Replicación entre datacenters con replicación entre clusters de Elasticsearch
La replicación entre datacenters es desde hace tiempo un requisito para las aplicaciones de misión crítica en Elasticsearch; y previamente se resolvía de forma parcial con tecnologías adicionales. Con la introducción de la replicación entre clusters en Elasticsearch 6.7, no se necesitan tecnologías adicionales para replicar los datos en todos los datacenters, las regiones geográficas o los clusters de Elasticsearch.
La replicación entre clusters (CCR) permite la replicación de índices específicos de un cluster de Elasticsearch a uno o más clusters de Elasticsearch. Además de la replicación entre datacenters, existe una variedad de casos de uso adicionales de CCR, entre los que se incluyen la localización de datos (replicación de datos para que estén más cerca de un usuario/servidor de aplicaciones, como la replicación de un catálogo de productos a 20 datacenters diferentes en todo el mundo) o la replicación de datos de un cluster de Elasticsearch a un cluster de reportes central (por ejemplo, 1000 sucursales bancarias en todo el mundo que escriben en su cluster de Elasticsearch local y replican a un cluster en la casa central para fines de reportes).
En este tutorial de replicación entre datacenters con CCR, mencionaremos brevemente los conceptos básicos de CCR, destacaremos las opciones de arquitectura y compensaciones, configuraremos un despliegue entre datacenters de ejemplo y destacaremos los comandos administrativos. Si deseas ver una introducción técnica a CCR, consulta Seguir al líder: Una introducción a la replicación entre clusters en Elasticsearch.
CCR es una característica de nivel platino y está disponible con la licencia de prueba gratuita de 30 días que puede activarse con la API de inicio de prueba o directamente desde Kibana.
Conceptos básicos de la replicación entre clusters (CCR)
La replicación se configura a nivel de índice (o se basa en un patrón de índice)
CCR se configura a nivel de índice en Elasticsearch. Al configurar la replicación a nivel de índice, hay una gran cantidad de estrategias de replicación disponibles, entre las que se incluye replicar algunos índices en una dirección y otros en otra dirección, y arquitecturas granulares entre datacenters.
Los índices replicados son de solo lectura
Un índice puede replicarse en uno o más clusters de Elasticsearch. Cada cluster que esté replicando el índice mantiene una copia de solo lectura de este. El índice activo capaz de aceptar escrituras se denomina líder. Las copias pasivas de solo lectura de dicho índice se denominan seguidores. No existe el concepto de elección de un nuevo líder, cuando un índice líder no está disponible (por ejemplo, debido a una interrupción en el datacenter/cluster), el administrador de clusters o aplicaciones debe elegir explícitamente otro índice para escrituras (muy probablemente en otro cluster).
Se eligieron valores predeterminados de CCR para una amplia variedad de casos de uso de alto rendimiento
No se recomienda cambiar los valores predeterminados a menos que se comprenda en detalle cómo el ajuste de un valor afectará al sistema. La mayoría de las opciones pueden encontrarse en la API de creación de seguidor, como “max_read_request_operation_count” o “max_retry_delay”. Pronto publicaremos un blog sobre cómo afinar estos parámetros para cargas de trabajo únicas.
Requisitos de seguridad
Como se describe en CCR Getting Started Guide (Guía de primeros pasos con CCR), el usuario en el cluster de origen debe tener el privilegio de cluster “read_ccr” y los privilegios de índice “monitor” y “read”. Dentro del cluster de destino, el usuario debe tener el privilegio de cluster “manage_ccr” y los privilegios de índice “monitor”, “read”, “write” y “manage_follow_index”. También pueden usarse sistemas de autenticación centralizados, como LDAP.
