大规模测试新的 Elasticsearch 冷层可搜索快照
之前在 Elasticsearch 7.10 版中以公测版推出的可搜索快照的冷层,现已在 Elasticsearch 7.11 版中正式发布。与温层相比,这个新的数据层在保持与热层和温层同等可靠性和冗余度的同时,可将集群存储量缩减最多达 50%。
在这篇博客中,我们将带您了解一下我们为确保冷层在大规模部署中完美运行而探索过的场景,这些研究探索突显了我们高度重视解决方案的质量和可靠性。
冷层知识回顾
冷层仅将主分片保留在本地存储上,不需要副本分片,而是依靠快照(保留在 AWS S3、Google Storage 或 Microsoft Azure Storage 等对象存储中)来提供必要的弹性,从而降低了集群成本。本地存储本质上类似于存储库中快照数据的缓存版本。
在冷节点或本地存储运行不正常的情况下,可搜索快照将自动恢复,并将分片重新平衡到其他节点上。
在全集群重启或滚动重启(或节点重启)的情况下,本地存储是持久性的,本地可用的数据将不会从快照中重新下载,从而最大限度地减少恢复为绿色集群所需的时间,并避免不必要的网络成本。
为了确保所有这些工作在大规模部署时能按预期进行,我们将验证工作集中在 3 个场景上,所有场景都使用以下配置:
- 5 个 Elasticsearch 节点(16G 堆)
- 采用 RAID-0 配置的 6 个 2TB 磁盘
- 5TB 的日志数据快照,分布在 10 个索引中,每个索引有 5 个分片,强制合并为一个段(强制合并可优化索引以提高读取访问性能,并减少发生故障时需要恢复的文件数量)
场景 1:全集群重启
我们验证的第一个场景是全集群重启。为了验证这一点,我们完成了以下步骤:
- 挂载 5TB 可搜索快照并等待本地缓存完全预热(第 0 阶段)。
- 根据全集群重启指南执行一次全集群重启。
- 重新启用分配后,测量集群需要多长时间:
- 变为绿色状态。
- 完成所有后台下载以预热缓存。
- 确保在第 3 步之后没有额外的分片重新平衡。
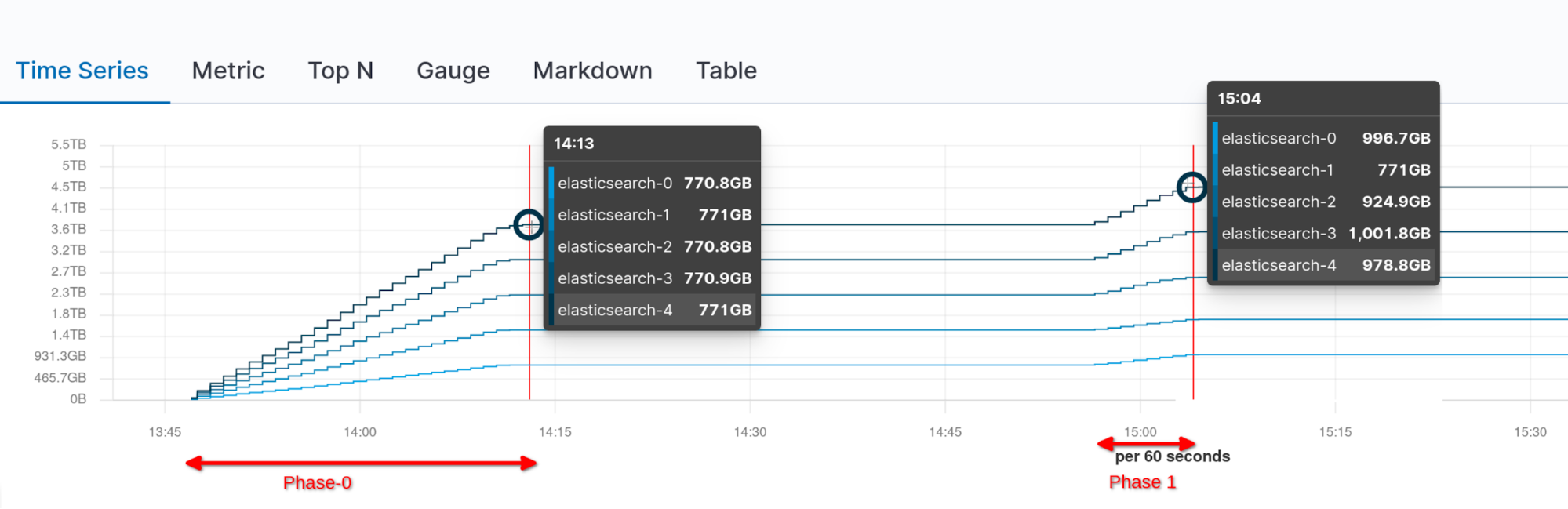
得益于 Elasticsearch 7.11 版新引入的持久层,启动所有节点并重新启用分配后,集群状态立即变为了绿色,不再发生后台下载。
下面我们可以看到挂载期间(第 0 阶段)和全集群重新启动并重新启用分配(第 1 阶段,没有额外的网络流量)后的累积网络流量:

场景 2:滚动重启
我们验证的第二种场景是滚动集群重启这一常见情况。
这个实验与全集群重启类似:
- 挂载 5TB 可搜索快照并等待本地缓存完全预热。
- 通过在停止每个节点之前禁用分片分配,为第一个节点执行滚动重启过程。
- 启动节点并在重新启用分片分配后,测量集群状变为绿色态所需的时间。由于有持久缓存,我们预计这个过程会很快。此外,我们还查明了每次重启后是否会发生不必要的后台下载。
- 对集群中的所有其他节点重复第 2 步和第 3 步。
这个实验也很成功,多亏了在 Elasticsearch 7.11 版中引入的持久缓存,集群状态几乎是瞬间变绿,并且没有从快照中进行额外的后台下载。
场景 3:节点崩溃
最后,我们希望确保在某个节点崩溃时能够执行正确的行为。我们进行了以下实验:
- 挂载 5TB 可搜索快照并等待本地缓存完全预热(第 0 阶段)。
- 从 5 个节点中,终止一个 Elasticsearch 节点(使用
SIGKILL终止节点 1),并等待集群再次变为绿色(第 1 阶段)。- 确保后台下载与从已终止节点托管的分片接收数据相关。
- 变为绿色后,不应进行额外的重新平衡。
- 再次启动故障节点(第 2 阶段):
- 只应进行对等恢复(因为所有数据都存在于其余 4 个节点上)来重新平衡分片。
- 集群应变为绿色。
再一次,这个实验也成功了。终止节点 1 后,其余节点会(从可搜索快照)自动恢复缺失节点托管的分片。
集群变为绿色后,没有发生额外的重新平衡,具体见下图,其中直观显示了每个节点的网络流量:
在恢复缺失的节点后,便开始对等恢复,节点 1 最终再次托管了必要数量的分片,以达到一个均匀分布的集群。

即刻开始使用
这个功能验证过程让我们非常激动,我们希望它也能引起您的兴趣!
要开始使用可搜索快照以及在冷层存储数据,既可在 Elastic Cloud 上快速部署一个集群,也可安装最新版本的 Elastic Stack。已经在运行 Elasticsearch?只需将集群升级到 7.11 版,即可开始试用。如果希望了解更多信息,请阅读数据层和可搜索快照文档。