Implementación de una arquitectura caliente-tibia-fría con gestión de ciclo de vida del índice
NOTA: Ya no se recomienda implementar arquitecturas calientes-tibias-frías con atributos de nodos como se describe en este documento (es decir, -Enode.attr.data=hot). Los #niveles de datos formalizaron este concepto a través del uso de node.roles (es decir, node.roles: ["data_hot", "data_content"]). Visita https://www.elastic.co/es/blog/elasticsearch-data-lifecycle-management-with-data-tiers para obtener información actualizada.
Si ya implementaste una arquitectura caliente-tibia-fría con atributos de nodos, se recomienda adoptar node.roles para los niveles de datos y luego usar la API de migración a niveles de datos o convertir de forma manual la configuración (es decir, políticas de ILM, configuración de índices, plantillas de índices) para usar las preferencias de niveles de datos.
Además, en este documento se hace referencia a plantillas de índices heredadas (es decir, PUT _template) y a la necesidad de iniciar un índice. Las plantillas de índices heredadas se reemplazaron por plantillas de índices que se pueden componer (es decir, PUT /_index_template) y si usas flujos de datos, no es necesario iniciar el índice.
La gestión de ciclo de vida del índice (ILM) es una característica que se presentó por primera vez en Elasticsearch 6.6 (beta) y se puso a disposición del público en general en la versión 6.7. ILM es parte de Elasticsearch y está diseñada para ayudarte a gestionar tus índices.
En este blog, exploraremos cómo implementar una arquitectura caliente-tibia-fría usando ILM. Las arquitecturas calientes-tibias-frías son comunes para los datos temporales como logging o métricas. Por ejemplo, supongamos que se está usando Elasticsearch para agregar archivos de log de varios sistemas. Los logs de hoy se están indexando activamente, y la mayoría de las búsquedas se realizan en los logs de esta semana (calientes). Es posible que se realicen búsquedas en los logs de la semana anterior, pero no tanto como en los de la semana actual (tibios). Es posible que se realicen o no búsquedas frecuentes en los logs del mes anterior, pero es bueno mantenerlos por las dudas (fríos).
En la ilustración anterior, hay 19 nodos en este cluster: 10 nodos calientes, 6 nodos tibios y 3 nodos fríos. *No necesitas 19 nodos para implementar la arquitectura caliente-tibia-fría con ILM, pero necesitarás al menos 2 nodos. La manera de dimensionar tu cluster depende de tus requisitos. *Los nodos fríos son opcionales y simplemente proporcionan un nivel más para modelar dónde colocar los datos. Elasticsearch te permite definir cuáles nodos son calientes, tibios o fríos. ILM te permite definir cuándo hacer el traslado entre las fases y qué hacer con el índice al entrar en dicha fase.
No existe una única arquitectura caliente-tibia-fría que se adapte a todo. Sin embargo, en general querrás más recursos de CPU y una E/S más rápida para los nodos calientes. Habitualmente, los nodos tibios y fríos requieren más espacio en disco por nodo, pero también pueden arreglárselas con menos recursos de CPU y una E/S más lenta.
Bien, comencemos.
Configuración del reconocimiento de la asignación de shards
La arquitectura caliente-tibia-fría depende del reconocimiento de la asignación de shards, y por lo tanto, comenzamos por etiquetar cuáles nodos son calientes, tibios y (opcionalmente) fríos. Es posible hacerlo mediante parámetros de inicio o en el archivo de configuración elasticsearch.yml. Por ejemplo:
bin/elasticsearch -Enode.attr.data=hot
bin/elasticsearch -Enode.attr.data=warm
bin/elasticsearch -Enode.attr.data=cold
(Si estás usando Elasticsearch Service en Elastic Cloud, tendrás que elegir la plantilla caliente/tibia con Elasticsearch 6.7+)
Configuración de una política de ILM
A continuación, debemos definir una política de ILM. Una política de ILM puede volver a usarse en todos los índices que desees. Esta política se divide en cuatro fases primarias: caliente, tibia, fría y eliminación. No es necesario que definas cada fase de una política. ILM siempre ejecutará las fases en ese orden (y omitirá las que no estén definidas). Para cada fase definirás cuándo se entra a la fase y un conjunto de acciones para gestionar tus índices del modo que consideres adecuado. En las arquitecturas calientes-tibias-frías, puedes configurar la acción asignar para trasladar tus datos de nodos calientes a nodos tibios y de nodos tibios a nodos fríos.
