为 Elastic APM Java 代理贡献插件指南
理想情况下,APM 代理会自动装载和跟踪已知存在的任何框架和库。实际上,APM 代理支持的技术和框架反映了我们的产能和优先级安排。我们会根据广大尊贵用户的反馈意见,不断按照优先级来扩展我们支持的技术和框架列表。尽管如此,如果您正在使用 Elastic APM Java 代理并且漏掉了现有功能不支持的一些内容,那么有几种方法可以进行跟踪。
例如,您可以使用我们的公共 API 跟踪您自己的代码,也可以使用我们很棒的自定义方法跟踪配置对第三方库中的特定方法进行基本监测。但是,如果您希望基于第三方代码扩展对特定数据的可见性,则可能需要执行更多操作。幸运的是,我们的代理是开源的,您可以做我们能做的一切。既然有所研究,何不与社区成员分享一下呢?这样做的一大好处是能够获得更广泛的反馈,并让您的代码在其他环境中运行。
我们非常欢迎大家积极参与来扩展我们的功能,只要您贡献的内容能够像客户对我们期望的那样,达到我们必须执行的几个标准即可。例如,请查看用于支持 OkHttp 客户端调用的此项 PR 或用于扩展我们对 JAX-RS 支持的此项 PR。因此,要想为代码库贡献内容,请在动手开始编码之前注意以下事项;这里还提供了一个测试用例,以帮助您理解此插件实施指南。
测试用例:装载 Elasticsearch Java REST 客户端
在发布代理之前,我们希望支持我们自己的数据存储客户端。我们希望 Elasticsearch Java REST 客户端用户知道:
- 发生了对 Elasticsearch 的查询
- 这个查询花费的时间
- 哪个 Elasticsearch 节点响应了该查询请求
- 有关查询结果的一些信息,如状态代码
- 发生错误的时间
_search操作查询本身
此外,我们还决定第一步只支持同步查询,并在我们部署适当的基础架构之后,再考虑支持异步查询。
我提取了相关代码,将其上传到了 Gist,并会在整个帖子中引用。请注意,虽然这不是在 GitHub 存储库中可找到的实际代码,但它十分实用和贴切。
Java 代理的特定方面
编写 Java 代理代码时,需要注意一些特殊事项。我们先简单介绍一下测试用例,然后再查看。
字节码装载
不用担心,您不需要在字节码中编写任何内容,我们用神奇的 Byte Buddy 库(它反过来依赖 ASM)代劳。例如,我们使用注释来说明在已装载方法的开头和末尾注入的代码。您只需要记住,您编写的某些代码实际上并不会在您编写代码的位置执行,而是将编译后的字节码注入其他人的代码中(这是开放性的一大好处 — 您可以确切地看到正在注入的代码)。

类的可见性
这可能是最难以解释的因素,也是隐藏陷阱最多的地方。我们需要非常清楚地了解代码的每个部分将从哪里加载,以及在运行时可以假设哪部分代码可用。添加插件时,您的代码将被加载到至少两个不同的位置:一个是在已装载库/应用程序的上下文中,另一个在核心代理代码的上下文中。例如,我们依赖于 HttpEntity,这是随 Elasticsearch 客户端一起提供的一个 Apache HTTP 客户端类。由于此代码被注入到客户端的一个类中,因此我们知道这个依赖关系是有效的。另一方面,使用 IOUtils(核心代理类)时,除了核心 Java 与核心代理之外,我们不能假设任何依赖关系。如果不熟悉 Java 类加载概念,那么至少对它大致了解一下可能会很用(例如,阅读这段有用的概述)。
开销
好吧,性能始终是一个考虑因素,没人想写低效的代码。但是,在编写代理代码时,我们无权作出在编写代码时通常所做的开销权衡决策。我们需要在所有方面都精益求精。我们是他人聚会上的客人,我们应该无缝完成自己的工作。
有关代理性能开销和调优方法更深入的概述,可以查看这篇有趣的博客文章。
并发
通常,每个事件的第一个跟踪操作将在请求处理线程(池中许多线程之一)中执行。我们需要尽可能少地在这个线程中执行操作并快速完成,然后释放出来以处理更重要的业务。这些操作的附带结果将在共享集合中进行处理,它们在这里会遇到并发问题。例如,我们在入口处创建的 Span 对象会在请求处理线程的此代码中多次更新,但后来被用于序列化并通过不同的线程发送到 APM 服务器。此外,我们需要了解是跟踪同步还是潜在的异步操作。如果我们的跟踪可以在某个线程中启动并继续在其他线程中运行,我们就必须考虑这一点。
返回到我们的测试用例
下面介绍实施 Elasticsearch REST 客户端插件所采取的操作,为了方便起见,分为以下三个步骤。
注意: 从这里开始,以下内容会变得非常有技术性......
