什么是混合搜索?
两种或更多检索方法。一个排序列表。
混合搜索是一种信息检索技术,它将两种或更多搜索方法(例如,词汇搜索和语义搜索)融合成一个单一的排序列表,以提高相关性和召回率。最常见的组合是将擅长匹配精确词语和短语的全文词汇搜索与解释查询背后含义的语义向量搜索结合起来。词汇方面增加了精确性,语义方面提供了对用户潜在意图的深入理解。
这些方法在单个查询中同时运行,然后使用专门的融合策略将它们的合并成一个连贯的排序。虽然词汇+语义是最流行的组合,但混合搜索也可以结合其他方法——例如地理空间+语义搜索甚至文本+图像搜索——以适应不同的需求。
为什么混合搜索很重要
混合搜索可以在单个管道中发挥各种检索方法的优势,同时弥补它们各自的弱点。现代 AI 必须处理多种模态,包括文本、图像、音频、日志等,并弥合用户意图与数据之间的鸿沟。相关性正变得比以往任何时候都重要。例如在电子商务领域,如果搜索体验能帮助用户快速筛选和细化结果,它可以算是成功的;但 AI 智能体通常需要单个高度相关的答案来回答问题或执行操作。这就是为什么当今能够混合并优化检索技术如此重要,它不仅能为传统搜索结果提供支持,还能为提供精准、基于数据的响应的对话式智能体提供动力。
在深入探讨混合搜索之前,让我们快速了解一下词汇搜索和语义搜索有何不同,以及它们为何能够相互补充。
词汇搜索详解
当您拥有结构良好的数据,且用户清楚自己需要什么时,词汇搜索是理想之选。它通过匹配确切的词项来实现高度精确和可解释的搜索,依赖于相关性评分算法(如 BM25F),根据查询词项在文档中出现的频率和稀有性对文档进行排序。这种方法提供透明的评分,并通过字段权重提升、同义词和分析器支持相关性微调。由于没有模型开销,词汇搜索快速高效,筛选器和分面即使在大规模下也能可靠执行,而不会出现性能下降或需要全索引扫描。它对于结构化查询、稀有词项和特定领域语言尤其有效。
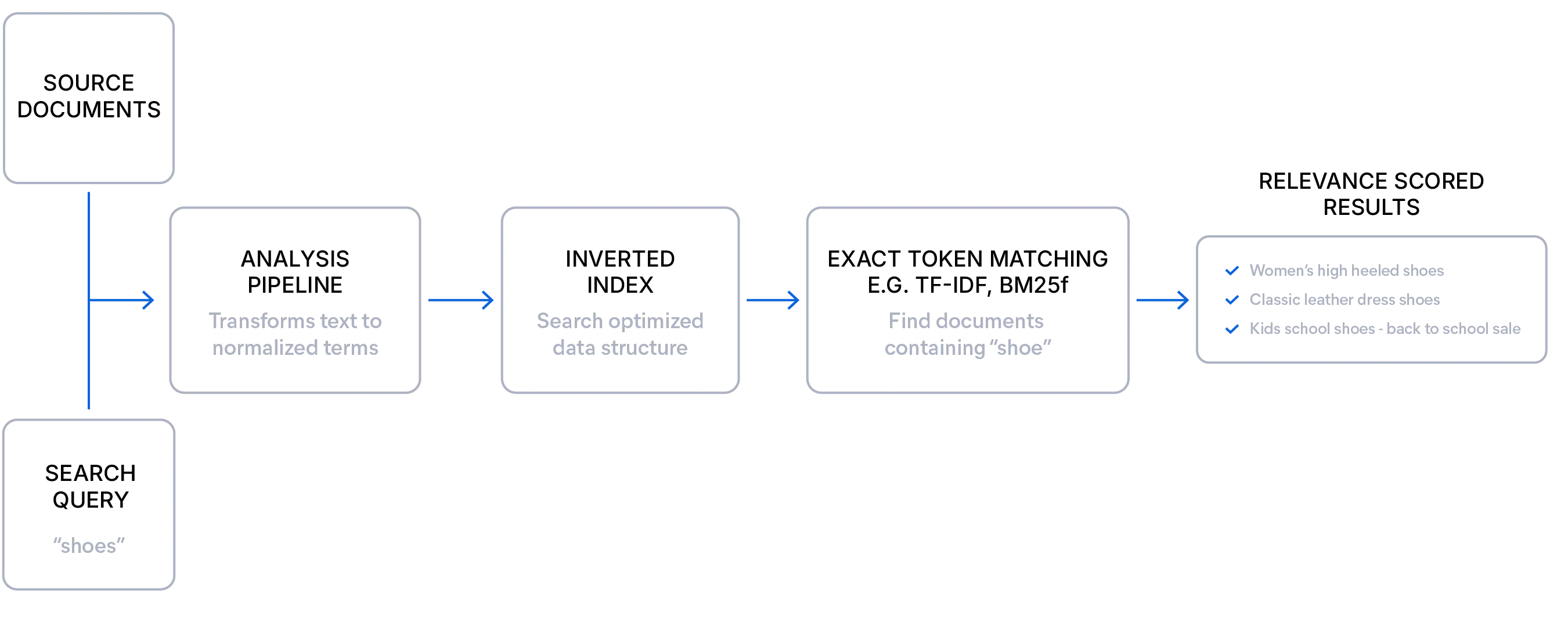
这是一个简单的词汇搜索查询示例:
GET example-index/_search
{
"query": {
"term": {
"text": "blue shoes"
}
}
}
我们再看一个使用 Elasticsearch 查询语言(ES|QL)针对烹饪博客的词汇搜索示例。该博客包含各种食谱,具有文本内容、分类数据和数值评分等多种属性。
FROM cooking_blog METADATA _score | WHERE description:"fluffy pancakes" | KEEP title, description, _score | SORT _score DESC | LIMIT 1000
此查询在描述字段中搜索包含“fluffy”或“pancakes”(或两者都包含)的文档。默认情况下,ES|QL 在搜索词项之间使用 OR 逻辑,因此它会匹配包含任意指定词语的文档。您可以使用 KEEP 命令精确指定要在结果中包含哪些字段,并请求 _score 元数据,以便根据结果与查询的匹配程度对搜索结果进行排序。
