Prometheus-Überwachung
Prometheus skalieren ohne operativen Aufwand – 30-mal schneller, 2,5-mal weniger Speicherplatz
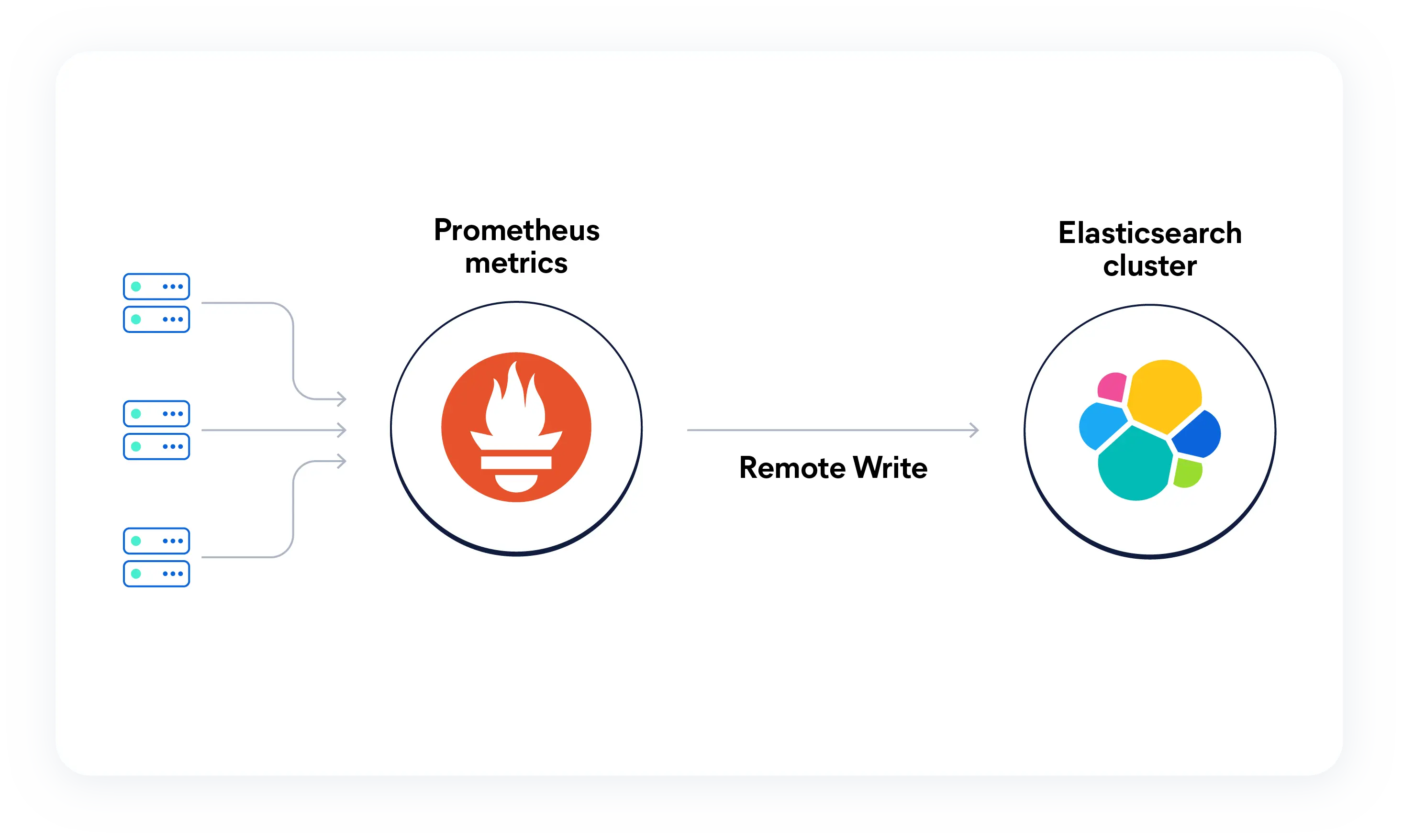
Ingestieren Sie nativ Prometheus-Metriken in Elasticsearch und führen Sie PromQL-Abfragen direkt in Kibana aus. Vereinheitlichen Sie Zeitreihendaten mit hoher Kardinalität mit Logs und Traces für eine vollständige Stack-Beobachtbarkeit, die KI-gesteuert, skalierbar und von Natur aus offen ist.
