Metriküberwachung basierend auf der Elasticsearch-Plattform, der SREs vertrauen
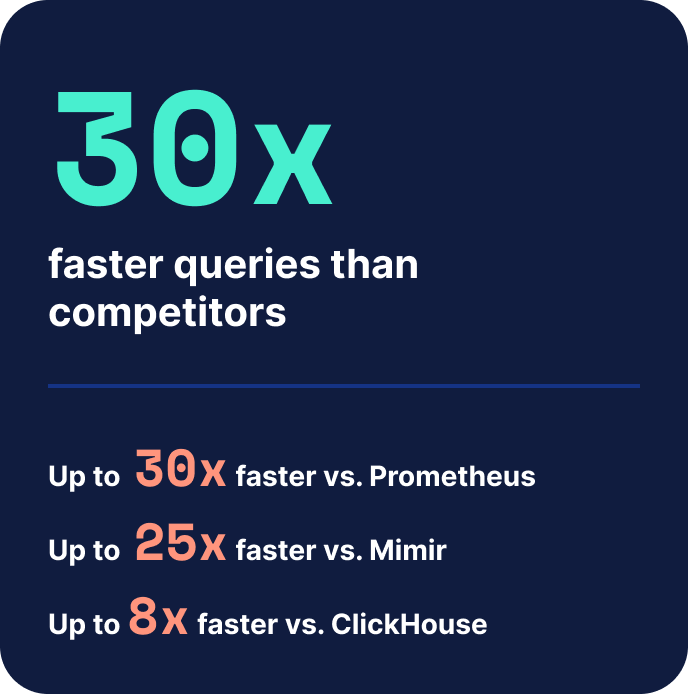
Elastic vereint erstklassige Metrik-Effizienz mit der branchenweit umfassendsten Log-Analyselösung. Bis zu 30-mal schnellere Abfragen als bei vergleichbaren TSDBs, basierend auf einem spaltenorientierten Datenspeicher, der für Workloads mit hoher Kardinalität entwickelt wurde und kostengünstig skaliert. Mit nativem PromQL können Sie Ihre gewohnten Workflows beibehalten.
Lernen Sie die beste Engine für spaltenorientierte Metriken ihrer Klasse kennen
Der spaltenorientierte Elasticsearch-Datenspeicher übertrifft andere Speicher bei der Datenaufnahme von Metriken, der Speicherung und der Abfragegeschwindigkeit in jeder Größenordnung.


Skalieren ohne Datenverlust
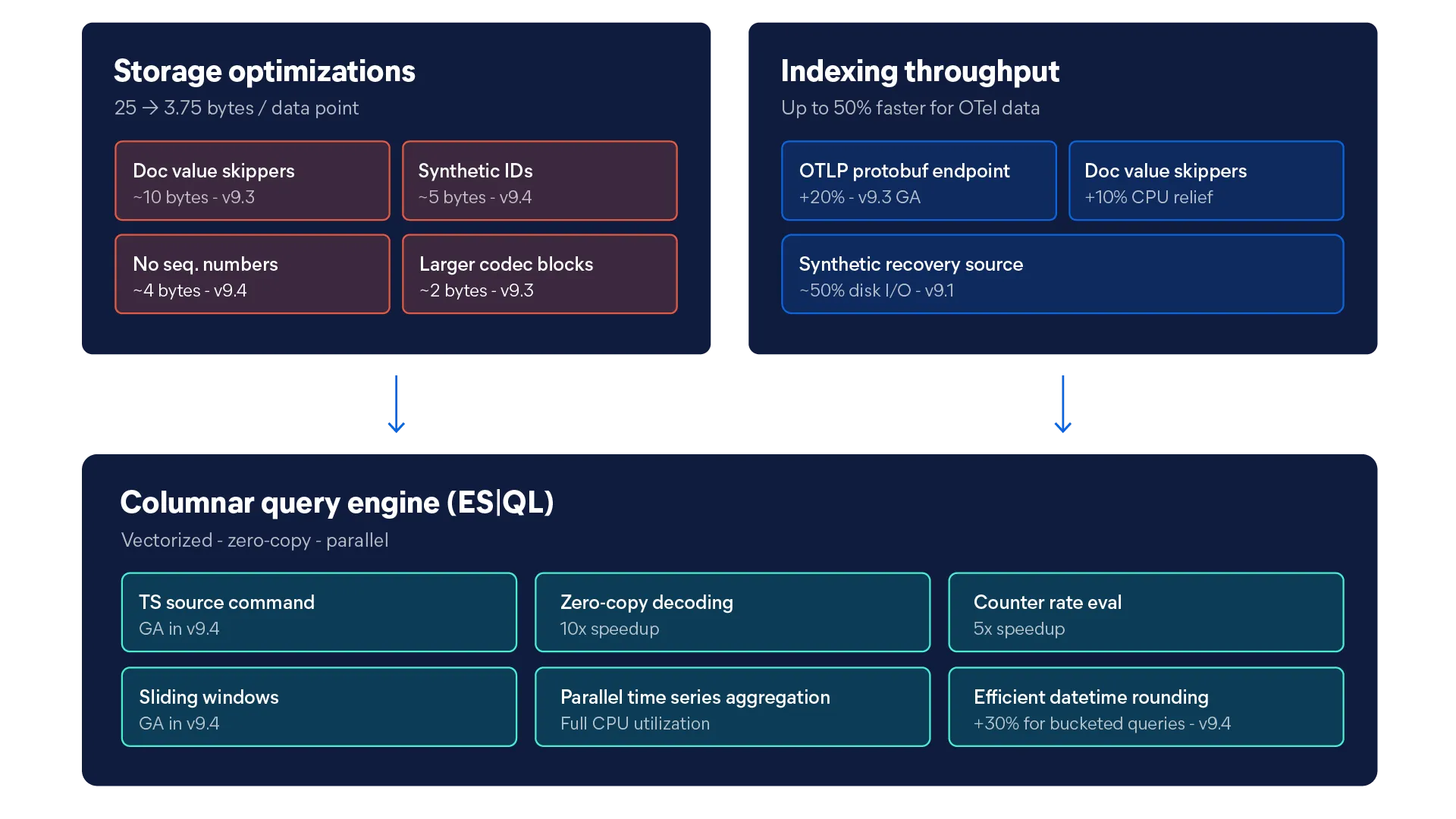