第 1 步:选择要装载的内容
这是该过程中最重要的一步。如果我们做一点研究并确保正确,就更有可能找到合适的方法并使过程变得非常容易。注意事项:
- 相关性:我们应装载方法,以实现:
- 捕获我们想要捕获的内容。例如,我们需要确保方法的结束时间减去开始时间可反映我们想要创建的 span 的持续时间
- 没有误报。如果调用了方法,我们始终要关注这点
- 没有漏报。在执行与 span 相关的操作时始终调用方法
- 进入或退出时,提供所有相关信息
- 向前兼容性:我们的目标是一个不太可能经常更改的中心 API。我们不想为跟踪库的每个次要版本都更新代码。
- 向后兼容性:这种装载方法计划向后支持多远?
我对客户端代码一无所知(即使它是 Elastic 的),于是下载并开始调查最新版本,当时是 6.4.1。Elasticsearch Java REST 客户端提供了高级和低级 API,其中高级 API 依赖低级 API,并且所有查询最终都通过后者完成。因此,为了同时支持这两种 API,我们自然只会关注低级客户端。
深入研究代码后,我找到了一个签名为 Response performRequest(Request request) 的方法(在 GitHub 中的这个位置)。对于这同一方法,还有四个附加的重写,所有这些重写都调用这一个方法并全部标记为 deprecated。此外,此方法调用 performRequestAsyncNoCatch 重写。其他唯一一个调用后面这个重写的方法是签名为 void performRequestAsync(Request request, ResponseListener responseListener) 的方法。进一步的研究表明,异步路径与同步路径完全相同:四个附加的已弃用重写都调用一个非弃用的重写(调用 performRequestAsyncNoCatch 来发出实际请求)。因此,从相关性考虑,performRequest 方法最为适合,因为它能准确地捕获所有同步请求,并在进入/退出时提供请求和响应信息:完美!我们告知 Byte Buddy 想要装载这种方法的方式是:重写匹配器提供的相关方法。

