上下文工程的核心能力
构建可靠的 AI 始于上下文。
上下文工程将数据、检索、工具和记忆连接起来,这些是使模型能够从正确的信息中学习、推理并行动的关键组成部分。




Elastic 优势:为您的智能体提供合适的信息、工具和防护措施
所有数据。单一平台,建立上下文。
使用 Elasticsearch 构建上下文。添加精准搜索,或构建完整的对话式 AI 技术栈。可从任意环节开始,使用默认值和扩展选择,从简单的 Q&A 到复杂的智能体工作流,塑造您的相关性之旅。在云端、本地或完全隔离的环境中部署 — 您的上下文层在数据所在之处运行。
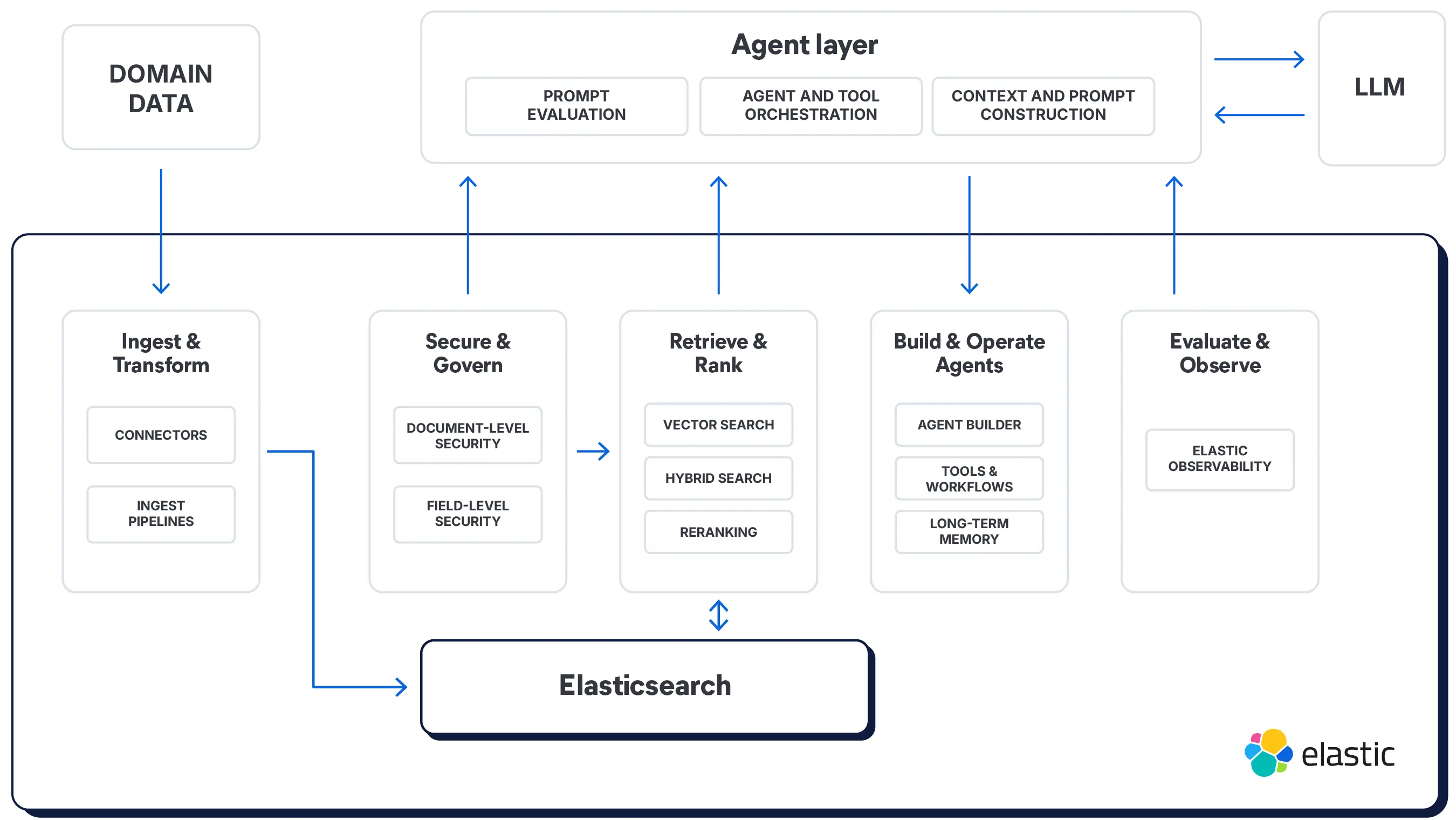
上下文工程启动平台
为您的数据生命周期提供强大的 API。索引、搜索、筛选、应用基于角色的访问控制(RBAC)——针对文本、嵌入、地理、时间序列或元数据。
定义摄取管道,对文档进行清理、标注和规范化,以确保出处清晰,字段可解析。
POST /_ingest/pipeline { "description": "Clean and enrich documents", "processors": [ { "set": { "field": "source", "value": "access_logs_prod" } }, { "grok": { "field": "message", "patterns": [ "{TIMESTAMP_ISO8601:timestamp} User %{WORD:user} accessed - %{IP:ip}" ] } } ] }
