Powering enterprise AI at scale: The Elastic and NVIDIA cuVS integration
Seamlessly vectorize high-volume data and accelerate your time to production with the new gold standard for GPU-accelerated vector search.


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Summary
- Elastic has collaborated with NVIDIA to launch GPU-accelerated vector indexing powered by NVIDIA cuVS.
- Elasticsearch integrated into the NVIDIA AI Factory validated design provides a proven, full-stack, pre-engineered blueprint for accelerating AI applications.
- Enterprises can vectorize massive volumes of unstructured data up to 12x faster than CPU-based approaches.
Organizations are heavily investing in AI. But in order to drive real business value, you need an infrastructure that can not only store massive amounts of data but also search and retrieve context from it fast. Moreover, you need systems that can reason, learn, answer questions, and take action, not just return search results.
Elastic vector indexing with NVIDIA cuVS GPU acceleration eliminates a critical barrier to successful enterprise-scale AI deployments, enabling organizations to vectorize massive volumes of unstructured data, delivering accurate, real-time context required by modern AI solutions at scale.
Frontier AI
Enterprises are entering a new phase of AI adoption, where the proliferation of unstructured data has made traditional search inadequate for extracting insights. As a result, organizations are turning to high-performance vector databases and semantic search to power modern AI applications, such as generative AI (GenAI), retrieval augmented generation (RAG), and AI agents.
Meanwhile, organizations are building AI factories to simplify AI deployment, scale performance, and maximize GPU efficiency and capacity. The integrated stack which combines accelerated compute with high-performance vector search is the most economically efficient maxim to push frontier AI to your consumers and the enterprise.
Is efficient AI possible?