通过这个实操教程,可以更深入地了解词汇搜索。
语义搜索详解
语义搜索根据查询和文档之间含义的相似性来检索结果,而不是像词汇搜索那样仅仅匹配精确的词项。
嵌入模型可将文本或其他媒体的含义转换为称为向量的数值表示。这些向量(一系列数字)捕捉了文本的底层上下文和主题,并存储在像 Elasticsearch 这样的向量数据库中。
这使得搜索引擎即使在与查询没有共享确切词语的情况下,也能找到概念上相似的结果。
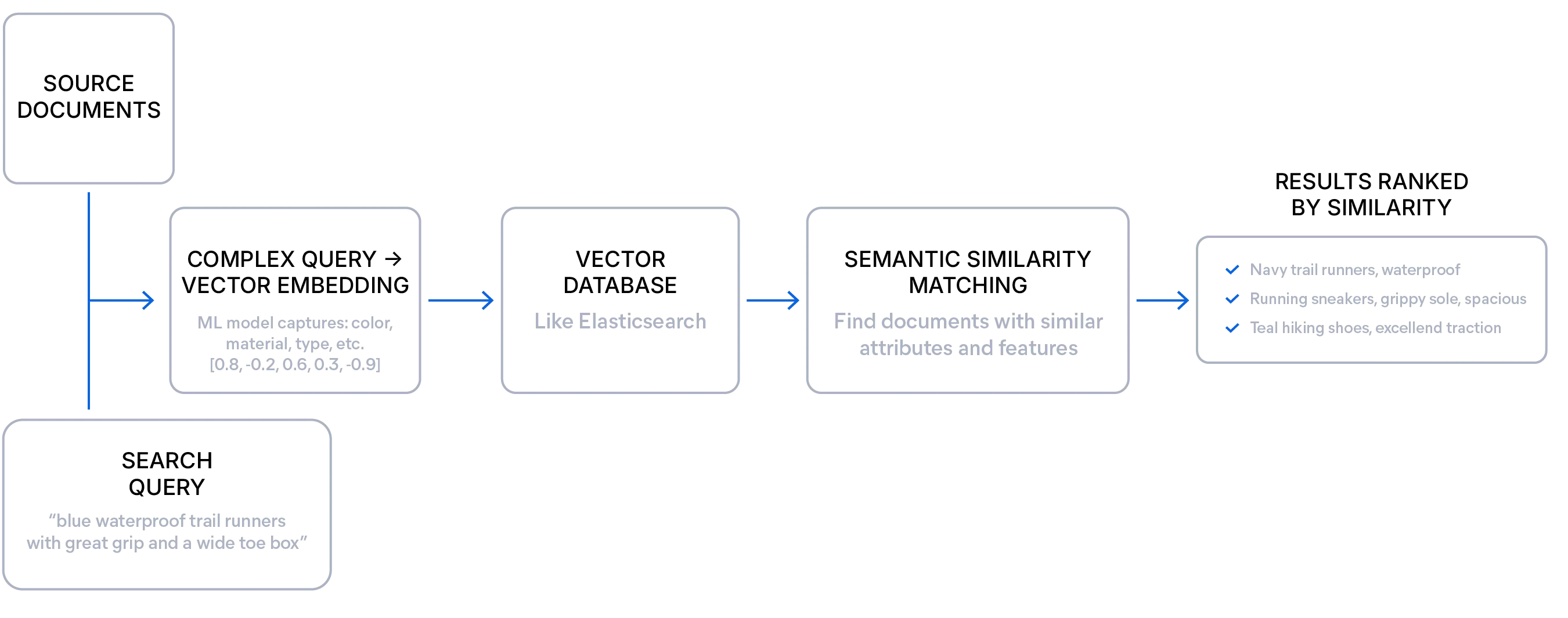
这种方法对于非结构化数据、探索性查询以及用户可能不知道确切搜索词项的情况尤其有用。开发人员可以利用语义搜索来提供更相关的结果,并处理模糊、冗长或有歧义的措辞,同时仍然呈现正确的答案。
以下是一个语义搜索查询的示例:
GET example-index/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "blue waterproof trail runners with great grip and a wide toe box"
}
}
}
当映射包含 semantic_text 类型的字段时,ES|QL 支持语义搜索。一旦文档被运行在推理终端上的底层模型处理完毕,您就可以执行语义搜索。以下是针对 semantic_description 字段的自然语言查询示例:
FROM cooking_blog METADATA _score | WHERE semantic_description:"What are some easy to prepare but nutritious plant-based meals?" | SORT _score DESC | LIMIT 5
了解有关语义搜索的更多信息,或通过这个实操教程,深入了解语义搜索。
像 BM25F 这样的词汇算法在查询词项与文档词项匹配时表现出色,但当相关内容以不同方式表达时,它们就会失效。(例如,搜索“运动鞋”的查询可能会错过那些只提到“鞋子”或“越野跑鞋”的文档。)语义向量搜索使用高维嵌入和近似最近邻 (ANN) 算法(如HNSW),无论确切词项是否重叠,都能检索到概念上相似的文档,但如果上下文有歧义,它也可能引入噪声。
混合搜索的工作原理
如果能同时获得两者的优点,会怎么样?混合搜索应运而生。如果运用得当,混合搜索的效果会超过其各部分之和;它能产生远比单独使用词汇或语义搜索更好的结果。混合型既能兼顾两者,相关性平衡,更标准化折损累积增益 (NDCG),还能提升召回率,无需额外加装第二个搜索系统。
以下是一个混合搜索查询示例:
GET example-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"term": {
"description": "shoes"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [1.25, 2, 3.5],
