Instrucciones para aportar un plugin al agente Java de APM de Elastic
Idealmente, un agente de APM instrumentaría y rastrearía automáticamente cualquier marco de trabajo y biblioteca que se sepa que existe. En realidad, lo que los agentes de APM soportan refleja una combinación de capacidad y priorización. Nuestra lista de tecnologías y marcos de trabajo soportados crece constantemente conforme a la priorización basada en las aportaciones de nuestros valiosos usuarios. De todos modos, si usas un agente Java de APM de Elastic y omites algo que no se soporta de fábrica, existen varias maneras de rastrearlo.
Por ejemplo, puedes usar nuestra API pública para rastrear tu propio código y nuestra increíble configuración de rastreo de método personalizado para el monitoreo básico de métodos específicos en bibliotecas de terceros. Sin embargo, si deseas tener una visibilidad ampliada de datos específicos de código de terceros, probablemente necesites hacer un poco más. Afortunadamente, nuestro agente es open source, por lo que puedes hacer todo lo que nosotros podemos hacer. Y puedes aprovechar y compartirlo con la comunidad. Una gran ventaja de esto es recibir más comentarios y hacer que tu código funcione en entornos adicionales.
Agradeceremos enormemente cualquier aporte que amplíe nuestras capacidades, siempre y cuando se ajuste a varios estándares que debemos hacer cumplir, tal como lo esperan nuestros usuarios. Por ejemplo, echa un vistazo a esta solicitud de extracción para dar soporte a las llamadas de cliente OkHttp o esta extensión de nuestro soporte de JAX-RS. Entonces, antes de poner manos a la obra y comenzar a codificar, estas son algunas cosas que debes tener en cuenta cuando realices aportes a nuestra base de código; las presentamos en un caso de prueba que servirá para esta guía de implementación de plugin.
Caso de prueba: Instrumentación del cliente REST de Java de Elasticsearch
Antes de lanzar nuestro agente, queríamos dar soporte a nuestro propio cliente de almacén de datos. Queríamos que los usuarios del cliente REST de Java de Elasticsearch supieran lo siguiente:
- Que se realizó una búsqueda en Elasticsearch.
- El tiempo que tardó esta búsqueda.
- Cuál nodo de Elasticsearch respondió a la solicitud de búsqueda.
- Cierta información sobre el resultado de la búsqueda, como el código de estado.
- Si se produjo un error.
- La búsqueda en sí de las operaciones
_search.
También decidimos solo brindar soporte para las búsquedas síncronas como primer paso y retrasar las asíncronas hasta que tengamos una infraestructura adecuada.
Extrajimos el código relevante, lo cargamos en Gist y lo mencionamos a lo largo del blog. Ten en cuenta que aunque no es el código real que encontrarías en nuestro repositorio de GitHub, es completamente funcional y relevante.
Aspectos específicos del agente Java
Es necesario tener en cuenta ciertas consideraciones especiales al escribir un código de agente Java. Repasémoslas brevemente antes de analizar nuestro caso de prueba.
Instrumentación del código de bytes
No te preocupes, no necesitarás escribir nada en código de bytes, usaremos la biblioteca mágica Byte Buddy (que, a su vez, se basa en ASM) para eso. Por ejemplo, las anotaciones que usamos para indicar qué insertar al comienzo y al final del método instrumentado. Solo debes tener en cuenta que una parte del código que escribas no se ejecutará realmente donde lo escribes, sino que se insertará como código de bytes compilado en el código de otra persona (lo cual es un gran beneficio de la apertura; puedes ver exactamente qué código se inserta).

Visibilidad de clase
Este puede ser el factor más esquivo y donde se ocultan la mayoría de los errores. Es necesario conocer bien el origen desde el cual se cargará cada parte del código y lo que puede suponerse que estará disponible para este en el tiempo de ejecución. Al agregar un plugin, el código se cargará al menos en dos ubicaciones diferentes: una es el contexto de la aplicación o biblioteca instrumentada, y la otra es el contexto del código del agente principal. Por ejemplo, tenemos una dependencia en HttpEntity, una clase de cliente HTTP Apache incluida con el cliente de Elasticsearch. Como este código está insertado en una de las clases del cliente, sabemos que esta dependencia es válida. Por otra parte, al usar IOUtils (una clase de agente principal), no podemos suponer ninguna otra dependencia además de Java principal y agente principal. Si no estás familiarizado con los conceptos de carga de clase Java, puede ser útil obtener una idea general al respecto (por ejemplo, leyendo esta interesante visión general).