Elasticsearch: Branchenführende Effizienz für Metriken
Unser TSDB übertrifft Prometheus in Bezug auf die Ingestion und die Abfragegeschwindigkeit in jeder Größenordnung.
Prometheus + Elasticsearch
Elastic kombiniert Ihre Prometheus-Metriken mit der branchenweit umfassendsten Log-Analyselösung. Nutzen Sie Ihre gewohnten PromQL-Workflows und optimieren Sie sie durch Log-Korrelation und KI-gestützte Analysen. Statt Dashboards manuell zu durchsuchen, analysiert die KI Ihre Metriken und Logs und liefert Ihnen innerhalb von Sekunden die gewünschten Ergebnisse.
Hören Sie auf, Ihren Observability-Stack mit Klebeband zusammenzuflicken
SREs sind der operativen Belastung durch die Skalierung von Prometheus und den Kontextwechsel zur Lösung von Vorfällen mit isolierten Signalen müde. Elastic vereint alles in einer einzigen, leistungsstarken Plattform.



Die Prometheus-Steuer ist offiziell optional
Das Verwalten und Skalieren von Prometheus sollte sich nicht wie eine zweite Arbeit anfühlen. Der einheitliche Datenspeicher von Elastic ermöglicht die langfristige Aufbewahrung, ohne Kompromisse bei Leistung und Kosten.
Elasticsearch
Prometheus / Mimir / ClickHouse
Native Prometheus und PromQL bedeuten kein Lock-in, keine Umschreibungen oder monatelange Migrationsprojekte.
Für die Langzeitspeicherung und Skalierung von Prometheus sind oft zusätzliche Backends wie Mimir und ClickHouse erforderlich.
Während Mimir PromQL unterstützt, benötigt ClickHouse eine Übersetzungsebene.
Speichert Prometheus und OTel nativ in einem einzigen hochleistungsfähigen Zeitreihendatenspeicher. Keine semantischen Änderungen, keine proprietären Schichten.
Prometheus benötigt einen Otel-Collector mit expliziter Umwandlung.
ClickHouse unterstützt OTel, erfordert jedoch benutzerdefinierte Schemaarbeit und Pipeline-Konfiguration.
Korrelieren Sie Metriken, Protokolle und Traces auf einer Plattform mit einer Abfragesprache (ES|QL), ohne die Tabs oder den Kontext zu wechseln. PromQL-Anweisungen können als Teil von ES|QL-Abfragen eingebunden werden.
Metriken und Protokolle befinden sich in separaten Backends, was bei Störungen einen Wechsel zwischen Tools und Abfragesprachen erforderlich macht.
ClickHouse kann alle drei Signalarten speichern, erfordert aber umfangreiche Anpassungen an Schema und Pipeline.
Spaltenbasierte Festplattenspeicherung bedeutet, dass es keine Obergrenze für die Kardinalität im Arbeitsspeicher gibt. Skalieren Sie auf Kubernetes- und Cloud-Umgebungen mit hoher Kardinalität ohne OOM-Wände.
Prometheus und Mimir verwenden einen invertierten Index im Speicher – Kardinalitätsspitzen verursachen OOM-Abstürze zum denkbar schlechtestmöglichen Zeitpunkt.
Übertrifft Prometheus und Mimir bei den meisten Abfragetypen um mehr als 10–25×, sowohl bei niedriger als auch hoher Kardinalität.
ClickHouse kommt mit der Kardinalität besser zurecht, erfordert jedoch beim Skalieren erhebliche Anpassungen.
Integriertes automatisches Downsampling. Die Daten in voller Auflösung bleiben durchsuchbar. Die überragende Komprimierung reduziert Ihren Speicherbedarf ohne manuelle Arbeit oder Datenverlust.
Mimir hat kein integriertes Downsampling. Die Verwaltung der Langzeitaufbewahrung erfordert manuelle Aufzeichnungsregeln, die die Granularität dauerhaft zerstören.
ClickHouse benötigt benutzerdefinierte TTL- und Aggregationspipelines.
Vorhersehbare Preisgestaltung mit langfristiger Aufbewahrung in voller Auflösung – keine Kardinalitätsstrafen, keine erzwungenen Roll-ups.
Die Skalierung von Prometheus und Mimir bedeutet, Kosten gegen Leistung einzutauschen: mehr zahlen, um Daten länger aufzubewahren, oder Downsampling durchführen und an Granularität verlieren.
