借助 Vectorspace AI 数据集和 Canvas 生成阿尔法并加以可视化
摘要
本文讲述了如何使用 Elastic Stack 和 Kibana 中的 Canvas 来创建 Vectorspace 数据集,以便对信息进行可视化并解锁数据的巨大威力和价值。
背景
2002 年在劳伦斯伯克利国家实验室,Vectorspace 基于自然语言理解(NLU,当今亦称作词嵌入)创建了特征向量。他们当时使用特征向量来生成相关性矩阵数据集,从而分析延长寿命相关的基因、乳腺癌以及太空辐射后 DNA 损伤修复之间的隐藏关系。
数据源包括实验室的实验结果、美国国家医学图书馆的科学文献、本体论、受控词表、百科全书、字典以及其他基因研究数据库。
那时,他们还实施了 AutoClass(一个用来对星球进行分类的贝叶斯式分类器),并用其来基于包含基因表达值的数据集对基因组进行分类。通过词嵌入和主题建模对数据集进行扩充后,他们将损失降至了最低,而且结果也更实用。他们那时的目标是在电脑中模仿生物医学研究人员在取得发现成果前的一刻所建立的概念联系。其中有一些工作成果以论文形式得以发表,他们在文中描述了与延长线虫寿命相关的基因之间有哪些隐藏关系。在 2005 年,美国海军的 SPAWAR(空间与海上作战系统中心)部门参与了进来,从而提供了更多资源来将研究扩展至诸如金融市场等领域。
改造数据集
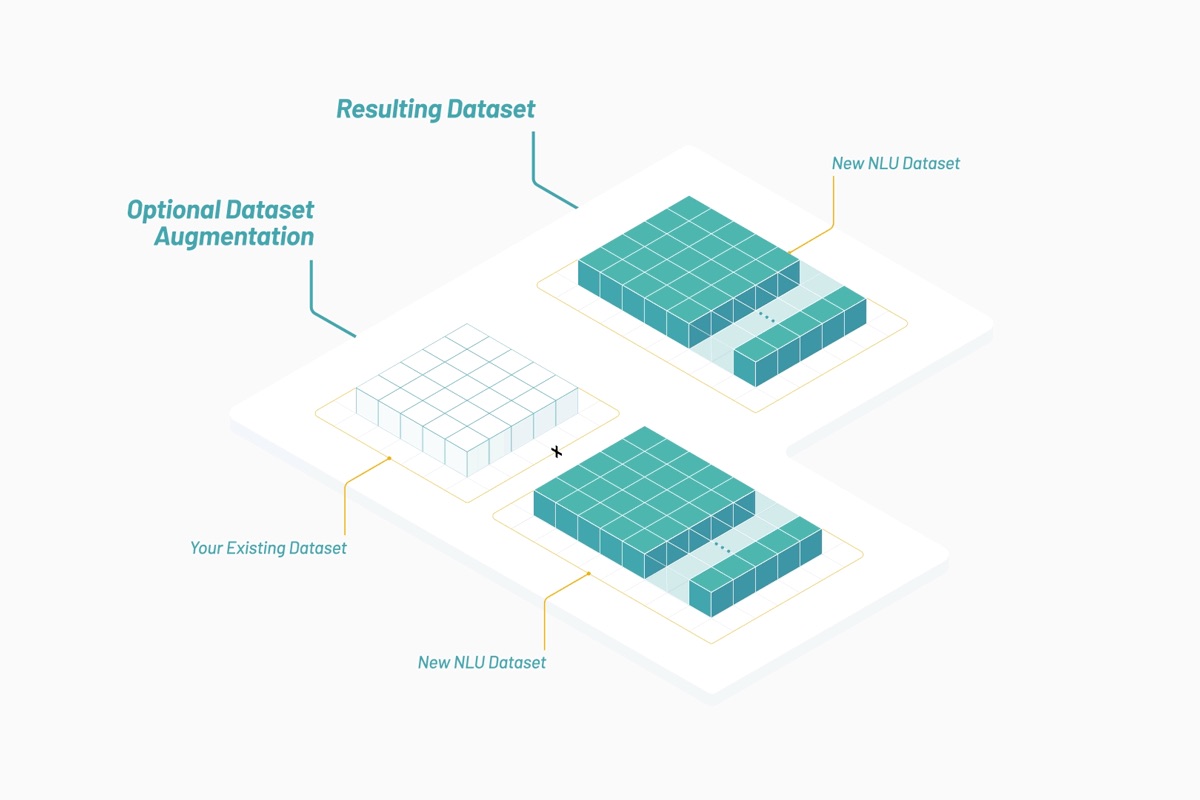
Vectorspace 逐渐学会了通过扩充或合并特征向量(以词嵌入表示)来对数据集进行改造。这样便产生了新的可视化、解读、假设或发现。借助这些类型的特征向量对金融市场的时序数据集进行扩充后,可能会形成独特信号,或者说生成阿尔法。所有一切的出发点都是要拥有已针对选定上下文或主题进行优化的数据源,如下所示:
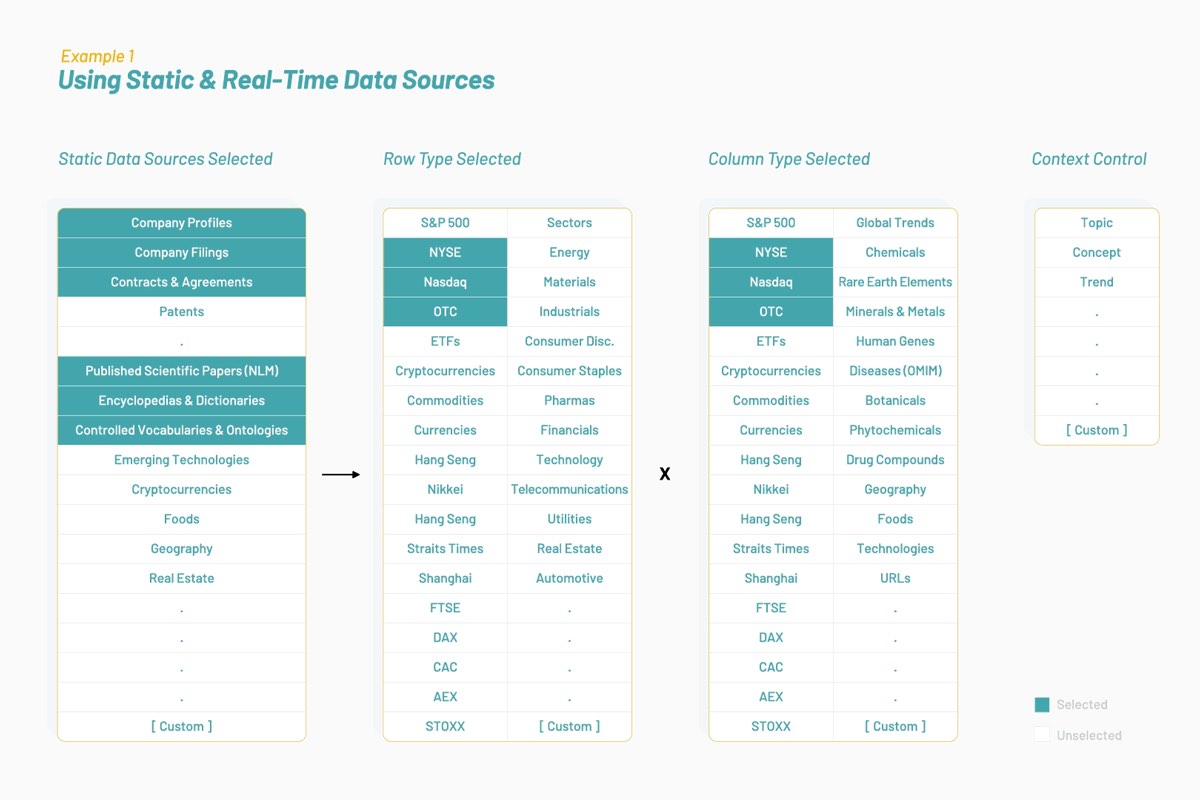
所生成的数据集由特征向量(亦即围绕 NYSE 和纳斯达克的上市公司,基于生物医学文献和人类语言而形成的词嵌入)组成。这是一种跨学科研究方法,旨在确定基因和股票在相互影响的过程中,是否具有相似属性和行为。
确立一个双重目标
第一重:对于已观测到的基因、蛋白质、药物和疾病之间相互影响的相关知识,确定在何处将其应用到股票上。