Sobrecarga
Bien, el rendimiento siempre es una consideración. Nadie quiere escribir código ineficiente. Sin embargo, al escribir código agente, no tenemos derecho a tomar las decisiones habituales de compensación de sobrecarga que normalmente tomamos cuando escribimos código. Debemos ser eficientes en todos los aspectos. Somos los invitados, y se espera que hagamos nuestro trabajo sin causar inconvenientes.
Para obtener una visión general más detallada acerca de la sobrecarga de rendimiento del agente y cómo ajustarlo, lee este interesante blog.
Concurrencia
Normalmente, la primera operación de rastreo de cada evento se ejecutará en el hilo de gestión de solicitudes, uno de los muchos hilos en un pool. Debemos hacer lo mínimo indispensable en este hilo y hacerlo rápido para liberarlo y que se ocupe de asuntos más importantes. Los productos secundarios de estas acciones se gestionan en colecciones compartidas en las que se exponen a problemas de concurrencia. Por ejemplo, el objeto Span que creamos en la entrada misma se actualiza varias veces en todo este código en el hilo de gestión de solicitudes, pero más adelante lo usa un hilo diferente para la serialización y el envío al servidor de APM. Además, debemos saber si rastreamos operaciones síncronas o potencialmente asíncronas. Si el rastreo puede comenzar en un hilo y continuar en otros, debemos tenerlo en cuenta.
Regresemos al caso de prueba
A continuación encontrarás una descripción de lo que se necesitó para implementar el plugin del cliente REST de Elasticsearch; está dividida en tres pasos por cuestiones de comodidad.
Advertencia: A partir de ahora, se vuelve muy técnico.
Paso 1: Selección de lo que se instrumentará
Este es el paso más importante del proceso. Si investigamos un poco y hacemos esto correctamente, es más probable que encontremos los métodos adecuados y que lo hagamos muy fácil. Qué tener en cuenta:
- Relevancia: debemos instrumentar métodos que cumplan con lo siguiente:
- Capturen exactamente lo que deseamos capturar. Por ejemplo, debemos asegurarnos de que la hora de finalización menos la hora de inicio del método refleje la duración del intervalo que deseamos crear.
- No sean falsos positivos. Si se invocó un método, siempre nos interesa saberlo.
- No sean falsos negativos. Siempre se llama al método cuando se ejecuta la acción relacionada con el intervalo.
- Tengan toda la información relevante disponible cuando se ingrese o salga de ellos.
- Compatibilidad con versiones posteriores: nuestro objetivo es una API central con pocas probabilidades de cambios frecuentes. No queremos actualizar el código con cada versión menor de la biblioteca rastreada.
- Compatibilidad con versiones anteriores: ¿hasta qué versión soportará esta instrumentación?
Sin saber nada del código del cliente (a pesar de que es de Elastic), descargamos la versión más reciente en ese momento, la 6.4.1, y comenzamos a investigarla. El cliente REST de Java de Elasticsearch ofrece las API tanto de nivel alto como bajo, en las que la API de nivel alto depende de la de nivel bajo, y eventualmente todas las búsquedas pasarán por esta última. Por lo tanto, para soportar ambas, naturalmente solo buscaríamos en el cliente de nivel bajo.
Indagando en el código, encontramos un método con la firma Response performRequest(Request request) (aquí en GitHub). Existen cuatro anulaciones adicionales del mismo método, todas llaman a esta y están marcadas como deprecated. Además, este método llama a performRequestAsyncNoCatch. El único otro método que llama a esta última es un método con la firma void performRequestAsync(Request request, ResponseListener responseListener). Después de un poco más de investigación, descubrimos que la ruta asíncrona es exactamente igual a la síncrona: cuatro anulaciones en desuso adicionales llaman a una en uso que llama a performRequestAsyncNoCatch para realizar la búsqueda en sí. Entonces, el método performRequest obtuvo una puntuación del 100 % en relevancia, debido a que captura exactamente todo y solo las búsquedas síncronas, y tanto la información de la búsqueda como la de la respuesta se encuentran disponibles en la entrada y salida: ¡perfecto! Para indicarle a Byte Buddy que deseamos instrumentar este método debemos anular los métodos relevantes que proporcionan buscadores de coincidencias.

