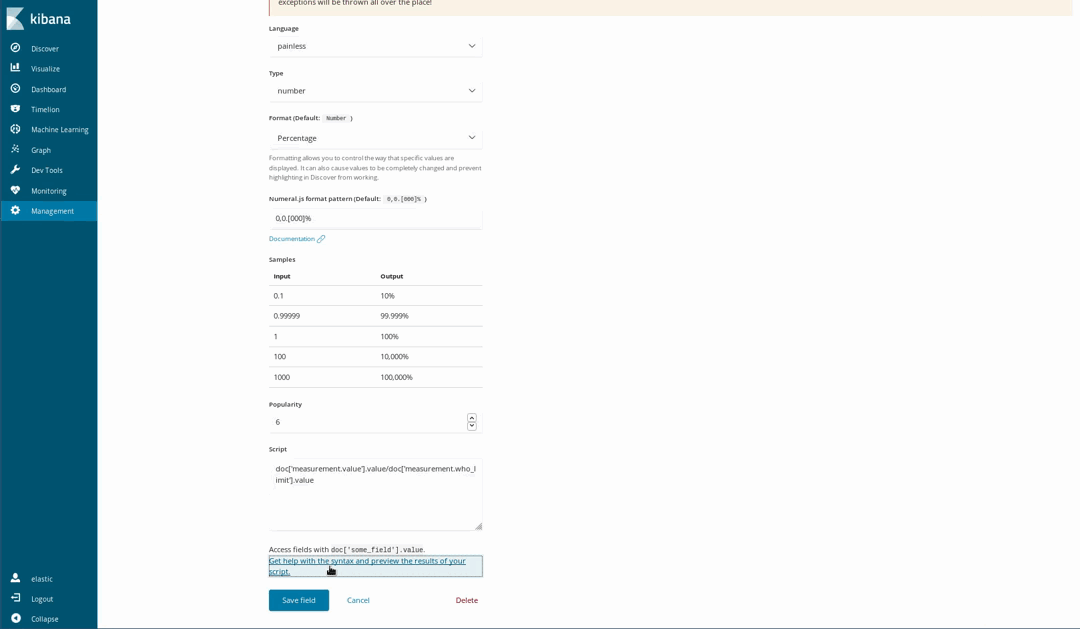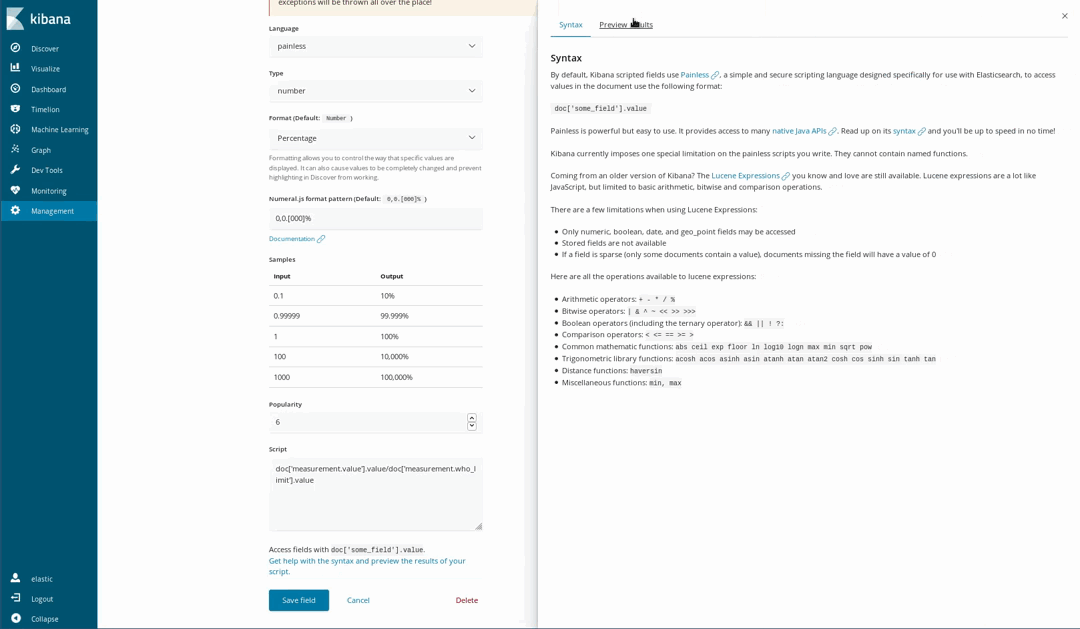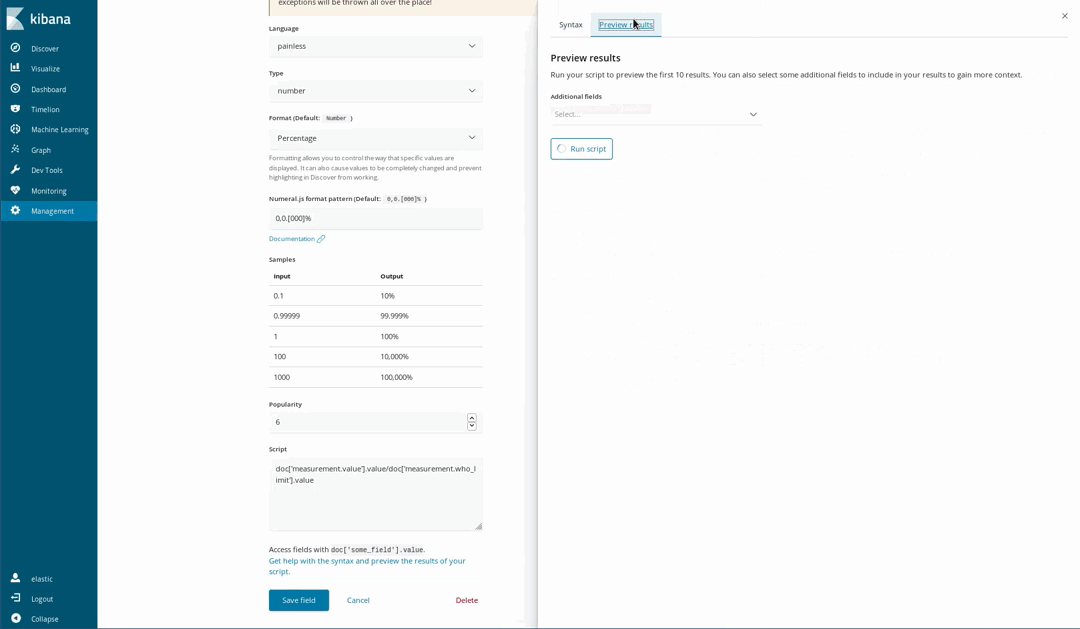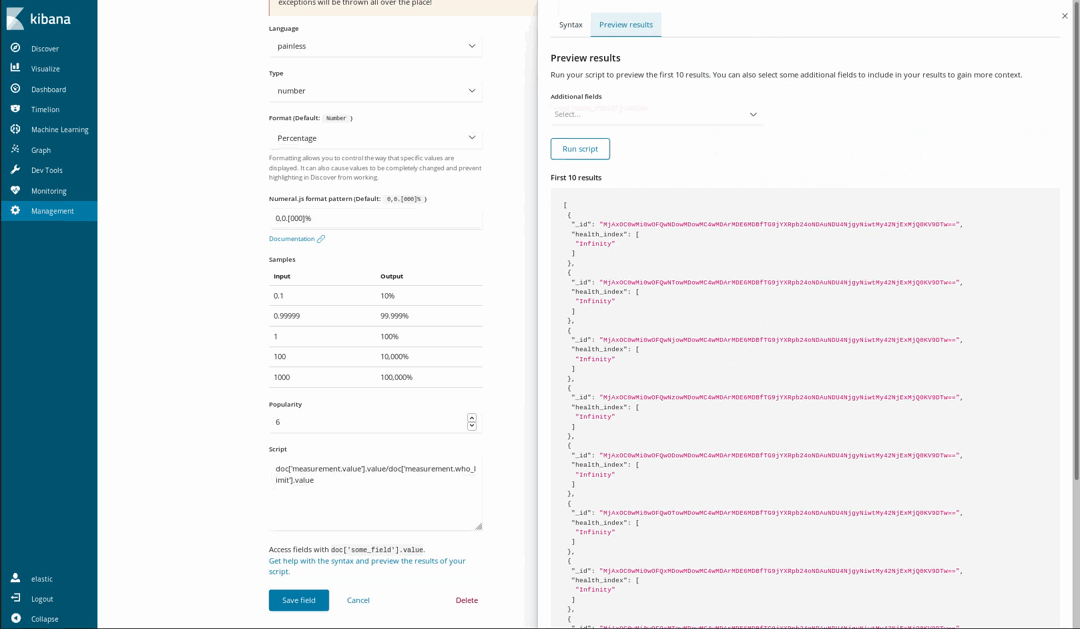
Luego los utilizamos en nuestras visualizaciones como si fueran campos indexados comunes:
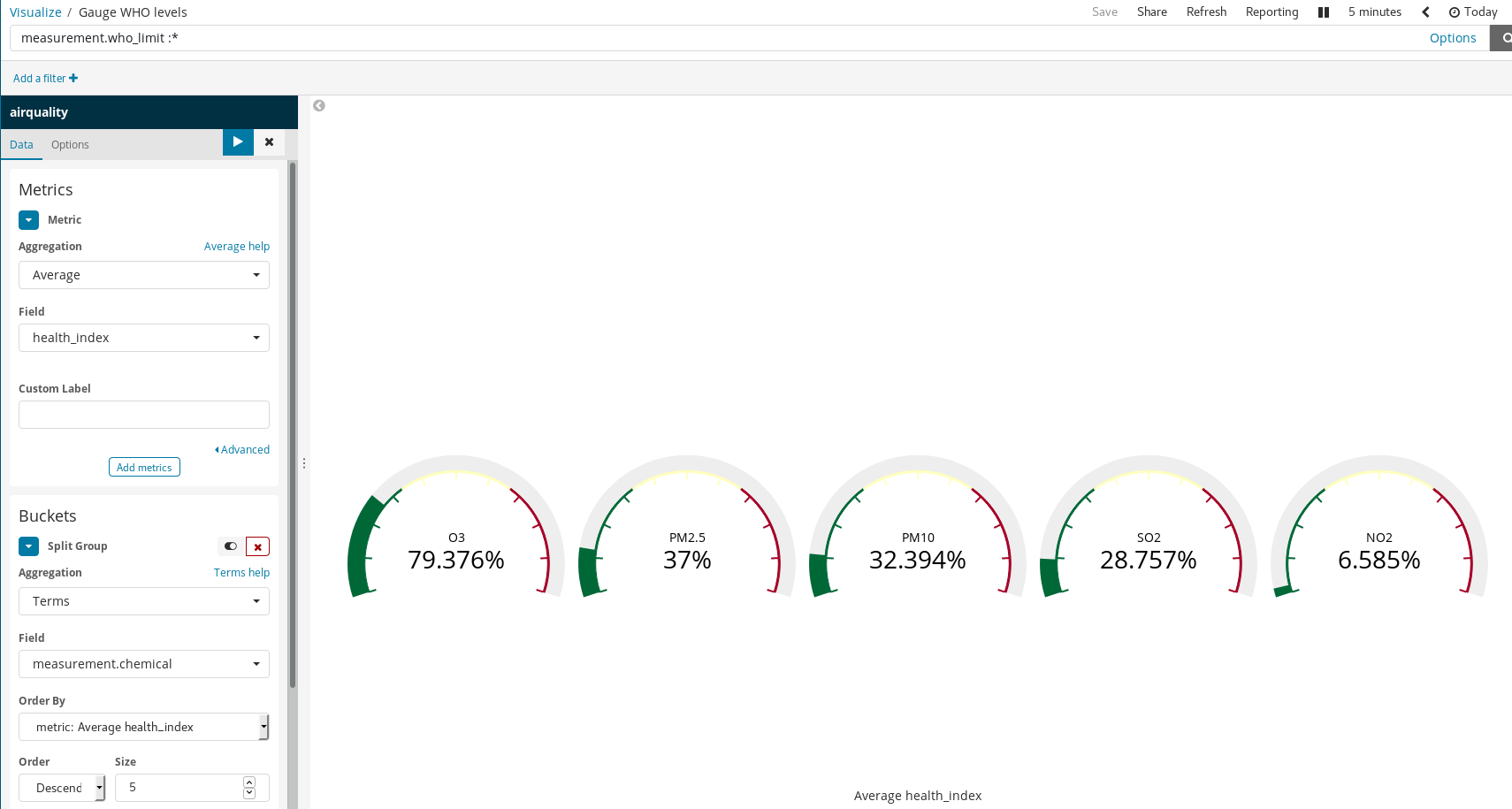
Vale la pena observar cómo estas reglas simples producen valiosas visualizaciones en Kibana. En el ejemplo de arriba, hicimos lo siguiente:
