Aprovechar Elasticsearch para dar un impulso al rendimiento del 1000 %
Voxpopme es una de las plataformas de investigación y análisis de video líderes en el mundo. Fundada en 2013 con la simple premisa de que el video es la forma más poderosa para dar una voz a cientos y miles de personas de manera simultánea. Nuestro software único ingesta videos grabados por el consumidor y contenido de formato largo (p. ej., grupos de enfoque) de una variedad de socios de encuesta y brinda datos de marketing valiosos en forma de grafos, temas navegables y showreels personalizables.
Desde nuestro lanzamiento, hemos destinado cuatro años a optimizar y automatizar la investigación y el análisis que se pueden obtener a partir de los videos para eliminar las barreras que bloquean conexiones reales entre marcas y consumidores. Para mejorar la experiencia del cliente, usamos las herramientas de PLN más recientes de IBM Watson para la identificación y agregación de los sentimientos de los encuestados y tenemos una alianza exclusiva con Affectiva para analizar emociones faciales. En 2017, incluimos Elasticsearch en nuestro arsenal de herramientas para entregar la mejor experiencia posible a nuestros clientes.
Superar nuestra infraestructura heredada
En Voxpopme, nuestro stack de tecnología ha cambiado significativamente en los últimos doce meses. En 2017, nuestra plataforma procesó medio millón de encuestas en video, la misma cantidad que en los cuatro años anteriores combinados, y esa cantidad se duplicó en 2018. Enfrentamos dificultades de escalamiento, lo cual fue un buen problema para resolver, pero un problema a fin de cuentas.
Los problemas surgieron de nuestro sistema heredado, que estaba compuesto por una aplicación monolítica de PHP que interactuaba con una serie de bases de datos diferentes para la funcionalidad básica. La lógica detrás de esta separación de datos original inicialmente era sólida:
- La mayoría de nuestros datos se almacenaba en una base de datos MySQL. Esto cubría los usuarios, las respuestas individuales de los videos y cosas por el estilo: datos relacionales estructurados que se conectaban con claves externas y se creaban, leían, actualizaban y eliminaban con una API RESTful.
- Los datos del cliente se almacenaban en un cluster MongoDB, que aceptamos de la forma en que se nos brindó. Esto permitía a los usuarios etiquetar, anotar y filtrar sus videos con su propia terminología.
- Almacenábamos las transcripciones de los videos de quienes respondían en un cluster pequeño de Elasticsearch, que usábamos para búsquedas de texto completo.
Por mucho tiempo, este enfoque funcionó muy bien, pero había un problema obvio.
El poder computacional no es ni gratuito ni infinito
Una búsqueda en nuestra plataforma puede ser increíblemente simple o muy compleja. En las instancias más simples, permitimos a los usuarios buscar por la clave primaria de una respuesta de video. Esto es fácil e involucra solo una búsqueda simple en la base de datos indexada de MySQL.
Pero, ¿qué sucede con las búsquedas cuando un usuario quiere filtrar usando un entero indexado, un poco de sus propios datos de formato libre y también ajustar los resultados a los encuestados que mencionaron un tema en particular? Por ejemplo:
Encontrar todos los registros con fecha de respuesta entre el primer y el último día de junio en los que el ingreso familiar de los encuestados se encuentre entre 100 y 125 mil dólares y en los que se mencione la frase "muy caro".