De cara al futuro, esta API central nueva parecía una apuesta segura en cuanto a la estabilidad. Sin embargo, mirando hacia atrás, no era tan buena elección: la versión 6.4.0 y anteriores no tenían esta API...
Como era una candidata perfecta para la instrumentación, decidimos usarla y obtener un soporte duradero para el cliente REST de Elasticsearch, y agregar instrumentación adicional para las versiones anteriores. Seguimos un proceso similar para buscar una candidata para esos casos y terminamos con dos soluciones: una para las versiones 5.0.2 a 6.4.0 y otra para la versión 6.4.1 y superiores.
Paso 2: Diseño del código
Usamos Maven, y cada instrumentación nueva que presentamos para soportar una tecnología nueva sería un módulo al que llamamos plugin. En nuestro caso, como queríamos probar tanto los clientes REST de Elasticsearch anteriores y nuevos (lo que significa dependencias de cliente en conflicto), y debido a que la instrumentación sería un poco diferente en cada uno, tenía sentido que cada uno tuviera su propio módulo o plugin. Como ambos son para soportar la misma tecnología, los anidamos bajo un módulo principal común, lo que resultó en la estructura siguiente:
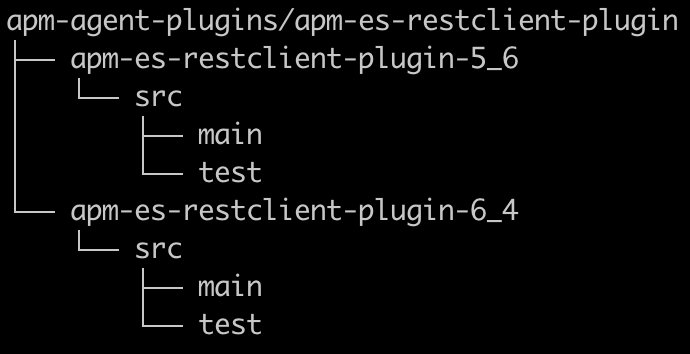
Es importante que solo el código del plugin real se empaquete en el agente, por lo que debes asegurarte de que las dependencias de biblioteca se incluyan como provided y las dependencias de prueba como test en tu pom.xml. Si agregas código de terceros, debe estar sombreado, es decir, reempaquetado para usar el nombre del paquete del agente Java de APM de Elastic raíz.
En cuanto al código real, a continuación encontrarás los requisitos mínimos para agregar un plugin:
La clase Instrumentation
Una implementación de la clase abstracta ElasticApmInstrumentation. Su rol es asistir en la identificación de la clase y el método correctos de instrumentación. Como hacer coincidir el tipo y el método puede extender considerablemente los tiempos de inicialización de las aplicaciones, la clase de instrumentación proporciona algunos filtros que mejoran el proceso de búsqueda de coincidencias; por ejemplo, pasar por alto clases que no contienen un determinado texto en su nombre o clases cargadas mediante un cargador de clases que no tiene visibilidad del tipo que estamos buscando. Además, proporciona cierta metainformación que permite activar y desactivar la instrumentación a lo largo de la configuración.
Observa que ElasticApmInstrumentation se usa como servicio, lo que significa que cada implementación debe estar incluida en un archivo de configuración del proveedor.
El archivo de configuración del proveedor de servicios
Tu implementación ElasticApmInstrumentation es un proveedor de servicios, que se identifica en el tiempo de ejecución a través de un archivo de configuración del proveedor ubicado en el directorio de recursos META-INF/services. El nombre del archivo de configuración del proveedor es el nombre plenamente calificado del servicio y contiene una lista de los nombres plenamente calificados de proveedores de servicios, uno por línea.