- Filtramos los documentos: seleccionamos solo aquellos para los que había límites de la OMS.
- Utilizamos grupos divididos y agregación de términos en las
mediciones de químicos.
De esa manera, se generó un gráfico indicador para cada químico que tuviera límites recomendados por la OMS.
Lecciones sobre la contaminación en Madrid
Las visualizaciones de Kibana pueden aprovecharse para crear dashboards que agreguen visualizaciones, lo cual es clave para interpretar y comprender el estado de un sistema en tiempo real. En este caso, el sistema es la composición de la atmósfera y sus interacciones con las actividades humanas.
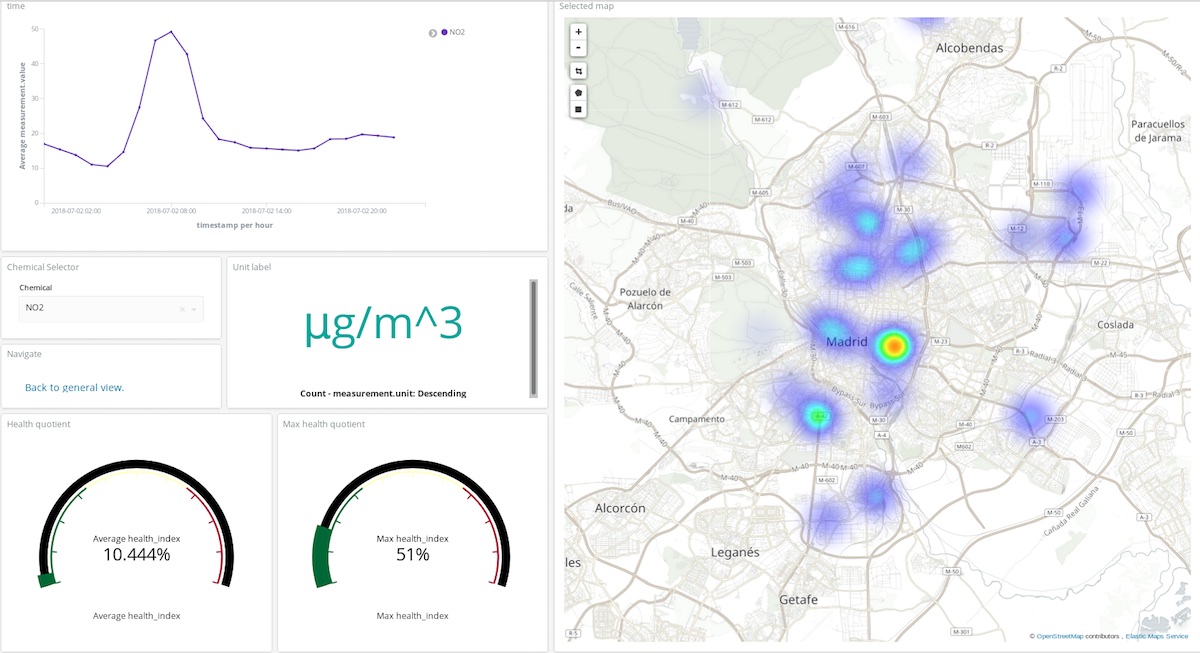
En el dashboard superior, un usuario puede elegir un químico y un período de tiempo para obtener una idea bastante clara de dónde y en qué medida ese compuesto contamina la atmósfera. ¡Puedes verlo tú mismo! (usuario: test, contraseña: madrid_air).