Ejemplos de arquitecturas de CCR entre datacenters
Datacenters de producción y DR
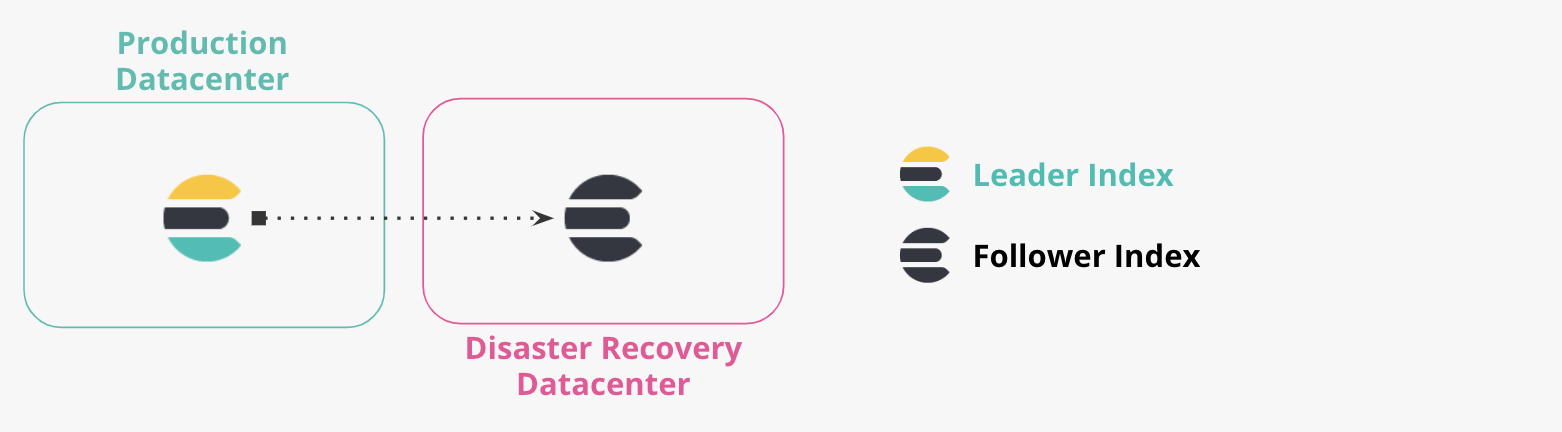
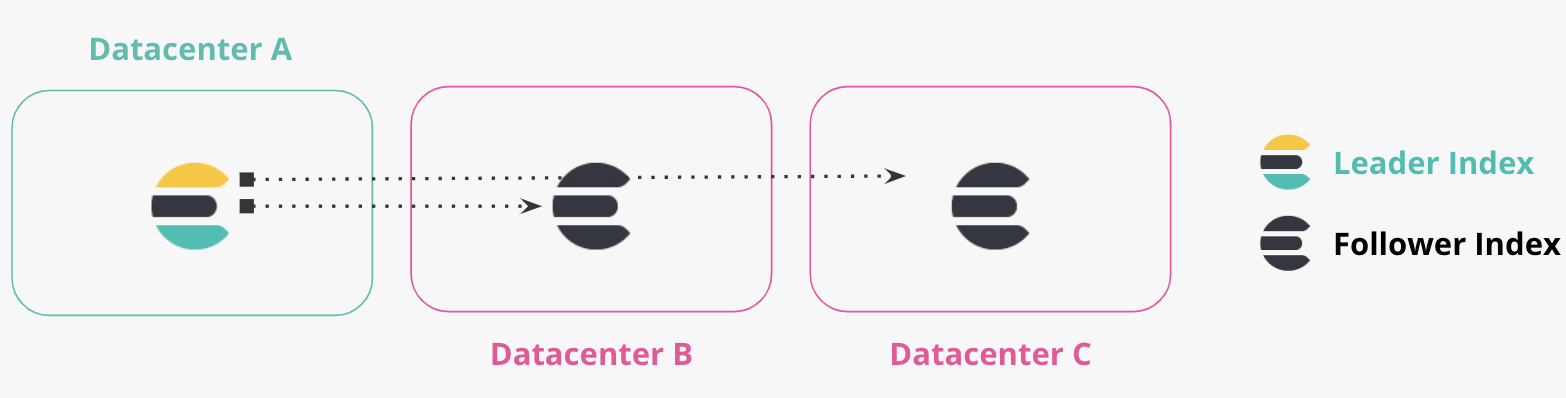
Más de dos datacenters
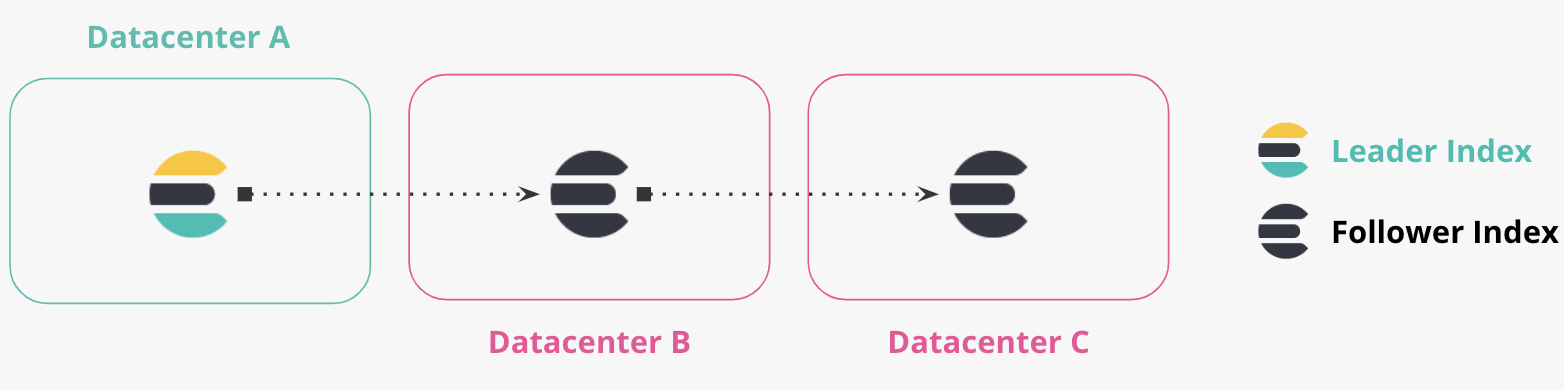
Replicación en cadena
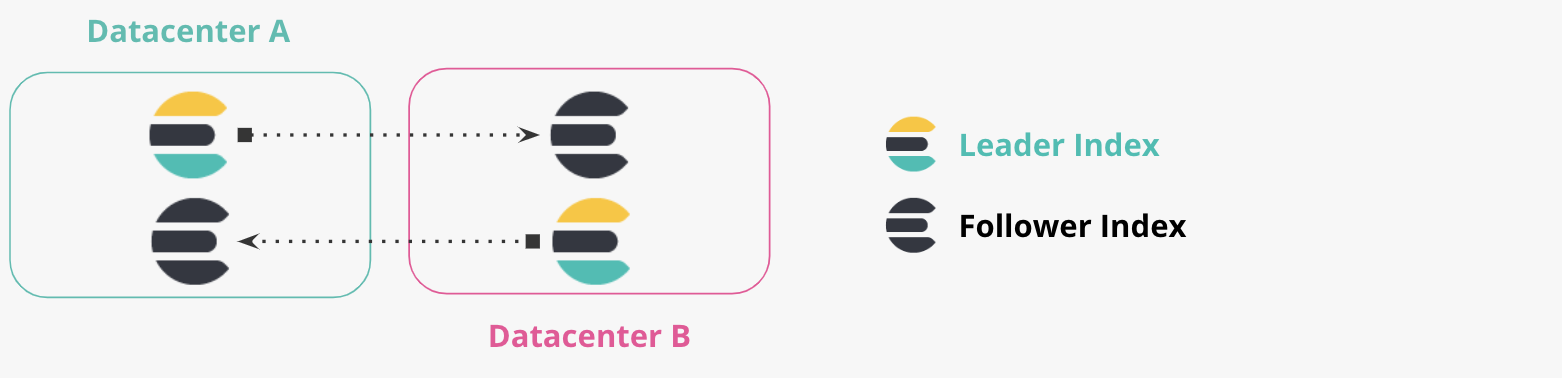
Replicación bidireccional
Tutorial de despliegue entre datacenters