Este fue nuestro enfoque:
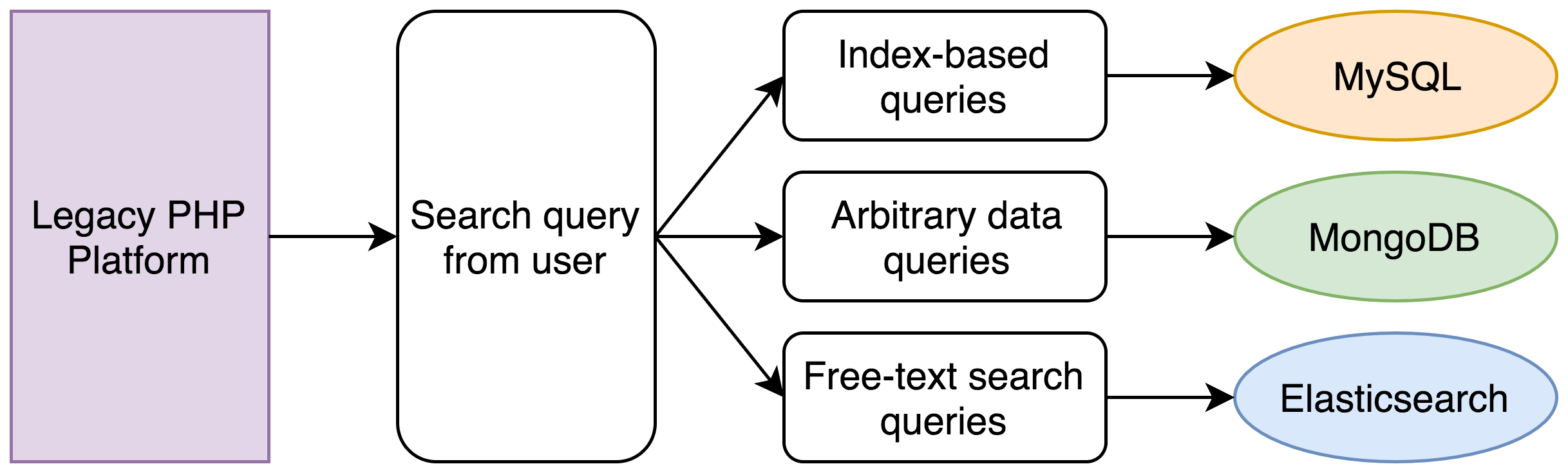
Con nuestro sistema heredado, habrían ocurrido las siguientes situaciones:
- Una búsqueda de MySQL encontraría todos los registros dentro del rango de fecha.
- Una búsqueda de MongoDB encontraría todos los registros dentro del rango de ingresos (ingresos es solo un ejemplo. Los clientes suelen almacenar información completamente arbitraria con nosotros).
- Una búsqueda de Elasticsearch habría encontrado todos los registros con la frase en la transcripción.
- Se habría calculado una intersección de las ID de los tres conjuntos de registros.
- Se habría ejecutado una nueva búsqueda de MySQL y MongoDB para obtener el conjunto de datos completo para cada registro.
- Los registros se habrían organizado y paginado.
Un simple conjunto de criterios de búsqueda podría involucrar, fácilmente, cinco búsquedas de base de datos diferentes. Originalmente, esto habría sido una operación de menos de un segundo, pero cinco años de datos y el hecho de que PHP se ejecute en un solo subproceso hacían que las búsquedas en la base de datos se tuvieran que realizar una después de la otra, lo cual podía demorar hasta 30 segundos.
Fue un modelo que nos lanzó al mercado rápidamente y nos sirvió durante una buena cantidad de años, pero que no pudo escalar de la mejor forma. Cuando percibimos que la experiencia de nuestros usuarios comenzó a desmejorar, decidimos que era hora de reescribir el mecanismo de búsqueda.
Ya teníamos algo de experiencia con Elasticsearch por nuestro stack existente, por lo que comenzamos a conversar con el gerente de ventas de Elastic para hablar sobre los problemas que enfrentábamos al realizar búsquedas complejas en un rango de datos que residen en varios lugares. Encontrar la solución correcta fue crítico: nuestro producto se centra en mostrar y realizar cálculos en los datos de forma rápida y eficiente. Los cuellos de botella al recuperar los datos serían inaceptables.
También consideramos extender nuestro cluster de MongoDB existente, pero después de una breve consulta telefónica con Elastic, el equipo de desarrollo decidió que la única solución que nos permitiría almacenar, buscar y manipular datos fácilmente (p. ej., agregaciones) era Elasticsearch.