También puedes obtener una idea general (con el mismo usuario y contraseña) de la calidad del aire de Madrid.
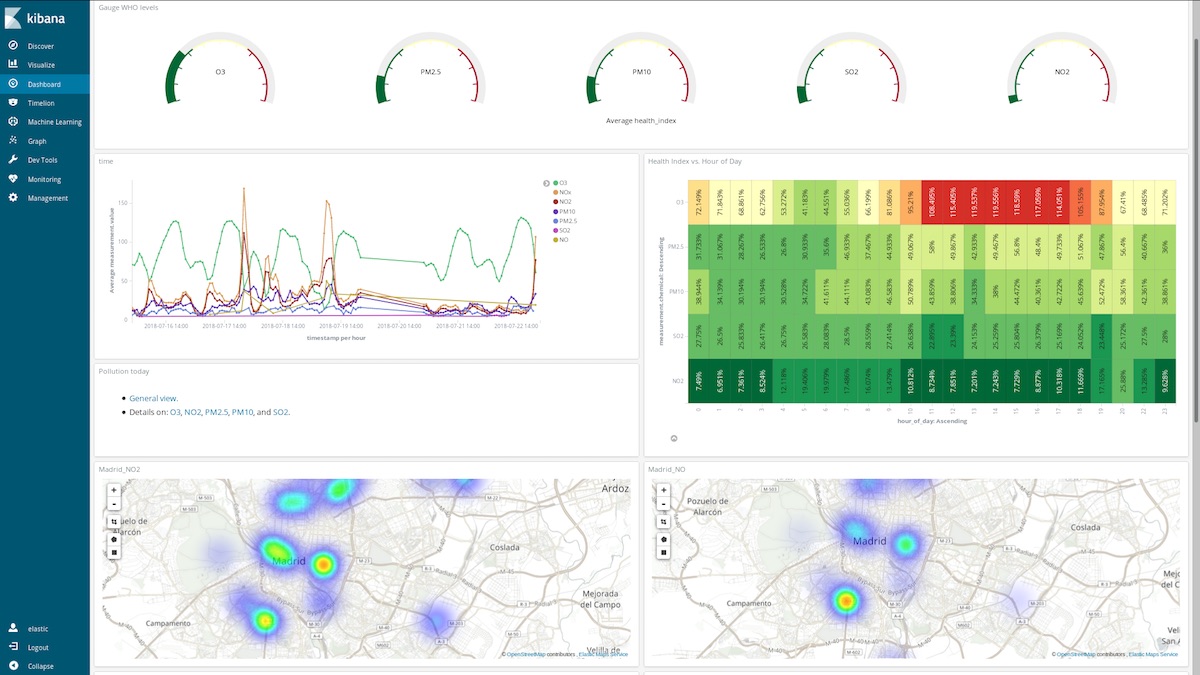
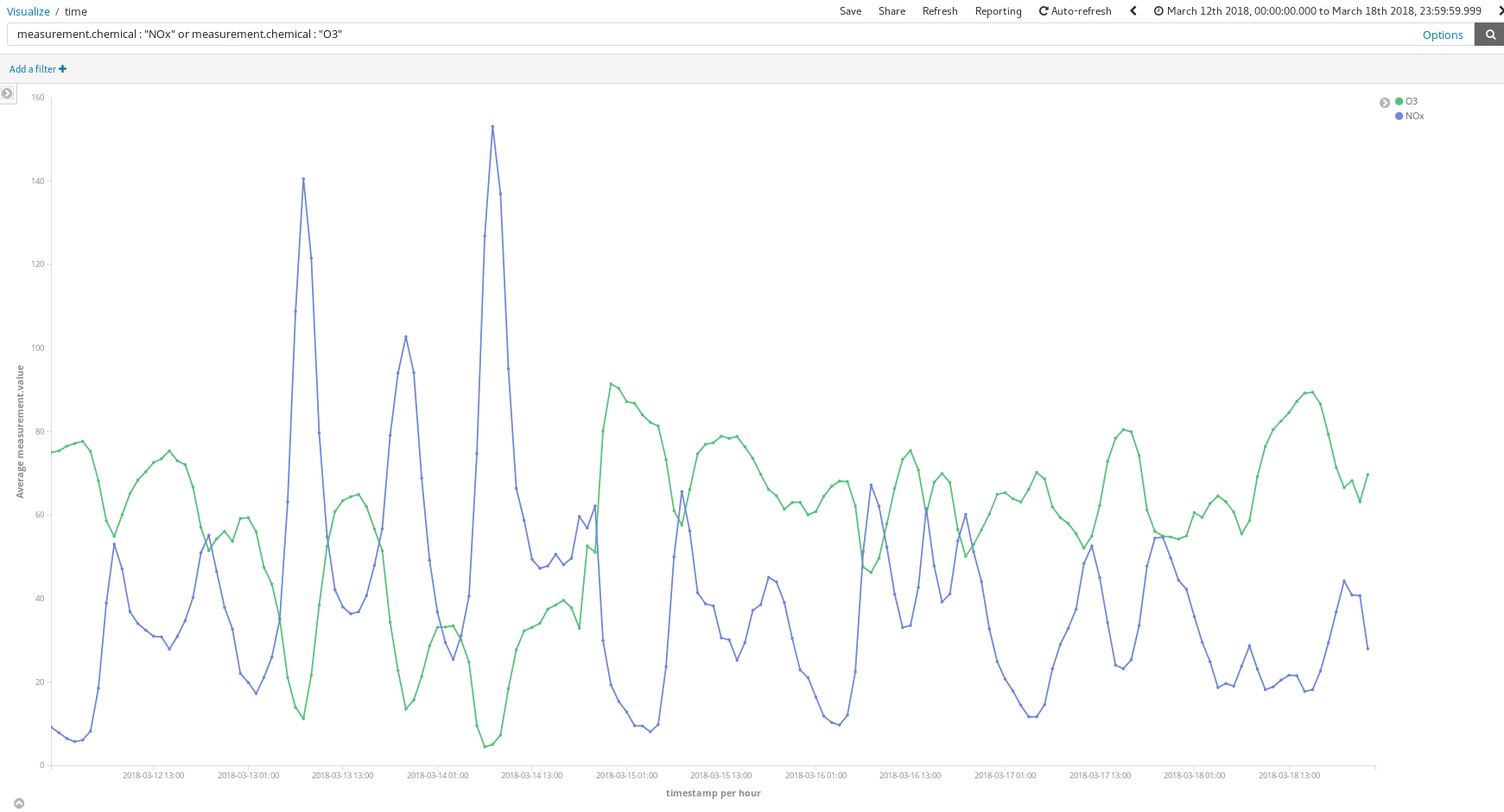
¿En qué nos ayudan estos dashboards? Echemos un vistazo a una semana de marzo al azar (del 12 al 18 de marzo):
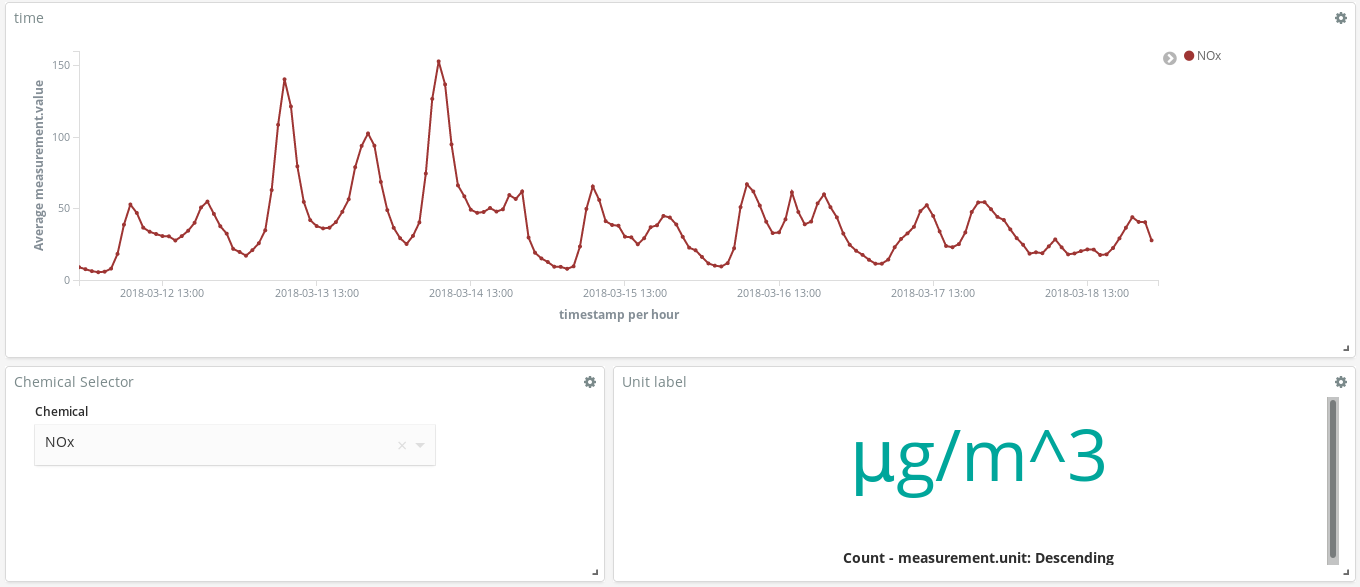
¿Estos picos de NOx (un compuesto producido por la combustión de motores diésel) nos dicen algo acerca de los hábitos de los madrileños? A decir verdad, sí. Estos picos ocurren dos veces al día...