1. Configuración
Para este tutorial, usaremos dos clusters, ambos estarán en nuestra computadora local. Puedes ubicar los clusters donde desees.
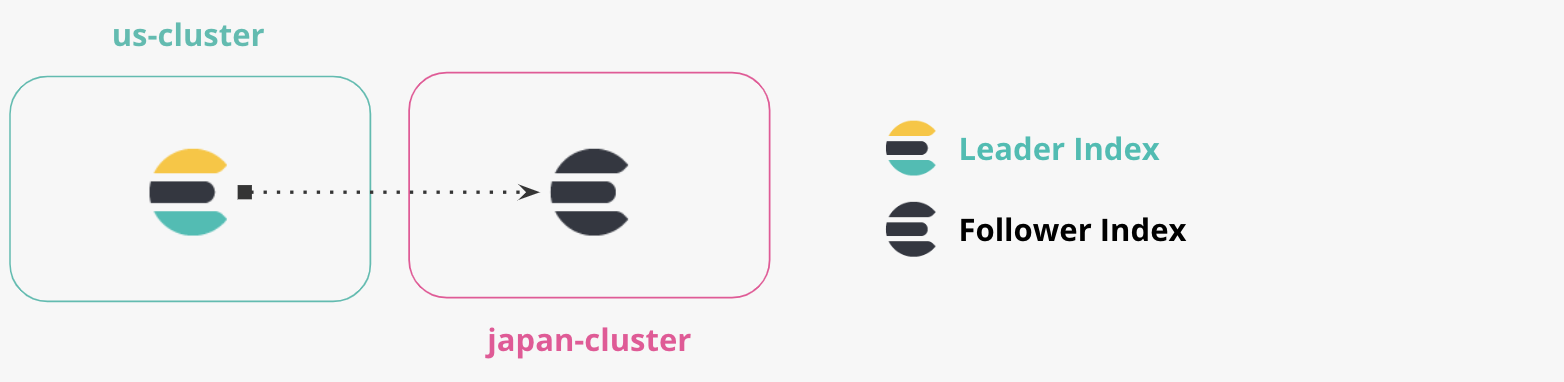
- ‘us-cluster’: este es nuestro “cluster de EE. UU.”, y lo ejecutaremos de forma local en el puerto 9200. Replicaremos los documentos del cluster de EE. UU. al cluster de Japón.