"k": 50,
"num_candidates": 100
}
}
],
"rank_constant": 20,
"rank_window_size": 50
}
}
}
您还可以在 ES|QL 中结合全文查询和语义查询。在此示例中,我们使用自定义权重组合全文搜索和语义搜索:
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"shoes") | SORT _score DESC | LIMIT 50)
( WHERE knn(vector, [1.25, 2, 3.5], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 50 ) // k for knn is derived from LIMIT
| FUSE RRF WITH { "rank_constant": 20 }
| SORT _score DESC
| LIMIT 50
运行混合搜索查询通常涉及执行至少一个词汇搜索和一个语义搜索,然后合并它们的结果。主要的挑战在于将多个排序列表合并成一个连贯、统一的排序。
由 BM25F 或 TF-IDF 等算法生成的词汇搜索分数可能没有上限,其最大值受词项频率和文档分布的影响。相比之下,语义搜索的分数通常落在一个固定范围内,由相似度函数决定(例如,余弦相似度的范围为 [0, 2])。
要合并它们,您需要一种能够保持检索到的文档相对相关性的融合方法。
使用 Elasticsearch 进行混合搜索
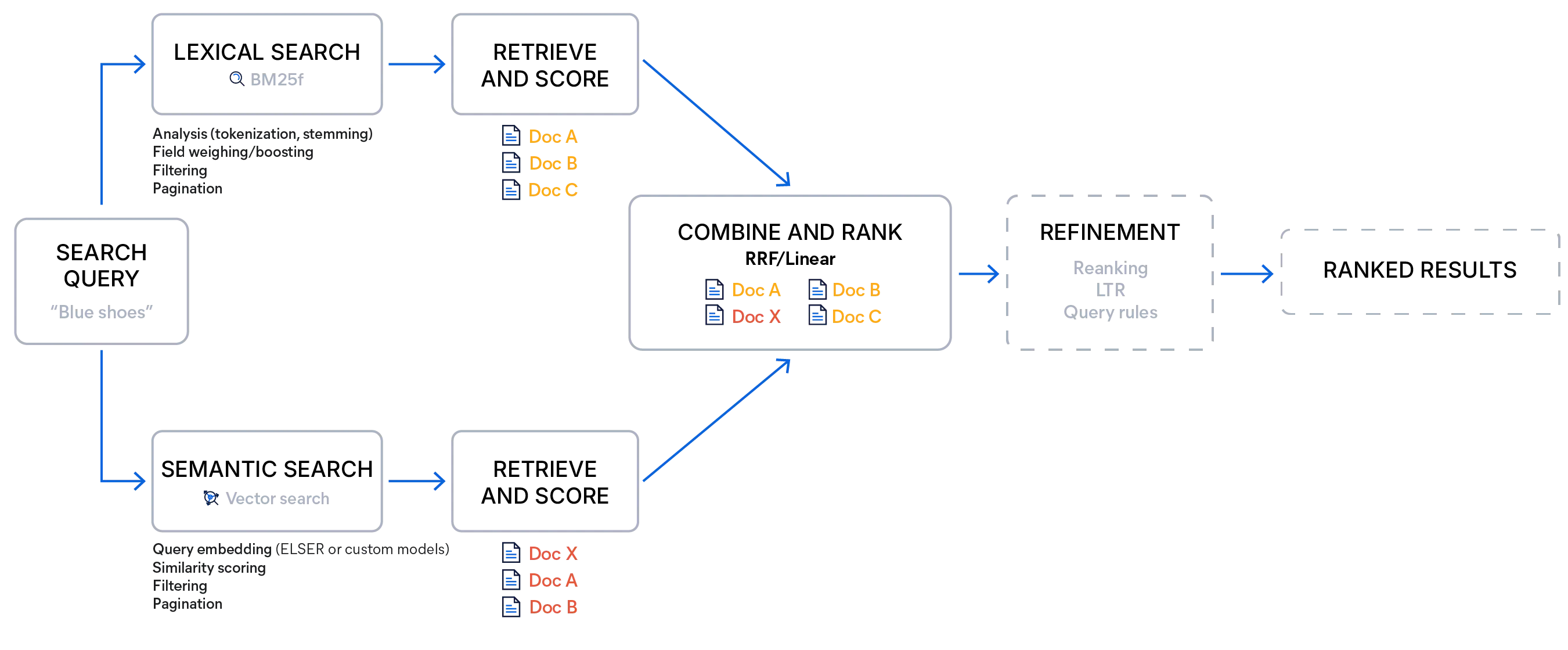
使用 Elasticsearch 进行混合搜索可以通过将标准关键词查询与向量查询配对来实现,或者使用检索器来实现——这是一种搜索选项,可以运行多种不同类型的查询,并使用选择的评分方法将它们的合并成一个单一的排序列表。这使得在单个搜索调用中就能实现多阶段检索管道,无需多次请求或额外的客户端逻辑来合并结果。
Elasticsearch 提供了两种内置的融合方法:倒数排序融合 (RRF) 和线性组合(在 API 中通常称为线性检索器)。两者都旨在生成统一排序,保留每个检索器的优势,但在评分处理方式和最佳适用场景上有所不同。
倒数排序融合完全忽略原始分数,而只关注文档在每个列表中出现的排序高低。排序靠前的文档文档都会获得较高的分数奖励,出现在多个列表中的文档会获得累加的分数提升。这种方法很稳健,因为它规避了分数范围不兼容的问题,除了排序常数外几乎不需要调整,并且自然地促进了顶部结果的多样性。
RRF 根据文档在结果集中的排序,使用以下公式对文档进行评分,其中 k 是一个任意常数,用于调整低排序文档的重要性:
![]()
当检索器在它们的顶部结果中存在一些重叠,并且开发人员需要一个无需标注训练数据或复杂校准的即插即用解决方案时,RRF 尤其有用。