第二重:通过使用扩充数据集在金融市场中生成阿尔法,探索如何创建一种方法来为更安全地让人类进行长期太空旅行的相关研究提供资金。
上行事件触发行为
所观测到的基因间的相互影响与股票间的相互影响相似吗?2004 年 9 月 20 日发生的一个事件从部分程度上给出了答案。因为默克 (MRK) 的药物 Vioxx(万络)可能会诱发心脏病,公司股价降低了 21%(可能是这个数字)。这一事件触发了其他上市制药公司——尤其是辉瑞 (PFE)——的股价发生潜在同向变化。基于辉瑞与默克所生产药物 Vioxx 之间的关联,Vectorspace 制作的扩充数据集成功预计出辉瑞股价的延时反应。稍后会详细讲解这一点。
进一步研究发现了 The Journal of Finance 杂志 2001 年 2 月版上的一篇有趣论文,名为“Contagious Speculation and a Cure for Cancer: A Non-Event that Made Stock Prices Soar”(传染性投机与癌症治疗药:备受期望但未能实现的一件事推动股价暴涨)。这篇文章描述了一家名为 EntreMed(当时所用股票代码为 ENMD)的公司的事件:
“周日《纽约时报》上有一篇关于新型癌症治疗药物的可能进展的文章,这篇文章使得 EntreMed 的股价从周五收盘时的 12.063 美元暴涨至周一开盘时的 85 美元,周一收盘时的股价接近 52 美金。在随后三周内,其收盘价都高于 30 美元。这一热情也蔓延到了其他生物技术股票。然而,早在五个多月之前,《科学》杂志,以及包括《泰晤士报》在内的诸多大众报纸都报道了癌症研究领域这一可能的重大突破。因此,尽管媒体并未提供真正意义上的新信息,公众的热情关注还是引发了股价的长期上涨。” 在研究人员得出的诸多深入观察结果中,有一条结论十分引人注目:“[股价]变化主要集中在一些具有共同点的股票上,但这些不一定是经济基本面。”—(Huberman 和 Regev 387)
