基于父子进程关系来检测异常模式
在检测基于文件的攻击方面,杀毒检测和基于机器学习的恶意软件检测的效果已经提升,因此敌手开始转而使用“离地攻击”技巧来避开现代安全软件。该技巧涉及执行操作系统上预安装的的系统工具,或者涉及执行管理员为完成某些任务(例如自动完成 IT 部门的行政管理型任务,定期运行脚本,在远程系统上执行代码,等等)而通常引入的系统工具。如果攻击者使用受信任的 OS 工具(例如 powershell.exe、wmic.exe 或 schtasks.exe),则他们会很难被发现。由于这些二进制文件本来是良性的,而且广泛应用于大部分环境中,所以攻击者大部分时间可以不动声色地避开第一道防线,他们只需与定期执行的噪音内容夹杂在一起就能蒙混过关。在发生安全事件后检测诸如此类的模式时,用户需要筛查数百万个事件,没有清晰的着手点。
为了予以应对,安全研究人员开始打造检测工具来定位可疑的父子进程链。通过将 MITRE ATT&CK™ 作为 playbook,研究人员可以编写检测逻辑,从而在父程序使用特定命令行参数来启动子进程时发送告警。这里有一个很好的例子:针对包含 base64 编码参数的 MS Office 子进程 powershell.exe 发出告警。然而,这一过程十分耗时,不仅需要领域的专业知识,还需要明确的反馈回路以对充满噪音的检测工具进行调整。
安全人员已经开发了多个开源的红蓝框架来模拟攻击并评价检测工具的表现——但是无论检测工具的效果多好,它的逻辑都只能解决某一特定攻击。检测工具不能进行泛化,也无法检测新发攻击,这为机器学习提供了一个独特契机。
从图形出发思考问题
刚开始考虑如何检测异常的父子进程时,我便立即想到可将它转变为一个图形问题。毕竟,对给定主机而言,进程的执行过程能够用图形来表示。我们图形中的节点将会是按进程 ID (PID) 分解而成的单独进程,而连接节点的每条线则代表一个 process_creation 事件。给定连线中将会包括从事件中获取的重要元数据,例如时间戳、命令行参数以及用户。
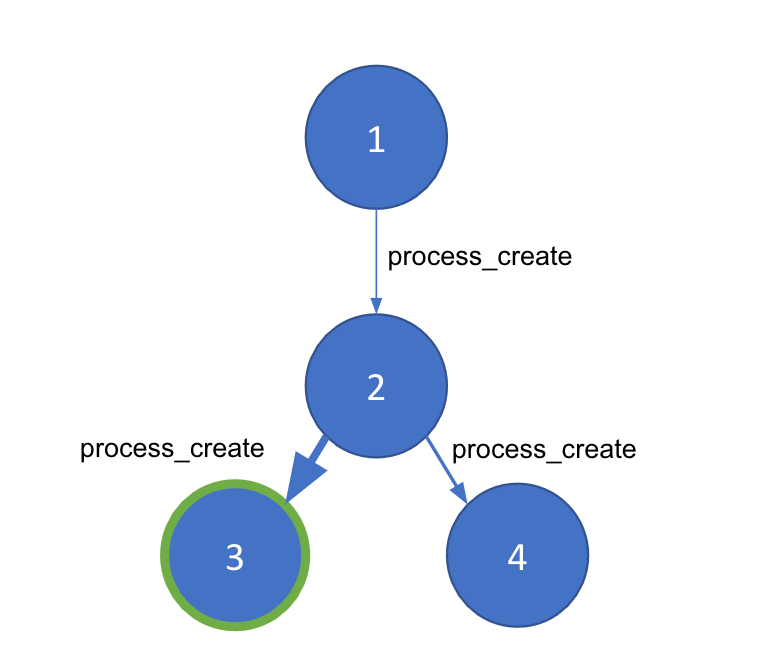
现在我们有了主机进程事件的图形表现形式。然而,“离地攻击”可以从一直执行的同一系统级进程中启动新进程。我们需要找到一种方法来在特定图形中将好的和坏的进程链区别开来。社区检测技巧指基于节点间线条的密度将大的图形细分为较小的“社区”。要使用这种方法,我们需要找到一种方法来为节点间的连线生成权重,从而确保社区检测方法能够正确运行并找到图形中的异常部分。对此,我们需要求助于机器学习。
机器学习
为了生成连线权重模型,我们需要使用监督式学习,这种机器学习方法会将带标签的数据输入到模型中。幸运的是,我们可以使用上面提到的开源红蓝框架来帮助生成一些训练数据。下面便是我们在训练语料库中所使用的的几个开源红蓝框架:
红队框架
- Atomic Red Team (Red Canary)
- Red Team Automation (Endgame/Elastic)
- Caldera Adversary Emulation (MITRE)
- Metta (Uber)
蓝队框架
- Atomic Blue (Endgame/Elastic)
- Cyber Analytics Repository (MITRE)
- MSFT ATP Queries (Microsoft)
数据采集和标准化

