无状态 — 您使用 Elasticsearch 查找的新状态
不断发展您的 Elasticsearch 架构以简化部署



在 Twitter 上分享


在 LinkedIn 上分享


在 Facebook 上分享


通过邮件分享


打印
我们的初始历程
Elasticsearch 的首个版本是一个分布式可扩展搜索引擎,于 2010 年发布,它能够让客户快速搜索并收获关键洞察。十二年已经过去,这期间有超过 65,000 次提交,时至今日,Elasticsearch 仍在继续为用户提供经过实战检验的解决方案以解决广泛的搜索问题。由于有了超过 1,500 名贡献者(包括数百名 Elastic 全职员工)的付出,Elasticsearch 一直在持续发展以满足搜索领域涌现的新难题。
在 Elasticsearch 成立早期,由于有人提出了数据丢失问题,Elastic 团队付出了多年的努力来重新编写集群协作系统,以保证能够安全地存储已确认的数据。当管理大型集群中的索引很明显成为一个棘手问题时,我们的团队致力于实施全面的 ILM 解决方案,通过允许用户预定义索引模式和生命周期操作,实现索引管理的自动化。随着用户发现需要存储大量的指标和时序数据,我们添加了各种功能(诸如更好地进行压缩)来降低数据量。随着搜索大量冷数据的存储成本的增加,我们投入精力创建可搜索快照;通过可搜索快照,用户能够直接在低成本对象存储上搜索用户的数据。
我们的这些努力为 Elasticsearch 的下一次发展奠定了基础。随着云原生服务和新编排系统的增长,我们决定现在需要继续发展 Elasticsearch 来改善使用云原生系统时的体验。我们坚信:在 Elastic Cloud 上运行 Elasticsearch 时,这些变化在运维、性能和改善成本方面能带来机遇。
我们的发展方向——未来是无状态
运维或编排 Elasticsearch 时的主要挑战之一是它依赖很多种持久状态数据,因此它是一个有状态系统。三种主要数据是事务日志、索引存储和集群元数据。这一状态表示存储必须持久,而且在节点重启或替换期间不能丢失。
Elastic Cloud 上的既有 Elasticsearch 架构必须跨多个可用区复制索引,从而在发生中断时提供冗余。我们希望将此数据的持久性从本地磁盘转移至对象存储,例如 AWS S3。通过依赖外部服务来存储此数据,我们将无需对复制进行索引,从而大幅减少与采集相关的硬件。鉴于云对象存储(例如 AWS S3、GCP Cloud Storage 和 Azure Blob Storage)跨可用区复制数据的方式,这一架构还能提供很高的可靠性保证。