When large enterprises build internal generative AI platforms that must index and retrieve context from petabytes of corporate data efficiently, costs immediately come to the forefront. These AI factories need every advantage possible to reduce expensive workloads.
Similarly, organizations looking to scale their vector search capabilities struggle to do so without linearly increasing their CPU hardware spend. When you set out to build a high-performing vector database, you face the challenge of constructing the vector index (HNSW graph) on the CPU. When comparing every vector, index building can explode into millions, or even billions, of arithmetic operations. And with that complexity comes ingestion bottlenecks. Add in index lifecycle operations like compaction and merges, and your compute overhead can increase significantly.
Cost-optimized vector infrastructure
To help you overcome such challenges, Elastic and NVIDIA together are enabling the Elastic AI Ecosystem, redefining how enterprises build and scale AI factories by delivering GPU-accelerated vector search and powerful AI infrastructure that unlocks next generation, real-time intelligence.
By combining the NVIDIA Enterprise AI Factory validated design with Elasticsearch’s powerful vector database, organizations can deliver deeper insights and real-time, relevant data to AI agents and GenAI applications securely and at enterprise scale.
With Elastic and NVIDIA, you get the power of a high-performing, feature-rich vector database with GPU acceleration built for modern AI.
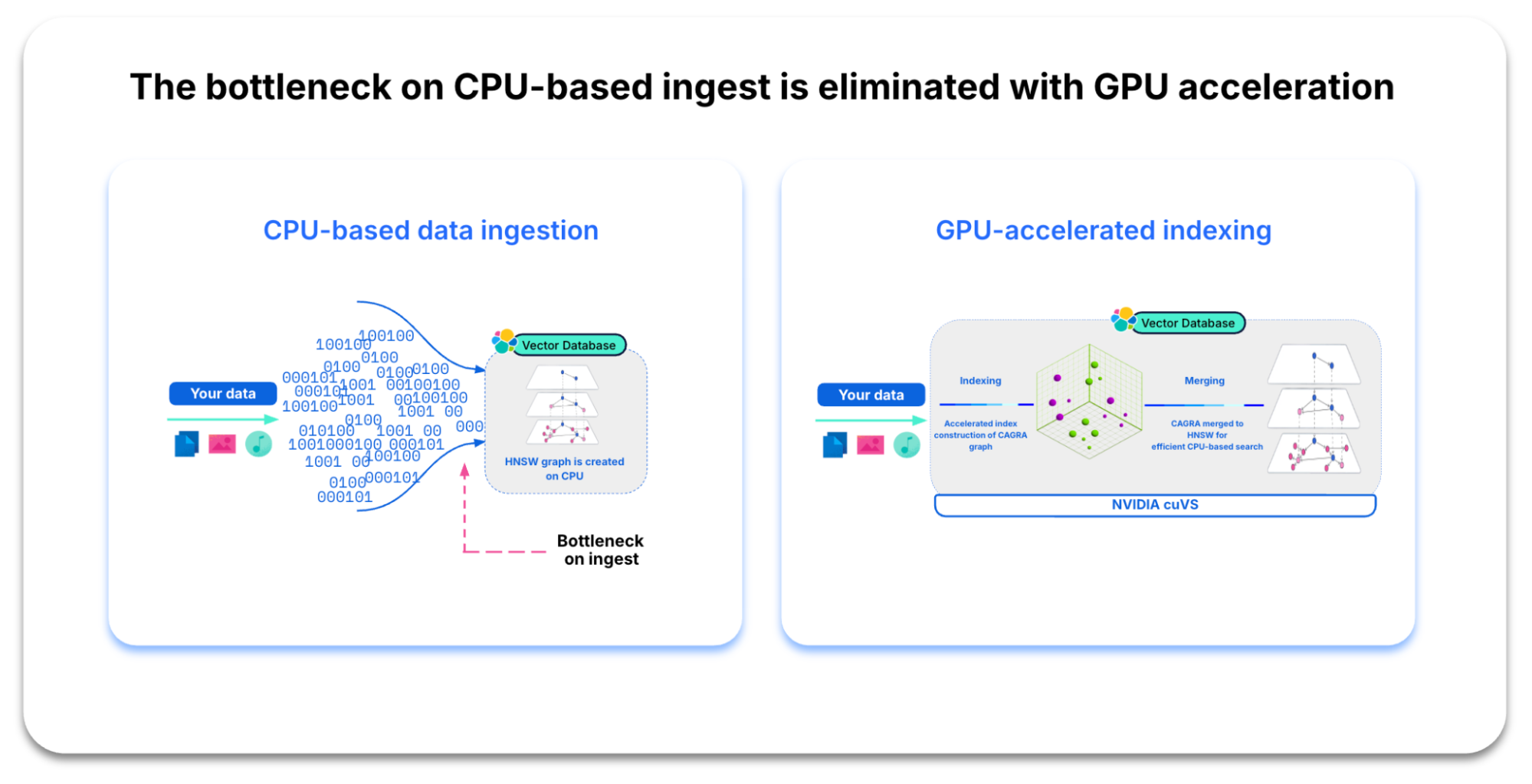
Below are some of the benefits you can expect from this integration.
Accelerated deployment
Reduce time-to-market by using a full-stack, pre-engineered system for building on-premises AI factories. Elasticsearch is a validated and supported vector database within the NVIDIA Enterprise AI Factory validated design, ensuring a reliable framework for deploying agentic AI applications.
Quick, efficient indexing
Handle exponentially growing vector embeddings and massive data volumes more efficiently. Integrating NVIDIA cuVS into Elasticsearch delivers a nearly 12x improvement in indexing throughput and a 7x increase in faster force merging.