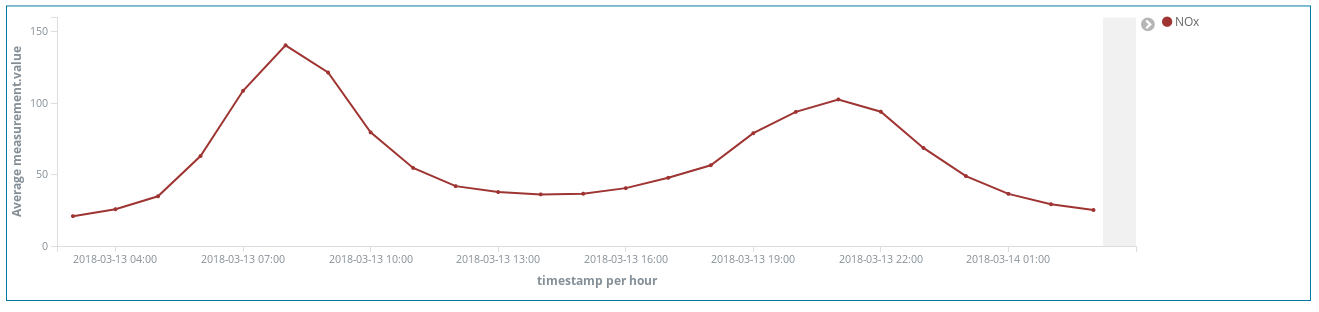
Uno alrededor de las 8 a. m. CEST, y el otro alrededor de las 9 p. m. CEST. Lo que vemos aquí es que cada vez son más los trabajadores que utilizan sus vehículos diésel para moverse por la ciudad y llegar a sus lugares de trabajo. Casi nadie usa su vehículo durante el horario laboral, por lo que la oleada de humo se produce cuando los madrileños terminan su trabajo en la oficina y regresan a casa.