Die technische Tiefe, die den Standard für Log-Ingest, Speicher und Abfrageleistung setzte, ist exakt das, was wir angewandt haben, um eine bessere TSDB für Metriken mit hoher Kardinalität zu erstellen. Dasselbe Team, dieselbe Strenge, ein neuer Datentyp – darauf ausgelegt, jede Metrik in voller Auflösung ohne die damit verbundenen Kosten zu speichern.




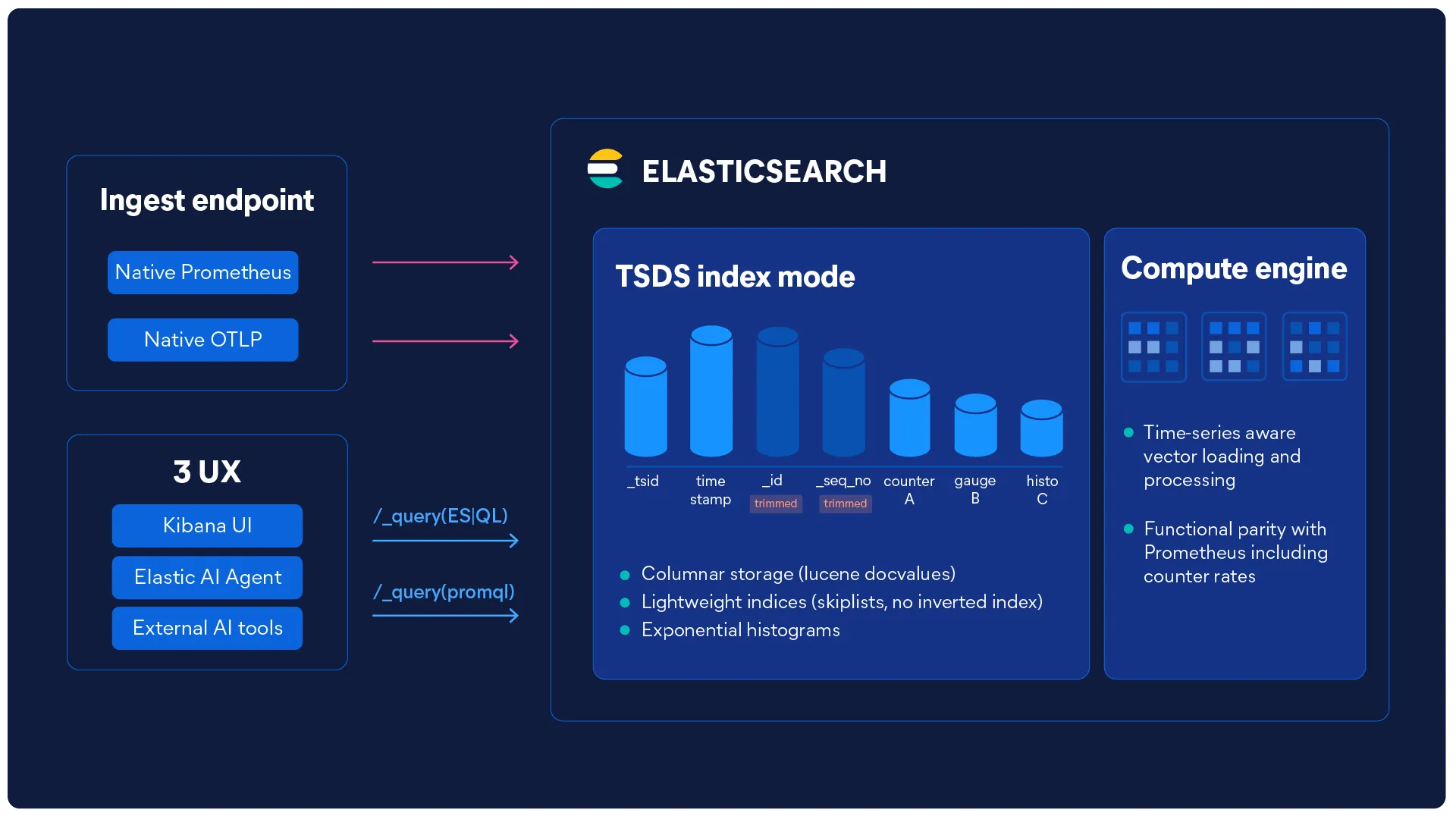
Elasticsearch scannt keine Zeilen. Es liest Spalten.
Der segmentbasierte Speicher von Elasticsearch ist von Haus aus spaltenorientiert und liefert bei Millionen von Zeitreihen mit vektoriellem Laden und Verarbeiten im Bruchteil einer Sekunde eine Antwort.
ELASTICSEARCH 9.4 BENCHMARKS
Technik, die sich in den Zahlen spiegelt
Direkter Vergleich der drei Metriken, die eine produktionsreife TSDB definieren: Abfragegeschwindigkeit, Speicherdichte und Datendurchsatz
| Dimension | Elasticsearch 9.4 | Prometheus | Mimir | ClickHouse |
|---|---|---|---|---|
| AbfragegeschwindigkeitZeitreihen mit hoher Kardinalität | Schnellste Ausgangsgrundlage |
Bis zu 30-mal langsamer | Bis zu 30-mal langsamer | Bis zu 8x langsamer |
| SpeicherdichteByte/Abtastwert | Beste 3,74 B |
~9,42 B | ~3,95 B | ~6,8 B |
| Ingest-DurchsatzProben/Sekunde | Schnellster 428K/s |
402K/s | 404K/s | ~300K/s |
| Native PromQLKein Adapter erforderlich | Nativ | ✓ Native | ✓ Native | Adapter erforderlich |
| OTel-nativKeine Schema-Konvertierung | OTel-first | Über Exporter | Über Exporter | Manuelles Mapping |
DIESE INNOVATION HAT ES MÖGLICH GEMACHT
Aufbau der Elasticsearch Engine für spaltenorientierte Metriken
Von der Speicherarchitektur bis zur Abfrageausführung: Jeder Teil unserer Plattform wurde für einen bestimmten Zweck entwickelt. Hier ist die Technik, die es möglich gemacht hat.