- ‘japan-cluster’: este es nuestro “cluster de Japón”, y lo ejecutaremos de forma local en el puerto 8200. El cluster de Japón mantendrá un índice replicado del cluster de EE. UU.
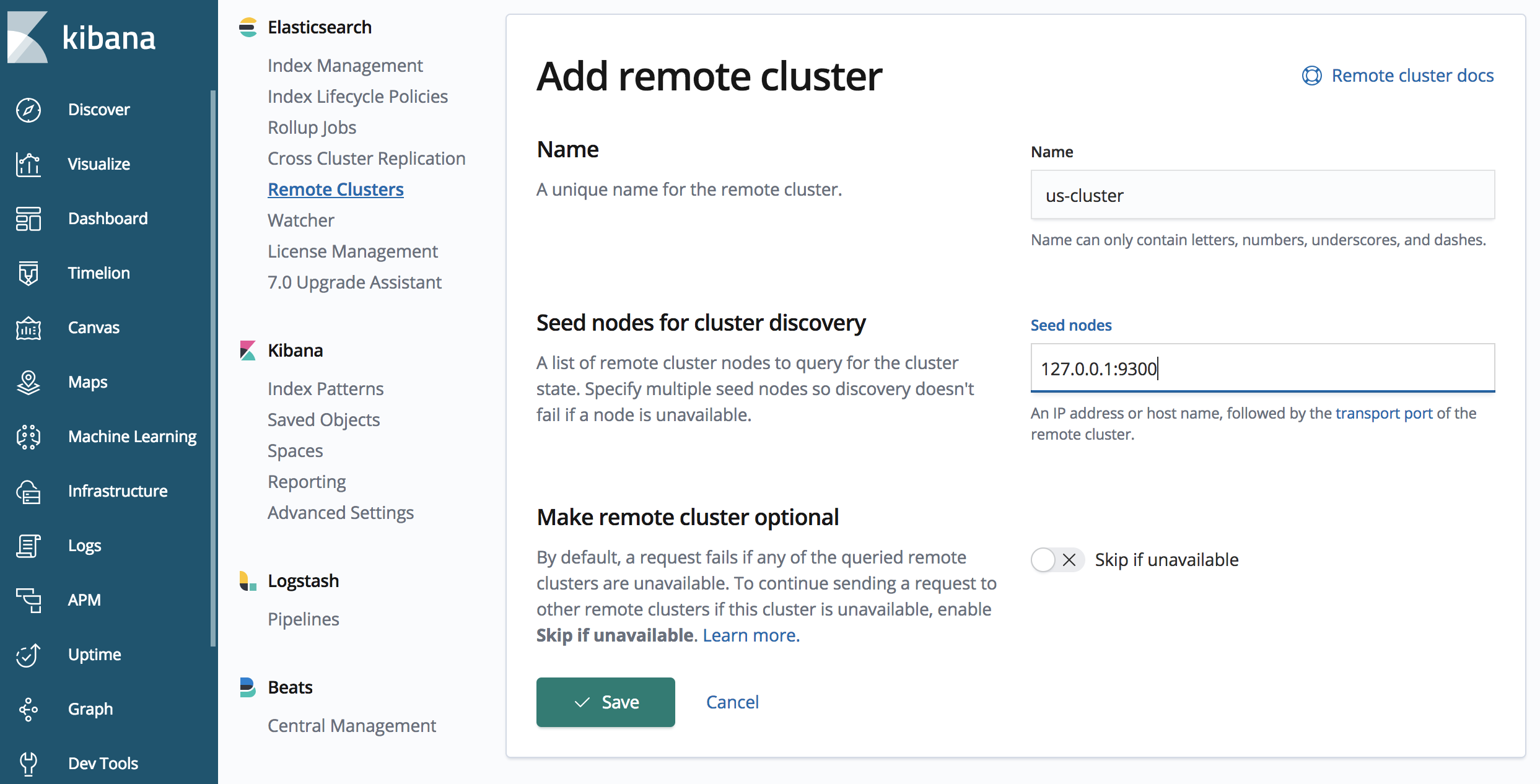
2. Definición de clusters remotos
Al configurar CCR, los clusters de Elasticsearch deben saber sobre la existencia de otros clusters de Elasticsearch. Este requisito es unidireccional: el cluster de destino mantendrá conexiones unidireccionales con el cluster de origen. Definimos otros clusters de Elasticsearch como clusters remotos y especificamos un alias para describirlos.