POST /_ingest/pipeline
{
"description": "Clean and enrich documents",
"processors": [
{
"set": {
"field": "source",
"value": "access_logs_prod"
}
},
{
"grok": {
"field": "message",
"patterns": [
"{TIMESTAMP_ISO8601:timestamp} User %{WORD:user} accessed - %{IP:ip}"
]
}
}
]
}
组合并管理您的智能体
只需一小段代码即可创建并扩展工具、代理和聊天界面。
同类最佳?内置
首先在 Elastic Inference Service (EIS) 上使用 Jina AI 模型。或者,通过跨 AI 生态系统的原生集成,接入您已经在使用的模型。
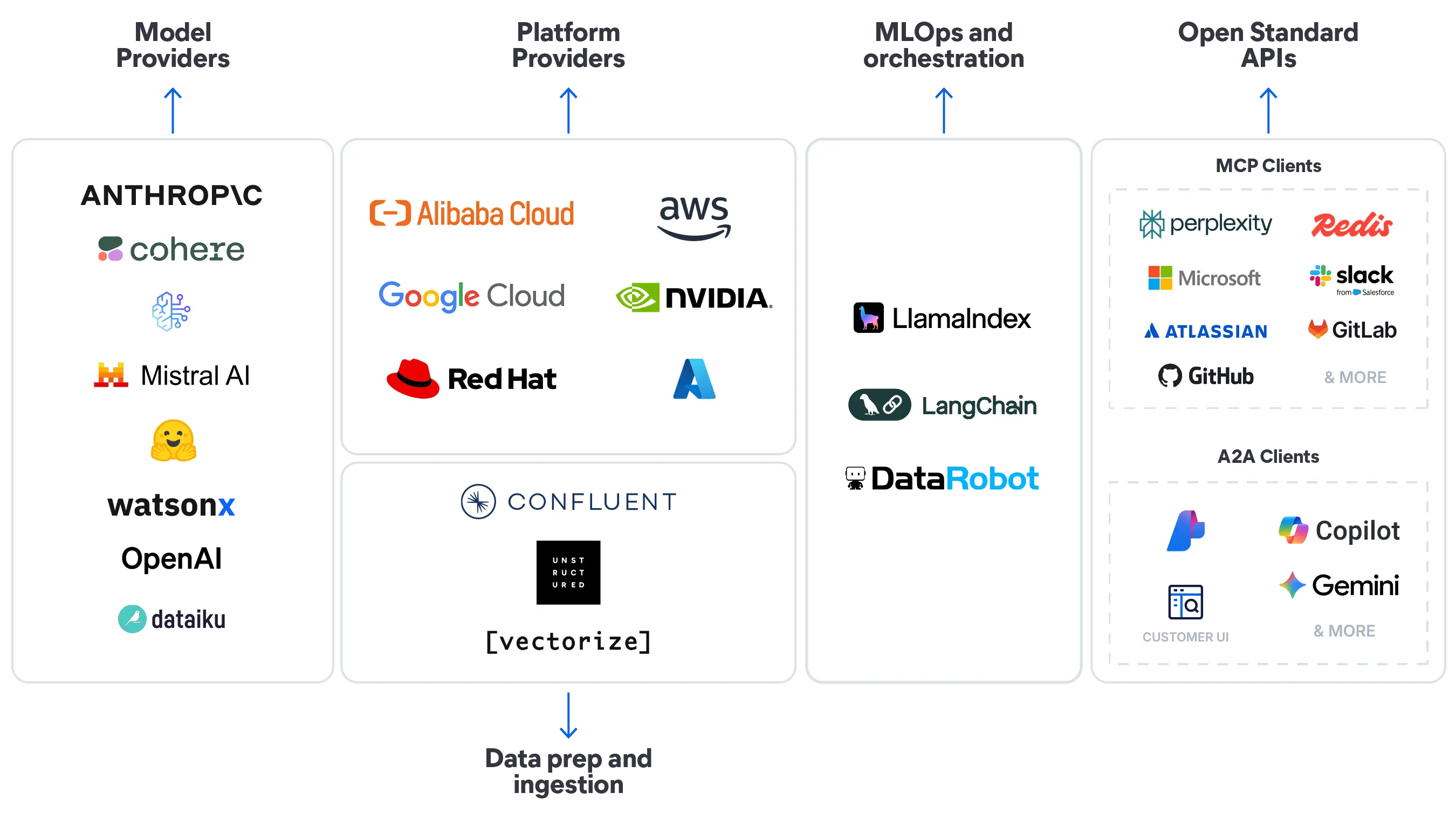
调优您的相关性之旅
Elasticsearch 让您在各个层面都能掌控相关性——从精确搜索到完整的对话式 AI 技术栈。
在 Elasticsearch Labs 的博客中探索完整的调优之旅。
常见问题
为什么上下文对 AI 和智能体很重要?
为什么上下文对 AI 和智能体很重要?
智能体难以在不同工作流中长期维护上下文、状态和记忆。随着时间的推移,上下文使智能体能够持续保持连贯性、觉察能力与一致性。如果没有上下文,即使是强大的模型也会失去关键线索,导致遗漏、幻觉或误解。上下文工程确保每次响应都基于准确、相关且及时的信息。