Nuestras primeras impresiones
El cluster de Elasticsearch que habíamos estado usando para la búsqueda de texto era un cluster versión 1.5 de Compose.io. Como hemos invertido con fuerza en AWS para el resto de nuestra infraestructura, optamos inicialmente por Amazon Elasticsearch Service con un cluster versión 5.x en ejecución.
Nuestro nuevo modelo consistía en mantener todos los datos dispares de los registros dentro de un documento único de Elasticsearch mediante valores anidados con claves conocidas para los datos de formato libre más complicados de nuestros clientes. De esta manera, cualquier búsqueda de usuario podría gestionarse con una única búsqueda de Elasticsearch.
En una semana, ya teníamos una prueba básica del concepto cargada con varios miles de documentos, y nuestras primeras impresiones al ejecutar las búsquedas en Kibana fueron tan buenas que con gusto aprobamos la reescritura completa de nuestro mecanismo de búsqueda de back-end.
Este fue nuestro nuevo enfoque:
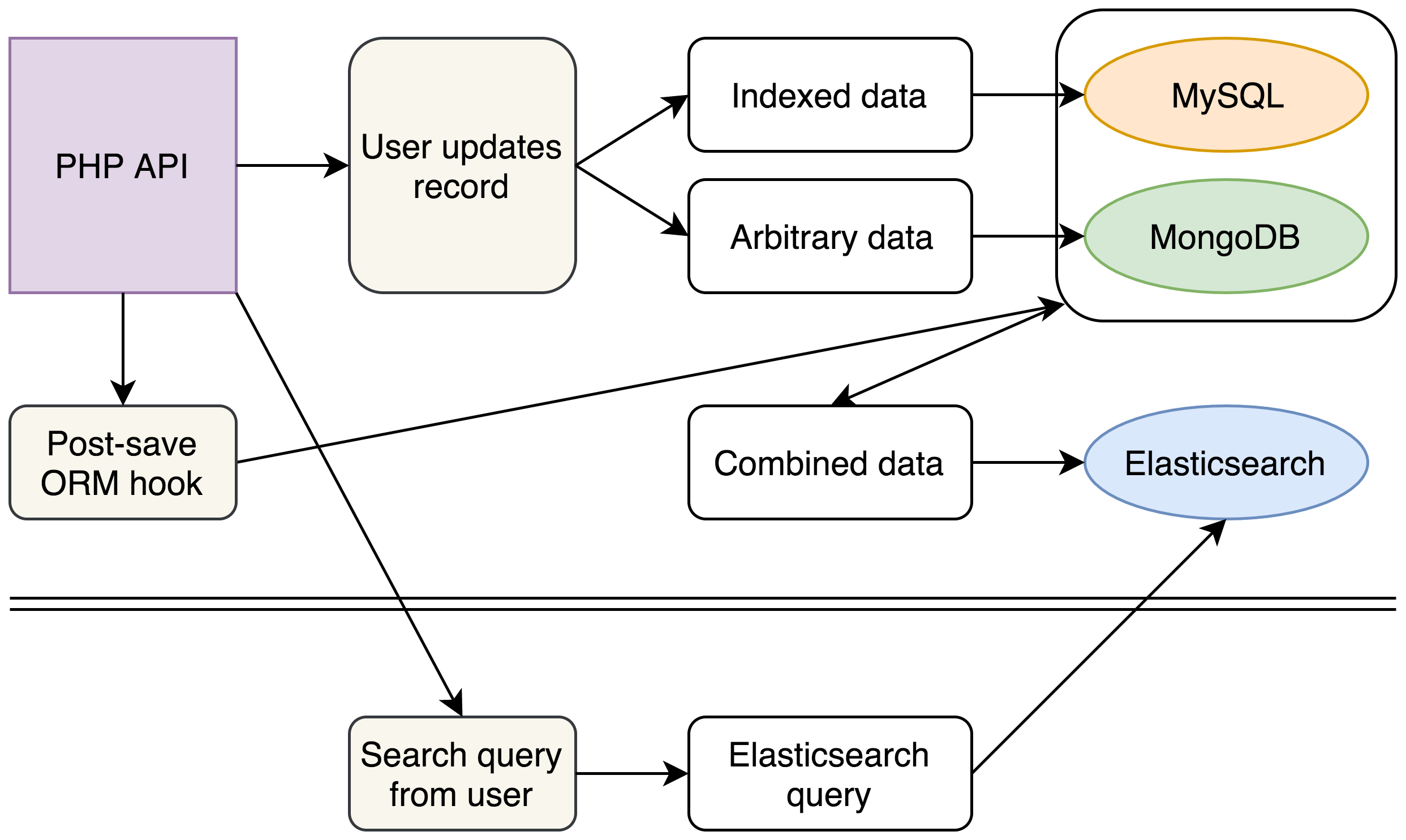
(Por ahora, nuestras bases de datos heredadas permanecen sin cambios, pero con la introducción de nuestro nuevo cluster de Elasticsearch para búsquedas complejas, podemos planificar eliminar MongoDB de nuestro stack por completo).
Con nuestro nuevo stack, continuamos escribiendo en MySQL y MongoDB como antes. Sin embargo, cada escritura también desencadenaba un evento que recopilaba y aplanaba nuestros datos desde las diferentes fuentes en un único documento JSON que se insertaba en Elasticsearch.
En el back-end, escribimos un nuevo mecanismo de búsqueda que construyó búsquedas complejas de Elasticsearch a partir de las solicitudes de búsqueda existentes de nuestros usuarios y eliminó completamente el código heredado que se usaba para búsquedas en MySQL y MongoDB. Buscar en un único cluster de Elasticsearch nos permitió obtener los mismos datos en una fracción del tiempo.