由于团队之前在量化算法开发、投资理财和运营上市公司等相关领域拥有经验,他们开始观测基因和股票之间的相似性。和基因一样,股票也有“表达值”和属性,而且彼此之间以及与外部事件、话题或全球趋势之间也有隐藏关系。作为知识的一种形式,这些关系会比其他任何内容都更深入地嵌入到人类语言中。和基因一样,股票集群也会相互影响,并随着其他股票的变化而变化。基于“潜在的交织关系”,这一数据可用来预计未来股价之间的相关性。股票集群还可以兼作“篮子”,篮子中的股票彼此之间以及与外部事件之间会有一些已知和隐藏的共通关系。集群或篮子可以通过上下文进行控制。
涨潮时不一定所有船只都会浮起
Vectorspace 发现基于“可挖掘的信息储存”,可以利用金融市场的低效性来抓住机会创建集资途径,所以他们开始分析是什么导致了他们发现的相关性。他们开始观测股票间的延迟反应,有点像外海涨潮之后的几分钟或几个小时内,港口或海湾里面的海水会增加并将船只浮起。港口内的水位升高可能由一个事件引起,而且这一事件之后还会将港口内的船只浮起,在这个示例中,可以将船只看做可交易资产(例如股票)的集群。在金融市场中,一些船只会浮起,另外一些则不会。通过预测哪些资产与某一事件有相关性,以及预测此相关性的强度和上下文,可以提供重要信号。这就像拥有一种不对称信息,借助这些信息用户在部署做多或做空资本时,能够领先市场或降低风险。这也可以称为“生成阿尔法”,用户可以对这里的阿尔法进行可视化和解读。
为了验证这一概率性的船只浮起假设,他们分析了 20 年的数据来查找在市场中发生事件时上市公司股价之间同向变化或潜在交织关系的规律。他们发现了很多示例,其中就包括下面三个事件:EntreMed (ENMD) 1998,默克 (MRK) 2004,和塞尔基因 (CELG) 2019。
事件 1:EntreMed (ENMD) 股价暴涨 608%(1998 年 5 月 4 日)
EntreMed 在周五收盘后发布新闻说其研发出了一种抗癌药。其股价在周五收盘时为 12 美元,周一开盘时股价高达 85 美元。随后,与 ENMD 有关的一篮子股票也开始涨价,这里的相关是指按照人类语言均属于与癌症疗法相关的蛋白质科学。
描述这一事件的文章中包括下列相关节选:
第 392 页第 4 段“这些公司中,有三家的回报率超过 100%,有两家介于 50% 到 100% 之间,还有另外两家的回报率介于 25% 到 50% 之间。将这些回报率与表 I 中所报告的极端回报分布相比,可以看出这七家生物技术股票的回报率有多么不同寻常,尤其需要注意的是,他们的集群性质可谓前所未有。”