La clase Advice
Esta es la clase que proporciona el código real que se insertará en el método rastreado. No implementa una interfaz común, sino que generalmente usa las anotaciones @Advice.OnMethodEnter o @Advice.OnMethodExit de Byte Buddy. De esta forma le informamos a Byte Buddy cuál es el código que deseamos insertar al inicio de un método y justo antes de salir de este (de manera silenciosa o arrojando un Throwable). La API completa de Byte Buddy nos permite hacer todo tipo de cosas sofisticadas, como lo siguiente:
- Crear una variable local en la entrada del método que estará disponible en la salida del método
- Observar y posiblemente reemplazar un argumento del método, el valor devuelto o el
Throwablearrojado cuando corresponda - Observar
esteobjeto
Eventualmente, la estructura de nuestro módulo del cliente REST de Elasticsearch es la siguiente:
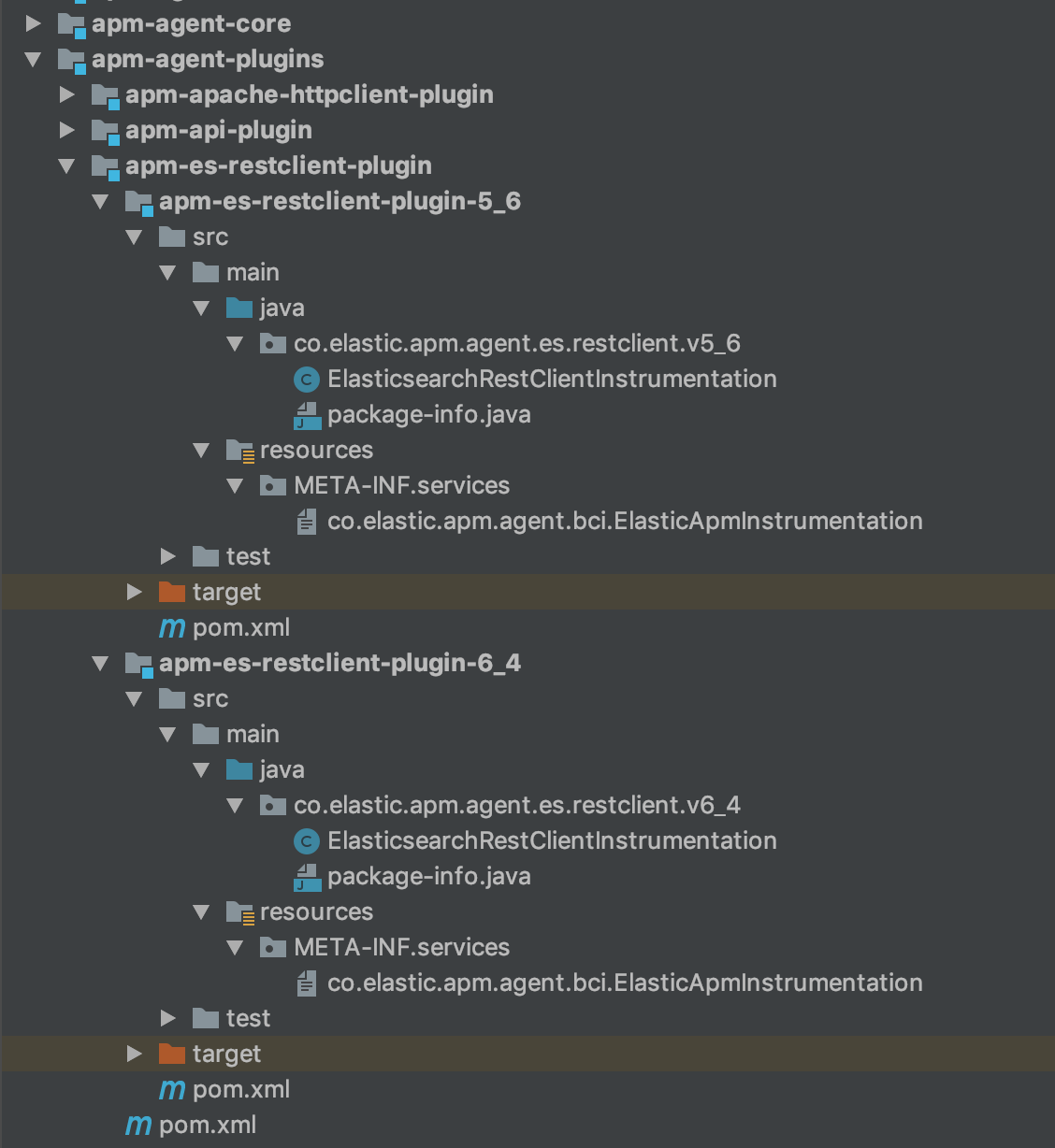
Paso 3: Implementación
Como mencionamos antes, hay algunas características específicas relacionadas con la escritura del código agente. Veamos cómo se desarrollaron estos conceptos en este plugin:
Creación y mantenimiento del intervalo
El APM de Elastic usa intervalos para reflejar cada evento de interés especial, como la gestión de solicitudes HTTP, las búsquedas en la base de datos, las llamadas remotas, etc. Se denomina Transacción al intervalo raíz de cada árbol de intervalos registrado por un agente (consulta más detalles en la documentación sobre nuestro modelo de datos). En este caso, usamos un Span para describir la búsqueda de Elasticsearch, debido a que no es el evento raíz registrado en el servicio. Como en este caso, un plugin normalmente creará un intervalo, lo activará, le agregará datos y eventualmente lo desactivará y finalizará. La activación y desactivación son las acciones de mantener un estado de contexto del hilo que permita obtener el intervalo actualmente activo en cualquier lado en el código (como lo hacemos cuando creamos el intervalo). Un intervalo se debe finalizar, y un intervalo activado se debe desactivar; por lo que try/finallyes una mejor práctica en este aspecto. Además, si ocurre un error, también debemos reportarlo.