Surgieron beneficios adicionales de la estructura de nuestros documentos de Elasticsearch. Nuestra API proporciona documentos JSON, por lo que pudimos estructurar los documentos de Elasticsearch para que coincidan exactamente con la salida de nuestra API existente. Esto ahorra algunos segundos más, que anteriormente se usaban en combinar y reestructurar los datos que llegaban de MySQL y MongoDB.
Para las diferentes partes interesadas del negocio, fuimos capaces de reportar un aumento preliminar en el rendimiento de un 1000 % para partes clave de nuestra plataforma.
Este no es el proveedor que estás buscando
Después de prometer a todos un aumento del rendimiento de un 1000 %, el paso siguiente fue indexar todos nuestros datos y esperar que los números se mantuvieran al mismo nivel bajo presión.
Con todos los datos indexados, desafortunadamente el cluster AWS no se desempeñó bien.
Si hubiéramos simplemente indexado los datos una vez y después realizado la búsqueda muchas veces, quizás no habríamos tenido ningún problema. Sin embargo, nuestro modelo dependía de la combinación y la reindexación de datos siempre que se actualizaban en MySQL o MongoDB. Esto podía suceder miles de veces durante el período en el que era más probable que se realizaran búsquedas.
Descubrimos que el rendimiento bajó y que, a veces, los tiempos de búsqueda caían a segundos. Esto tuvo el efecto adverso de potencialmente bloquear nuestra aplicación de PHP, lo que a su vez podía mantener las conexiones de MySQL abiertas y, por un efecto dominó negativo, nuestro stack completo podía dejar de responder.
Estábamos experimentando estos problemas cuando Elastic{ON} llegó a Londres, así que aprovechamos la oportunidad para hablar con un representante de Elastic en el pabellón de AMA sobre los tamaños de cluster y los problemas que estábamos experimentando Mencionamos que nuestro mejor tiempo de búsqueda era de alrededor de 40 ms, y nos aconsejaron que usar el servicio Elastic Cloud de Elastic en lugar de AWS podría brindar tiempos de respuesta más cercanos a 1 ms con las configuraciones predeterminadas.