将索引存储转移到外部服务后,我们还可以通过分离索引和搜索责任来对 Elasticsearch 进行重新架构。我们不想拥有一个主实例和一个复制实例来同时处理两种工作负载,而是希望拥有一个索引层和一个搜索层。通过分离这些工作负载,它们可以单独进行扩展,而且对于相应的用例,硬件选择也可以更加具有针对性。它还有助于解决这个长期挑战:搜索和索引负载会相互影响。
在经过了长达数月的概念验证和实验阶段之后,我们确信这些对象存储服务能够满足我们为索引存储和集群元数据所设想的要求。我们的测试和基准测试显示,这些存储服务能够满足我们在 Elastic Cloud 上所看到的最大集群的高索引需求。除此之外,将数据备份在对象存储中能够降低索引成本,并允许对搜索性能进行简单微调。为了能够搜索数据,Elasticsearch 将会使用经过实战检验的可搜索快照模型;在此模型中,数据会永久持续保存在云原生对象存储中,并将本地磁盘用作频繁访问的数据的缓存。
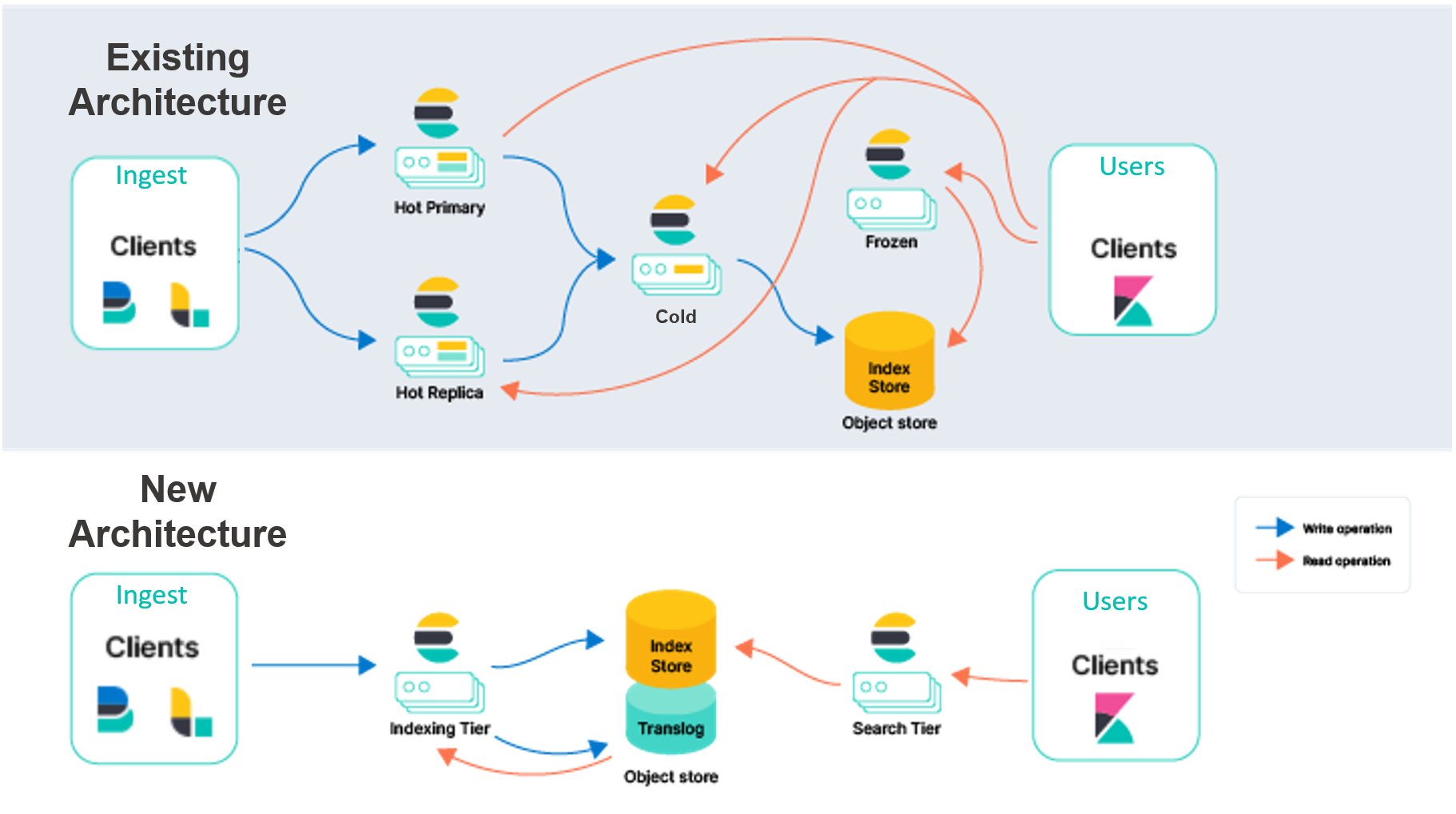
为了帮助区分,我们将既有模型描述为“节点到节点”复制。在此模型的热层中,主分片和副本分片都会完成同等繁重的工作,来处理“采集和服务”搜索请求。这些节点是“有状态的”,因为它们依赖本地磁盘来安全地为它们所托管的分片持续保存数据。此外,分片和副本分片会持续通信以保持同步。它们实现这一点的方法是:将在主分片上执行的操作复制到副本分片上,这意味着这些操作的成本(主要是 CPU)会针对每个指定的副本产生。完成这一采集工作的同样分片和节点还会完成搜索请求,因此在配置和扩展时必须将这两个工作负载都考虑在内。
除了搜索和采集,节点至节点复制模型中的分片还能处理其他繁重任务,例如合并 Lucene 段。虽然这一设计有其优点,根据我们多年来从客户那里了解到的知识以及更广意义上的云生态系统的演变,我们看到了大量机遇。
新架构能够帮助实现很多即时和未来的改进,包括:
- 您可以大幅增加在同一硬件上的采集吞吐量,或者换言之,大幅提高同一采集工作负载的效率。之所以能提高是因为不再针对每个副本复制索引操作。CPU 密集型索引操作仅需要在索引层上完成一次,然后便会将生成的段发送到对象存储。在那里,数据便已准备好可被搜索层使用。
- 您可以将计算和存储分离开来,以简化您的集群拓扑。今天,Elasticsearch 拥有多个数据层(内容、热、温、冷,以及冻结)以将数据与硬件配置文件进行匹配。热层适用于近实时搜索,冻结层则适用于搜索不太频繁的数据。尽管这些层各有其价值,但也增加了复杂性。在新架构中,数据层将不再有必要,从而简化了 Elasticsearch 的配置和运维。我们还将索引与搜索分离开来,从而进一步降低复杂性,并让我们能够单独地扩展这两个工作负载。