第 395 页第 1 段“有关癌症治疗突破的这条新闻不仅影响了对这一开发拥有直接商业化权益的公司的股价,这并不奇怪;市场可能意识到了可能的溢出效应,并进而推测其他公司可能从这一创新中受益。”
第 396 页第 3 段“变化主要集中在一些具有共同点的股票上,但这些不一定是经济基本面”
事件 2:默克 (MRK) 股价暴跌 25.8% (2004 年 9 月 30 日)
年销售额达 25 亿美元的药物 Vioxx 由于含有会引发心脏病的 COX-2 抑制剂,默克公司从市场上撤回此药。这一相关性有一个起因。MRK 前一天的收盘价为 45.07 美元,而 9 月 30 日的开盘价为 33.40 美元。在使用兼作为特征向量的词嵌入进行实验的过程中,他们发现基于相似的特征向量辉瑞 (PFE) 是与默克最密切相关的公司,因为这两家公司当时都在研发类似的基于 COX-2 抑制剂的药物化合物。几周后,PFE 的股价也大幅下跌。
“在 2004 年 12 月 17 日,辉瑞和美国国家癌症研究所宣布他们在研究针对大肠息肉疗效的长期临床试验中停止施用西乐葆(塞来昔布),因为这一药物会增加罹患心脑血管疾病的风险;西乐葆是一种环氧化酶 2 (COX-2) 抑制剂。默克的罗非昔布 (Vioxx) 是另一种 COX-2 抑制剂,这一药物由于会增加罹患心肌梗塞和中风的风险于 2004 年 9 月从全球市场撤回。”- CMAJ。
PFE 的股价暴跌 24%,从前一天收盘时的 28.98 美元跌至当天 21.99 美元的低点。
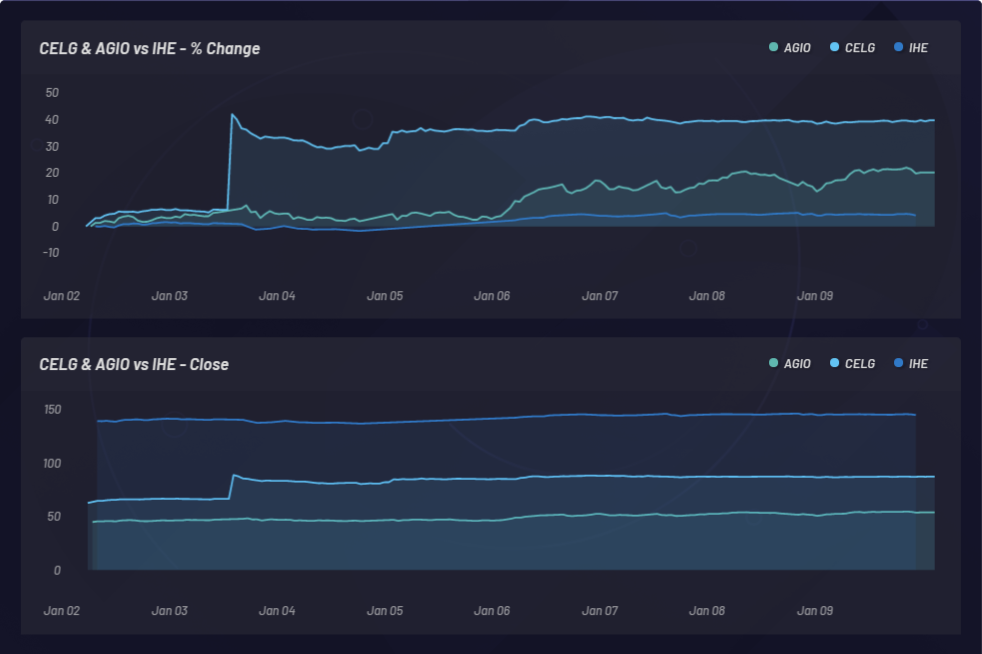
事件 3:塞尔基因 (CELG) 暴涨 31.8%(2019 年 1 月 3 日)
2019 年 1 月 3 日,百时美施贵宝 (BMY) 斥资 740 亿美元收购了 塞尔基因 (CELG)。CELG 的股价一夜从每股 66.64 美元暴涨至 87.86 美元,涨幅高达 31.8%。在四天期间内,与 CELG 相关的一篮子股票(因为发现基于人类语言这些公司存在一定关系)产生了 20% 的利润。帮助将这些实体联系起来的数据源包括上市公司资料库,以及由同行评议的已发表科学文献。