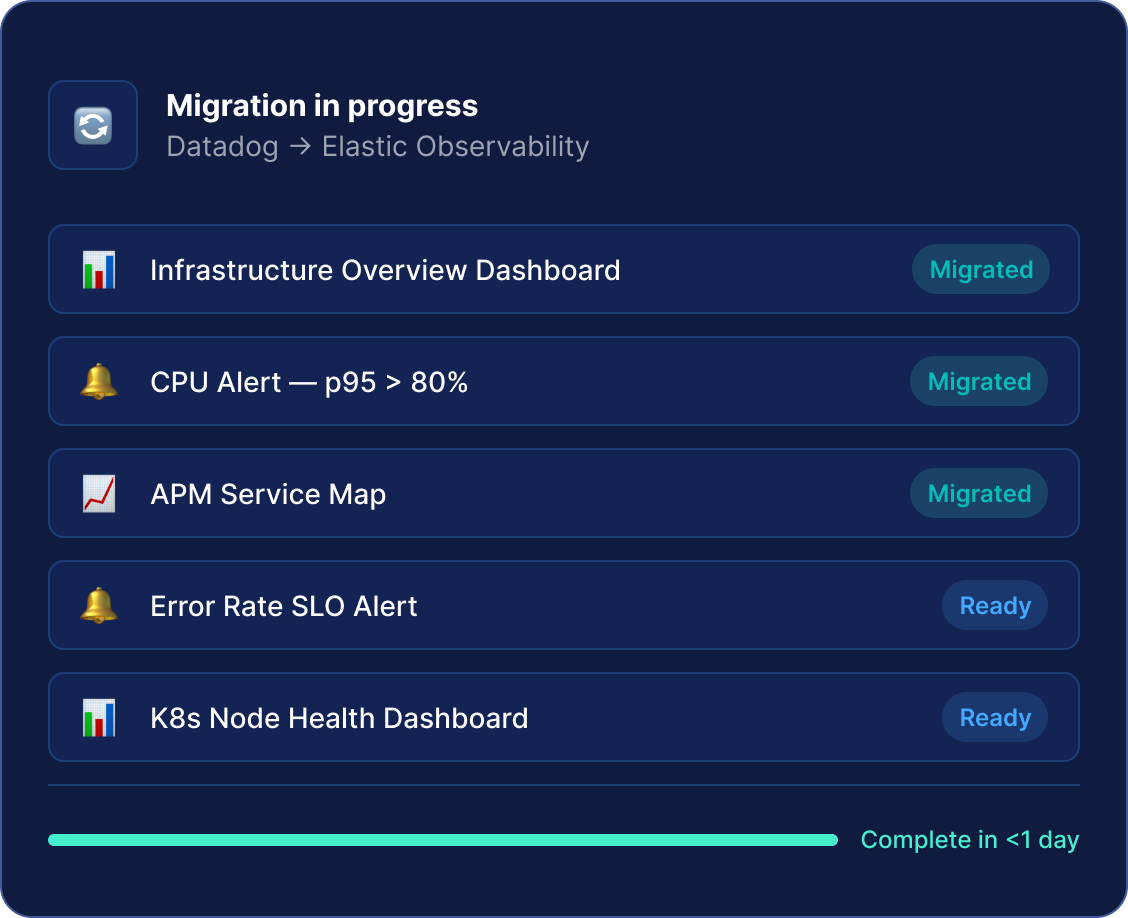
Migrationstool – technische Vorschau
Über Nacht von Datadog oder Grafana migrieren
Konvertieren Sie Dashboards und Warnregeln von Datadog und Grafana automatisch in Elastic und reduzieren Sie so die Kosten und die Komplexität eines Plattformwechsels.
Sind Sie bereit, zu wechseln und 50 % Ihrer Rechnung für Datadog-Metriken zu sparen?