Queremos asegurarnos de que nuestro ‘japan-cluster’ sepa sobre la existencia del ‘us-cluster’. La replicación en CCR se basa en la extracción, y no es necesario que especifiquemos una conexión entre el ‘us-cluster’ y el ‘japan-cluster’.
Definamos el ‘us-cluster’ a través de una llamada de API en el ‘japan-cluster’.
# Desde el japan-cluster, definiremos cómo se puede acceder al us-cluster
PUT /_cluster/settings
{
"persistent" : {
"cluster" : {
"remote" : {
"us-cluster" : {
"seeds" : [
"127.0.0.1:9300"
]
}
}
}
}
}
(Para los comandos basados en API, recomendamos usar la consola de herramientas de desarrollo dentro de Kibana, para acceder a ella, ve a Kibana -> Dev tools [Herramientas de desarrollo] -> Console [Consola]).
La llamada de API anterior define un cluster remoto con el alias “us-cluster”, al cual puede accederse en “127.0.0.1:9300”. Pueden especificarse una o más semillas (seeds); por lo general se recomienda especificar más de una, en caso de que una semilla no esté disponible durante el protocolo de intercambio.
Se incluyen más detalles sobre la configuración de clusters remotos en nuestra documentación de referencia sobre cómo definir un cluster remoto.
También es importante observar el puerto 9300 para la conexión con el ‘us-cluster’, el ‘us-cluster’ espera el protocolo HTTP en el puerto 9200 (debido a que es la opción predeterminada y se especificó en el archivo elasticsearch.yml para nuestro 'us-cluster'). Sin embargo, la replicación se realiza con el protocolo de transporte de Elasticsearch (para la comunicación nodo a nodo); y el puerto predeterminado es el 9300.
Existe una UI de administración para los clusters remotos dentro de Kibana; en este tutorial revisaremos tanto la UI como la API para CCR. Para acceder a la UI para clusters remotos en Kibana, haz clic en “Management” (Administración, ícono de engranaje) en el panel de navegación izquierdo, luego dirígete a “Remote Clusters” (Clusters remotos) en la sección Elasticsearch.
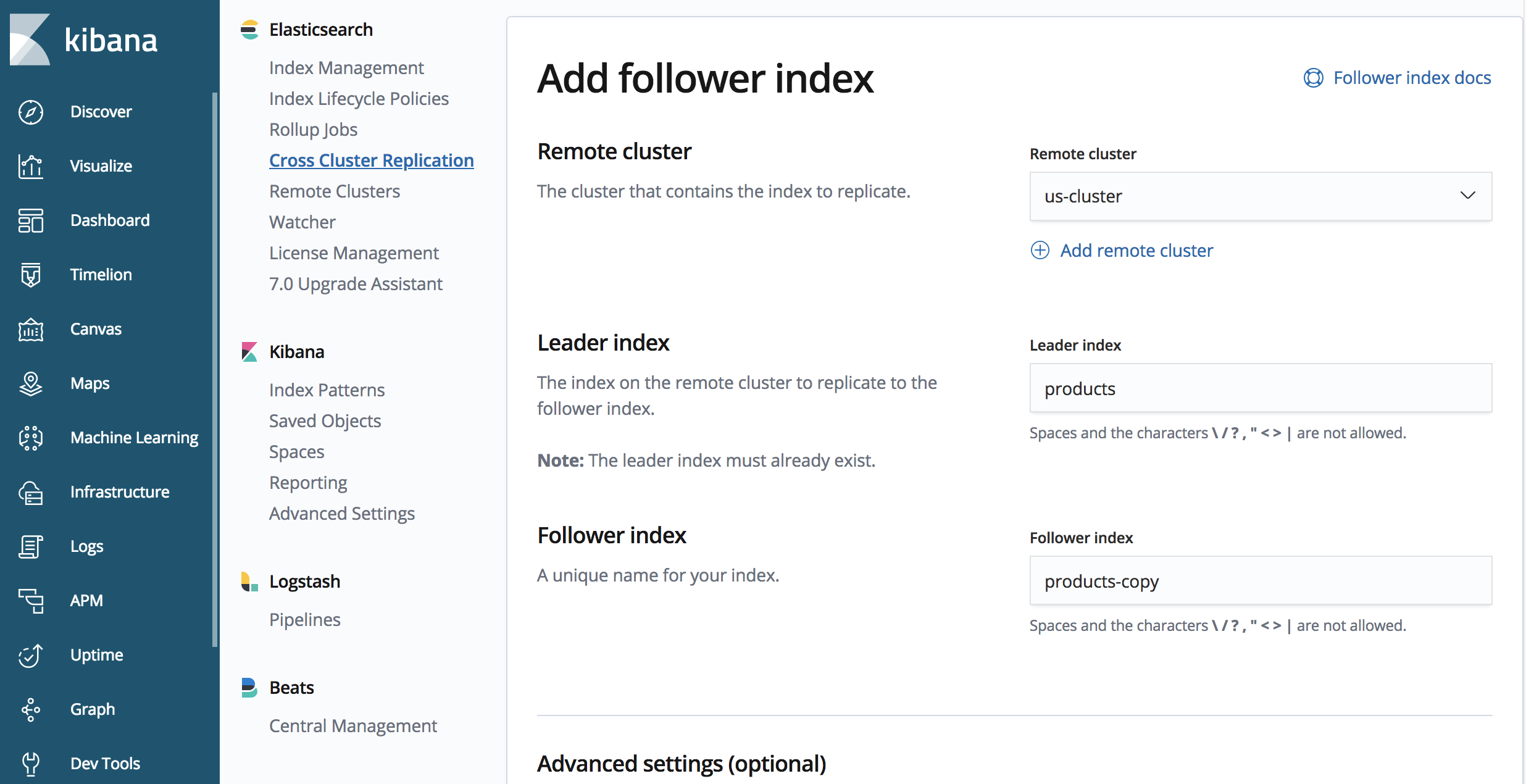
3. Creación de un índice para replicación