También es interesante ver cómo aumenta la concentración de O3 a medida que se reduce la concentración de NOx. El O3 es un subproducto de las reacciones entre el NOx y los compuestos orgánicos en presencia de la luz solar, por lo que se espera que haya una correlación entre el NOx y el O3.
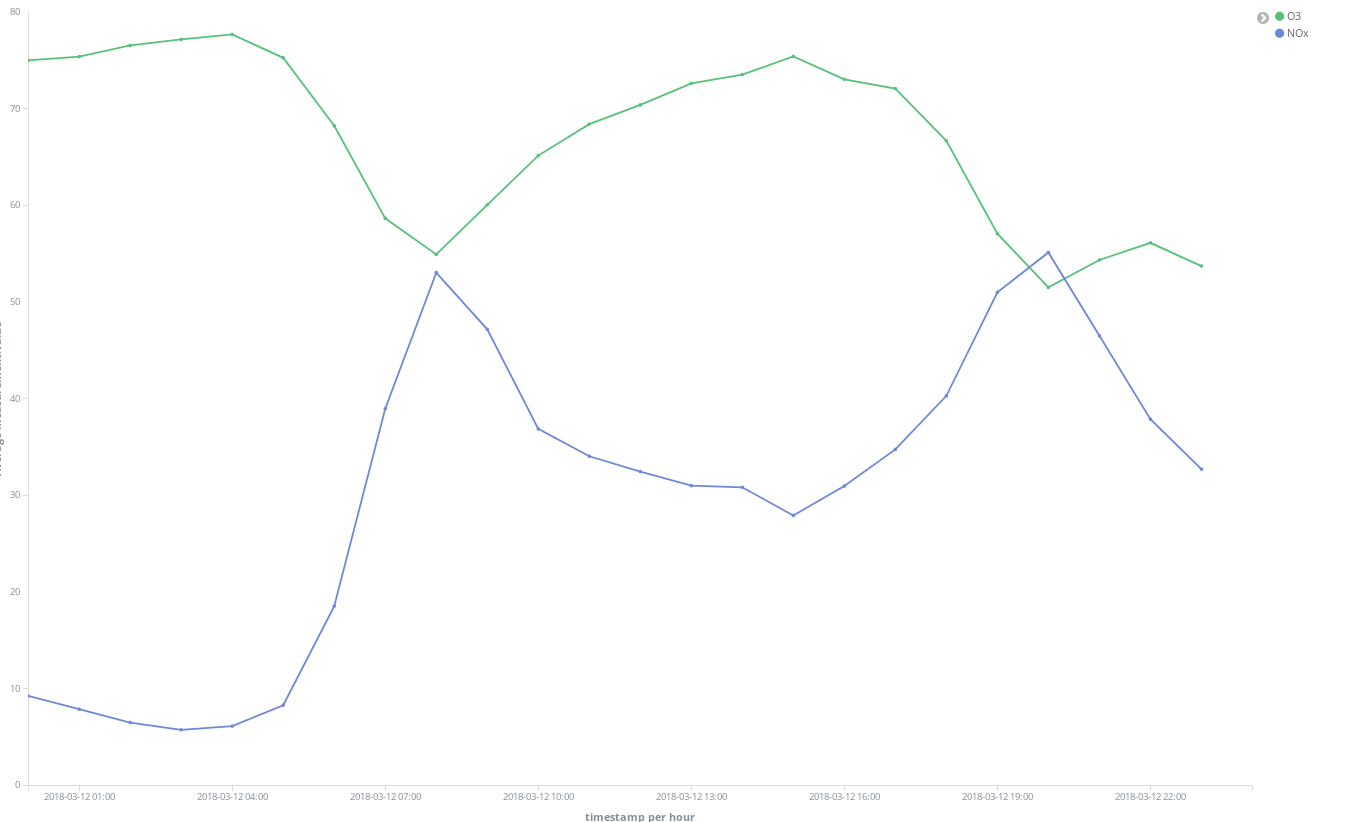
También podemos ver que la situación general mejora los fines de semana:
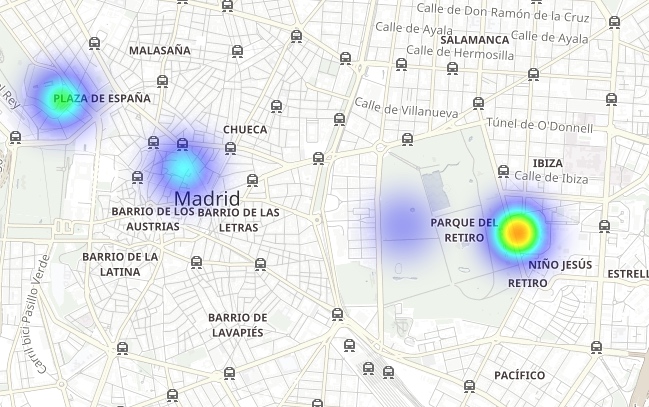
Observa cómo el Parque del Retiro (un gran espacio verde en el corazón de la ciudad) está rodeado por puntos de emisión de NO2 y, al mismo tiempo, es un área con menos emisiones gracias a la densa vegetación y la falta de tráfico:
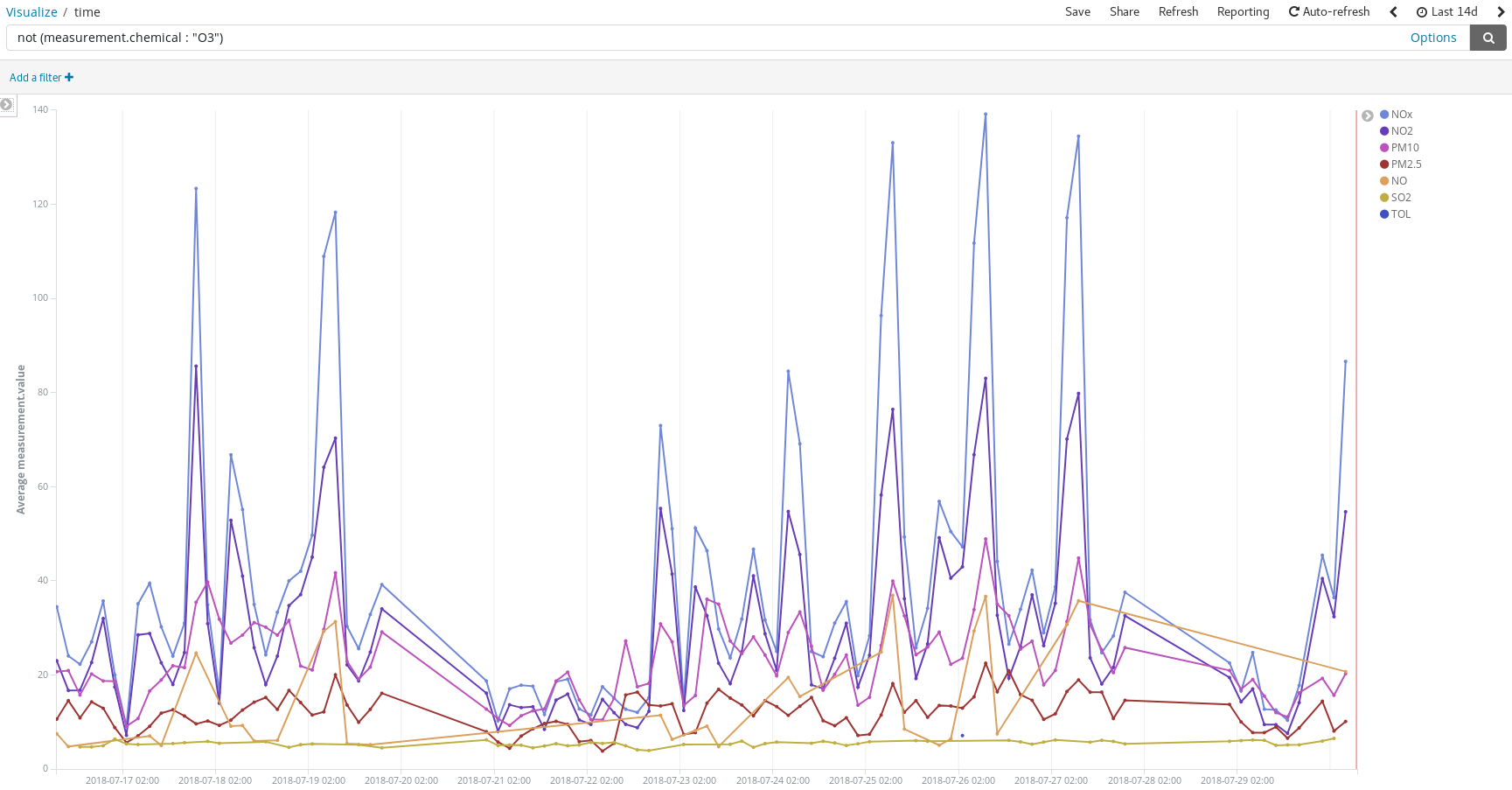
Detecta los picos de contaminación en los días en que las personas suelen usar sus automóviles para trasladarse a sus destinos de veraneo:
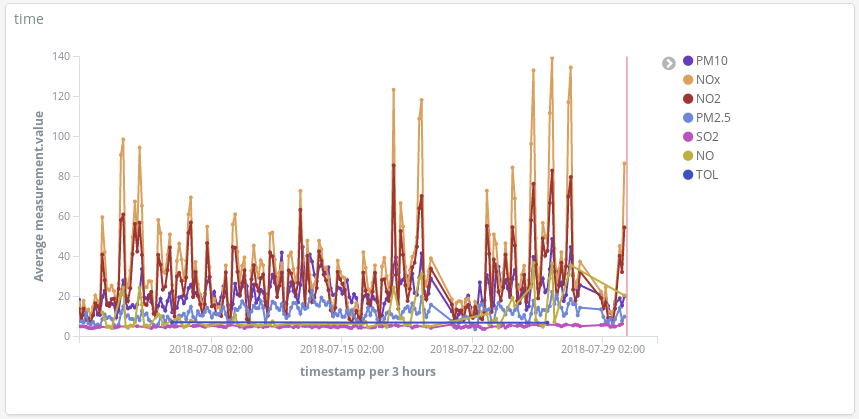
