KeyBank 使用 Elastic 构建企业级监测解决方案的历程
这篇文章回顾了在 2019 年 Elastic{ON} Tour 芝加哥大会上发表的社区演讲。想了解到更多此类演讲内容?查看会议档案或了解 Elastic{ON} Tour 何时会到您附近的城市举办。
KeyBank 是美国最大的银行之一。随着银行业务的增加,他们的端到端监测系统也越来越庞大。由于 KeyBank 在美国 15 个州设有多达 1,100 个分行和 1,400 台 ATM,公司 Cloud Native 部门的高级产品经理 Mick Miller 表示 KeyBank 的基础设施已俨然发展为一艘“专门打造的诺亚方舟”。换言之,他们所有东西都有两套,最终导致拥有多达 21 个不同的数据孤岛。“我们发现公司的平均解决时间真的很慢,但平均指责时间却超快。”
深挖根本原因
由于有那么多系统,而且无法轻松关联不同数据孤岛之间的数据,所以团队无法了解问题的根本原因。分行纷纷报告工作站的性能很差,而且公司手机银行应用的评分也在下滑,但是由于无法将可观测性数据关联在一起,他们被缚住了手脚。不仅如此,他们的日志和指标系统也开始逼近存储容量的上限,这导致了所有新的监测工作都暂停;然而要是升级上一家服务提供商的许可证,费用高到令人望而却步。
团队开始积压大量的监测请求,这不仅占用了他们开发新系统所需的时间,而且还出现了一个更关键的问题:性能问题导致客户流失。举例说明,当客户开立账户时,系统会持续发生故障,导致耗时过长并且会造成极差的用户体验。而且,如果潜在客户无法轻松开立账户,他们会另找一家银行。
借助 Elasticsearch 提升可观测性
由于他们的系统不再提供日志和指标来帮助调查非安全相关问题,所以 KeyBank 开始改用 Elastic Stack。利用所创建的 Elasticsearch 开发集群,他们向分行网络上的数千台工作站部署了 Winlogbeat 和 Metricbeat,并开始对日志和指标数据进行索引。几天后,他们获得了大量洞察,并且发现了三大根本原因:磁盘 I/O 持续偏高,可用内存低,以及网络完全饱和。
由于 KeyBank 有更多员工能够在 Kibana 中看到响应时间数据的可视化,这一问题的紧急性骤然上升。团队需要开始对整个系统进行大量更新,管理层也开了绿灯,允许他们部署首个生产集群。 不断流入的可观测性数据为他们提供了所需的可见性,但又出现了一个问题:数据流致使他们的开发环境发生溢流。他们意识到是时候制定增长计划了。
“坏消息是:基本不可能准确预估工作负载。然而,还有一个好消息,即我们在这一过程中已经知道必须做出改变。所以我们设计了系统架构,以确保能够在无需停机的情况下重新配置公司的系统。”— Mick Miller,KeyBank
精准扩展
随着监测需求的增长,KeyBank 开始通过迭代方法来对 Elasticsearch 监测系统进行改进,从而扩展公司的端到端系统。经过一些微调后,他们的架构现在遵循一些核心原则,这些核心原则能够让他们精准地实施变更,而不会影响到整套系统。其中的每个逻辑层级必须:
- 可独立扩展
- 高度可用
- 有容错功能
幸运的是,这些领域正是 Elasticsearch(以及其水平架构)的强项。 KeyBank 目前端到端的“采集到索引”性能还不到半秒钟,所以如果未能达到 SLA,他们只需扩展规模即可。“这些都是集中存储数据带来的意外惊喜,我们觉得 Elasticsearch 是实现这一结果的出色解决方案。”Miller 说道。
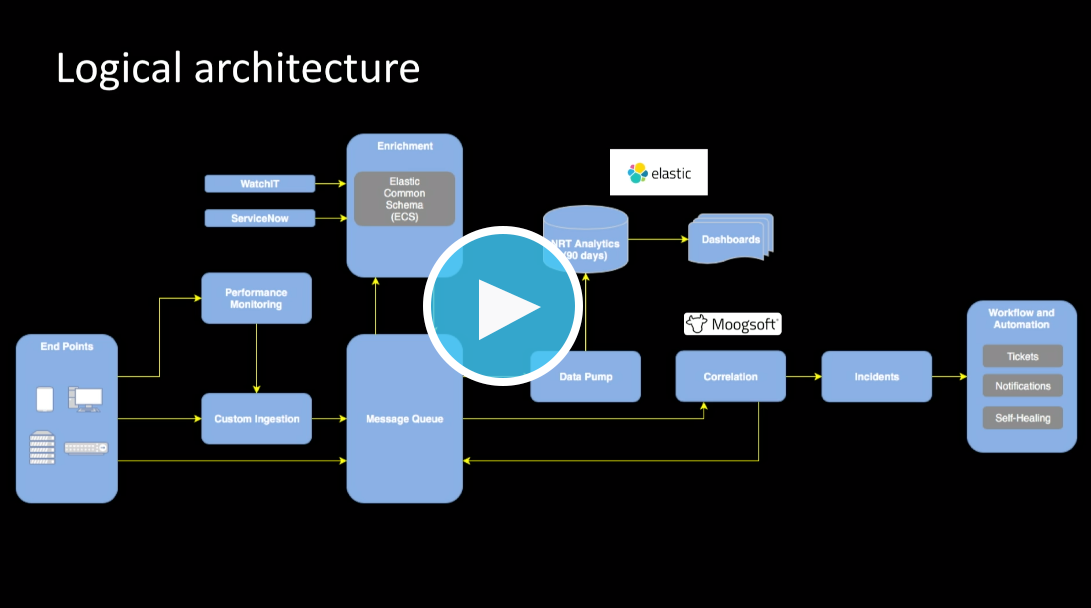
欢迎观看 KeyBank 使用 Elastic 构建企业级监测解决方案的历程(2019 年 Elastic{ON} Tour 芝加哥大会上的演讲),详细了解扩展 Elasticsearch 系统的方法(和时机)。您还会了解到他们是如何实施自动化以及在虚拟化和实体计算资源之间取得平衡的,这些举措为他们节省了 500 多万美元。