相比之下,线性组合直接合并每个检索器的实际分数。由于词汇分数和语义分数的量级差异很大,线性组合需要标准化,例如最小-最大扩展,才能使分数具有可比性。
一旦归一化,就会使用代表每个检索器相对重要性的权重来混合分数。权重大于 1 会提升检索器的影响力,而权重小于 1 则会降低其影响力。
这种方法允许进行精细控制:当关键词精确性很重要时,开发人员可以强调 BM25F;当意图和上下文至关重要时,可以向语义相似性倾斜;或者在检索分数之外集成额外的业务或个性化信号。当权重经过仔细校准后,线性组合可以产生更准确和可预测的排序,从而优于 RRF,但它确实需要实验,并且对特定数据集的调整很敏感。
线性组合将词汇搜索结果和语义搜索结果与各自的权重 α 和 β(其中 0 ≤ α, β)相结合,如下所示:
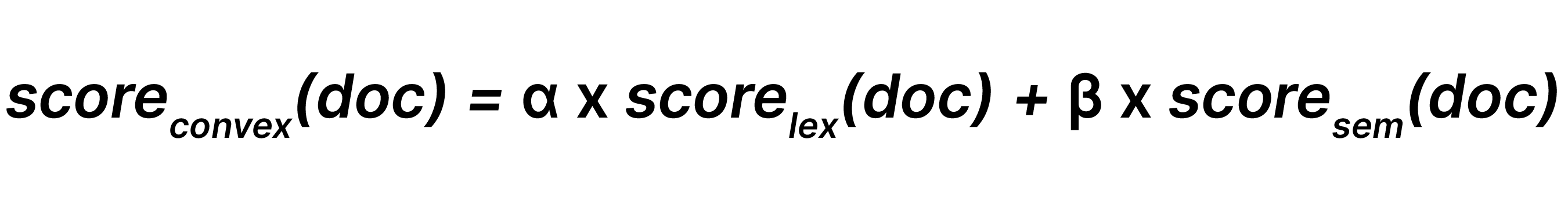
在实践中,RRF 是进行混合搜索的最佳起点,因为它简单且能够适应不匹配的分数尺度。它无需大量调整就能产生强大的结果,使其成为原型设计或检索器结果重叠时的理想选择。当不同的检索方法返回不相交的结果,或者需要仔细平衡词汇、语义和外部信号时,线性组合更为适用。简而言之,RRF 提供了开箱即用的快速、可靠的混合效果,而一旦权重和归一化器针对应用程序和数据进行了调整,线性组合则能提供更高的潜在准确性。
总结如下:
| 倒数排序融合 | 线性组合 |
|---|---|
从 RRF 开始,快速获得稳健的混合结果。 |
当您准备好微调相关性时,进阶到线性组合。 |
简而言之,线性组合在调整后能提供更高的潜在准确性,而 RRF 更容易实现,且无需标注训练数据也能很好地工作。
试用此教程,了解更多关于混合搜索的信息。
混合搜索检索的工作原理
- 词汇检索:BM25F 将查询词项与已索引的词元进行匹配——非常适合精确匹配、结构化筛选和可解释评分。
- 语义检索:向量(密集或稀疏)表示文本含义;相似性搜索能发现即使没有共同词语的相关内容。
- 融合:使用 RRF、加权混合或线性检索器合并分数。筛选器和权重提升会一致地应用于两种检索。
| 搜索类型 | 运作方式 | 会发生什么 | 适用场景 |
|---|---|---|---|
| 词汇搜索 查询:“red running shoes size 10” | 将查询中的确切词语与文档中的词语进行匹配(BM25F、TF-IDF、分析器、同义词)。 | 查找标题/描述中包含这些确切词元的产品(例如,"NikeMen's Red Running Shoes, Size 10" )。 | 购物者确切地知道他们想要什么。精确、可解释且高效。 |
| 语义搜索 查询:“lightweight shoes for jogging” | 使用嵌入来捕获含义和上下文,而不仅仅是关键词。查找概念上相关的结果,即使词项不匹配。 | 返回“Adidas Cloudfoam Running Sneakers, Size 10”,即使“lightweight”和“jogging”没有逐字出现。 | 购物者用自然语言描述意图或用途。处理模糊或描述性查询。 |