La disponibilidad de Elastic Stack Features (anteriormente X-Pack) en Elastic Cloud fue un gran beneficio para nosotros, ya que solo teníamos sistemas de logging y creación de grafos limitados en ese momento. Como X-Pack no está incluido en la oferta de Elasticsearch de AWS, decidimos lanzar un cluster de Elastic Cloud para realizar algunas pruebas de lado a lado. Si se desempeñaba al menos tan bien como el cluster de AWS, sabíamos que cambiaríamos solo para recibir los otros beneficios.
La UI de Elastic Cloud era muy limpia y fácil de usar. Durante el indexado, fue necesario escalar a medida que agregábamos más trabajadores para procesar los datos, y nos impresionó lo fácil que fue gestionar el cluster: solo había que mover un control deslizante hacia la izquierda o la derecha y hacer clic en "Actualizar".
Una vez que nuestros datos se indexaron correctamente en el nuevo cluster, pudimos ejecutar búsquedas complejas con una rapidez de 2 ms con poco o ningún bloqueo (desde entonces, hemos optimizado las cosas aún más para eliminar completamente el bloqueo). Si bien unos cuantos milisegundos aquí y allá generalmente son imperceptibles para el usuario final, para los técnicos entre nosotros fue agradable ver que la latencia se redujo al 5 % de su nivel anterior
Aprovechar nuestros datos al máximo
No queríamos ser anticuados y solo usar Elasticsearch como un motor de búsqueda para el usuario. Muchas de las historias de éxito que hemos oído sobre la tecnología parecen enfocarse en el logging, y descubrimos rápidamente que nosotros no éramos una excepción.
Configuramos un cluster de logging separado para ingestar los logs de los pods de Kubernetes y ahora disfrutamos de una visibilidad más clara de la salud de nuestros servidores que antes simplemente no estaba disponible para nosotros y podemos reaccionar mucho más rápido cuando surgen problemas.
También hemos podido ofrecer algo similar a los usuarios de nuestra plataforma. Usando agregaciones, hemos podido brindar a nuestros usuarios una forma gráfica de visualizar sus datos. Esto en sí mismo fue una gran adición a nuestra plataforma y surgió simplementecomo un efecto secundario de tener los datos en Elasticsearch.
Durante los últimos meses, hemos modificado y refinado nuestros procesos, y vemos una mejora en el rendimiento de nuestros clusters de Elasticsearch todas las semanas. Estos aumentos en el rendimiento han incluido grandes ganancias de memoria al mover campos que requieren datos de campo del cluster primario a un cluster menor al cual se accede con menos frecuencia (nuestra presión de memoria de línea de base bajó del 75 % al 25 %). También hemos optimizado nuestro código para escribir nuestros datos de forma masiva en lugar de a petición, lo que ha hecho que el cluster responda mejor durante momentos pico.
Para el futuro, planificamos usar Elasticsearch de forma intensiva para analizar los datos internos que mantenemos como compañía. Como ha probado ser una parte esencial de nuestro producto de cara al cliente, ya hemos comenzado a experimentar con el almacenamiento de nuestros propios datos en los índices de Elasticsearch y planeamos usar el Elastic Stack para aprender más sobre nuestra eficiencia operacional como compañía.
 David Maidment es ingeniero de software sénior en Voxpopme y se especializa en preparar la base de códigos de la empresa para el futuro a medida que la compañía experimenta un crecimiento exponencial.
David Maidment es ingeniero de software sénior en Voxpopme y se especializa en preparar la base de códigos de la empresa para el futuro a medida que la compañía experimenta un crecimiento exponencial.
 Andy Barraclough es cofundador y CTO de Voxpopme y trabaja en la gestión del equipo técnico y la coordinación de la visión a largo plazo de la compañía.
Andy Barraclough es cofundador y CTO de Voxpopme y trabaja en la gestión del equipo técnico y la coordinación de la visión a largo plazo de la compañía.