如何使用 Elastic 可观测性来监测 NVIDIA GPU 指标
图形处理器简称为 GPU,它可不只是用来玩电脑游戏的。当今,GPU 还可用来训练神经网络、模拟“计算流体动力学”、挖矿挣比特币,以及处理数据中心的工作负载。而且它们是大部分高性能计算系统的核心,所以在当今的数据中心,监测 GPU 性能和监测 CPU 性能一样重要。
鉴于这一点,我们来看一下如何利用 Elastic 可观测性和 NVIDIA 的 GPU 监测工具来观测和优化 GPU 的性能。
依赖因素
要将 NVIDIA GPU 指标设置完毕并成功运行,我们需要从源代码 (Go) 构建 NVIDIA GPU 监测工具。对了,我们需要一个 NVIDIA GPU。由于 AMD 和其他 GPU 类型使用不同的 Linux 驱动器和监测工具,所以我们会在其他博文中对它们讲解。
很多云提供商,例如 Google Cloud 和 Amazon Web Services (AWS),都提供 NVIDIA GPU。在本文中,我们将会使用 Genesis Cloud 上运行的一个实例。
首先我们要找到适用于 Ubuntu 18.04 的 NVIDIA DCGM 入门指南,按照其中安装部分的说明,安装 NVIDIA Datacenter Manager(NVIDIA 数据中心管理器)。注意:遵照指南进行操作时,请额外注意使用您自己的信息替代 <architecture>。可以使用 uname 命令来找出我们的架构。
uname -a
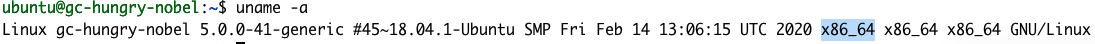
这条响应告诉我们 X86_64 是我们的架构。所以《入门指南》中的第 1 步就是:
echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
同时,第 2 步中有个拼写错误。移除 $distribution 后面的 >。
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub
安装完毕后,运行 nvidia-smi 命令应该就能看到我们的 GPU 详情。
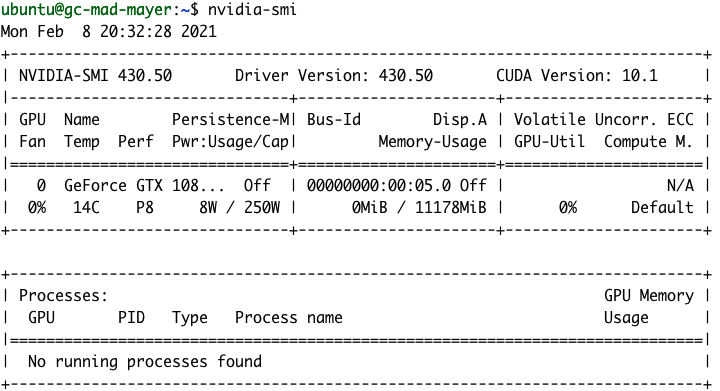
NVIDIA GPU 监测工具
要构建 NVIDIA 的 GPU 监测工具,我们需要安装 Golang。所以,我们现在就做这一步。
cd /tmp wget https://golang.org/dl/go1.15.7.linux-amd64.tar.gz sudo mv go1.15.7.linux-amd64.tar.gz /usr/local/ cd /usr/local/ sudo tar -zxf go1.15.7.linux-amd64.tar.gz sudo rm go1.15.7.linux-amd64.tar.gz
好了,现在从 Github 中安装 NVIDIA 的 GPU 监测工具,就可以完成 NVIDIA 的设置了。
cd /tmp git clone https://github.com/NVIDIA/gpu-monitoring-tools.git cd gpu-monitoring-tools/ sudo env "PATH=$PATH:/usr/local/go/bin" make install
Metricbeat