| 混合搜索 查询:“comfortable dress shoes for office” | 结合词汇和语义结果,然后融合排序(例如通过 RRF)。 | 检索与"Black Leather Dress Shoes, Comfort Fit" 等精确匹配的商品,以及与"Loafers with cushioned insoles"等语义相关的商品。两者同时出现,按相关性排序。 | 查询混合了精确词项和意图。在准确性与探索性之间取得平衡。 |
深入混合搜索:密集向量与稀疏向量详解
Elasticsearch 的语义搜索通过将查询和文档转换为能捕获含义的向量表示来工作。混合搜索结合了词汇检索和语义检索,无论使用的是密集模型还是稀疏模型。
密集向量
密集向量是由像 BERT 这样的模型产生的固定长度数字数组,其中相似的输入(例如 cat 和 kitten)在向量空间中位置接近,这使得它们对于语义匹配、推荐和相似性搜索非常有效。
当文本以密集向量形式嵌入时,它看起来像这样:
[ 0.13586345314979553, -0.6291824579238892, 0.32779985666275024, 0.36690405011177063, ... ]
每个维度都包含有意义的信息,使得向量数据密集。相似的内容产生的嵌入在向量空间中彼此靠近。
在 Elasticsearch 中,密集向量存储在 dense_vector 字段中,并使用近似最近邻 (ANN) 算法(如 HNSW)进行查询。这非常适合捕捉文本、图像或其他内容的整体语义。
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 5,
"num_candidates": 100
}
}
]
}
}
}
这是一个 ES|QL 示例:
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"fox") | SORT _score DESC | LIMIT 5)
( WHERE knn(image_vector, [0.1, 3.2, 2.1], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 5 )
| FUSE
| SORT _score DESC如上所示,混合搜索查询只是利用了 rrf 检索器,该检索器结合了使用标准检索器进行的词汇搜索查询(例如,匹配查询)和在 knn 检索器中指定的向量搜索查询。此查询的作用是首先在全局级别检索前五个向量匹配项,然后将它们与词汇匹配项结合,最后返回 10 个最佳匹配结果。rrf 检索器使用 RRF 排序来结合向量匹配和词汇匹配。
理解稀疏向量和 ELSER
密集嵌入并不是进行语义搜索的唯一方式。
稀疏向量主要包含零值,只有少数带权重的值与可解释的词项相关联,这使得它们在资源利用上高效、可解释,并且在零样本场景中有效。
稀疏向量表示如下:
{"f1":1.2,"f2":0.3,… }