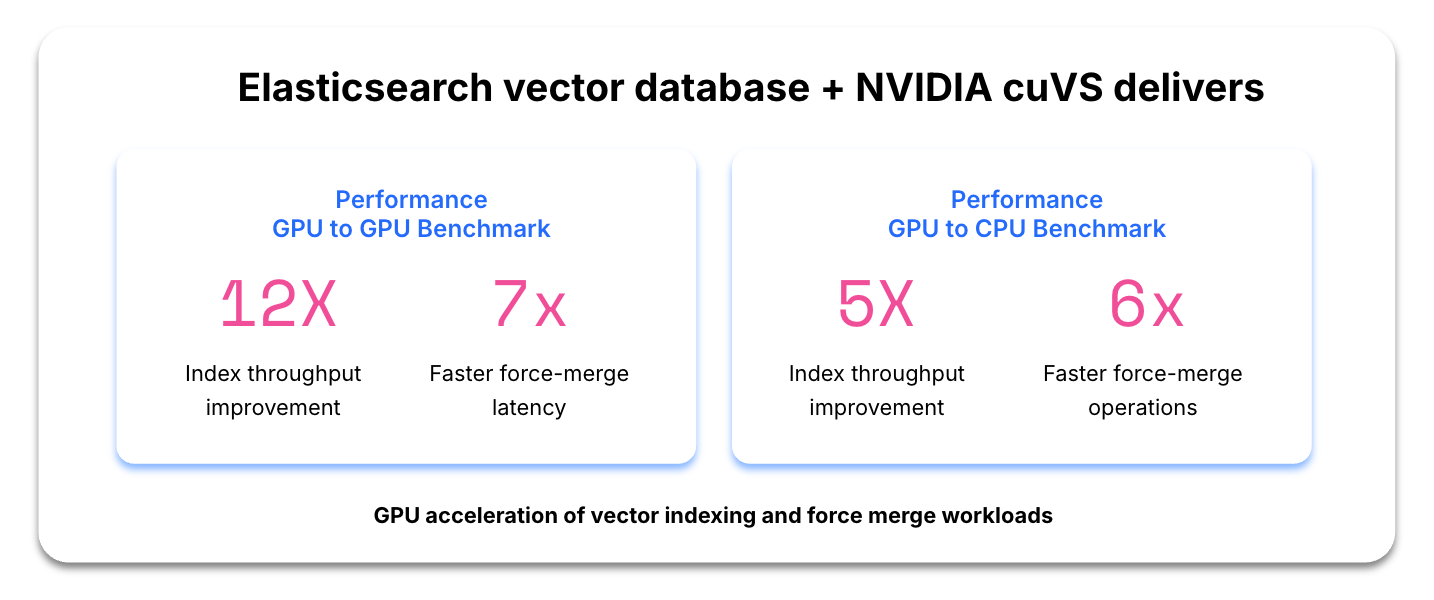
Cost-efficiency and resource optimization
Offloading math-intensive workloads to GPUs reduces CPU usage and maximizes the value of your existing infrastructure. On a cost-adjusted comparison, GPU acceleration versus standard CPU usage delivers approximately 5x higher indexing throughput and 6x faster force merging operations.
Enhanced real-time query performance
Elastic’s NVIDIA-accelerated vector search removes performance bottlenecks, allowing your infrastructure to handle massive query volumes with near-instant response times so that you can scale generative AI and RAG applications efficiently while delivering real-time, relevant insights.
Seamless future-proofing and scalability
Maintain a high-performance, proven-at-scale vector database without the burden of constant manual optimization. NVIDIA cuVS optimizes and accelerates vector search operations across evolving NVIDIA GPU architectures and CUDA versions, ensuring peak performance and seamless scalability for AI and data-intensive workloads.
Native GPU-accelerated inference and model management
Eliminate the complexity of managing external inference providers and infrastructure. Elastic Inference Service (EIS) provides native, high-throughput inference directly within Elasticsearch, using modern NVIDIA AI infrastructure to maintain low-latency performance at scale. Deploy production-ready managed models, including Jina AI’s multilingual embedding and reranker models, natively to ensure precise recall tuning and data sovereignty without extra operational overhead.
What’s next?
Elastic and NVIDIA collaborated to deliver more speed, scale, and value to enterprises that rely on vector search to build and deliver real-time RAG and AI applications. Your team can provide performance at scale with less strain on your infrastructure and your budget.
With Elasticsearch included in the NVIDIA AI Factory validated design, you get a proven, full-stack, pre-engineered blueprint for accelerating AI applications, meaning more efficiency and faster time to market.
The NVIDIA cuVS integration is currently in technical preview for Elastic self-managed enterprise customers (version 9.3). General availability is scheduled for April 2026 with the version 9.4 release, which will provide a production-ready foundation for high-volume vector search and real-time context retrieval.
Learn more about the expanding Elastic AI Ecosystem, download the Elastic AI Ecosystem Developer Guidebook, or connect with Elastic technical experts about high-performance AI at NVIDIA GTC. Visit us at booth #3200, watch live demos, and speak with Elastic experts.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, and associated marks are trademarks, logos, or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos, or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print