在向后兼容方面,这个新的中心 API 似乎是实现稳定性的良好选择。然而,在向前兼容方面,它并不是一个好的选择 — 版本 6.4.0 及之前的版本没有这个API ……
由于这是一个非常完美的备用装载选项,所以我决定使用它并获取对 Elasticsearch REST 客户端的长期支持,同时为旧版本添加附加装载。我创建了一个类似的过程来查找候选装载,并最终得到两个解决方案:一个用于版本 5.0.2 到 6.4.0,另一个用于版本 6.4.1 及更高版本。
第 2 步:代码设计
我们使用 Maven,对于我们为支持新技术而引入的每个新的装载,都是我们称为插件的模块。就我而言,因为我想同时测试新旧 Elasticsearch REST 客户端(意味着客户端依赖关系会存在冲突),并且由于每个客户端的装载都有所不同,所以每个客户端都需要拥有自己的模块/插件。由于新旧客户端都支持相同的技术,所以我将它们嵌套在一个公共的父模块下,最后得到以下结构:
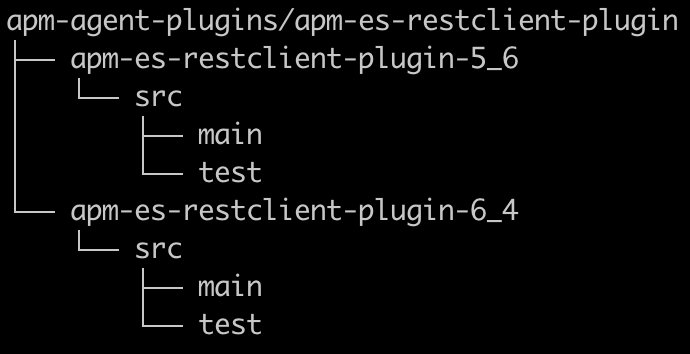
请务必只将实际的插件代码打包到代理中,以确保库依赖关系的作用域为 provided,并且测试依赖关系在 pom.xml 中的作用域为 test。如果您添加第三方代码,则必须对代码进行着色,即重新打包以使用根 Elastic APM Java 代理程序包名称。
对于实际代码,以下是添加插件的最低要求:
Instrumentation 类
抽象 ElasticApmInstrumentation 类的实施。它的作用是帮助确定用于 Instrumentation 类的正确的类和方法。由于执行类型和方法匹配会明显增加应用程序启动时间,因此,Instrumentation 类提供了一些增强匹配过程的筛选器,例如,忽略名称中不包含某个字符串的类,或者忽略由对我们正在寻找的类型完全没有可见性的类加载器加载的类。此外,它还提供了一些元数据信息,能够通过配置打开和关闭检测。