在 Vectorspace 对这一过程的分析中,他们发现某些 NLU 相关性可以在股票间以及股票与事件之间引发潜在的股价相关性。该团队观测了很多诸如上面的示例,这些示例均可用来在市场上占据领先地位或者参与信息套利之类的活动。
对阿尔法进行可视化
当今在 Vectorspace AI,他们会设计数据集以监测生命科学领域内基因、蛋白质、微生物、药物和疾病相互之间影响的隐藏关系网络,或者金融市场中股票间的隐藏关系网络。大多数时候,我们的客户会使用这些数据集来扩充他们既有的专有数据集。这些数据集是通过将特征向量整合在一起来生成的,这些特征向量包括基于词语和对象矢量化而得出的已计分属性。数据集会以近实时的速度进行更新,并且可以使用实用型令牌积分通过 API 予以访问。
通过利用 Elastic Stack 和 Canvas,Vectorspace 能够以可完全定制的白标视图形式为用户提供近实时的可视化和解读。这对整体流程来说至关重要,因为新的解读和洞见能够引发新的假设、信号或发现。
很常见的一种情况是,资产管理公司和机构出于隐私考虑,会请求在本地部署数据工程管道解决方案。通过使用 Elastic Cloud Enterprise,我们可将数据工程管道打包到一起,这能够让我们提供一站式的信号生成解决方案。
Vectorspace 金融市场客户的目的是优化信噪比,改善阿尔法的生成过程,将损失函数降至最低,或者最大化夏普或索提诺比率。他们通过下面两点实现这些目的:通过回测策略基于近实时扩充的数据集对结果进行可视化和解读;同时还要避免回测过拟合。
数据集更新频率从一分钟到一个月不等,具体取决于底层数据源的波动性。请求比较多的一个数据集包由一个时序定价数据集组成,其中行包括通过特征向量(具有 NLU 相关性分数的药物化合物)进行扩充的上市制药公司。选择运行所处的上下文至关重要。正如上下文可以改变一个词的定义一样,从长期来看,添加正确的上下文限制可以引导相关性分数值发生变化。上下文还可以控制实体之间以及实体与事件之间关系的强度。
使用 Canvas 进行可视化
让我们深入了解并使用其中一个数据集来生成和可视化与塞尔基因 (CELG) 相关的一篮子股票,以及触发其中部分股票延迟涨价的事件。我们将会逐步讲解 Vectorspace 客户使用这些数据集以及在 Canvas 中解读近实时结果和回测结果时通常完成的步骤。首先,客户会看一下整个篮子群组中最底行的结果,以确认塞尔基因篮子不是挑选出来的。