我们现在可以安装 Metricbeat 了。访问 elastic.co 快速查看一下 Metricbeat 的最新版本,然后在下面的命令中调整版本号。
cd /tmp wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.10.2-amd64.deb sudo dpkg -i metricbeat-7.10.2-amd64.deb # 7.10.2 是版本号
Elastic Cloud
好了,现在我们可以设置并运行 Elastic Stack 了。对于新的 GPU 监测数据,我们需要一个主页。因此,我们需要在 Elastic Cloud 上创建一个新部署。如果您还不是 Elastic Cloud 的客户,现在可以注册享受 14 天的免费试用。或者您也可以在本地创建自己的部署。
接下来,在 Elastic Cloud 上创建一个新的“Elastic 可观测性”部署。
您的云部署设置完毕并运行之后,请记下它的 Cloud ID 和身份验证凭据,因为在之后的 Metricbeat 配置中会用得到。
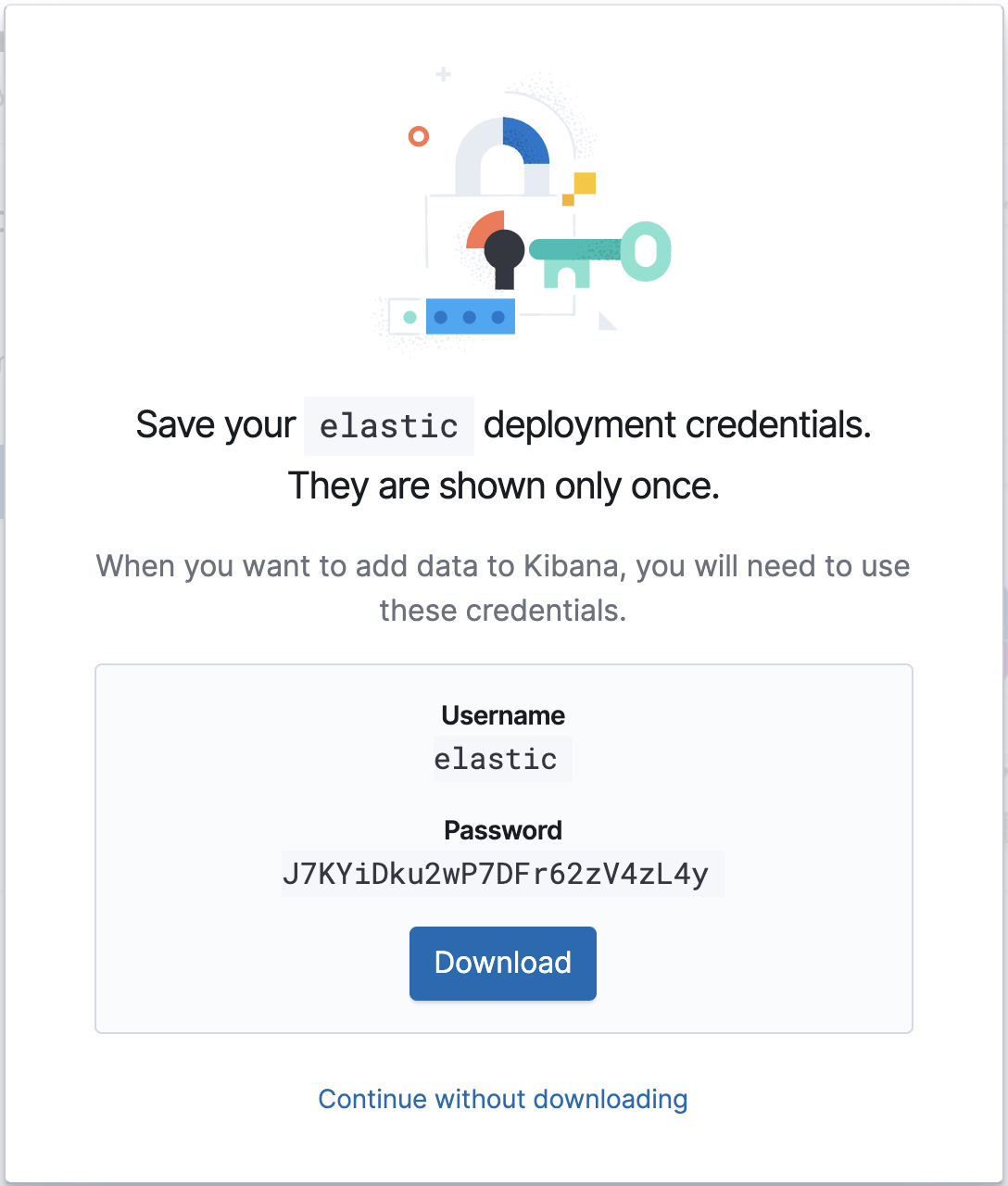
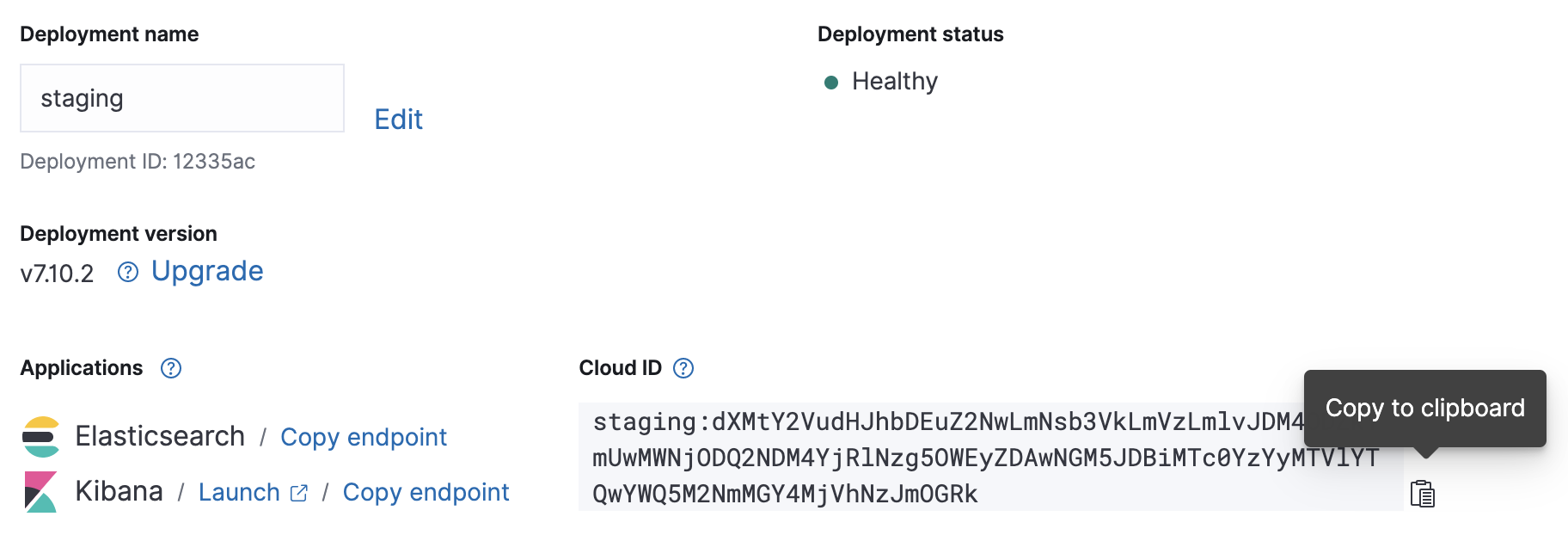
配置
Metricbeat 的配置文件位于 /etc/metricbeat/metricbeat.yml。使用您最喜欢的编辑工具将其打开,然后编辑 cloud.id 和 cloud.auth 参数,让其与您的部署相匹配。
Metricbeat 配置变更示例(使用的是上面的截图):