请注意,ElasticApmInstrumentation 可用作一项服务,这意味着每个实施都需要在提供程序配置文件中列出。
服务提供程序配置文件
您的 ElasticApmInstrumentation 实施是一个服务提供程序,它在运行时通过位于资源目录 META-INF/services 中的提供程序配置文件进行标识。提供程序配置文件的名称是服务的完全限定名称,它包含服务提供程序的完全限定名称列表,每行一个。
Advice 类
该类提供将被注入到跟踪方法的实际代码。它没有实施通用接口,但通常使用 Byte Buddy 的 @Advice.OnMethodEnter 和/或 @Advice.OnMethodExit 注释。这就是我们如何告知 Byte Buddy 我们想要在方法开始时注入的代码以及退出之前(静静地或引出 Throwable)的代码。借助功能全面的 Byte Buddy API,我们可以在这里创建各种丰富多彩的内容,比如
- 在方法入口处创建一个可在方法出口处使用的局部变量。
- 观察并可能替换方法参数、返回值或引出的
Throwable(如果适用)。 - 观察
this对象。
最终,我的 Elasticsearch REST 客户端模块结构如下:
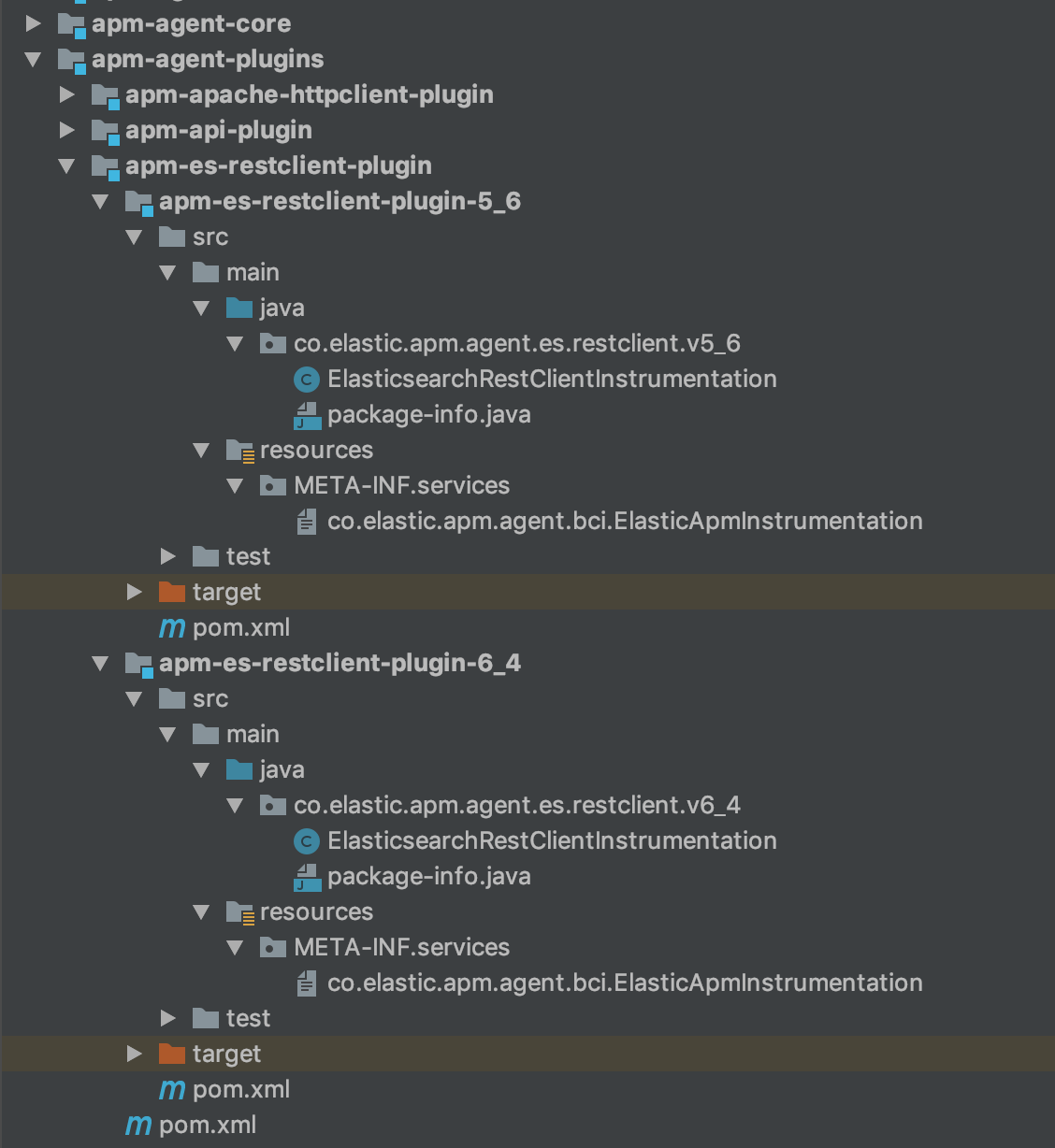
第 3 步:实施
如上所述,编写代理代码有一些细节。让我们看看这些概念是如何在这个插件中产生的:
跨度创建和维护
Elastic APM 使用跨度来反映每个特别关注的事件,例如处理 HTTP 请求、进行数据库查询和进行远程调用等。由代理记录的每个跨度树的根跨度称为事务(请参阅我们的数据模型文档了解更多内容)。在这种情况下,我们使用 Span 来描述 Elasticsearch 查询,因为它不是服务上记录的根事件。就像在这种情况下,插件通常会创建一个 Span、激活它、为其添加数据,最终停用并结束它。激活和停用是维护线程上下文状态的操作,该状态允许在代码中的任何位置获取当前活动的跨度(就像我们在创建跨度时所做的那样)。跨度必须结束并且激活的跨度必须停用,因此在这方面最佳做法是使用 try/finally。此外,如果发生错误,我们也应该报告错误。