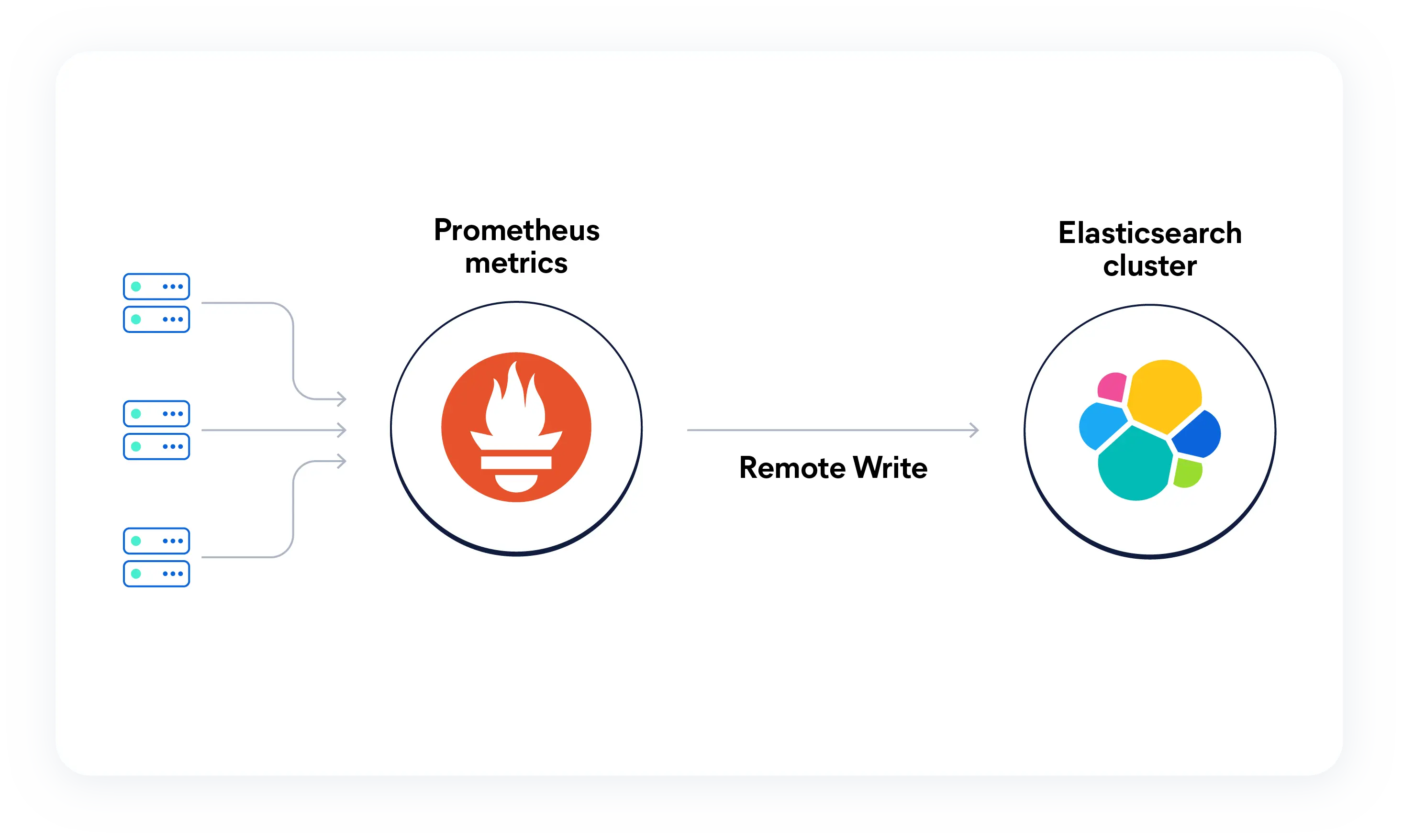
Senden Sie Ihre Prometheus-Metriken an Elastic
Für den Prometheus Remote Write-Endpoint ist keine zusätzliche Konfiguration erforderlich. Sobald die Metriken fließen, können Sie sie mit ES|QL abfragen, die integrierte PROMQL-Funktion für PromQL-Kompatibilität nutzen oder native ES|QL-Abfragen schreiben, um Metriken mit Logs und Traces im selben Store zu verknüpfen.