ClickHouse muss ständig optimiert werden, um die Abfragegeschwindigkeit mit den Speicheraufwendungen in Einklang zu bringen.
Volle Funktionalität für Elastic Cloud-, selbstverwaltete und Hybrid-Deployments.
Prometheus und Mimir sind ausschließlich selbstverwaltet, mit erheblichem operativem Aufwand im großen Maßstab.
Für den Betrieb von ClickHouse sind umfangreiche Infrastrukturkenntnisse erforderlich.
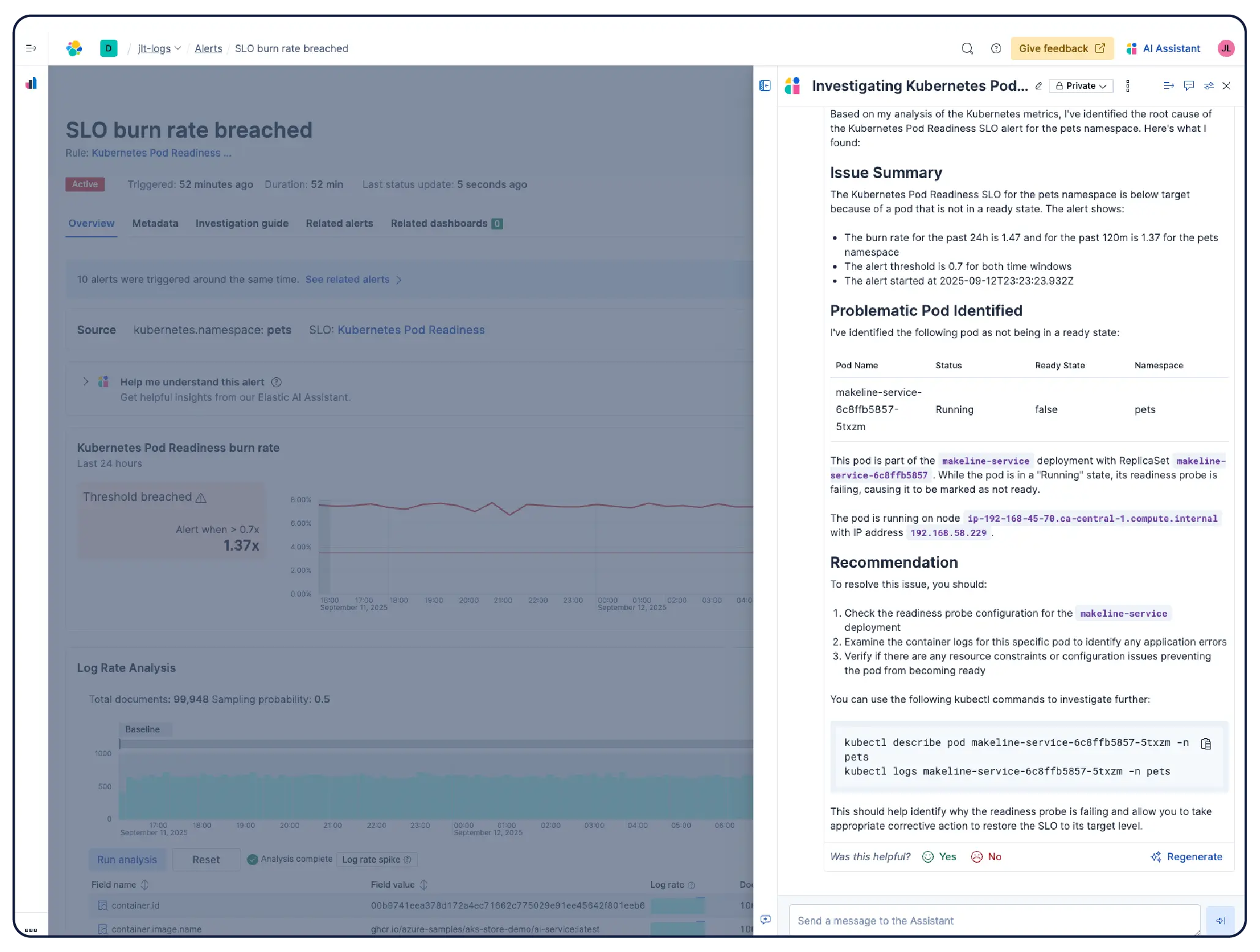
KI analysiert Ihre Metriken, Logs und Traces, um schnell die Grundursachen zu ermitteln und die Behebung zu leiten – kein manuelles Durchsuchen von Dashboards erforderlich.