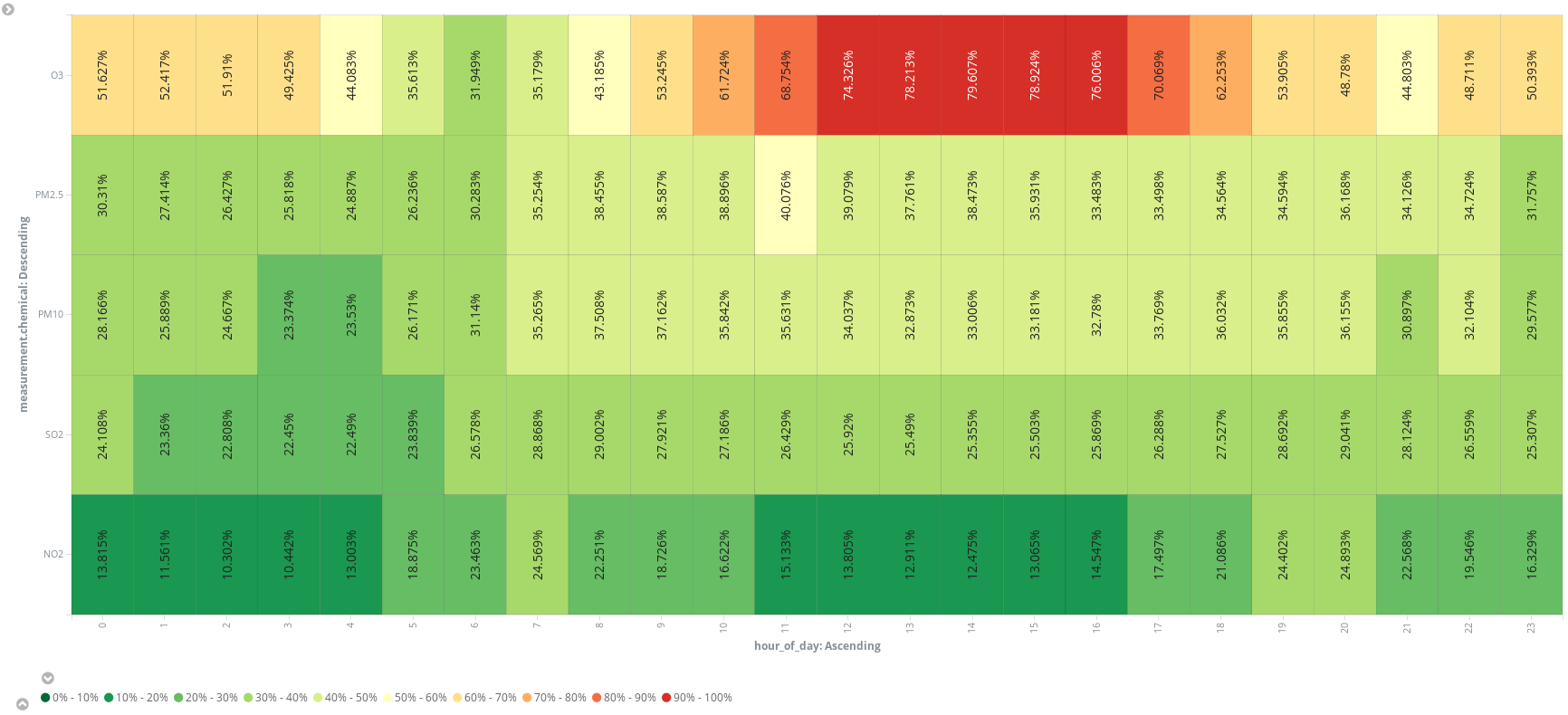
O agrega un campo con un script adicional (hora_del_día) para agrupar las entradas por hora para presentar las medidas promedio, por químico, en un mapa de calor. Parece que el mejor horario para salir a correr es a las 6 a. m.:
A fin de cuentas, nos convencimos de que hay más químicos en el aire que simplemente nitrógeno, oxígeno, dióxido de carbono, argón y agua. Así que la respuesta es "no". No es solo aire lo que respiramos cuando paseamos por la Gran Vía en Madrid. Y probablemente pase lo mismo al pasear por Manhattan. ¿Te gustaría comprobarlo por tu cuenta? Ahora que conoces el camino, todo lo que necesitas para comenzar es una fuente de datos abierta.
Conclusión
Si fuéramos ingenieros de datos y nos pidieran que configuráramos herramientas para que los científicos de datos de nuestra empresa analizaran los niveles de contaminación en Madrid, habríamos terminado nuestro trabajo una vez que hubiéramos registrado el patrón del índice calidad del aire en Kibana, incluido el enlace de acceso en un correo electrónico, y les hubiéramos permitido jugar un poco con eso. El Elastic Stack ofrece una pila de analíticas completa desde donde es posible obtener respuestas en minutos y de una manera muy intuitiva, ya que el único código que se utiliza para escribir es uno de los campos con script (si es necesario).
Gracias a Elastic Cloud, nuestro trabajo como ingenieros de datos se ha simplificado a unos pocos clicks y a escribir el servicio de extracción, transformación y carga (Extract Transform Load, ETL). Pero ¿realmente debemos escribir un ETL para obtener y cargar nuestros datos en Elasticsearch? En la próxima publicación, descubrirás que el Elastic Stack también puede hacerse cargo de eso.