永远不要破坏用户代码(并避免副作用)
除了编写非常“有防御性”的代码之外,要始终假设我们的代码可能会引发异常,这就是在我们的建议代码中使用 suppress = Throwable.class 的原因。这会告知 Byte Buddy,为在建议代码执行期间引发的所有 Throwable 类型都添加一个 Exception 处理程序,以确保在我们注入的代码失败时仍然执行用户代码。
此外,我们必须确保建议代码不会引起任何副作用,这可能会改变已装载代码的状态并因此影响其行为。就我而言,这与读取 Elasticsearch 查询的请求正文相关。通过 getContent API 获取请求内容流来读取正文。此 API 的某些实施将为每个调用返回一个新的 InputStream 实例,而其他实施为每个请求返回多个调用的相同实例。由于我们只知道在运行时使用了哪个实施,因此,我们必须确保读取正文不会阻止客户端读取它。幸运的是,还有一个 isRepeatable API 正好可以告诉我们。如果我们无法确保这一点,就可能会破坏客户端功能。
类的可见性
默认情况下,Instrumentation 类也是 Advice 类。但是,由于这些类的作用,它们之间有一个重要的区别。始终调用 Instrumentation 方法,无论它要装载的相应库实际上是可用的还是甚至在使用。另一方面,Advice 代码仅在检测到特定库的相关类时使用。我的 Advice 代码依赖于 Elasticsearch REST 客户端代码,以获取用于请求的 URL、请求正文、响应代码等信息。因此,在单独的类中编译 Advice 代码并且只在需要时由 Instrumentation 类引用会更安全。请注意,Advice 代码往往会依赖于已装载的库,因此这通常是一种很好的做法。
性能开销考虑因素