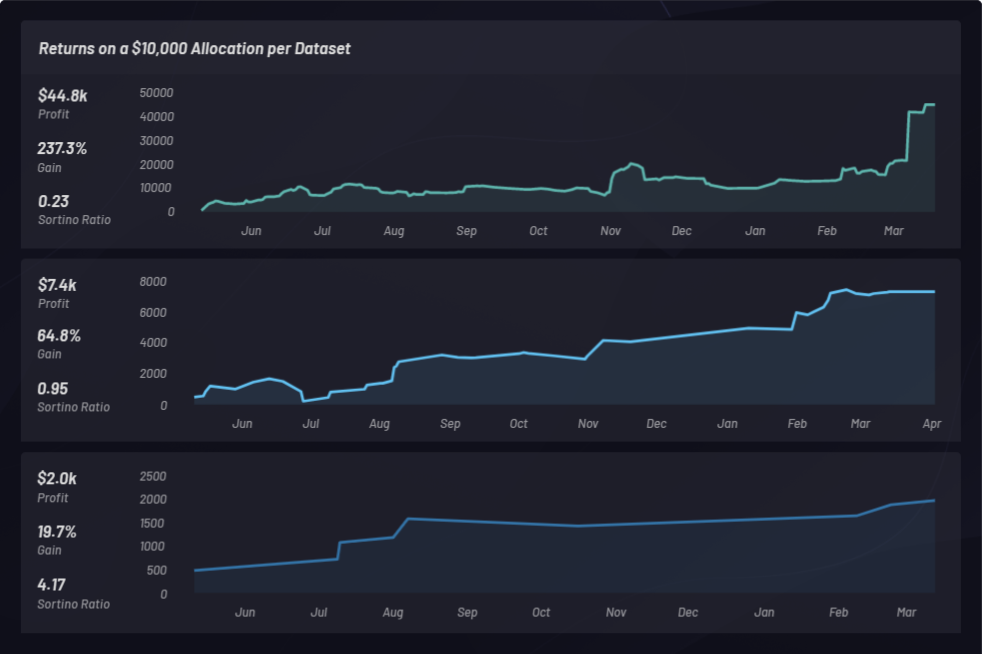
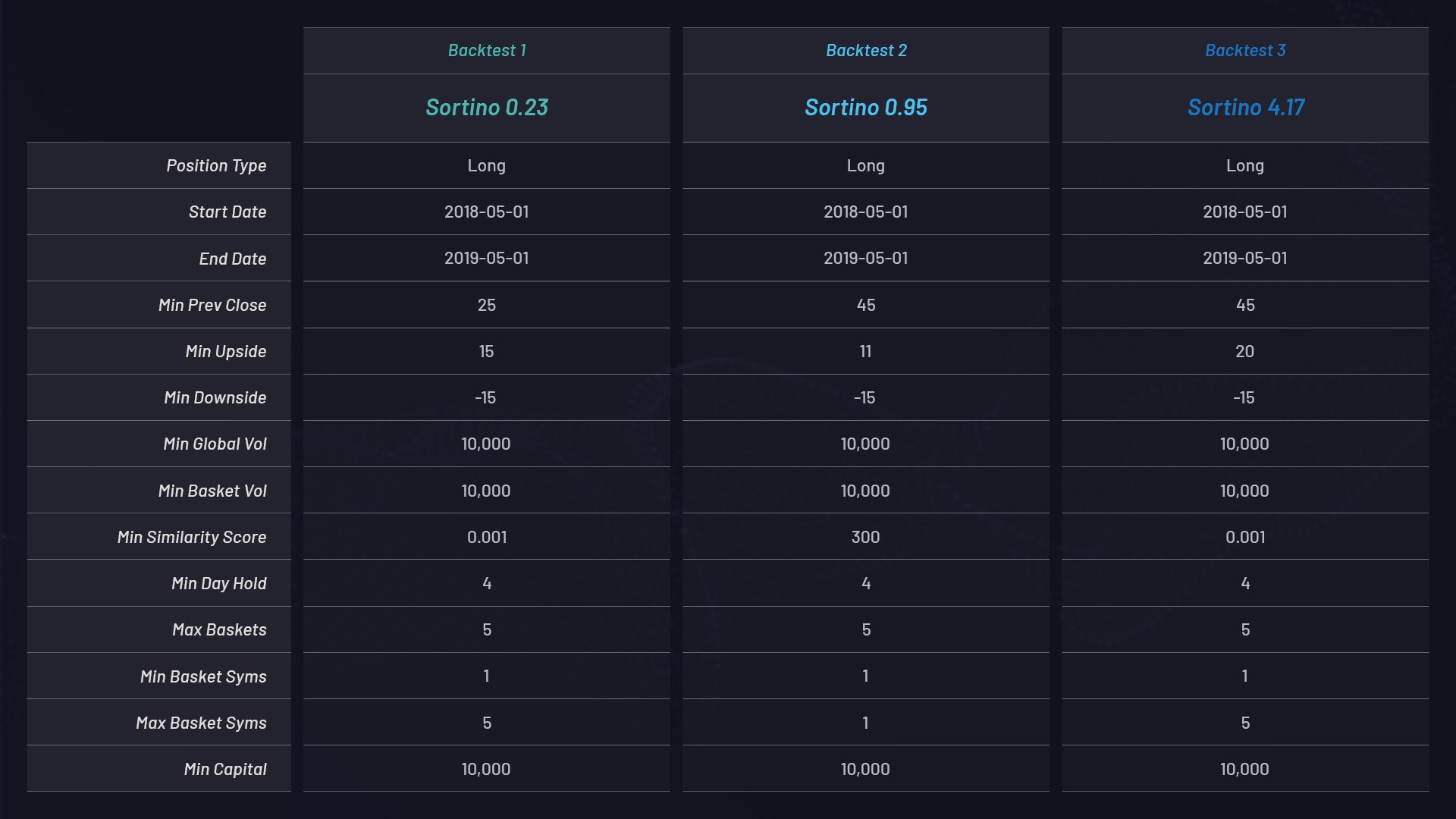
下面是使用具有不同参数设置的纯做多篮子完成的三个单独回测。每个都分配了 10,000 美元的资本,并且按照索提诺比率进行排序:
每个篮子的参数设置:
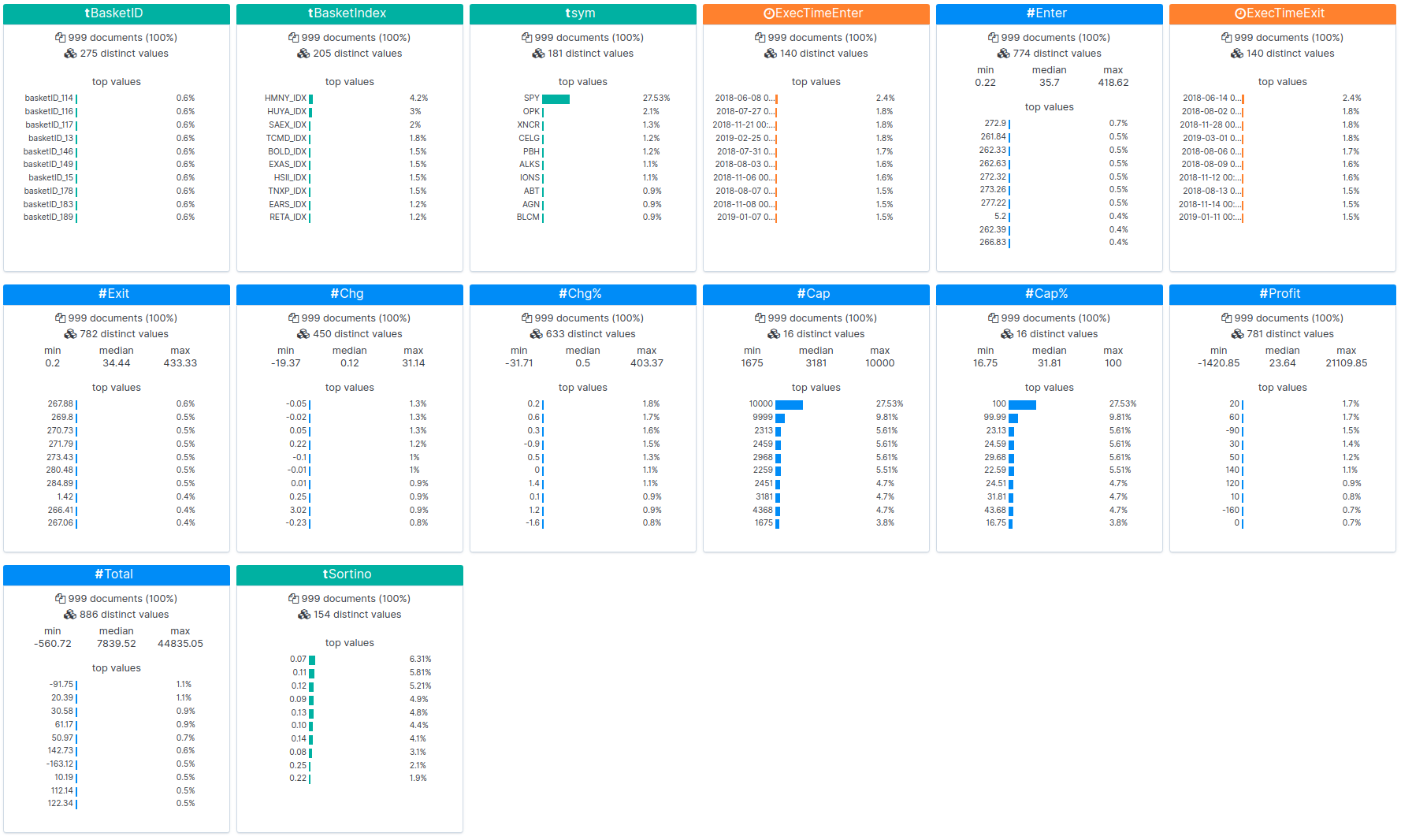
下图中,回测结果已加载到 Kibana 中,并且展示出了统计数据:
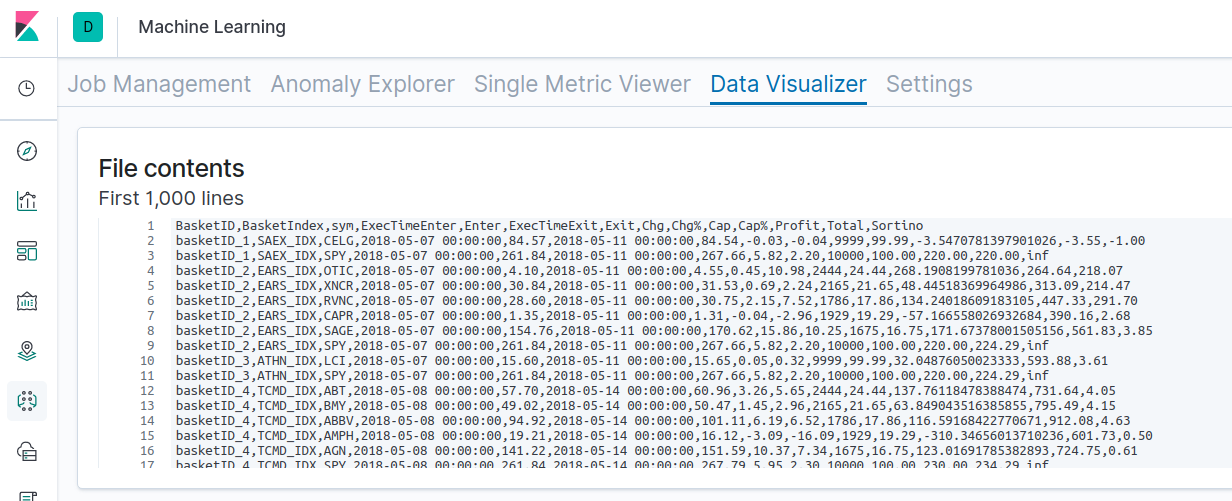
您可以在这里查看其中一次回测的原始结果。可通过下列步骤对已扩充的 NLU 数据集完成回测。我们正是通过这些步骤生成了上面的结果。
- 使用数据集 API 针对 NYSE 和纳斯达克的所有股票生成兼作为特征向量的词嵌入。
- 使用 2018 年 5 月 1 日至 2019 年 5 月 1 日(为期一年)NYSE 和纳斯达克所有股票的历史价格数据来扫描特殊事件触发行为(以股价暴涨进行定义)。
- 只要股价增幅超过所选的百分比阈值(例如 +15%),就会使用此数据集生成一个相关股票的集群或篮子。查看上表中的 MIN_UPSIDE 参数。
- 然后会使用诸如数量、市场上限、浮动情况等筛选参数对篮子进行精细调整。
- 交易的进入和退出时间设置为四天持有期。
- 计算做多和做空篮子的收益,而且在索提诺比率之外,还会计算标准普尔 500 以进行基线比较。
- 通过 Canvas 对数据集和回报率进行监测、可视化和解读。
对回报率进行回测
我们看一下使用 Canvas 完成的三个一年期(从 2018 年 5 月 1 日至 2019 年 5 月 1 日)回测的整体结果,比较基础是此期间生成的所有篮子的表现。
回测会启用功能以检测出在塞尔基因收购完成后股价上升的上市公司。会加载已扩充数据集,并从中观测相关性。数据集生成的篮子(集群)也可以按照它们的表现进行查看。可以将篮子与标准普尔 500 的基线表现进行对比,以确保您至少跑赢大盘。还会监测各个篮子以确定它们的表现是否优于标准普尔 500 (SPY):