- 由于减少了必须存储在本地磁盘上的数据量,您能够在索引层上体验到存储成本方面的改进。当前,在索引时,Elasticsearch 必须在热节点上(同时包括主节点和副本节点)存储一个完整的分片副本。通过将数据直接索引到对象存储的无状态方法,仅需要这些本地数据的一部分即可。对于纯添加用例,索引时仅需存储部分元数据。这能够大幅降低索引所需的本地存储。
- 您能够降低与搜索查询相关的存储成本。通过将可搜索快照模型作为搜索数据的原生模式,与搜索查询相关的存储成本将会大幅降低。取决于用户的搜索延迟需求,Elasticsearch 将会允许进行调整以提高对频繁请求数据的本地缓存。
基准测试 — 索引吞吐量提升 75%
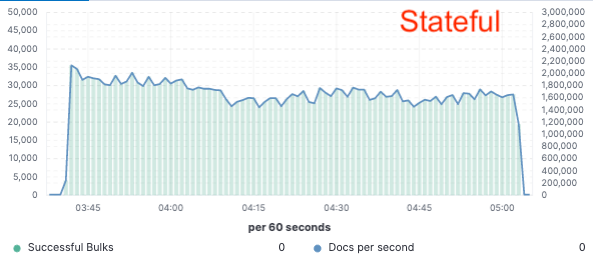
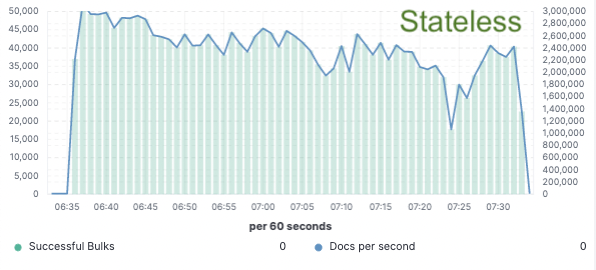
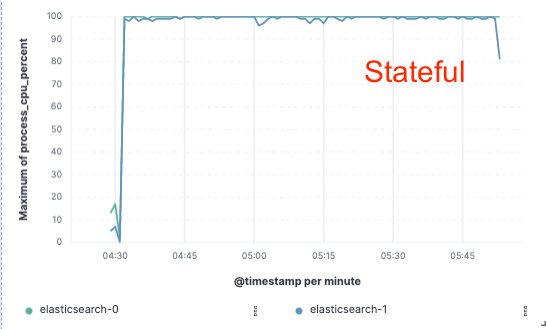
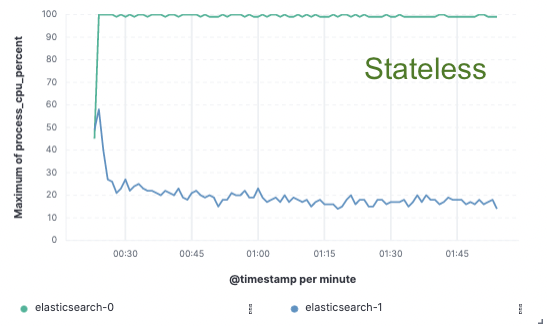
为了验证这一方法,我们实施了大量的概念验证;在概念验证时,我们仅将数据索引到单一节点上,而通过云对象存储进行复制。我们发现由于无需专门的硬件进行索引复制,我们可以将索引吞吐量提升 75%。不仅如此,与在本地索引并写入数据(今天对于热层有必要如此做)相比,简单地从对象存储拉取数据这一做法的 CPU 成本也降低了很多。这意味着搜索节点能够完全将其 CPU 专门用于搜索。
我们针对所有三大公共云服务提供商(AWS、GCP 和 Azure)在一个包含两个节点的集群上完成了这些性能测试。由于我们追求的是生产无状态实施过程,我们希望继续构建更大型的基准测试。
索引吞吐量
CPU 使用率
我们推出无状态,助您实现节省
Elastic Cloud 上的无状态架构将能够允许您降低索引开销,单独对采集和搜索进行扩展,简化数据层的管理,并加速完成运维工作(例如扩展或升级)。这是对 Elastic Cloud 平台进行重大现代化的首个里程碑。
欢迎和我们一起实现无状态愿景
想要抢先尝试这一解决方案?您可以在 discuss 上或通过我们社区的 Slack 频道与我们联系。我们真心希望倾听您的反馈,您的反馈能帮助我们确定新架构的方向。
分享
在 Twitter 上分享
在 LinkedIn 上分享
在 Facebook 上分享
通过邮件分享
打印