cloud.id: "staging:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvJDM4ODZkYmUwMWNjODQ2NDM4YjRlNzg5OWEyZDAwNGM5JDBiMTc0YzYyMTVlYTQwYWQ5M2NmMGY4MjVhNzJmOGRk" cloud.auth: "elastic:J7KYiDku2wP7DFr62zV4zL4y"
Metricbeat 的输入配置是模块化的。NVIDIA GPU 监测工具会通过 Prometheus 来发布 GPU 指标,所以我们继续,现在便启用 Prometheus Metricbeat 模块。
sudo metricbeat modules enable prometheus
我们可以使用 Metricbeat 测试和模块命令来确认 Metricbeat 已配置成功。
sudo metricbeat test config

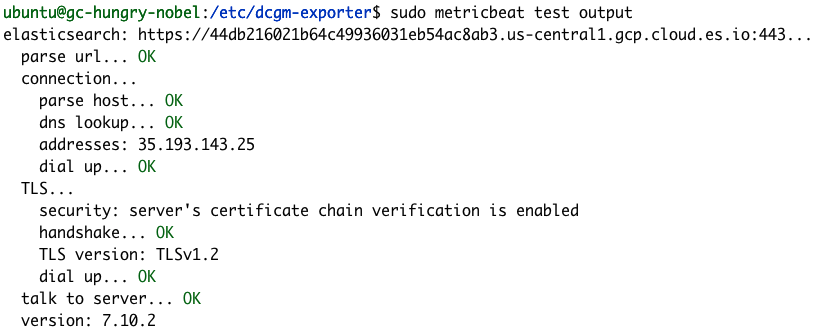
sudo metricbeat test output
sudo metricbeat modules list
如果您的配置测试没能像上面的例子那样取得成功,请查看我们的 Metricbeat 故障排除指南。
我们可以通过运行 Metricbeat 的设置命令(该命令会加载一些默认仪表板并设置索引映射)来完成 Metricbeat 的配置。这条设置命令通常需要几分钟时间才能完成。
sudo metricbeat setup

导出指标
现在可以开始导出指标了。启动 NVIDIA 的 dcgm-exporter(dcgm 导出工具)。