Creemos un índice denominado ‘products’ en nuestro ‘us-cluster’, lo replicaremos desde nuestro ‘us-cluster’ de origen a nuestro ‘japan-cluster’ de destino:
En el ‘us-cluster’:
# Crea un índice de productos
PUT /products
{
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0,
"soft_deletes" : {
"enabled" : true
}
}
},
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "keyword"
}
}
}
}
}
Es posible que hayas notado la configuración “soft_deletes”. Las eliminaciones parciales (soft deletes) son necesarias para que un índice funcione como índice líder para CCR (consulta Los que no conocen la historia para saber más):
soft_deletes: Una eliminación parcial ocurre cuando un documento existente se elimina o actualiza. Al retener estas eliminaciones parciales por límites configurables, el historial de operaciones puede retenerse en los shards líderes y ponerse a disposición de las tareas del shard seguidor a medida que reproduce el historial de operaciones.
A medida que un shard seguidor replica las operaciones del líder, dejará marcadores en los shards líderes para que el líder sepa en qué parte del historial se encuentran los seguidores. Las operaciones de eliminación parcial debajo de estos marcadores pueden fusionarse. Sobre estos marcadores, los shards líderes retendrán estas operaciones hasta por el período de un alquiler de retención del historial de shard, el cual es de 12 horas, de forma predeterminada. Este período determina la cantidad de tiempo que un seguidor puede estar desconectado sin ponerse en riesgo de retrasarse irremediablemente y necesitar que el líder vuelva a iniciarlo.
4. Inicio de la replicación
Ahora que ya creamos un alias para nuestro cluster remoto y un índice que deseamos replicar, iniciemos la replicación.
En nuestro ‘japan-cluster’:
PUT /products-copy/_ccr/follow
{
"remote_cluster" : "us-cluster",
"leader_index" : "products"
}
El punto final contiene ‘products-copy’, este es el nombre del índice replicado dentro del cluster ‘japan-cluster’. Estamos replicando desde el cluster ‘us-cluster’ que definimos previamente, y en el cluster ‘us-cluster’, el nombre del índice que estamos replicando es ‘products’.