No romper nunca el código del usuario (y evitar efectos secundarios)
Además de escribir un código muy “defensivo”, siempre suponemos que nuestro código puede arrojar Excepciones, por lo que usamos suppress = Throwable.class en nuestros consejos. Esto le informa a Byte Buddy que debe agregar un controlador Exception para todos los tipos Throwable arrojados durante la ejecución del código de consejo, lo que garantiza que el código del usuario se ejecute incluso si falla el código insertado.
Además, debemos asegurarnos de no causar ningún efecto secundario con el código de consejo que pueda cambiar el estado del código instrumentado y afectar su comportamiento como resultado. En nuestro caso, esto resultaba relevante para leer el cuerpo de la solicitud de las búsquedas de Elasticsearch. El cuerpo se lee mediante la obtención del flujo de contenido de la solicitud a través de una API getContent. Algunas implementaciones de esta API devolverán una instancia InputStream nueva para cada invocación, mientras que otras devuelven la misma instancia para varias invocaciones por solicitud. Como solo sabemos qué implementación se usa en el tiempo de ejecución, debemos asegurarnos de que leer el cuerpo no evitará que el cliente lo lea. Afortunadamente, también existe una API isRepeatable que nos indica exactamente eso. Si no lo garantizamos, podríamos romper la funcionalidad del cliente.
Visibilidad de clase
De manera predeterminada, la clase Instrumentation también es la clase Advice. Sin embargo, hay una diferencia importante entre ellas debido a su rol. Los métodos Instrumentation se invocan siempre, sin importar si la biblioteca correspondiente a la que pretende instrumentar realmente está disponible o siquiera en uso. Por otra parte, el código Advice se usa solo cuando se detectó la clase relevante de una biblioteca específica. Nuestro código Advice tiene dependencias en el código del cliente REST de Elasticsearch para obtener información como la URL usada para la solicitud, el cuerpo de la solicitud, el código de respuesta, etc. Por lo tanto, sería más seguro compilar el código Advice en una clase diferente y solo consultarlo mediante la clase Instrumentation cuando sea necesario. Ten en cuenta que en la mayoría de los casos, el código Advice tendrá dependencias en la biblioteca instrumentada, por lo que esta puede ser una mejor práctica en general.
Consideraciones respecto de la sobrecarga de rendimiento
Una de las cosas que queríamos hacer es obtener búsquedas _search, lo que significa leer el cuerpo de la solicitud HTTP al que tenemos acceso en la forma de InputStream. No hay mucho que podamos hacer respecto a que debemos almacenar el contenido del cuerpo en algún lugar, por lo que la sobrecarga de memoria tendrá como mínimo la longitud del cuerpo que permitamos leer para cada solicitud rastreada. Sin embargo, sí existen posibilidades en cuanto a las asignaciones de memoria, que se traducen en CPU y pausas por recolección de basura. Entonces, volvemos a usar ByteBuffer para copiar bytes leídos desde el flujo, CharBuffer para almacenar el contenido de la búsqueda hasta que se serialice y envíe al servidor de APM, e incluso CharsetDecoder. De esta forma, no asignamos y desasignamos memoria por solicitud. Esto reduce la sobrecarga a expensas de un código un poco más complicado (código en la clase IOUtils).