Der KI-Assistent von Grafana arbeitet über fragmentierte Backends, anstatt über einen einzigen einheitlichen Datenspeicher.
ClickHouse hat keine native agentische KI. Die Untersuchung hängt von der Korrelation über verschiedene unverbundene Tools und Datensilos ab.
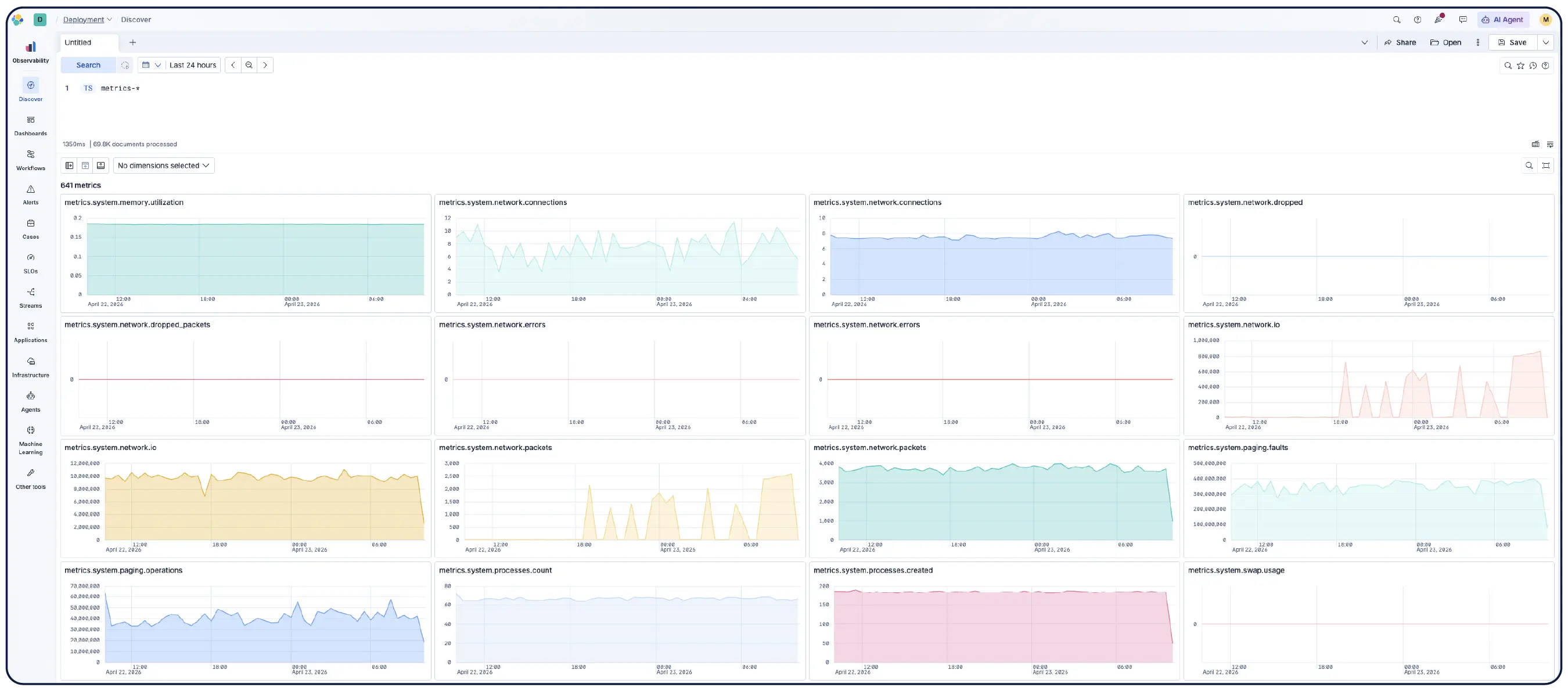
Infrastrukturdaten in konkrete Maßnahmen umsetzen
Überwachen Sie Ihre Infrastruktur im großen Maßstab. KI-gestützte Untersuchungen heben Anomalien hervor, decken Trends auf und automatisieren Abhilfemaßnahmen – so können Sie Kapazitäten planen und Probleme schneller lösen.