在 Elasticsearch 中,Elastic Learned Sparse EncodeR (ELSER) 是一个域外稀疏自然语言处理 (NLP) 模型,它将文本扩展为语义相关的词项并分配权重,从而实现超越精确关键词的匹配,同时保持可解释性。
此外,semantic_text 字段通过在索引时自动处理嵌入生成和推理,使语义搜索变得像传统文本搜索一样简单。您可以像文本字段一样索引文档,并运行简单的匹配查询——即使是跨字段类型不同的索引——无需额外的查询逻辑即可获得词汇和语义匹配项。如需高级控制,可以在同一字段上使用 knn 或 sparse_vector 查询。
ELSER 示例:
- 预训练词汇量约为 30000 个词项
- 存储为 sparse_vector(词项/权重对)
- 通过 semantic_text 在索引时自动生成,或利用推理摄取处理器在索引时自动生成
- 通过倒排索引(类似于词汇搜索)进行查询,使其高效、易于筛选且可解释
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
密集向量和稀疏向量共同提供了灵活性:密集向量擅长捕捉细微的含义,而稀疏向量则提供透明性和可扩展性,适用于实际搜索。
看看 ELSER 的文本扩展如何帮助您获得更好的结果:
实践中的稀疏向量与密集向量对比
| 稀疏向量 (ELSER) | 密集向量 | |
|---|---|---|
| 运作方式 | 将文本扩展为语义相关的加权术语。每个维度对应一个带有权重的词元。 | 将内容(文本、图像等)编码为固定长度的浮点向量。含义相似 = 向量空间中位置接近。 |
| 优势 |
|
|
| 示例用例 |
|
|
| 非常适合 | 当您需要语义改进和透明度时,或者当特定领域的词项最重要时 | 当您需要在各种数据类型中根据意义而非确切词语进行发现和相似性分析时 |
使用密集和稀疏模型的混合搜索
到目前为止,我们已经看到了运行混合搜索的两种不同方式,具体取决于搜索的是密集向量空间还是稀疏向量空间。我们可以在同一个索引内混合使用密集和稀疏数据。
POST my-index/_search
{
"_source": false,
"fields": [ "text_field" ],
"retriever": {
"rrf": {
"retrievers": [
{
"knn": {
"field": "image_vector",
"query_vector": [0.1, 3.2, ..., 2.1],
"k": 5,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
更进一步:结合密集向量、稀疏向量和 BM25F 的混合搜索
此示例结合了三个检索器,并使用 RRF 融合它们的排序列表:
- BM25F(匹配文本):精确的关键词/短语匹配(“snowy mountain”)
- kNN(image_vector):使用提供的图像嵌入进行视觉相似性搜索( k 个结果来自 num_candidates)