Además de solo trasladar los datos entre los nodos calientes-tibios-fríos, hay muchas acciones adicionales que puedes configurar. La acción desplazar se usa para gestionar el tamaño o la antigüedad de cada índice. La acción forzar fusión puede usarse para optimizar tus índices. La acción congelar puede usarse para reducir la presión de memoria en el cluster. Hay muchas más acciones disponibles, consulta la documentación correspondiente a tu versión de Elasticsearch para conocerlas.
Política de ILM básica
Echemos un vistazo a una política de ILM muy básica:
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}
Esta política dice que después de 30 días o si el índice alcanza un tamaño de 50 gb (basado en shards primarios), se desplaza el índice y se comienza a escribir en un índice nuevo.
ILM y plantillas de índice
A continuación, debemos asociar esa política de ILM con una plantilla de índice:
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
Nota: Cuando se usa la acción de desplazamiento, es necesario especificar la política de ILM en una plantilla de índice (en lugar de hacerlo directamente en el índice).
En el caso de las políticas que incluyen la acción desplazar, también debes iniciar el índice con un alias de escritura después de crear la plantilla de índice.
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}
Suponiendo que se cumple correctamente con todos los requisitos para el desplazamiento, cualquier índice nuevo que comience con test-* se desplazará automáticamente después de 30 días o 50 gb. Usar índices gestionados de desplazamiento con max_size puede reducir en gran medida la cantidad de shards (y por lo tanto, la sobrecarga) de tus índices.
Configuración de una política de ILM para ingesta
Beats y Logstash soportan ILM, y si esta característica está habilitada, configurará una política predeterminada similar a la del ejemplo anterior. Beats y Logstash también se ocuparán de todos los requisitos para la acción desplazar. Esto significa que cuando ILM está habilitada para Beats y Logstash, a menos que tengas índices diarios grandes (>50 gb/día), el tamaño probablemente sea el factor primario para determinar cuándo se crea un índice nuevo (lo cual es bueno). A partir de la versión 7.0.0, ILM con desplazamiento será la configuración predeterminada para Beats y Logstash.
Sin embargo, debido a que no existe una única arquitectura caliente-tibia-fría que se adapte a todo, Beats y Logstash no se enviarán con políticas de arquitectura caliente-tibia-fría. Podemos crear una política nueva que funcione para la arquitectura caliente-tibia-fría y obtener optimizaciones en el camino.
Podríamos actualizar la política predeterminada de Beats o Logstash. Sin embargo, eso desdibuja las líneas entre la configuración predeterminada y lo personalizado. Además, actualizar la política predeterminada también presenta el riesgo de que no se les aplique la política correcta a las versiones futuras (la configuración predeterminada de la plantilla de Beats cambiará en las versiones 7.0+). Podríamos usar las configuraciones de Beats y Logstash para definir las políticas personalizadas mediante su respectiva configuración. Esto también funciona, pero es posible que no quieras cambiar la configuración de cientos (o miles) de instancias de Beats para cambiar la política de ILM. El tercer enfoque que se describe aquí aprovecha la coincidencia de varias plantillas para permitir que Elasticsearch mantenga el control total sobre la política de ILM.
Optimización de la política de ILM para la arquitectura caliente-tibia-fría
Creemos primero una política de ILM optimizada para una arquitectura caliente-tibia-fría. Nuevamente, no hay una opción que se adapte a todo, y probablemente tus requisitos difieran.
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size":"50gb",
"max_age":"30d"
},
"set_priority": {
"priority": 50
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
},
"allocate": {
"require": {
"data": "warm"
}
},
"set_priority": {
"priority": 25
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": {
"priority": 0
},
"freeze": {},
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {}
}
}
}
}
}
Caliente
Esta política de ILM comenzará por configurar la prioridad del índice en un valor alto para que los índices calientes se recuperen antes que los demás. Después de 30 días o 50 gb (lo que suceda primero), se desplazará el índice y se creará uno nuevo. Ese índice nuevo iniciará la política nuevamente, y el índice actual (el que acaba de desplazarse) esperará hasta 7 días desde que se desplazó para entrar en la fase tibia.