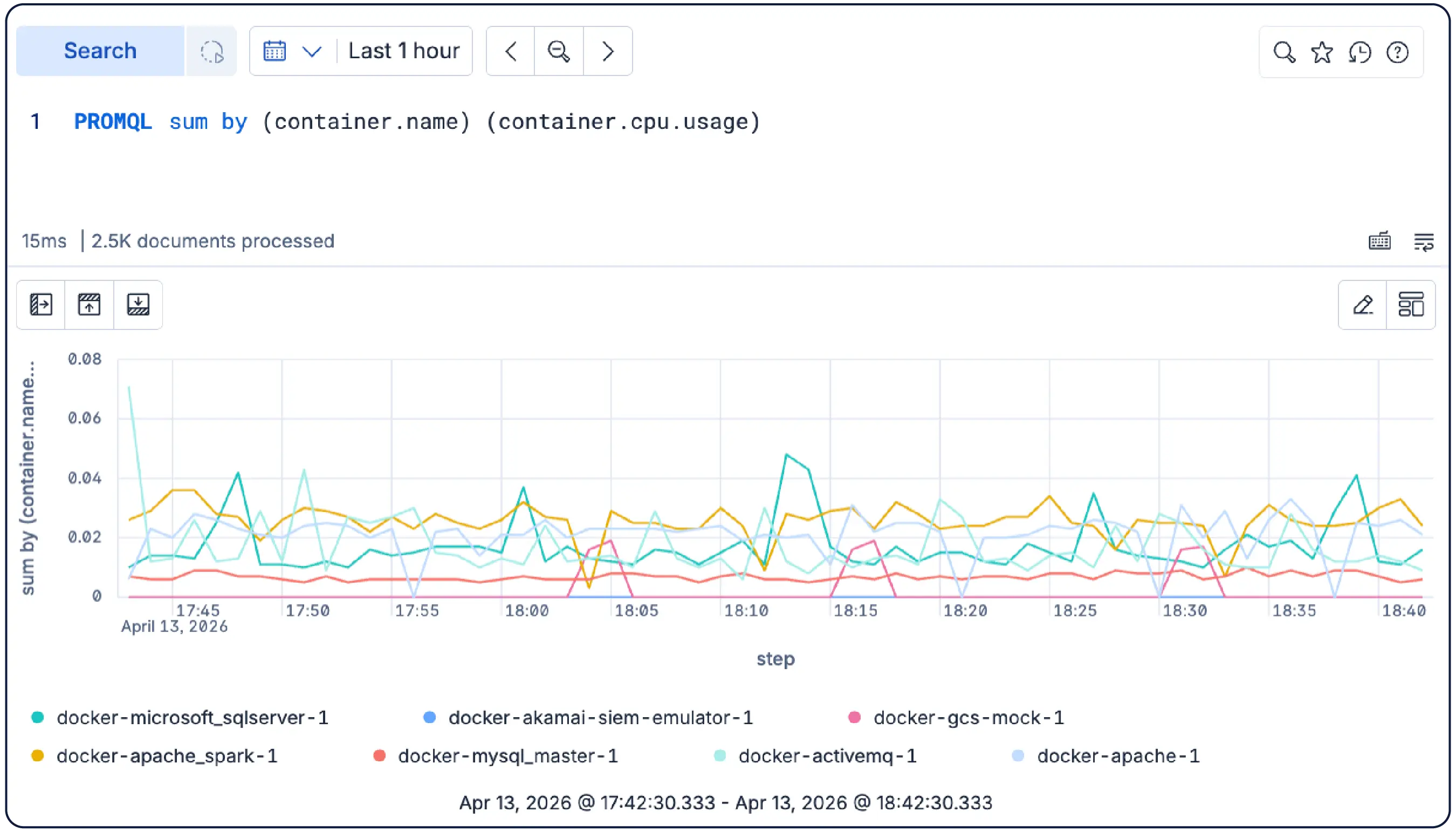
Führen Sie PromQL-Abfragen direkt in Kibana aus – ohne Übersetzungsschicht oder Code-Anpassungen. Rate, sum by, max_over_time und andere gängige Funktionen funktionieren wie gewohnt neben ES|QL.
Migrationstool – technische Vorschau
Über Nacht von Grafana migrieren
Konvertieren Sie Dashboards und Alarmierungsregeln automatisch von Grafana in Elastic und reduzieren Sie so die Kosten und die Komplexität eines Plattformwechsels.
