具有可信上下文的 RAG
AI 应用必须在规模化场景下提供准确结果,才能建立用户信任。借助 Elasticsearch 混合检索的准确性,为 LLM 提供可靠的上下文支撑,并实现低延迟、高效率的 RAG 扩展。
为卓越准确性与高效向量扩展而构建的 RAG
提供生产环境所需的上下文,兼顾向量性能、成本效率与安全性。
通过混合搜索、语义重排序和内置推理(结合第三方或原生领先的 Jina AI 模型),为您的 RAG 应用提供精准上下文。使用融合关键词、向量和过滤条件的单一查询,替代仅依赖向量的简单检索。


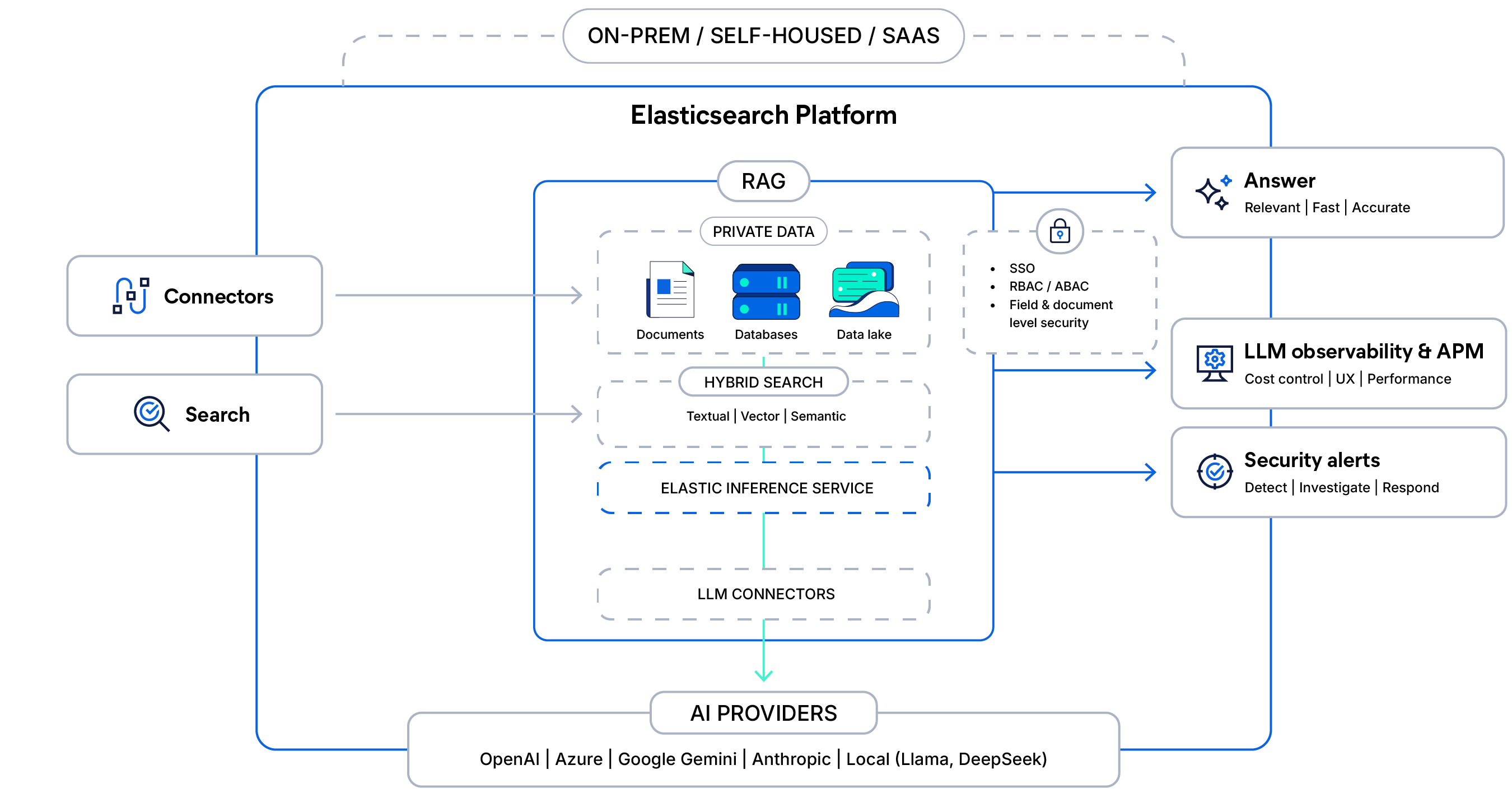
情境感知 RAG 背后的架构
将您的私有数据与安全的混合搜索和托管推理相结合,通过访问控制为 LLM 响应提供依据,并在规模化场景下提供快速、可观测、生产就绪的答案。
您正在构建什么?
基于您的数据构建对话应用,并打造上下文驱动的智能体。探索完整培训目录,或在 Elasticsearch Labs 上跟随教程实践。


常见问题
在人工智能中,RAG 是什么?
在人工智能中,RAG 是什么?
检索增强生成(RAG,Retrieval Augmented Generation)是一种自然语言处理模式,使企业能够搜索专有数据源,并提供可为大语言模型提供支撑的上下文。这使生成式 AI 应用能够给出更准确、更具实时性的响应。
RAG 有哪些好处?
RAG 有哪些好处?
在实施得当的情况下,RAG 可实时安全地访问相关的领域专有数据,减少生成式 AI 应用中的幻觉,并提升响应精度。
使用 Elastic 进行 RAG 工作流程有哪些优势?
使用 Elastic 进行 RAG 工作流程有哪些优势?
Elastic 通过开箱即用的能力解决 RAG 最棘手的难题,包括摄取高质量数据、为模型响应提供可靠依据、在大规模场景下实现准确高效的检索、实施基于角色和文档级的安全控制,以及保留来源归因以确保响应可信。借助原生向量、词法与混合检索,结合 ELSER 等自研模型及灵活的第三方模型集成,并依托经验证的企业级性能,Elastic 帮助团队更快上线、更易调优,并稳定运行 RAG 系统。
Elasticsearch 如何实现上下文工程?
Elasticsearch 如何实现上下文工程?
Elasticsearch 专为大规模相关性而构建,这是上下文工程的基础。它将向量搜索、关键词搜索和结构化搜索与分析、推理和可观测性整合到一个平台中。这使开发人员能够轻松存储、检索并精准排序结构化和非结构化业务数据,从而确保智能体始终获得正确的上下文。
借助 Agent Builder,Elasticsearch 更进一步,将聊天、检索、工具创建和编排直接引入平台。开发人员可利用自己的数据、模型和工具,在几分钟内构建、测试并扩展上下文驱动型智能体,且全程由 Elasticsearch 的相关性、安全性和性能提供支持。