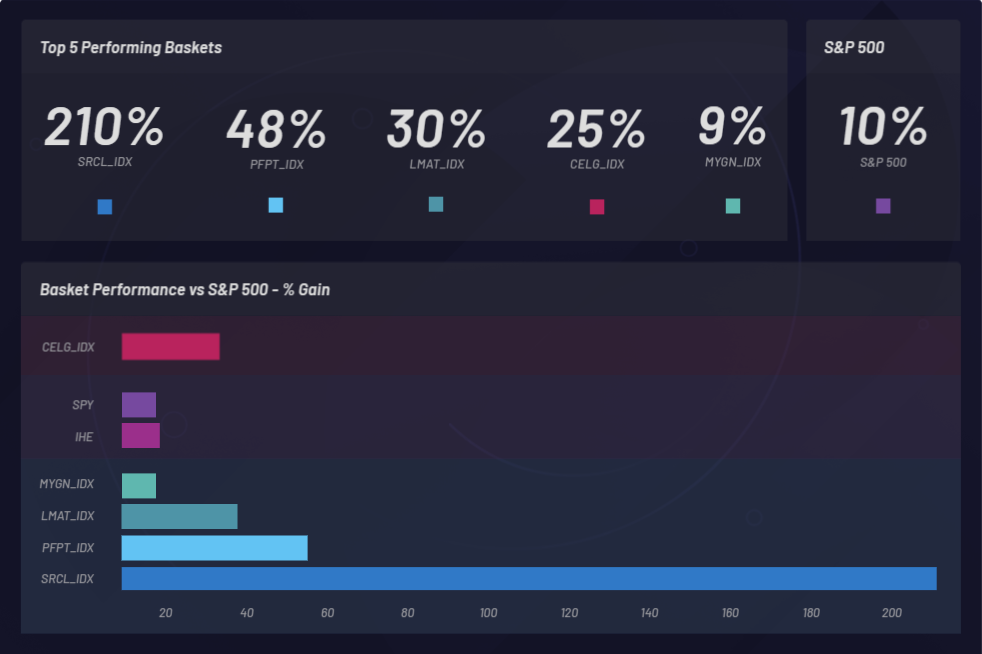
下图显示了事件的监测过程以及在其他股票中造成的潜在同向变化。在这个例子中,CELG (Celgene) 是事件,而 EPZM (Epizyme) 则被挑选出来作为所产生篮子中的成分。NLU 相关性可以预测价格相关性。通过采集股票与事件之间不断更新的 NLU 相关性,可以基于不对称信息套利获得竞争优势。只有价格变化或价格相关性相对于 CELG 和 EPZM 之间的任何 NLU 相关性(从下面可以观测出来)有延迟响应的时候,您才能够领先市场:
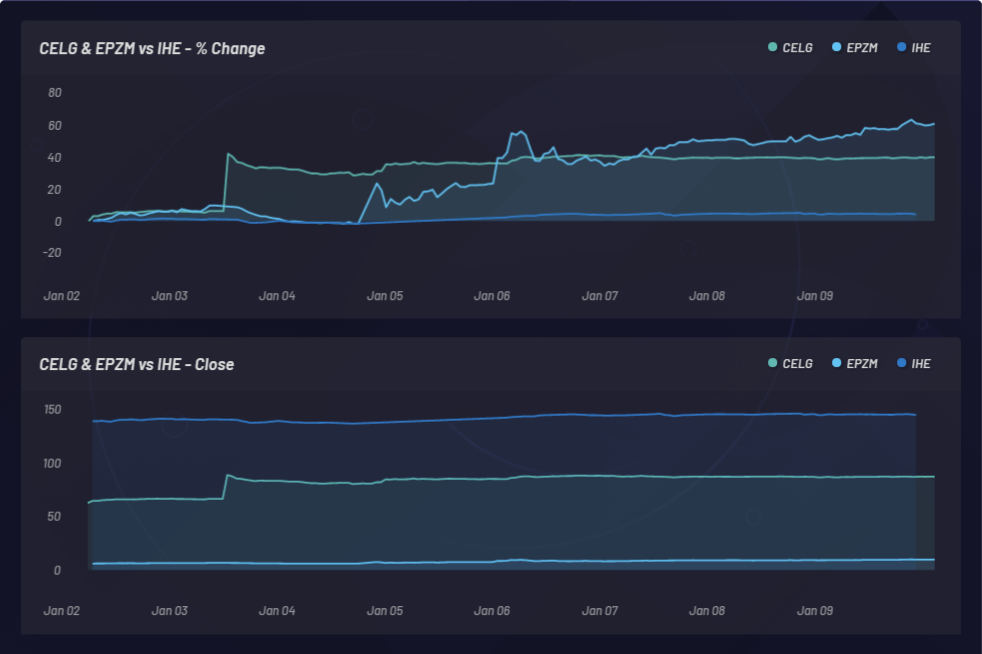
CELG(塞尔基因)与 AGIO (Agios Pharmaceuticals) 表现的比较:
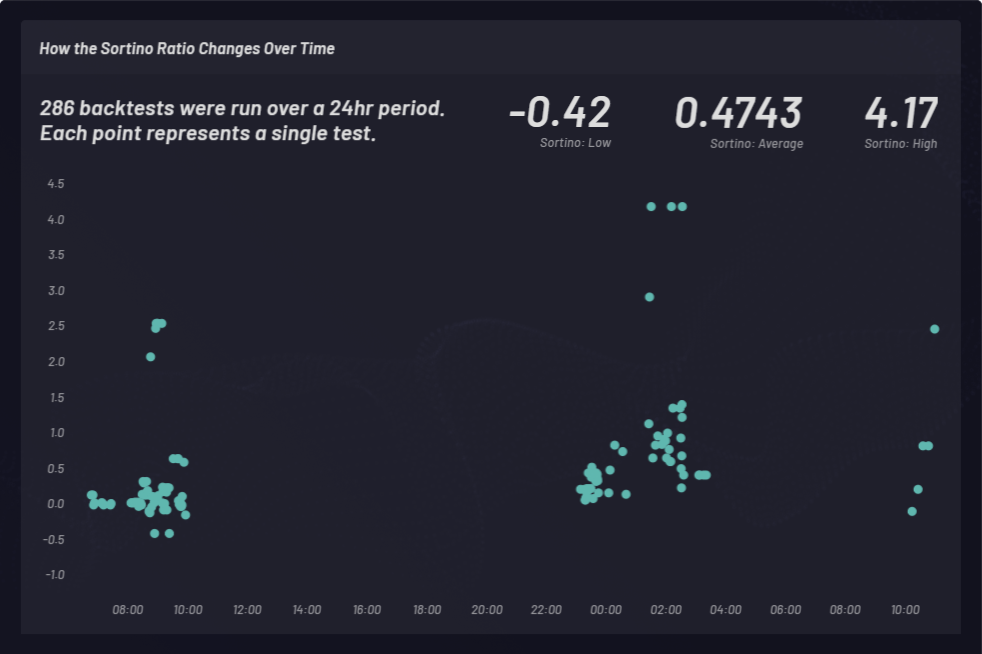
我们计算索提诺比率来衡量风险调整后的收益。在下面的示例中,我们选择了索提诺比率,而非夏普比率,以便将上行不稳定性作为良好因素予以考量。索提诺比率会随时间变化。在 24 小时期间内的三个不同时间点针对三个做多篮子进行了回测。采用不同的全局参数设置共计进行了 286 次回测。下面集群中的每个点都代表一次回测,其中 Y 轴表示相应的索提诺比率:
利用不断变化的相关性
美国国家医学图书馆 (NLM) 每 24 小时会发表大约 1,500 份由同行评议的科学论文。Vectorspace 使用 NLM 作为其数据源之一。

基因、药物化合物、制药行业新闻和上市公司之间的相关性会随着时间而改变,有时短短数秒内就会变化。在查找老药新用的备选化合物时,这能够影响信噪比。
如果上市制药公司与基因、蛋白质、药物化合物、微生物或疾病之间的相关性数值发生变化,这些新关系会反映在数据集中,并且可以使用 Canvas 近实时地进行监测。

在创建基于 NLU 的数据集的过程中,使用上下文控制可以生成新类型的相关性评分。控制 NLU 关系的上下文对于获得新见解至关重要。
通过添加上下文控制,基于 NLU 的数据集可以协助研究人员回答诸如下面的问题“基于最新研究,在 DNA 损伤修复基因的上下文中,哪些制药股票与这些药物化合物具有相关性?”,同时还能在 Canvas 中提供强大方法来对回答/结果进行可视化和解读。