我们想要做的其中一件事就是获取 _search 查询,这意味着要以 InputStream 的形式读取我们有权访问的 HTTP 请求正文。关于我们需要将正文内容存储在某个地方这一事实我们可做的工作不多,所以内存开销至少是我们允许读取的每个已跟踪请求的正文长度。但是,在内存分配方面还是有很多工作可做,这可转换为 CPU 和由于垃圾收集而导致的暂停。因此,我们重用 ByteBuffer 来复制从流中读取的字节,重用 CharBuffer 来存储查询内容,直到序列化并发送到 APM 服务器,甚至 CharsetDecoder。这样,我们就不会基于每个请求分配和释放任何内存。因此,这减少了一些更复杂代码(IOUtils 类中的代码)的开销。
最终结果
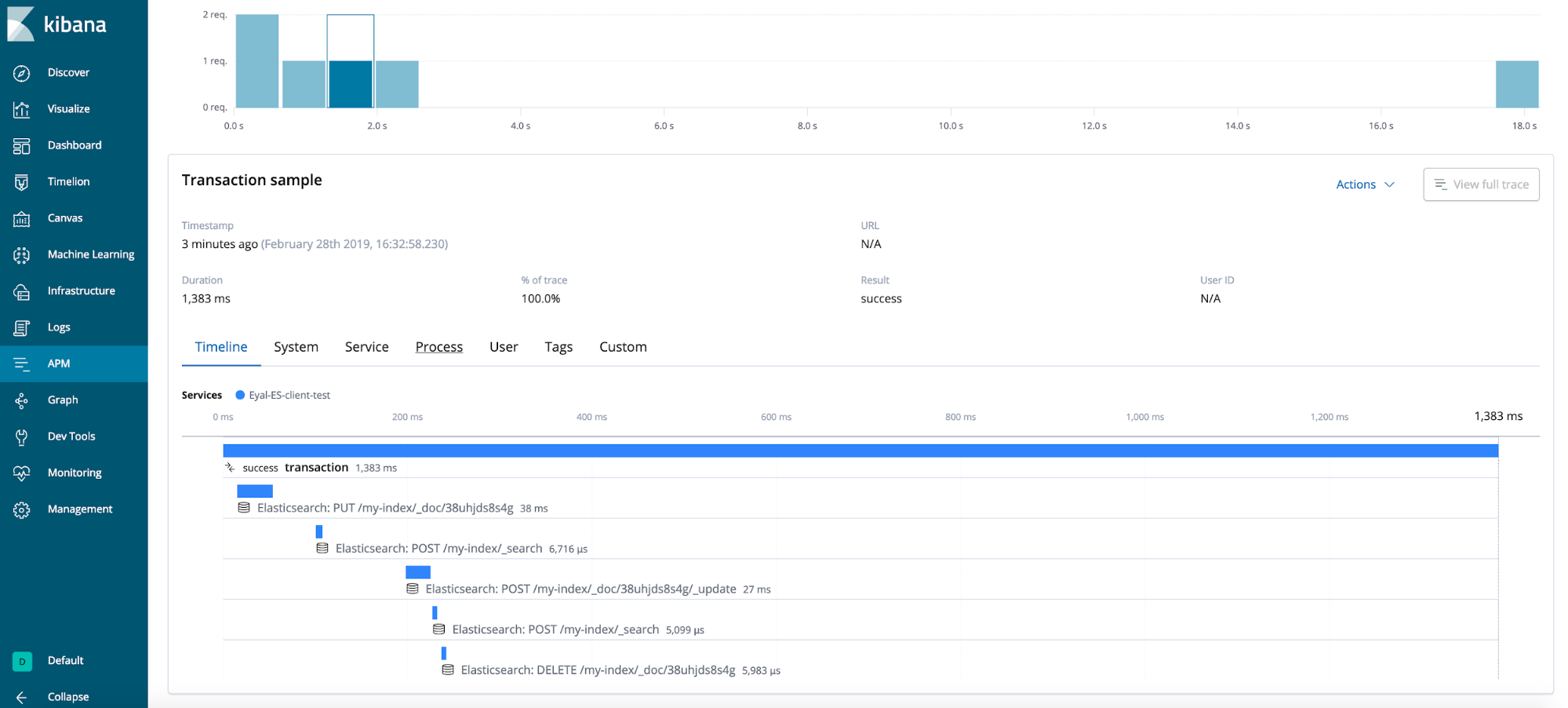
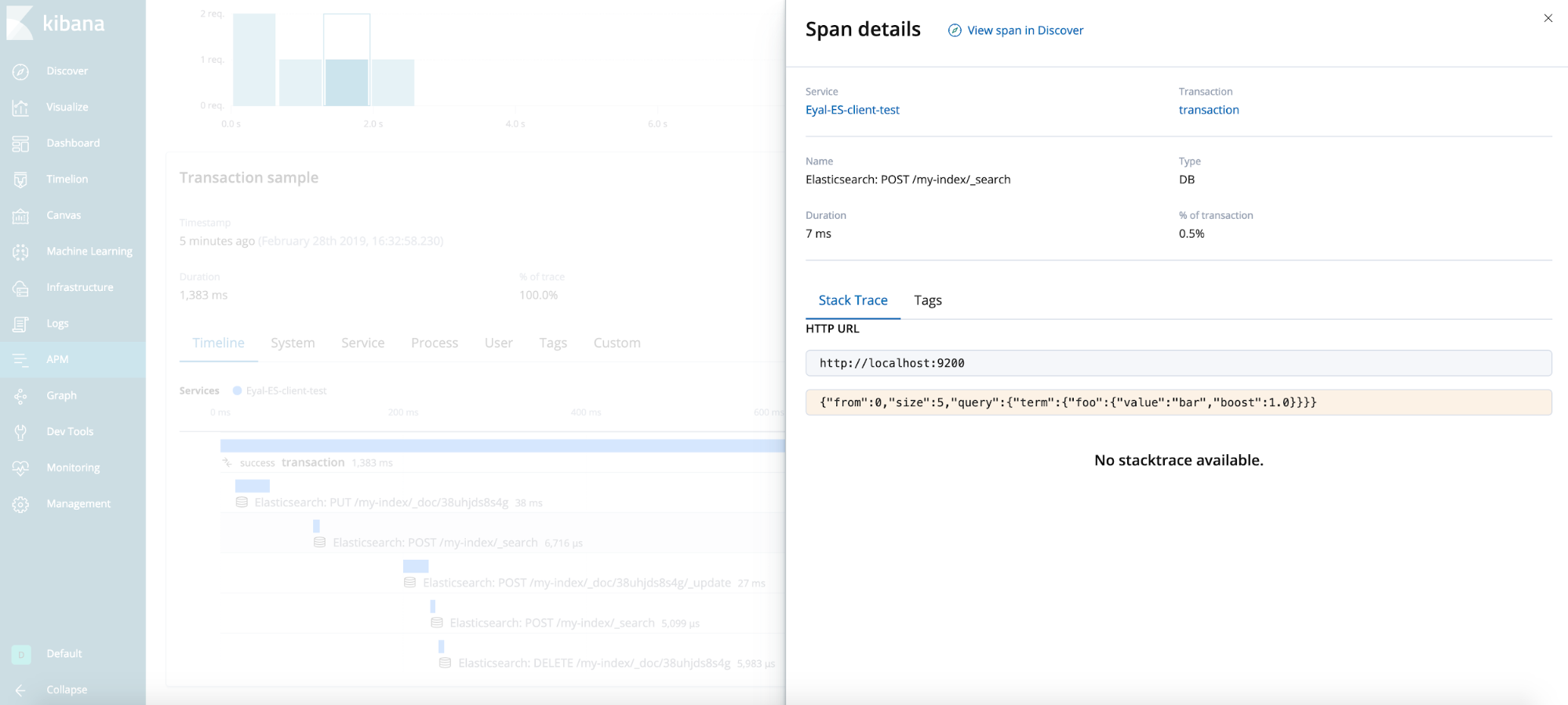
一般提示(未在测试用例中演示)
注意嵌套调用
某些情况下,在装载 API 方法时,您可能会遇到其中一个已装载方法调用另一个已装载方法的情况。例如,一个重写方法调用其超级方法,或者 API 的一个实施环绕另一个实施。了解这类情况非常重要,因为我们不希望为同一个操作报告多个跨度。没有规则说明何时适用、何时不适用,并且很可能会在不同场景/设置中获得不同的行为,因此,这种情况下的提示仅适用于出于这方面考虑的代码。
注意自我监测
确保您的跟踪代码不会导致调用将被跟踪的操作。好一点的情况是,这将导致报告跟踪过程本身产生的跟踪操作。比较糟糕的情况是,这可能导致堆栈溢出。例如,JDBC 跟踪 — 在尝试获取一些数据库信息时,我们会使用 java.sql.Connection#getMetaData API,这可能导致发生数据库查询并被跟踪,进而引发另一个 java.sql.Connection#getMetaData 调用等等。
注意异步操作
异步执行意味着可以在一个线程中创建跨度/事务,然后在另一个线程中激活。每个跨度/事务必须恰好一次结束,并且在激活它的每个线程中始终停用。因此,我们必须对这方面有绝对的认识。