dcgm-exporter --address localhost:9090 # 输出 INFO[0000] Starting dcgm-exporter INFO[0000] DCGM successfully initialized! INFO[0000] Not collecting DCP metrics:Error getting supported metrics:This request is serviced by a module of DCGM that is not currently loaded INFO[0000] Pipeline starting INFO[0000] Starting webserver
注意:您可以忽略 DCP 警告
dcgm-exporter 指标的配置已在文件 /etc/dcgm-exporter/default-counters.csv 中进行定义,该文件中默认定义了 38 种不同的指标。如果需要可能值的完整列表,可以查看 DCGM Library API Reference Guide。
在另一个控制台中,我们会启动 Metricbeat。
sudo metricbeat -e
现在您可以前往 Kibana 实例并刷新 ‘metricbeat-*’ 索引模式。照下面做就可以了:前往 Stack Management(堆栈管理)> Kibana > Index Patterns(索引模式),然后从列表中选择 metricbeat-* 索引模式。然后点击 Refresh field list(刷新字段列表)。
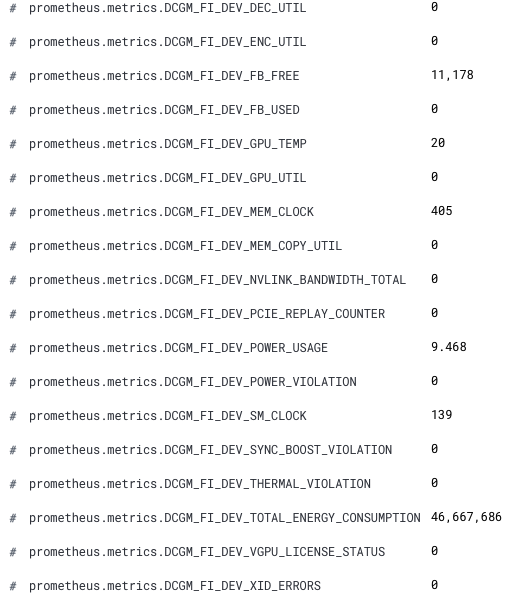