- 语义(semantic_text):通过查询的语义扩展进行概念匹配
rank_window_size 控制融合结果的数量;rank_constant 平衡每个列表的贡献。
GET my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text": {
"query": "snowy mountain"
}
}
}
}
},
{
"knn": {
"field": "image_vector",
"query_vector": [
0.01,
0.3,
-0.4
],
"k": 10,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"semantic": {
"field": "semantic_text",
"query": "snowy mountain"
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 60
}
}
}
让我们也看一个类似的 ES|QL 示例:
FROM my-index METADATA _score
| FORK (WHERE match(text, "snowy mountain") | SORT _score DESC | LIMIT 50)
(WHERE knn(image_vector, [0.01, 0.3, -0.4], {"min_candidates": 100 }) | SORT _score DESC | LIMIT 50)
(WHERE match(semantic_text, "snowy mountain") | SORT _score DESC | LIMIT 50)
| FUSE RRF WITH {"rank_constant": 60 } // 60 is the default anyway?
| SORT _score DESC
| LIMIT 50结论
混合搜索将全文搜索的精确性与语义搜索的上下文覆盖范围结合在一起,在各种内容中提供更准确、更相关的结果。通过支持密集和稀疏模型,并提供灵活的融合方法,如线性组合和倒数排序融合,您可以根据用例定制检索——无论是直接组合查询和向量,还是使用检索器简化多阶段检索。这种灵活性使混合搜索成为处理复杂查询、多样化数据和严苛相关性要求的强大方法。
详细了解混合搜索:
- 阅读这篇博文,深入了解什么是混合搜索、Elasticsearch 支持哪些查询类型,以及如何构建这些查询。
- 您知道,就上下文而言 — 混合搜索和上下文工程的演变
- ES|QL 中的混合搜索与多阶段检索
- 无忧混合搜索:通过检索器简化混合搜索
想超越向量吗?了解 Elasticsearch 中与 LLM 智能体结合的智能混合搜索。
准备好动手实践了吗?学习我们的混合搜索教程,将全文结果和 kNN 结果结合起来,或者尝试使用 ES|QL 教程,使用 ES|QL 进行搜索和筛选。