Es importante observar que nuestro índice replicado es de solo lectura y no puede aceptar operaciones de escritura.
Eso es todo. Configuramos un índice para que se replique de un cluster de Elasticsearch a otro.
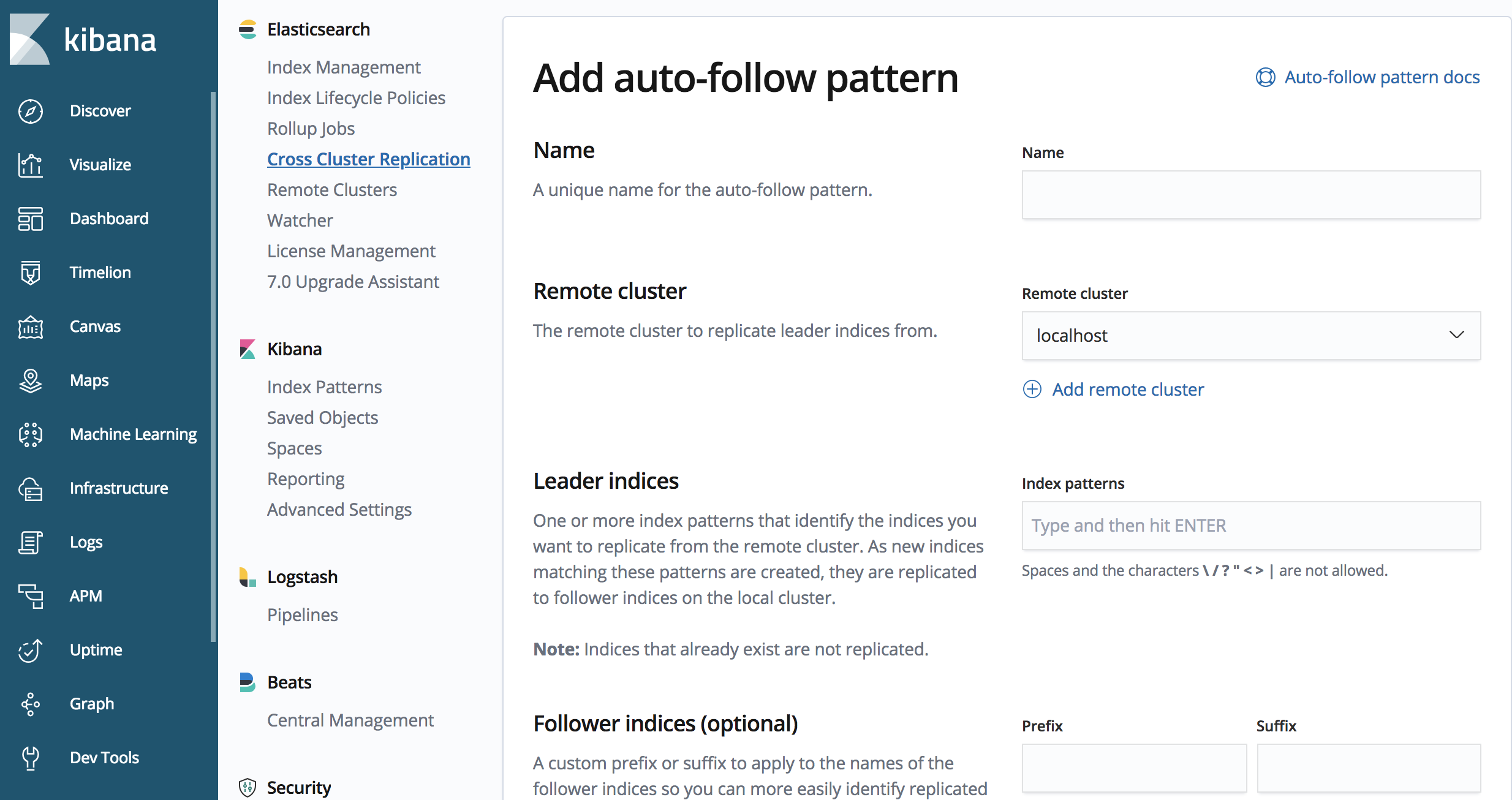
Inicio de la replicación para patrones de índice
Es posible que hayas notado que el ejemplo anterior no funcionará muy bien en los casos de uso basados en tiempo, en los que hay un índice por día o por una cantidad de datos. La API de CCR también contiene métodos para definir patrones de autoseguimiento, es decir, cuáles patrones de índice se deberían replicar.