Resultado final
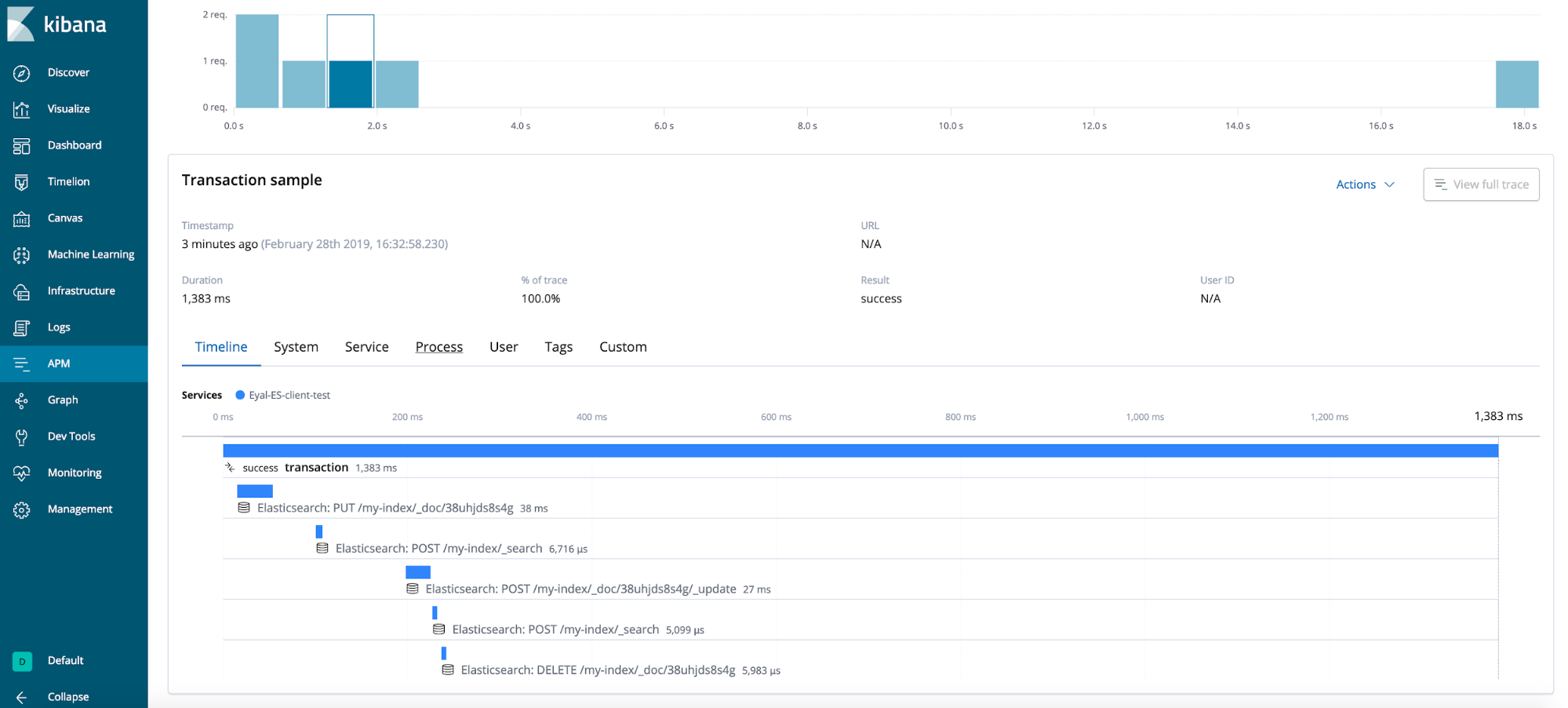
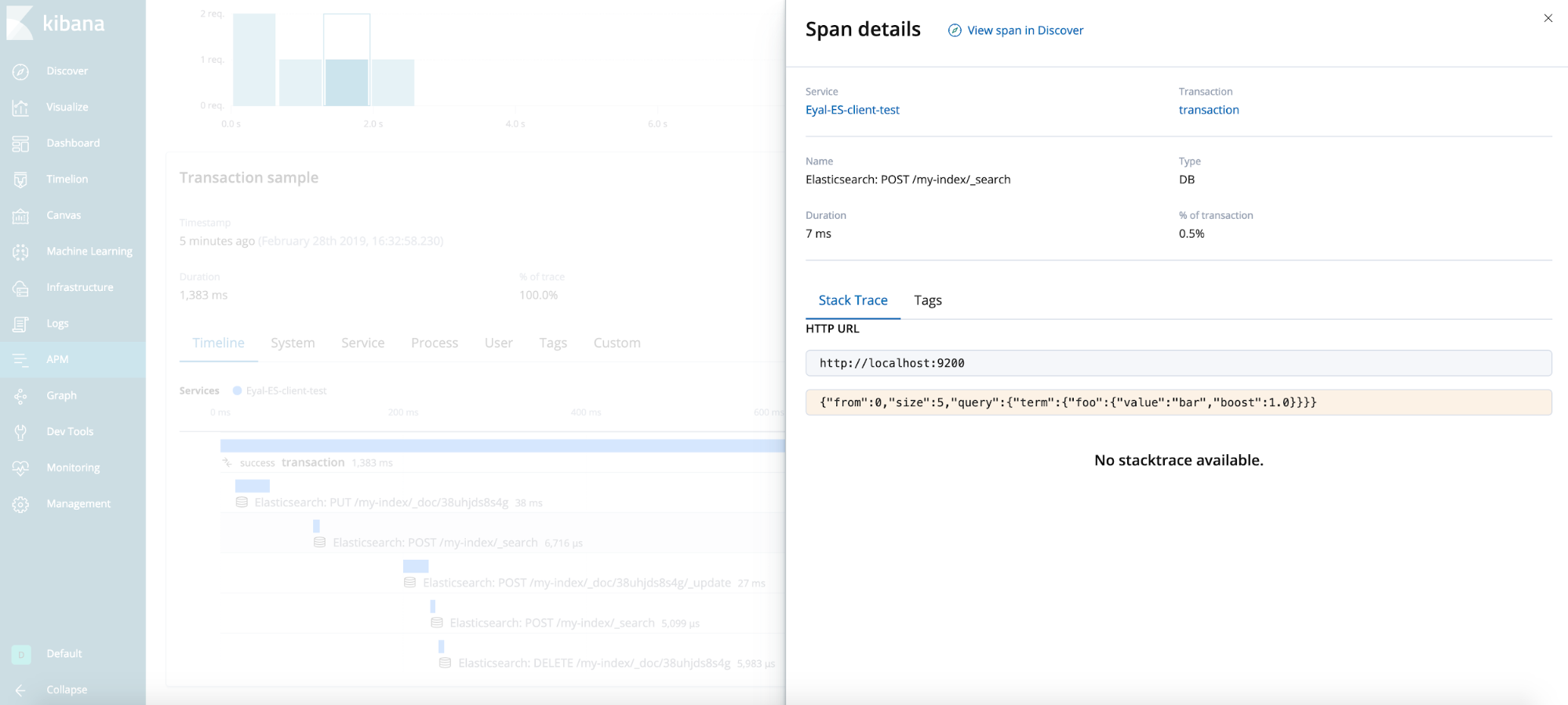
Consejos generales (no demostrados en este caso de prueba)
Cuidado con las llamadas anidadas
En algunos casos, al instrumentar métodos de API puedes encontrarte con una situación en la que un método instrumentado llame a otro método instrumentado. Por ejemplo, un método de anulación que llama a su supermétodo o una implementación de la API que incluye otra. Es importante estar al tanto de tales situaciones, debido a que no quisiéramos que se reporten varios intervalos de la misma acción. No existen reglas que indiquen cuándo esto aplica y cuándo no, y lo más probable es que veas diferentes comportamientos en las distintas situaciones o escenarios; por lo que el consejo en este caso es codificar teniendo esto en cuenta.
Cuidado con el automonitoreo
Asegúrate de que tu código de seguimiento no provoque acciones de invocación que también se rastrearán. En el mejor de los casos, esto resultará en el reporte de operaciones rastreadas que resultan del proceso de rastreo en sí. En el peor, puede llevar al desborde del Elastic Stack. Un ejemplo sería en el rastreo JDBC: cuando intentamos obtener información de la base de datos, usamos la API java.sql.Connection#getMetaData, que puede causar que se ejecute y rastree una búsqueda en la base de datos, lo que lleva a otra invocación de java.sql.Connection#getMetaData y así sucesivamente.
Tener en cuenta las operaciones asíncronas
La ejecución asíncrona significa que un intervalo o una transacción puede crearse en un hilo y luego activarse en otro. Cada intervalo o transacción debe finalizarse exactamente una vez y siempre debe desactivarse en cada hilo en el que se activó. Por ello, se debe estar completamente al tanto de esto.