由于每 24 个小时会发表大约 1,500 份由同行评议的科学论文,同时还有新闻其他公共存档,所以相关性分数会变化,这相应地会确定并更新上市制药公司和药物化合物之间的关系。如与公司的专有数据进行整合,基于 NLU 的数据集能够提供独特信号。
结论
基于自然语言处理 (NLP) 和 NLU 的相关性为生成新见解、假设或发现提供了新方法。
在上下文相关性、备选数据源、特征向量、可视化和解读方面,您还可以使用 NLU 数据集在生命科学和金融市场领域完成更多事情。将来我们的团队可能还会讨论其中一些主题,包括针对各种可交易资产扩充时序型数据集。通过使用单独的 NLU 特征向量,我们的团队能够解释如何构建基于图形的关系网或者完整的集群网(使用 Canvas 和 Elastic Stack 中的其他工具制作)。此外,我们的团队还可描述通过什么方法来让设备基于实用性令牌 API 和公开市场交易委托账本在特征向量之间完成交易,从而将所选的损失函数降至最小。
Vectorspace 在分析与 LET 辐射(太空辐射)相关的染色体损伤修复、实验胚胎学以及太空旅行对人类寿命影响的过程中,继续为数据集构建相关应用程序。通过使用 Elastic Stack(包括 Canvas 和其他工具),所有这些都变得更加富有创意,更加实用。如果您希望详细了解如何扩充数据集或者如何获得免费的实用性令牌 API 积分,欢迎联系 Vectorspace,我们将十分乐意为您提供必要数据,让您轻松入门。
而且,如果您想试用 Elastic Stack,欢迎免费试用 14 天的 Elasticsearch Service,或者您也可以将其作为默认分发包的一部分下载下来。
Vectorspace 创建系统和数据集来模仿人类的认知以用于信息套现和科学发现目的(高级 AI/NLP/ML),公司的客户包括 Genentech、劳伦斯伯克利国家实验室、美国能源部 (DOE)、美国国防部 (DOD)、NASA 的太空生物科学部门、DARPA、SPAWAR(美国海军的空间与海上作战系统中心),等等。
Shaun McGough 是 Elastic 的产品经理,在数据可视化和另类投资领域拥有丰富经验。