Podemos usar la API de CCR para definir un patrón de autoseguimiento.
PUT /_ccr/auto_follow/beats
{
"remote_cluster" : "us-cluster",
"leader_index_patterns" :
[
"metricbeat-*",
"packetbeat-*"
],
"follow_index_pattern" : "{{leader_index}}-copy"
}
La llamada de API del ejemplo anterior replicará un índice que comience con ‘metricbeat’ o ‘packetbeat’.
También podemos usar la UI de CCR en Kibana para definir un patrón de autoseguimiento.
5. Prueba de configuración de replicación
Ahora que nuestro índice de productos se replicó de ‘us-cluster’ a ‘japan-cluster’, insertemos un documento de prueba y verifiquemos que se haya replicado.
En el cluster ‘us-cluster’:
POST /products/_doc
{
"name" : "My cool new product"
}
Ahora busquemos en ‘japan-cluster’ para asegurarnos de que se haya replicado el documento:
GET /products-copy/_search
Debería haber un solo documento, escrito en ‘us-cluster’ y replicado en ‘japan-cluster’.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "products-copy",
"_type" : "_doc",
"_id" : "qfkl6WkBbYfxqoLJq-ss",
"_score" : 1.0,
"_source" : {
"name" : "My cool new product"
}
}
]
}
}
Notas de administración entre datacenters
Revisemos algunas de las API administrativas para CCR y configuraciones ajustables, y describamos el método para convertir un índice replicado en un índice normal en Elasticsearch.
API administrativas para replicación
Existen varias API administrativas útiles para CCR en Elasticsearch. Pueden ser útiles para depurar la replicación, modificar la configuración de la replicación o recopilar diagnósticos detallados.
# Muestra todas las estadísticas relacionadas con CCR
GET /_ccr/stats
# Pausa la replicación de un índice dado
POST //_ccr/pause_follow
# Reanuda la replicación; en la mayoría de los casos, luego de pausarla
POST //_ccr/resume_follow
{
}
# Deja de seguir un índice (deteniendo la replicación del índice de destino), lo que primero requiere que se pause la replicación
POST //_ccr/unfollow
# Estadísticas de un índice de seguimiento
GET //_ccr/stats
# Elimina un patrón de autoseguimiento
DELETE /_ccr/auto_follow/
# Ve todos los patrones de autoseguimiento u obtén un patrón de autoseguimiento por nombre
GET /_ccr/auto_follow/
GET /_ccr/auto_follow/
Hay más detalles disponibles sobre las API administrativas de CCR en la documentación de referencia de Elasticsearch.
Conversión de un índice seguidor en un índice normal
Podemos usar un subconjunto de las API administrativas anteriores para revisar la conversión de un índice seguidor en un índice normal en Elasticsearch que sea capaz de aceptar escrituras.
En nuestro ejemplo anterior, la configuración era bastante simple. Recuerda que el índice ‘products-copy’ replicado en nuestro ‘japan-cluster’ es de solo lectura, no puede aceptar escrituras. En caso de que quisiéramos convertir el índice ‘products-copy’ en un índice normal en Elasticsearch (capaz de aceptar escrituras), entonces podemos realizar los comandos siguientes. Ten en cuenta que las escrituras en nuestro índice original ('products') pueden continuar, y es posible que queramos restringir las escrituras en nuestro índice ‘products’ primero, antes de convertir el índice ‘products-copy’ en un índice normal de Elasticsearch.
# Pausa la replicación
POST //_ccr/pause_follow
# Cierra el índice
POST /my_index/_close
# Deja de seguir
POST //_ccr/unfollow
# Abre el índice
POST /my_index/_open
Continúa explorando la replicación entre clusters (CCR) en Elasticsearch
Redactamos esta guía para ayudarte a dar los primeros pasos con CCR en Elasticsearch, esperamos que sea suficiente para que te familiarices con CCR, aprendas sobre las distintas API de CCR (incluidas las UI disponibles en Kibana) y experimentes con la característica. Entre los recursos adicionales se incluyen Getting started with cross cluster replication guide (Guía de primeros pasos con la replicación entre clusters) y Cross Cluster Replication APIs reference guide (Guía de referencia de las API de replicación entre clusters).
Como siempre, déjanos comentarios y consultas en nuestros foros de discusión, nos aseguraremos de responder lo más pronto posible.