采集了一些事件数据之后,我们需要将它们转换为数字表现形式(图 2)。借助这一表现形式,此模型能够学习到有关攻击范围内父子进程关系的更广泛详情,这有助于避免单纯地学习签名。
首先,我们对进程名称和命令行参数执行特征工程(图 3)。TF-IDF 矢量化过程将在我们的整个数据集中采集特定词汇对于某一事件的统计显著性。通过将时间戳转换为整数,我们能够确定父进程开始时间和子进程启动时间之间的差值。其他特征本质上均为二进制(1 或 0,是或否)。下面便是这一特征类型的几个很好示例:
- 此进程已签署了吗?
- 我们信任签署人吗?
- 此进程被提升了吗?

数据集的转换工作完成之后,我们将要用它来训练一个监督式学习模型(图 4)。这一模型的目的是为特定的进程创建事件提供一个介于 0(良性)和 1(异常)之间的“异常分数”。我们在图形中可以将这个异常分数作为连线的权重!
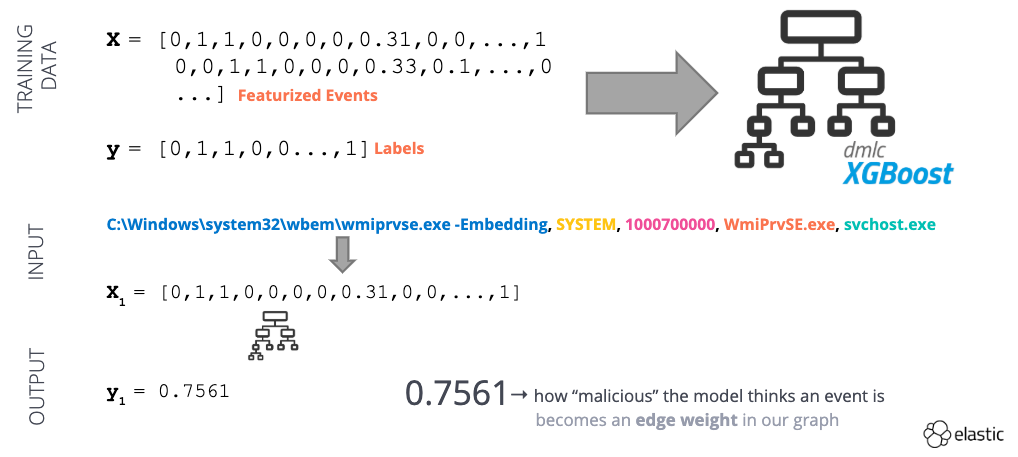
图 4 - 监督式机器学习工作流示例
强度服务


图 5 - 强度引擎所使用的的条件概率
现在,在机器学习模型的帮助下,我们有了权重图形。任务已完成,对吧?我们所训练的模型能够基于我们对好坏的整体理解,针对特定的父子进程链很好地确定进程的好坏。但是每个客户的环境都不相同。肯定会有一些我们之前从未观测到的进程,而且肯定有系统管理员喜欢使用 PowerShell 来处理所有事务。
基本可以确定一点,如果单独使用该模型,我们会看到海量的假阳性信息,而且分析师需要筛查的数据量也会增加。为了弥补这一潜在问题,我们开发了一套强度服务,这一服务能够告诉我们特定父子进程链在所属环境中的普遍程度。通过考虑本地环境的细微不同,我们能够更加自信地提升或压制可疑事件,并找出真正异常的进程链。
强度服务(图 5)依赖的是从条件概率中获得的两个统计数据,借助这两个统计数据我们便可声明:“从该父进程中,我看到这一子进程比其他子进程要多 X%”,并且“从该进程中,我看到此命令行比与这一进程相关的其他命令行要多 X%。” 强度服务确立之后,我们便可以对核心检测逻辑——find_bad_communities——进行最后的处理了。
寻找“坏”社区