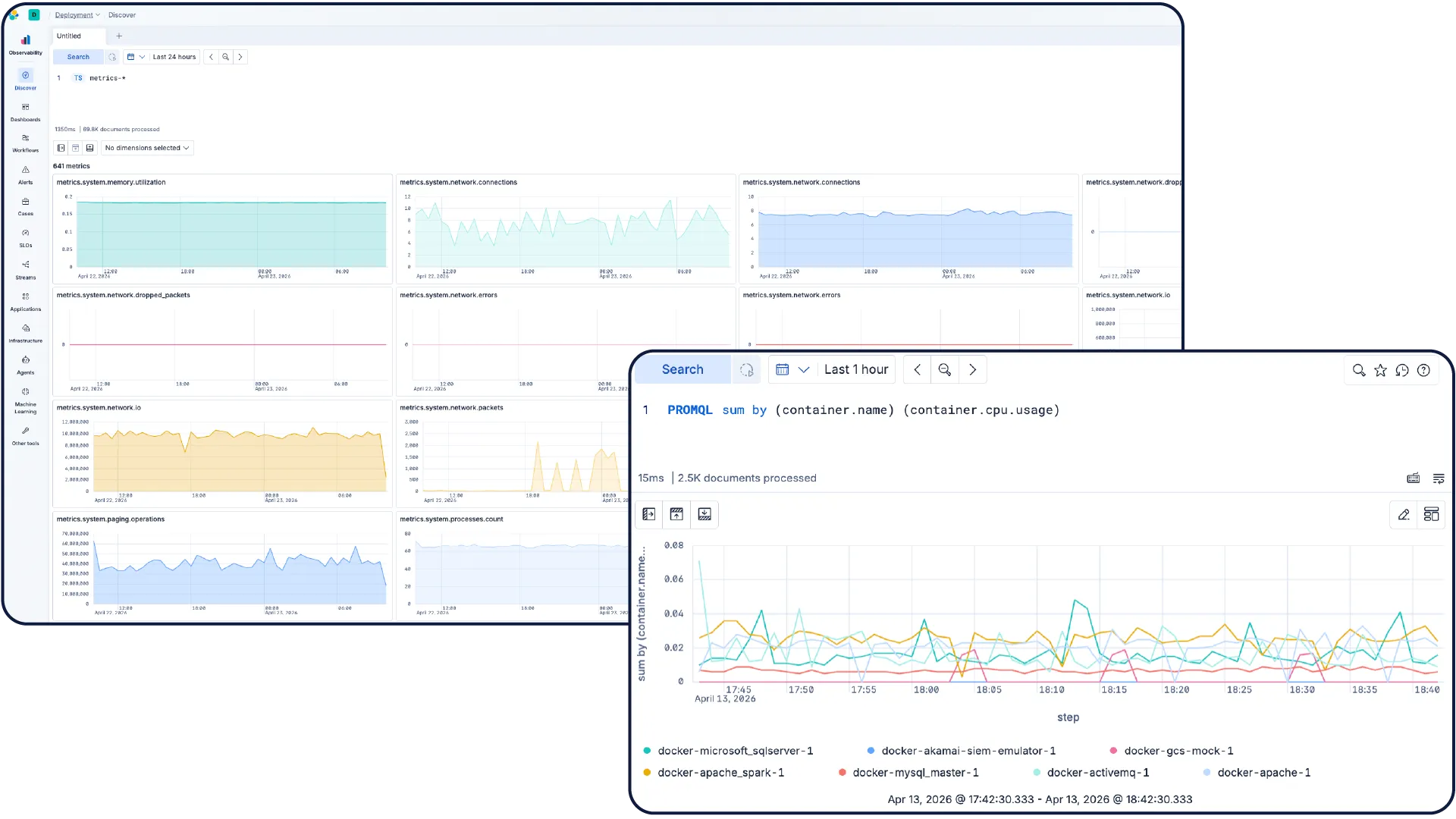
Metriken in verwertbare Maßnahmen umsetzen
Überwachen Sie Ihre Infrastruktur im großen Maßstab. Erkunden Sie Metriken in Discover, erstellen Sie Dashboards als Code, und lassen Sie KI-gestützte Untersuchungen Anomalien hervorheben, Trends aufdecken und Abhilfemaßnahmen automatisieren, damit Sie Kapazitäten planen und Probleme schneller lösen können.