Tibia
Una vez que el índice esté en la fase tibia, ILM reducirá el índice a 1 shard, forzará la fusión del índice a 1 segmento, configurará la prioridad del índice en un valor inferior a caliente (pero superior a frío) y trasladará el índice a los nodos tibios mediante la acción asignar. Una vez hecho esto, esperará 30 días (desde que se desplazó) para entrar en la fase fría.
Fría
Una vez que el índice está en la fase fría, ILM reducirá nuevamente la prioridad del índice para asegurar que los índices calientes y tibios se recuperen primero. Luego congelará el índice y lo trasladará a los nodos fríos. Una vez hecho esto, esperará 60 días (desde que se desplazó) para entrar en la fase de eliminación.
Eliminación
Aún no hemos hablado sobre la fase de eliminación. Sencillamente, la fase de eliminación contiene la acción eliminar que elimina el índice. Siempre querrás una min_age en la fase de eliminación que permita que tu índice se mantenga en la fase caliente, tibia o fría durante un período de tiempo dado.
Creación de una política de ILM desde Kibana
¿No te gusta escribir mucho en formato JSON? (A nosotros tampoco). Usemos la UI de Kibana para inspeccionar o crear la política:
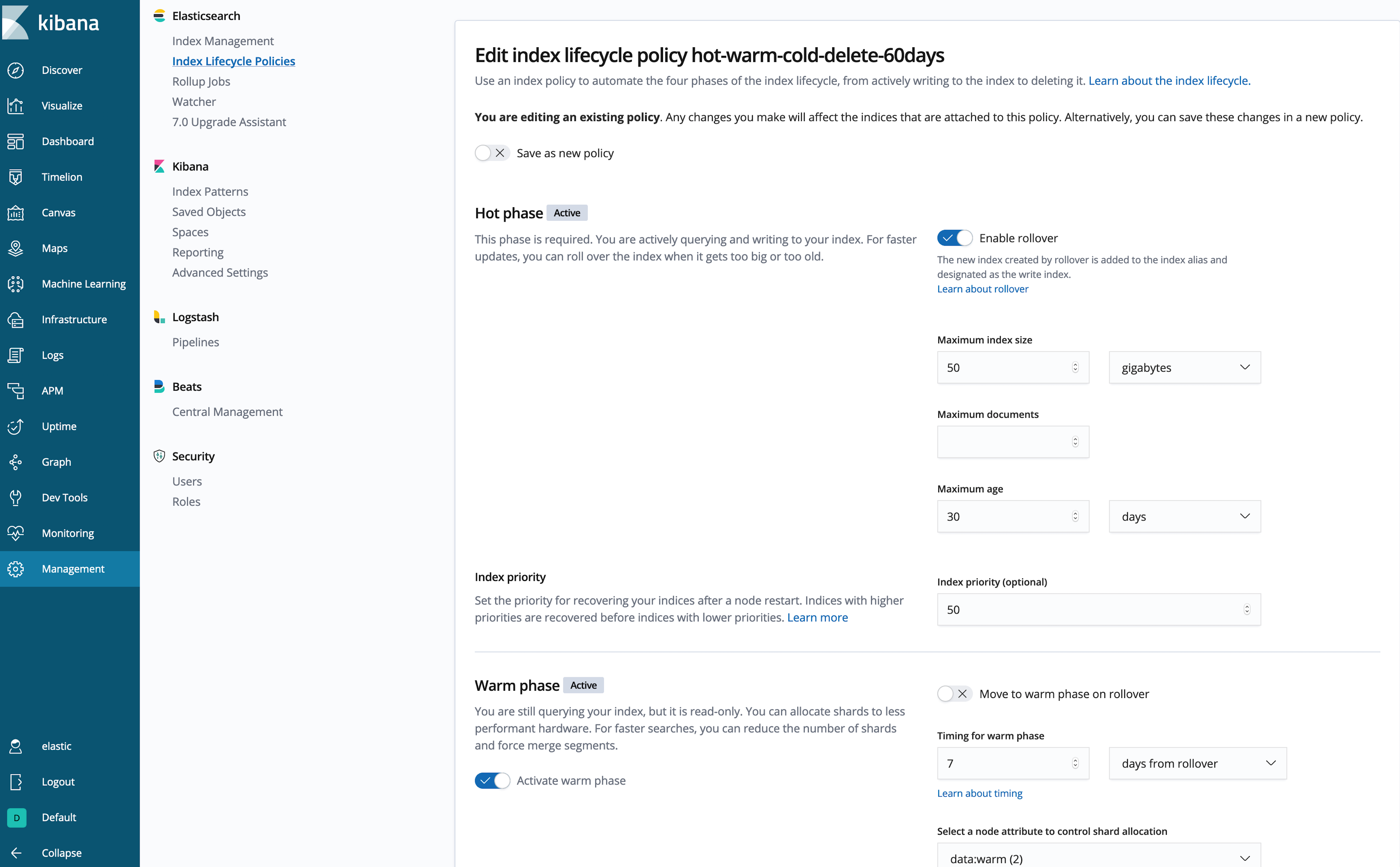 Así está mejor.