现在我们新的 GPU 指标就会出现在 Kibana 中了。新字段名称的前缀为 prometheus.metrics.DCGM_。下面这个 Discover 中的代码片段便显示了新字段。
恭喜您!我们现在已准备好,可以在 Elastic 可观测性中分析 GPU 指标了。
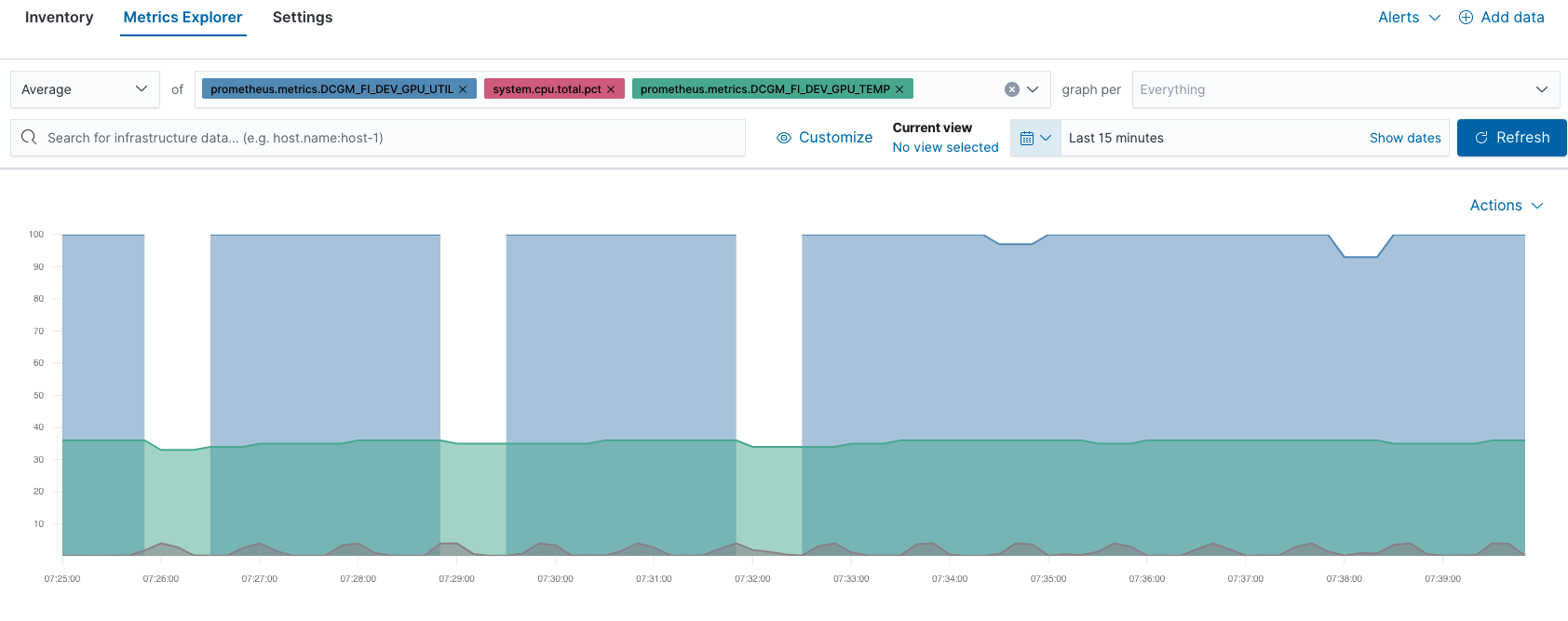
例如,您可以在 Metrics Explorer(指标浏览器)中对比 GPU 和 CPU 性能:
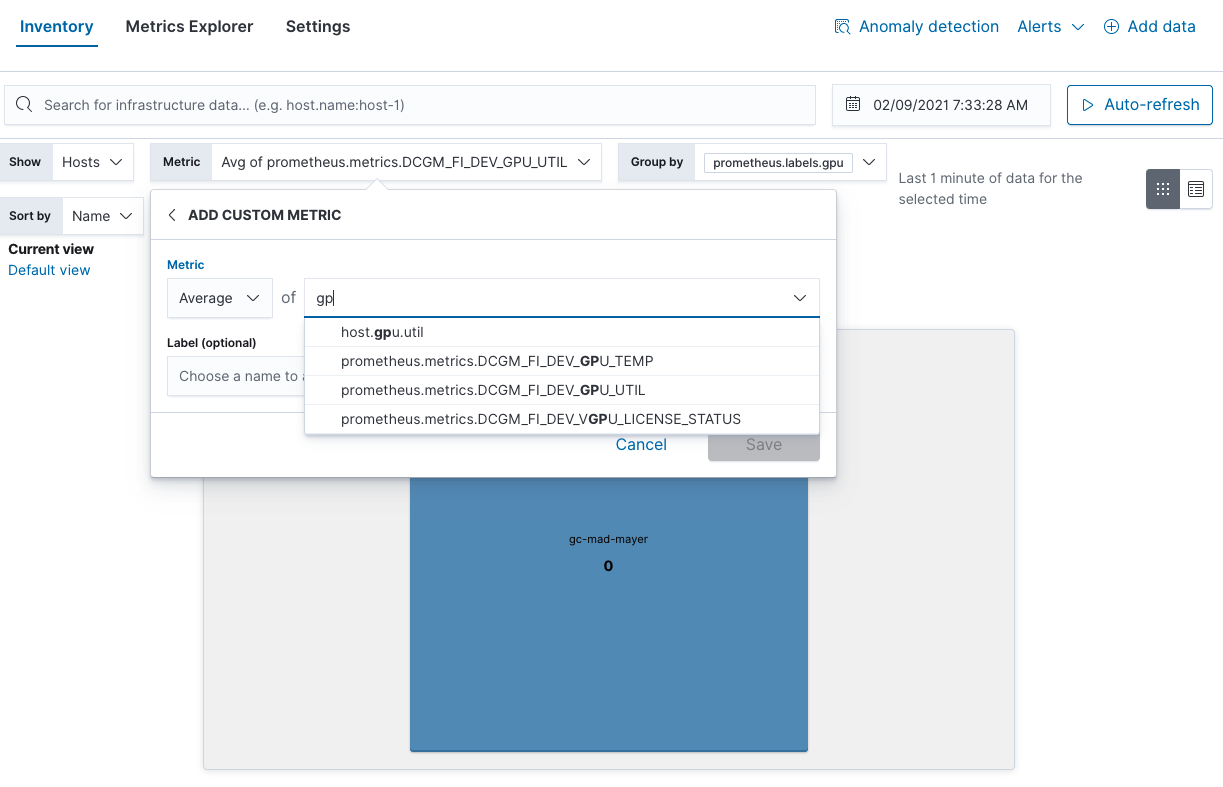
您还可以在 Inventory(库存)视图中找到 GPU 利用率热点:
有关 GPU 监测的几点考虑因素
希望这篇博文能对您有所裨益。这些只是几个监测选项而已,但是 Elastic 可观测性能够让您实现全部目标。我们在下面又列举了几个最好予以监测的 GPU 数据的例子(按照 NVIDIA 的资料):
- GPU 温度:查看热点
- GPU 功耗:功耗高于预期 => 可能存在硬件问题
- 当前时钟速度:低于预期 => 功率封顶,或者硬件问题
而且如果需要模拟 GPU 负载,您可以使用 dcgmproftester10 命令。
dcgmproftester10 --no-dcgm-validation -t 1004 -d 30
您还可以使用 Elastic 告警来自动实施 NVIDIA 的建议,进一步改善您的监测工作。然后再使用 Machine Learning 找出 GPU 基础设施中的异常,让监测成效更上一层楼。如果您不是 Elastic Cloud 的客户,还想试一下本篇博文中的步骤,现在可以注册享受 14 天的免费试用。