Häufig gestellte Fragen
Kann Elasticsearch Prometheus bei der Metriküberwachung ersetzen?
Kann Elasticsearch Prometheus bei der Metriküberwachung ersetzen?
Ja. Elasticsearch verfügt über einen nativen Prometheus-Remote-Write-Endpunkt, PromQL-Unterstützung über die integrierte PROMQL-Funktion in ES|QL sowie eine spaltenorientierte Metrik-Engine, die speziell für Zeitreihen mit hoher Kardinalität entwickelt wurde. Teams können innerhalb eines Tages von Prometheus migrieren, indem sie ihre bestehenden Grafana-Dashboards und Alarmregeln automatisch konvertieren.
Wie schneidet Elasticsearch im Vergleich zu Prometheus hinsichtlich der Abfragegeschwindigkeit ab?
Wie schneidet Elasticsearch im Vergleich zu Prometheus hinsichtlich der Abfragegeschwindigkeit ab?
In den Benchmarks von Elasticsearch 9.4 fragt Elasticsearch Zeitreihen mit hoher Kardinalität bis zu 30-mal schneller ab als Prometheus. Auch die Speichereffizienz ist höher: Elasticsearch speichert Metriken mit 3,74 Byte pro Stichprobe, im Vergleich zu etwa 9,42 Byte bei Prometheus.
Unterstützt Elasticsearch die OpenTelemetry (OTel)-Metriken nativ?
Unterstützt Elasticsearch die OpenTelemetry (OTel)-Metriken nativ?
Ja. Elasticsearch setzt auf OTel und nimmt Metriken im nativen OpenTelemetry-Format ohne Schemakonvertierung auf. Prometheus- und Beats-Formate werden nativ unterstützt und jeweils unverändert ohne Übersetzungsschicht gespeichert.
Wie lange dauert die Migration von Datadog oder Grafana zu Elasticsearch?
Wie lange dauert die Migration von Datadog oder Grafana zu Elasticsearch?
Elastic bietet ein Migrationstool (derzeit in der technischen Vorschau), das Datadog- und Grafana-Dashboards sowie Alarmregeln automatisch in das Elastic/Kibana-Format konvertiert. Für die Migration von Prometheus Prometheus ist lediglich eine Konfigurationsänderung erforderlich, um Prometheus Remote Write mit Elasticsearch zu verbinden.
Was ist eine TSDB und warum ist sie für die Metriküberwachung wichtig?
Was ist eine TSDB und warum ist sie für die Metriküberwachung wichtig?
Eine TSDB (Time Series Database – Zeitreihendatenbank) ist eine Datenbank, die für die Speicherung und Abfrage von zeitindexierten Daten, wie z. B. Infrastrukturmetriken, optimiert ist. Die TSDS (Time Series Data Streams – Zeitreihendatenströme) von Elasticsearch verwenden eine spaltenorientierte Speicher-Engine, die Daten in Batches verarbeitet und die Bereinigung synthetischer IDs sowie Doc-Value-Skipper verwendet, um den Speicherbedarf zu reduzieren. Dadurch ist sie schneller und kostengünstiger als herkömmliche zeilenbasierte Alternativen.
Was beschleunigt die spaltenorientierte Speicherung bei Metrikabfragen?
Was beschleunigt die spaltenorientierte Speicherung bei Metrikabfragen?
Die spaltenorientierte Speicherung beschleunigt Metrikabfragen, da nur die für eine Abfrage relevanten Datenspalten gelesen werden, anstatt ganze Zeilen zu durchsuchen. Bei Zeitreihenanalysen bedeutet dies, dass die Datenbank nur die benötigten Werte – beispielsweise die CPU-Auslastung über einen Zeitraum von 24 Stunden – abrufen kann, ohne irrelevante Felder zu berücksichtigen. Elasticsearch geht mit einer vektorisierten Abfrage-Engine, die Daten in Batches verarbeitet, noch einen Schritt weiter und ermöglicht so Antwortzeiten im Subsekundenbereich, und das selbst bei Millionen von Zeitreihen mit hoher Kardinalität.