Häufig gestellte Fragen
Worum geht es bei Prometheus und der Prometheus-Überwachung?
Worum geht es bei Prometheus und der Prometheus-Überwachung?
Prometheus ist ein Open-Source-Monitoring-Toolkit. Es wird in Cloud-nativen und containerisierten Umgebungen häufig eingesetzt und ist ein beliebtes Werkzeug zum Sammeln von Zeitreihendaten aus instrumentierten Jobs mithilfe eines offenen, herstellerneutralen und textbasierten Expositionsformats.
Warum sollten Sie sich von selbstverwaltetem Prometheus abwenden?
Warum sollten Sie sich von selbstverwaltetem Prometheus abwenden?
Die Skalierung von Prometheus erfordert einen operativen Aufwand, der sich im Laufe der Zeit steigert. Das Management von Backends wie Mimir erhöht die Komplexität, ohne das zugrundeliegende Problem zu lösen. Elastic übernimmt die Skalierung, sodass Sie das nicht tun müssen. Außerdem liefern unsere Kolumnenspeicherung und vektorisierte Verarbeitung Abfragegeschwindigkeiten, die Prometheus und Mimir bei den meisten Abfragetypen um mehr als 10–25x übertreffen.
Warum Prometheus-Metriken in Elasticsearch speichern?
Warum Prometheus-Metriken in Elasticsearch speichern?
Der lokale Speicher von Prometheus ist für eine kurze Aufbewahrungsdauer ausgelegt, typischerweise 15 bis 30 Tage. Die Elasticsearch TSDB bietet Ihnen eine effiziente Langzeitspeicherung (2,5-mal effizienter als Prometheus) mit automatischem Rollover, Kompression und Downsampling, wenn die Daten altern. Ihre bestehenden Scrape-Konfigurationen bleiben unverändert.
Funktionieren meine vorhandenen Prometheus-nativen Dashboards, Alarme und Abfragen weiterhin?
Funktionieren meine vorhandenen Prometheus-nativen Dashboards, Alarme und Abfragen weiterhin?
Ja. Native PromQL-Unterstützung bedeutet, dass Ihre bestehenden Prometheus-Workflows problemlos übertragen werden können. Es sind keine Abfrage-Neuschreibungen oder langen Übergangsprojekte erforderlich.
Wie senkt Elastic die Speicherkosten?
Wie senkt Elastic die Speicherkosten?
Hochwertiges Downsampling und Kompression verringern Ihren Speicherplatz. Vorhersehbare, ressourcenbasierte Preise sorgen dafür, dass Ihre Rechnung nicht in die Höhe schnellt, wenn die Kardinalität steigt oder Sie neue Etiketten hinzufügen. Behalten Sie jede benötigte Kennzahl in voller Auflösung, solange Sie sie brauchen.
Wie funktioniert die Logkorrelation mit Ihren Kennzahlen?
Wie funktioniert die Logkorrelation mit Ihren Kennzahlen?
Elastic speichert Metriken und Logs auf derselben Plattform, sodass Sie beide gemeinsam mit ES|QL abfragen können, ohne Kontextwechsel zwischen verschiedenen Werkzeugen oder Tabs.
Wie trägt Agentic AI zur Störungsbehebung bei?
Wie trägt Agentic AI zur Störungsbehebung bei?
Anstatt manuell durch Dashboard s zu navigieren, analysiert die agentische KI von Elastic Ihre Beobachtbarkeitsdaten, um Untersuchungen zu leiten, Grundursachen zu ermitteln und Workflows auszuführen.
Wie sieht die Migration tatsächlich aus?
Wie sieht die Migration tatsächlich aus?
Es gibt kein monatelanges Migrationsprojekt. Die native Unterstützung von PromQL und OTel bedeutet, dass Ihre bestehende Ingest-Architektur, Dashboards und Abfragen über Nacht migriert werden können. Fragen Sie nach unseren Migrationstools (derzeit in der technischen Vorschau).
Am Chat teilnehmen
Verbinden Sie sich mit der globalen Community von Elastic und nehmen Sie an offenen Gesprächen und an der Zusammenarbeit teil.

Stellen Sie Fragen, erhalten Sie Antworten und verschaffen Sie sich Gehör in unserem offenen Forum.

Tauchen Sie in Elastic ein. Lernen Sie, erkunden Sie und treten Sie mit Gleichgesinnten in Kontakt.

.jpg)