图 6 - 用来发现异常社区的 Python 代码
从上面的图 6 中,我们可以看到用来生成坏社区的 Python 代码。find_bad_communities 的逻辑十分简单直接:
- 将主机的每个 process_create 事件进行分类,以生成一个节点对(例如父节点和子节点)和相关的权重(例如我们模型的输出内容)
- 构建一个带箭头的图形
- 开展社区检测以在图形中生成一个社区列表。
- 在每个社区中,我们都要确定某个父子进程链(也就是每条连线)的强度如何。在最后的 anomalous_score 中,我们会考虑父子进程事件的常见程度。
- 如果 anomalous_score 达到或超过阈值,我们会将整个社区隔离开来,让分析师进行审查
- 对每个社区进行分析之后,我们会返回一个“恶意”社区列表,此列表按 anomalous_score 的最大值进行排序
结果
我们综合使用真实和模拟的良性及恶意数据对最终模型进行了训练。良性数据包括从我们内部网络上采集的 3 天的 Windows 进程事件数据。此数据的来源同时包括用户工作站和服务器,旨在再现小型公司的环境。我们通过下列两种方法来生成恶意数据:引爆 Endgame RTA 框架所提供的全部 ATT&CK 技巧,以及启动来自高级敌手(例如 FIN7 和 Emotet)的基于宏和二进制文件的恶意软件。
对于我们的主实验,我们决定使用来自 MITRE ATT&CK 评估的事件数据,此数据由 Roberto Rodriguez 的 Mordor 项目提供。“ATT&CK 评估”旨在使用 FOSS/COTS 工具(例如 PSEmpire 和 CobaltStrike)来模拟 APT3 活动。这些工具可以允许“离地攻击”技巧链接在一起,从而完成“命令执行”、“持久化”或“绕过防御”任务。
通过使用专有的进程创建事件,此框架能够识别数个多技巧攻击链。借助“发现”(图 7)和“内网漫游”(图 8),我们发现并高亮显示了一些内容以供分析师审查。

图 7 - 进程链执行“发现”技巧

图 8 - 进程链执行内网漫游
数据削减
我们的方法还有一个额外好处,它不仅能够发现异常进程链,而且还能够展示强度引擎在降低假阳性方面的价值。综合来看,我们得以大幅减少需要分析师审查的事件数据的数量。下面是一些统计数字:
- 在 APT3 情景中,我们针对每个终端记录了约 1 万条进程创建事件(共 5 个终端)。
- 我们在每个终端上发现了约 6 个异常社区。
- 每个社区由约 6-8 个事件组成。
展望未来
我们目前正在将这一研究方法从概念验证向集成解决方案(作为 Elastic 安全中的一项功能)推进。最让人看好的功能是“强度引擎”。虽然可高亮显示文件发生频率的强度引擎很常见,但是如果其可以描述事件间关系的强度(通过查看企业中的罕见/常见信息,并最终通过衡量全球范围内罕见的事件来加以强化),那么它就可以帮助安全专业人士通过新方法来检测威胁。
结论
我们去年在 VirusBulletin 和 CAMLIS 上展示了这一基于图形的框架(称为 ProblemChild),目标是减少检测工具编写流程所需的领域专业知识。通过应用监督式机器学习来获取权重式图形,我们展示了其能够识别符合下列特征的社区:社区中看似不同的事件构成了较大的攻击序列。我们的框架会应用条件概率来自动对异常社区进行排名,同时还会压制发生频率高的父子进程链。当用来实现这两个目标时,分析师可以使用这一框架来帮助制定或调整检测工具,以及减少一段时间内的假阳性。