在 Elasticsearch 7.10 中通过提高存储效率节省空间和成本
我们很高兴地宣布,在 Elasticsearch 7.10 中创建的索引将更小了。一味求大并非都是好事,我们的内部基准测试报告显示,空间占用降幅高达 10%。
对于小型用例来说,这个数字可能看起来不算大,但对于处理 PB 量级数据(并需要为之支付云存储费用)的团队来说,这无疑是一笔非常可观的费用。特别是,对于我们的 Elastic 可观测性和 Elastic 安全解决方案所创建的索引,由于其中保存的数据具有重复性,因此节省效果会最明显。
我们下面先看看这项改进的工作原理,然后再探索一下让节省变为现实的 Apache Lucene 8.7 更新。
当前存储的字段是如何压缩的
存储的字段是索引的一部分,用于存储文档的 _id 及其 _source。现在,存储的字段会被拆分成独立压缩的块。
为什么我们要拆分成数据块?数据块有助于保持对数据的快速随机访问。如果您要从存储的字段中检索字节序列,只需解压缩包含此字节序列中一个或多个字节的块即可。反之,如果您一次性压缩了所有数据,那么您会别无选择,只能在读取时解压缩所有数据,即使只需要其中的一个字节也要这样做。
Elasticsearch 提供了两种压缩选项:index.codec: default,指示 Elasticsearch 使用经 LZ4 压缩的 16kB 块;index.codec: best_compression,指示 Elasticsearch 使用经 DEFLATE 压缩的 60kB 块。
这两种压缩算法的一个重要组成部分就是字符串去重。每当在流中找到先前出现过的字符串时,便会将该字符串替换为对先前出现的那个字符串的引用。实际上,这是 LZ4 唯一做的事情,而 DEFLATE 会将字符串去重与 Huffman 编码结合起来,以便进一步压缩数据。

在对可观测性用例所产生的索引空间效率进行调查后,我们注意到增加块大小会显著提高压缩比。遗憾的是,增加块大小不是没有成本的,因为它们需要在检索时解压缩更多数据,这可能会降低 _search 的性能。
消解压缩之困的字典
通过字典既可以获得增大块大小的益处,又不会牺牲检索效率。具体方案是为压缩算法提供一个数据字典,该字典也可用于字符串去重。如果要压缩的数据流和字典之间有很多重复字符串,那么您可能最终会得到更好的压缩比。您要做的只是在解压时提供完全相同的字典,以便能够解压缩数据。
从 7.10 版开始,Elasticsearch 使用了更大的数据块,这些数据块本身被拆分为一个字典和 10 个使用该字典进行压缩的子块。
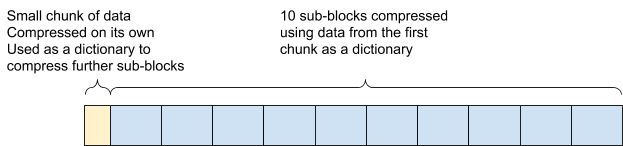
检索子块中包含的文档时,需要使用这个字典解压缩字典和包含文档的子块。
index.codec: default 现在使用经 LZ4 压缩的 4kB 字典和 60kB 的子块,而 index.codec: best_compression 使用经 DEFLATE 压缩的 8kB 字典和 48kB 的子块。默认编解码器增加的块大小可能会让您感到意外,因为上面提到过,更大的块大小会增加检索时间。
但是,我们的基准测试表明,从 16kB 增加到 60kB 可以显著提高压缩比,而对检索时间的影响却很小。因为我们的测试显示,大多数用户不会注意到任何形式的速度下降,所以我们决定使用更大的块。
这个更新什么时候最有益?
可观测性(数据日志、指标和跟踪)和安全数据(终端数据、日志)的一个特殊性在于,生成的文档包含有关所观测内容的重要元数据,并且这些元数据在各个文档之间的变化不大。即使您正在监测许多主机或终端,其中的许多系统通常也会有共同的属性(如它们的操作系统)。这就使得这些文档具有高度可压缩性,使用字典将有助于移除更多重复的字符串,因为操作系统将不再是每 60kB 重复一次(假设是 best_compression),而是每 8+10*48=488kB 重复一次。
结论
默认情况下,7.10 版中创建的所有新索引都将利用这项效率改进。您现有的任何索引都会在下次合并时自动更新,以使用这项改进,尽管这可能只会影响到您的热索引。
我们鼓励您在现有的部署中尝试一下,或者在 Elastic Cloud 上轻松免费试用 Elasticsearch Service(始终会提供最新版的 Elasticsearch)。我们期待听到您的反馈,请前往讨论区告知我们您的想法。