Así está mejor.
Ahora debemos asociar la política nueva hot-warm-cold-delete-60days con los índices de Beats y Logstash, y asegurarnos de que escriban en los nodos de datos hot. Como Beats y Logstash (de forma predeterminada) gestionan sus propias plantillas, usaremos la coincidencia de varias plantillas para agregar la política y las reglas de asignación a los patrones de índice a los que deseas aplicar la política de ILM. Debido a que esta plantilla coincide con los patrones de índice de Beats y Logstash, tendrás que saber con qué patrones de índice deseas establecer la coincidencia. Aquí usamos logstash-, metricbeat- y filebeat-*, puedes agregar aquí tantos como desees, suponiendo que Beats y Logstash tienen habilitado el soporte de ILM en su configuración. Si agregas aquí patrones de índice para productores de datos que no soportan ILM, deberás cumplir manualmente con los requisitos para el desplazamiento especificado en esta política.
PUT _template/hot-warm-cold-delete-60days-template
{
"order": 10,
"index_patterns": ["logstash-*", "metricbeat-*", "filebeat-*"],
"settings": {
"index.routing.allocation.require.data": "hot",
"index.lifecycle.name": "hot-warm-cold-delete-60days"
}
}
Habilitación de ILM en Beats o Logstash
Por último, activemos ILM para Beats y Logstash.
En Beats 6.7:
output.elasticsearch:
ilm.enabled: true
En Logstash 6.7:
output {
elasticsearch {
ilm_enabled => true
}
}
Consulta la versión correspondiente de la documentación para conocer cómo habilitar ILM en Beats y Logstash, debido a que puede ser diferente en las versiones más nuevas.
Ahora, cualquier índice nuevo que coincida con los patrones de índice creará los índices nuevos en los nodos calientes, e ILM aplicará la política hot-warm-cold-delete-60days.
Actualización de la política de ILM
Puedes actualizar la política de ILM en cualquier momento… Sin embargo, los cambios que hagas en la política solo se aplicarán cuando cambie la fase. Por ejemplo, si tu índice se encuentra actualmente en la fase caliente (y en espera de la fase tibia), cualquier cambio que hagas en la fase caliente no tendrá efecto sobre ese índice, pero cualquier cambio en la fase tibia se aplicará cuando entre en dicha fase. Esto se hace para evitar repetir las acciones de una fase dada. Puedes ver el estado de ILM del índice mediante la API de explicación.
Mucha de la información anterior sobre cómo lograr una arquitectura caliente-tibia antes de ILM sigue siendo válida, debido a que se usa la misma mecánica subyacente. Sin embargo, ahora con ILM, no se necesita Curator para lograr este patrón.
De cara al futuro
A partir de la versión 7.0, Beats y Logstash usan la gestión de ciclo de vida del índice de forma predeterminada cuando se conectan a un cluster que soporta la gestión de ciclo de vida. Beats también trasladó la mayoría de las configuraciones de ILM del espacio de nombre output.elasticsearch.ilm al espacio de nombre setup.ilm. Por ejemplo, consulta la documentación de Filebeat 7.0. También a partir del sistema 7.0, los índices como .watcher-history-* pueden gestionarse mediante ILM.
ILM facilita la implementación de una arquitectura de ahorro de costos, como la caliente-tibia-fría, en tus índices temporales. Prueba ILM hoy mismo y cuéntanos lo que piensas en nuestros foros de Debate. ¡Disfrútalo!