Elasticsearch 如何实现上下文工程?
Elasticsearch 如何实现上下文工程?
Elasticsearch 专为大规模相关性而构建,这是上下文工程的基础。它将向量搜索、关键词搜索和结构化搜索与分析、推理和可观测性整合到一个平台中。这使开发人员能够轻松存储、检索并精准排序结构化和非结构化业务数据,从而确保智能体始终获得正确的上下文。
借助 Agent Builder,Elasticsearch 更进一步,将聊天、检索、工具创建和编排直接引入平台。开发人员可利用自己的数据、模型和工具,在几分钟内构建、测试并扩展上下文驱动型智能体,且全程由 Elasticsearch 的相关性、安全性和性能提供支持。
我可以使用自己的模型或框架吗?
我可以使用自己的模型或框架吗?
可以。通过开放推理 API 以及与 LangChain、LlamaIndex 和模型上下文协议 (MCP) 的集成,您可以直接在 Elasticsearch 上引入自有模型并扩展 Agent Builder 工作流。
我可以在本地部署或隔离环境中进行上下文工程吗?
我可以在本地部署或隔离环境中进行上下文工程吗?
是的。Elasticsearch 支持完全本地部署的主权云和隔离式部署,无需外部连接。国防、政府、金融服务和医疗保健领域的组织可以完全在自己的基础架构内构建完整的上下文工程管道,包括混合检索、语义重排、代理工作流和 RBAC。使用 Elastic Cloud Enterprise(ECE),利用 Elastic 用于运行 Elastic Cloud 的相同工具,大规模编排本地部署的 Elasticsearch 集群。